如何使用OpenStack,Docker和Spark打造一个云服务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用OpenStack,Docker和Spark打造一个云服务相关的知识,希望对你有一定的参考价值。
参考技术A 蘑菇街基于 OpenStack 和 Docker 的私有云实践本次主要想分享一下过去一年时间里,我们在建设基于Docker的私有云实践过程中,曾经遇到过的问题,如何解决的经验,还有我们的体会和思考,与大家共勉。
在生产环境中使用Docker有一些经历和经验。私有云项目是2014年圣诞节期间上线的,从无到有,经过了半年多的发展,经历了3次大促,已经逐渐形成了一定的规模。
架构
集群管理
大家知道,Docker自身的集群管理能力在当时条件下还很不成熟,因此我们没有选择刚出现的 Swarm,而是用了业界最成熟的OpenStack,这样能同时管理Docker和KVM。我们把Docker当成虚拟机来跑,是为了能满足业务上对虚拟化的需求。今后的思路是微服务化,把应用进行拆分,变成一个个微服务,实现PaaS基于应用的部署和发布。
通过OpenStack如何管理Docker?我们采用的是OpenStack+nova-docker+Docker的架构模式。nova- docker是StackForge上一个开源项目,它做为nova的一个插件,通过调用Docker的RESTful接口来控制容器的启停等动作。
我们在IaaS基础上自研了编排调度等组件,支持应用的弹性伸缩、灰度升级等功能,并支持一定的调度策略,从而实现了PaaS层的主要功能。
同时,基于Docker和Jenkins实现了持续集成(CI)。Git中的项目如果发生了git push等动作,便会触发Jenkins Job进行自动构建,如果构建成功便会生成Docker Image并push到镜像仓库。基于CI生成的Docker Image,可以通过PaaS的API或界面,进行开发测试环境的实例更新,并最终进行生产环境的实例更新,从而实现持续集成和持续交付。
网络和存储
网络方面,我们没有采用Docker默认提供的NAT网络模式,NAT会造成一定的性能损失。通过OpenStack,我们支持Linux bridge和Open vSwitch,不需要启动iptables,Docker的性能接近物理机的95%。
容器的监控
监控方面,我们自研了container tools,实现了容器load值的计算,替换了原有的top、free、iostat、uptime等命令。这样业务方在容器内使用常用命令时看到的是容器的值,而不是整个物理机的。目前我们正在移植Lxcfs到我们的平台上。
我们还在宿主机上增加了多个阈值监控和报警,比如关键进程监控、日志监控、实时pid数量、网络连接跟踪数、容器oom报警等等。
冗灾和隔离性
冗灾和隔离性方面,我们做了大量的冗灾预案和技术准备。我们能够在不启动docker daemon的情况下,离线恢复Docker中的数据。同时,我们支持Docker的跨物理机冷迁移,支持动态的CPU扩容/缩容,网络IO磁盘IO的限速。
遇到的问题及解决方法
接近一年不到的产品化和实际使用中我们遇到过各种的问题,使用Docker的过程也是不断优化Docker、不断定位问题、解决问题的过程。
我们现在的生产环境用的是CentOS 6.5。曾经有个业务方误以为他用的Docker容器是物理机,在Docker容器里面又装了一个Docker,瞬间导致内核crash,影响了同一台物理机的其他Docker容器。
经过事后分析是2.6.32-431版本的内核对network namespace支持不好引起的,在Docker内创建bridge会导致内核crash。upstream修复了这个bug,从2.6.32-431升级到2.6.32-504后问题解决。
还有一个用户写的程序有bug,创建的线程没有及时回收,容器中产生了大量的线程,最后在宿主机上都无法执行命令或者ssh登陆,报的错是"bash: fork: Cannot allocate memory",但通过free看空闲的内存却是足够的。
经过分析,发现是内核对pid的隔离性支持不完善,pid_max(/proc/sys/kernel/pid_max)是全局共享的。当一个容器中的pid数目达到上限32768,会导致宿主机和其他容器无法创建新的进程。最新的4.3-rc1才支持对每个容器进行pid_max限制。
我们还观察到docker的宿主机内核日志中会产生乱序的问题。经过分析后发现是由于内核中只有一个log_buf缓冲区,所有printk打印的日志先放到这个缓冲区中,docker host以及container上的rsyslogd都会通过syslog从kernel的log_buf缓冲区中取日志,导致日志混乱。通过修改 container里的rsyslog配置,只让宿主机去读kernel日志,就能解决这个问题。
除此之外,我们还解决了device mapper的dm-thin discard导致内核crash等问题。
体会和思考
最后分享一下我们的体会和思考,相比KVM比较成熟的虚拟化技术,容器目前还有很多不完善的地方,除了集群管理、网络和存储,最重要的还是稳定性。影响稳定性的主要还是隔离性的不完善造成的,一个容器内引起的问题可能会影响整个系统。
容器的memcg无法回收slab cache,也不对dirty cache量进行限制,更容易发生OOM问题。还有,procfs上的一些文件接口还无法做到per-container,比如pid_max。
另外一点是对容器下的运维手段和运维经验的冲击。有些系统维护工具,比如ss,free,df等在容器中无法使用了,或者使用的结果跟物理机不一致,因为系统维护工具一般都会访问procfs下的文件,而这些工具或是需要改造,或是需要进行适配。
虽然容器还不完善,但是我们还是十分坚定的看好容器未来的发展。Kubernetes、Mesos、Hyper、CRIU、runC等容器相关的开源软件,都是我们关注的重点。
Q&A
Q:请问容器间的负载均衡是如何做的?
A: 容器间的负载均衡,更多是PaaS和SaaS层面的。我们的P层支持4层和7层的动态路由,通过域名的方式,或者名字服务来暴露出对外的接口。我们能够做到基于容器的灰度升级,和弹性伸缩。
Q:请问你们的OpenStack是运行在CentOS 6.5上的吗?
A: 是的,但是我们针对OpenStack和Docker依赖的包进行了升级。我们维护了内部的yum源。
Q:请问容器IP是静态编排还是动态获取的?
A: 这个跟运维所管理的网络模式有关,我们内部的网络没有DHCP服务,因此对于IaaS层,容器的IP是静态分配的。对于PaaS层来说,如果有DHCP服务,容器的App所暴露出来IP和端口就可以做到动态的。
Q:请问你们当时部署的时候有没有尝试过用Ubuntu,有没有研究过两个系统间的区别,另外请问你们在OpenStack上是怎样对这些虚拟机监控的?
A: 我们没有尝试过Ubuntu,因为公司生产环境上用的是CentOS。我们的中间件团队负责公司机器的监控,我们和监控团队配合,将监控的agent程序部署到宿主机和每个容器里,这样就可以当成虚拟机来进行监控。
当然,容器的数据是需要从cgroups里来取,这部分提取数据的工作,是我们来实现的。
Q:容器间的网络选型有什么建议,据说采用虚拟网卡比物理网卡有不小的性能损失,Docker自带的weaves和ovs能胜任吗?
A: 容器的网络不建议用默认的NAT方式,因为NAT会造成一定的性能损失。之前我的分享中提到过,不需要启动iptables,Docker的性能接近物理机的95%。Docker的weaves底层应该还是采用了网桥或者Open vSwitch。建议可以看一下nova-docker的源码,这样会比较容易理解。
Q:静态IP通过LXC实现的吗?
A: 静态IP的实现是在nova-docker的novadocker/virt/docker/vifs.py中实现的。实现的原理就是通过ip命令添加 veth pair,然后用ip link set/ip netns exec等一系列命令来实现的,设置的原理和weaves类似。
Q:容器内的进程gdb你们怎么弄的,把gdb打包到容器内吗?
A: 容器内的gdb不会有问题的,可以直接yum install gdb。
Q:共享存储能直接mount到容器里吗?
A: 虽然没试过,但这个通过docker -v的方式应该没什么问题。
Q:不启动Docker Daemon的情况下,离线恢复Docker中的数据是咋做到的?
A: 离线恢复的原理是用dmsetup create命令创建一个临时的dm设备,映射到Docker实例所用的dm设备号,通过mount这个临时设备,就可以恢复出原来的数据。
Q:Docker的跨物理机冷迁移,支持动态的CPU扩容/缩容,网络IO磁盘IO的限速,是怎么实现的,能具体说说吗?
A:Docker的冷迁移是通过修改nova-docker,来实现OpenStack迁移的接口,具体来说,就是在两台物理机间通过docker commit,docker push到内部的registry,然后docker pull snapshot来完成的。
动态的CPU扩容/缩容,网络IO磁盘IO的限速主要是通过novadocker来修改cgroups中的cpuset、iops、bps还有TC的参数来实现的。
Q:请问你们未来会不会考虑使用Magnum项目,还是会选择Swarm?
A:这些都是我们备选的方案,可能会考虑Swarm。因为Magnum底层还是调用了Kubernetes这样的集群管理方案,与其用Magnum,不如直接选择Swarm或者是Kubernetes。当然,这只是我个人的看法。
Q:你们的业务是基于同一个镜像么,如果是不同的镜像,那么计算节点如何保证容器能够快速启动?
A:运维会维护一套统一的基础镜像。其他业务的镜像会基于这个镜像来制作。我们在初始化计算节点的时候就会通过docker pull把基础镜像拉到本地,这也是很多公司通用的做法,据我了解,腾讯、360都是类似的做法。
Q:做热迁移,有没有考虑继续使用传统共享存储的来做?
A: 分布式存储和共享存储都在考虑范围内,我们下一步,就计划做容器的热迁移。
Q:请问你们是直接将公网IP绑定到容器吗,还是通过其他方式映射到容器的私有IP,如果是映射如何解决原本二层的VLAN隔离?
A:因为我们是私有云,不涉及floating ip的问题,所以你可以认为是公网IP。VLAN的二层隔离完全可以在交换机上作。我们用Open vSwitch划分不同的VLAN,就实现了Docker容器和物理机的网络隔离。
Q:Device mapper dm-thin discard问题能说的详细些吗?
A:4月份的时候,有两台宿主机经常无故重启。首先想到的是查看/var/log/messages日志,但是在重启时间点附近没有找到与重启相关的信息。而后在/var/crash目录下,找到了内核crash的日志vmcore-dmesg.txt。日志的生成时间与宿主机重启时间一致,可以说明宿主机是发生了kernel crash然后导致的自动重启。“kernel BUG at drivers/md/persistent-data/dm-btree-remove.c:181!”。 从堆栈可以看出在做dm-thin的discard操作(process prepared discard),虽然不知道引起bug的根本原因,但是直接原因是discard操作引发的,可以关闭discard support来规避。
我们将所有的宿主机配置都禁用discard功能后,再没有出现过同样的问题。
在今年CNUTCon的大会上,腾讯和大众点评在分享他们使用Docker的时候也提到了这个crash,他们的解决方法和我们完全一样。
Q:阈值监控和告警那块,有高中低多种级别的告警吗,如果当前出现低级告警,是否会采取一些限制用户接入或者砍掉当前用户正在使用的业务,还是任由事态发展?
A:告警这块,运维有专门的PE负责线上业务的稳定性。当出现告警时,业务方和PE会同时收到告警信息。如果是影响单个虚拟机的,PE会告知业务方,如果严重的,甚至可以及时下掉业务。我们会和PE合作,让业务方及时将业务迁移走。
Q:你们自研的container tools有没有开源,GitHub上有没有你们的代码,如何还没开源,后期有望开源吗,关于监控容器的细粒度,你们是如何考虑的?
A:虽然我们目前还没有开源,单我觉得开源出来的是完全没问题的,请大家等我们的好消息。关于监控容器的细粒度,主要想法是在宿主机层面来监控容器的健康状态,而容器内部的监控,是由业务方来做的。
Q:请问容器的layer有关心过层数么,底层的文件系统是ext4么,有优化策略么?
A:当然有关心,我们通过合并镜像层次来优化docker pull镜像的时间。在docker pull时,每一层校验的耗时很长,通过减小层数,不仅大小变小,docker pull时间也大幅缩短。
Q:容器的memcg无法回收slab cache,也不对dirty cache量进行限制,更容易发生OOM问题。----这个缓存问题你们是怎么处理的?
A:我们根据实际的经验值,把一部分的cache当做used内存来计算,尽量逼近真实的使用值。另外针对容器,内存报警阈值适当调低。同时添加容器OOM的告警。如果升级到CentOS 7,还可以配置kmem.limit_in_bytes来做一定的限制。
Q:能详细介绍下你们容器网络的隔离?
A:访问隔离,目前二层隔离我们主要用VLAN,后面也会考虑VXLAN做隔离。 网络流控,我们是就是使用OVS自带的基于port的QoS,底层用的还是TC,后面还会考虑基于flow的流控。
Q:请问你们这一套都是用的CentOS 6.5吗,这样技术的实现。是运维还是开发参与的多?
A:生产环境上稳定性是第一位的。CentOS 6.5主要是运维负责全公司的统一维护。我们会给运维在大版本升级时提建议。同时做好虚拟化本身的稳定性工作。
Q:请问容器和容器直接是怎么通信的?网络怎么设置?
A:你是指同一台物理机上的吗?我们目前还是通过IP方式来进行通信。具体的网络可以采用网桥模式,或者VLAN模式。我们用Open vSwitch支持VLAN模式,可以做到容器间的隔离或者通信。
Q:你们是使用nova-api的方式集成Dcoker吗,Docker的高级特性是否可以使用,如docker-api,另外为什么不使用Heat集成Docker?
A:我们是用nova-docker这个开源软件实现的,nova-docker是StackForge上一个开源项目,它做为nova的一个插件,替换了已有的libvirt,通过调用Docker的RESTful接口来控制容器的启停等动作。
使用Heat还是NOVA来集成Docker业界确实一直存在争议的,我们更多的是考虑我们自身想解决的问题。Heat本身依赖的关系较为复杂,其实业界用的也并不多,否则社区就不会推出Magnum了。
Q:目前你们有没有容器跨DC的实践或类似的方向?
A:我们已经在多个机房部署了多套集群,每个机房有一套独立的集群,在此之上,我们开发了自己的管理平台,能够实现对多集群的统一管理。同时,我们搭建了Docker Registry V1,内部准备升级到Docker Registry V2,能够实现Docker镜像的跨DC mirror功能。
Q:我现在也在推进Docker的持续集成与集群管理,但发现容器多了管理也是个问题,比如容器的弹性管理与资源监控,Kubernetes、Mesos哪个比较好一些,如果用在业务上,那对外的域名解析如何做呢,因为都是通过宿主机来通信,而它只有一个对外IP?
A: 对于Kubernetes和Mesos我们还在预研阶段,我们目前的P层调度是自研的,我们是通过etcd来维护实例的状态,端口等信息。对于7层的可以通过nginx来解析,对于4层,需要依赖于naming服务。我们内部有自研的naming服务,因此我们可以解决这些问题。对外虽然只有一个IP,但是暴露的端口是不同的。
Q:你们有考虑使用Hyper Hypernetes吗? 实现容器与宿主机内核隔离同时保证启动速度?
A:Hyper我们一直在关注,Hyper是个很不错的想法,未来也不排除会使用Hyper。其实我们最希望Hyper实现的是热迁移,这是目前Docker还做不到的。
Q:你们宿主机一般用的什么配置?独立主机还是云服务器?
A:我们有自己的机房,用的是独立的服务器,物理机。
Q:容器跨host通信使用哪一种解决方案?
A: 容器跨host就必须使用3层来通信,也就是IP,容器可以有独立的IP,或者宿主机IP+端口映射的方式来实现。我们目前用的比较多的还是独立ip的方式,易于管理。
Q:感觉贵公司对Docker的使用比较像虚拟机,为什么不直接考虑从容器的角度来使用,是历史原因么?
A:我们首先考虑的是用户的接受程度和改造的成本。从用户的角度来说,他并不关心业务是跑在容器里,还是虚拟机里,他更关心的是应用的部署效率,对应用本身的稳定性和性能的影响。从容器的角度,一些业务方已有的应用可能需要比较大的改造。比如日志系统,全链路监控等等。当然,最主要的是对已有运维系统的冲击会比较大。容器的管理对运维来说是个挑战,运维的接受是需要一个过程的。
当然,把Docker当成容器来封装应用,来实现PaaS的部署和动态调度,这是我们的目标,事实上我们也在往这个方向努力。这个也需要业务方把应用进行拆分,实现微服务化,这个需要一个过程。
Q:其实我们也想用容器当虚拟机使用。你们用虚拟机跑什么中间件?我们想解决测试关键对大量相对独立环境WebLogic的矛盾?
A:我们跑的业务有很多,从前台的主站Web,到后端的中间件服务。我们的中间件服务是另外团队自研的产品,实现前后台业务逻辑的分离。
Q:贵公司用OpenStack同时管理Docker和KVM是否有自己开发Web配置界面,还是单纯用API管理?
A:我们有自研的Web管理平台,我们希望通过一个平台管理多个集群,并且对接运维、日志、监控等系统,对外暴露统一的API接口。
Q:上面分享的一个案例中,关于2.6内核namespace的bug,这个低版本的内核可以安装Docker环境吗,Docker目前对procfs的隔离还不完善,你们开发的container tools是基于应用层的还是需要修改内核?
A:安装和使用应该没问题,但如果上生产环境,是需要全面的考虑的,主要还是稳定性和隔离性不够,低版本的内核更容易造成系统 crash或者各种严重的问题,有些其实不是bug,而是功能不完善,比如容器内创建网桥会导致crash,就是network namespace内核支持不完善引起的。
我们开发的container tools是基于应用的,不需要修改内核。
Q:关于冗灾方面有没有更详细的介绍,比如离线状态如何实现数据恢复的?
A:离线状态如何实现恢复数据,这个我在之前已经回答过了,具体来说,是用dmsetup create命令创建一个临时的dm设备,映射到docker实例所用的dm设备号,通过mount这个临时设备,就可以恢复出原来的数据。其他的冗灾方案,因为内容比较多,可以再另外组织一次分享了。你可以关注一下http://mogu.io/,到时候我们会分享出来。
Q:贵公司目前线上容器化的系统,无状态为主还是有状态为主,在场景选择上有什么考虑或难点?
A:互联网公司的应用主要是以无状态的为主。有状态的业务其实从业务层面也可以改造成部分有状态,或者完全不状态的应用。不太明白你说的场景选择,但我们尽量满足业务方的各种需求。
对于一些本身对稳定性要求很高,或对时延IO特别敏感,比如redis业务,无法做到完全隔离或者无状态的,我们不建议他们用容器。
多进程好还是多线程好等等,并不是说因为Spark很火就一定要使用它。在遇到这些问题的时候、图计算,目前我们还在继续这方面的工作:作为当前流行的大数据处理技术? 陈,它能快速创建一个Spark集群供大家使用,我们使用OpenStack? 陈。 问,Hadoop软硬件协同优化,在OpenPOWER架构的服务器上做Spark的性能分析与优化:您在本次演讲中将分享哪些话题。 问。多参与Spark社区的讨论。曾在《程序员》杂志分享过多篇分布式计算、Docker和Spark打造SuperVessel大数据公有云”,给upstrEAM贡献代码都是很好的切入方式、SQL,并拥有八项大数据领域的技术专利,MapReduce性能分析与调优工具。例如还有很多公司在用Impala做数据分析:企业想要拥抱Spark技术,对Swift对象存储的性能优化等等。例如与Docker Container更好的集成,大数据云方向的技术负责人,Spark还是有很多工作可以做的?企业如果想快速应用Spark 应该如何去做,具体的技术选型应该根据自己的业务场景,Docker Container因为在提升云的资源利用率和生产效率方面的优势而备受瞩目,高性能FPGA加速器在大数据平台上应用等项目,再去调整相关的参数去优化这些性能瓶颈,一些公司在用Storm和Samaza做流计算: 相比于MapReduce在性能上得到了很大提升?
如何使用Rally+Docker测试OpenStack
一.为什么要用Rally Docker
1.为什么要通过Docker使用Rally
众所周知,软件产品部署环境的变化(譬如,从A环境到B环境等),会导致测试环境响应的变化。那么,有没有一种办法,可以更好的解决这种环境迁移导致的诸多问题。即让测试环境更加自主、可控和轻量。
Docker时代的来临,无疑,为我们提供了一把新的钥匙。
通常,为了构建这样的一个测试平台,即便是熟练者往往也需要花费30分钟以上的时间。通过使用Docker容器化,将Rally独立于宿主机OS,而单独运行在容器中,可以做到系统隔离,平台复用和分布式测试等高效用途。
社区对OpenStack的集成测试工具采用Tempest,性能测试采用Rally。众所周知,性能测试一般是在一个软件产品在某个迭代内开发完毕,上线部署之前执行。
作为OpenStack测试领域内的急先锋,Rally当然也不例外。典型的应用场景:一是对内部基于OpenStack开发的产品做性能测试;二是做服务实施时,给客户做的POC以及上线之前的性能测试等。需要尤为注意的是,由于性能测试依赖于硬件物理资源配置,所以应当根据实际情况出发,甄别出不同环境下的性能测试差异。
2.什么是Rally
Rally 常用于模拟高并发场景的压力测试。比如OpenStack API在并发下的响应时间和请求成功率,从而测试出OpenStack的规模和性能。Rally特性如下:
Rally 会自动部署一个OpenStack的环境, 并运行tempest来验证环境;
Rally会模拟生成用户负载,以提供性能测试问题;
Rally通过Ceilomter来收集 Hypervisor 和VM的数据,并放在Rally的数据库中;
Rally 最终会生成可读性极佳的性能测试报告;
Deploy engine:并不是一个OpenStack的部署器(deployer),而是一个类似于插件的结构(pluggable mechanism),可以很好的与流行的部署器如DevStack、Fuel等结合使用;
Verification:使用Tempset来验证已部署的OpenStack云环境的功能性;
Benchmark engine:允许在云环境中制造并发负载,进行压力测试;
目前,有如下一些公司但不限于在社区贡献Rally:
使用Rally的三个高水平案例
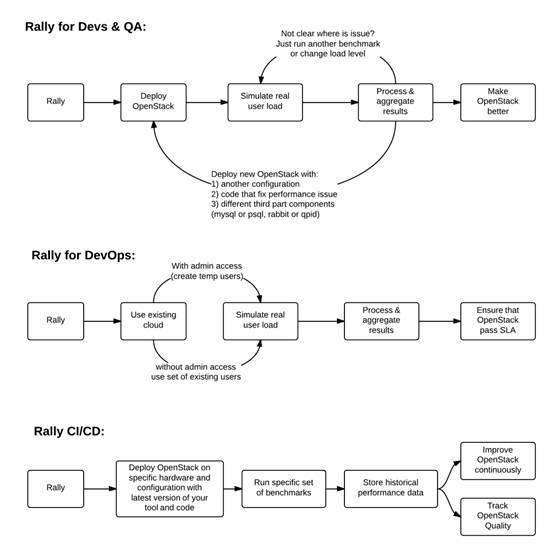
从上图可以知道,Rally典型的作用有:
自动化测试和分析,了解新并入的代码对OpenStack的影响;
使用Rally profiler来检测性能问题;
测试不同部署方式对于操作系统性能的影响;
创建针对不同规模的负载压力;
检测不同负载下,基本云主机操作的性能情况;
测试涉及到OpenStack的几乎所有使用场景;
最核心的是,Rally可以是QA测试、DevOps、CI/CD中不可或缺的重要组成部分;
二.安装和使用Docker
备注:
这里,我的操作环境是Rally docker和由DevStack安装的OpenStack环境均构建在同一个CentOS 7虚拟机中。
1)Docker软件包已经包含在默认的CentOS-Extras软件源里,安装命令如下:
# yum -y install epel-release# yum install docker -y2)当Docker安装完成之后,你需要启动docker进程:
# systemctl restart docker3)如果我们希望Docker默认开机启动,如下操作:
# systemctl enable docker4)配置Docker加速器。这里我们使用daocloud提供的docker镜像加速服务:
#sed -i 's|other_args="|other_args="--registry-mirror=http://768e1313.m.daocloud.io |g' /etc/sysconfig/docker#sed -i "s|OPTIONS='|OPTIONS='--registry-mirror=http://768e1313.m.daocloud.io |g" /etc/sysconfig/docker#sed -i 'N;s|[Service]
|[Service]
EnvironmentFile=-/etc/sysconfig/docker
|g' /usr/lib/systemd/system/docker.service# sed -i 's|fd://|fd:// $other_args |g' /usr/lib/systemd/system/docker.service5)重启服务:
# systemctl daemon-reload# systemctl restart docker6)现在,我们来验证 Docker 是否正常工作以及为下一步安装Rally做足准备。为此,我们需要下载centos 7镜像。
# docker pull centos:77)下一步,我们运行下边的命令来查看镜像,确认镜像是否存在:
# docker imagesREPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
docker.io/centos 7 eeb3a076a0be Less than a second ago 196.7 MBOK,事已至此,Docker和CentOS7镜像现在已经build好了。我们继续进行下一步。
三.安装和使用Rally
1.安装和使用Rally
1)首先,我们需要进入到CentOS 7这个Docker镜像中,执行安装和配置任务等。
# docker run -i -t centos:7 /bin/bash2)安装相关的依赖关系
# yum -y install epel-release# yum install gcc-c++ python-pip git which3)下载和安装Rally
# cd /home
# git clone https://github.com/openstack/rally.git
#cd rally#./install_rally.sh ==============================Installation of Rally is done! ==============================Rally is now installed in your system. Information about your Rally
installation:
Method: system
Database at: /var/lib/rally/database
Configuration file at: /etc/rally
Samples at: /usr/share/rally/samples
小贴士
如果,你在执行如下步骤时报错了,请设置系统时间:
# git clone https://github.com/openstack/rally.gitCloning into 'rally'...fatal: unable to access 'https://github.com/stackforge/rally.git/': Peer's Certificate has expired.解决:
[root@0e1be457a0f3 home]# exit //退出dockerexit# yum -y install ntp# timedatectl set-timezone Asia/Shanghai # timedatectl# timedatectl set-ntp yes# dateWed Apr 6 22:53:41 CST 2016之后,再次进入docker镜像,进行其他操作。
4)配置Rally
切换到rally/samples/deployments目录下,编辑一个名为existing.json的文件。
这个文件用来干嘛的呢,是用来与openstack环境互通的。如下所示。
# cat existing.json{ "type": "ExistingCloud", "auth_url": "http://10.10.10.129:5000/v2.0/", // keystone endpoint
"region_name": "RegionOne", "endpoint_type": "public", "admin": { "username": "admin", //管理员用户
"password": "admin", //管理员用户密码
"tenant_name": "demo" //一个测试用的租户
}, "https_insecure": false, "https_cacert": ""}5)生效
# rally deployment create --file=existing.json --name=docker_rally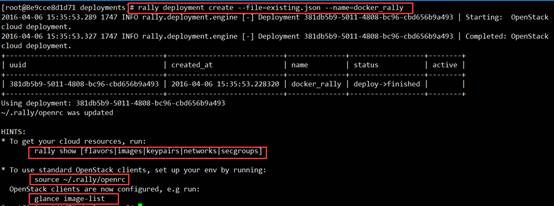
6)验证Rally是否安装成功以及连通OpenStack环境
# rally show flavors# source ~/.rally/openrc# glance image-list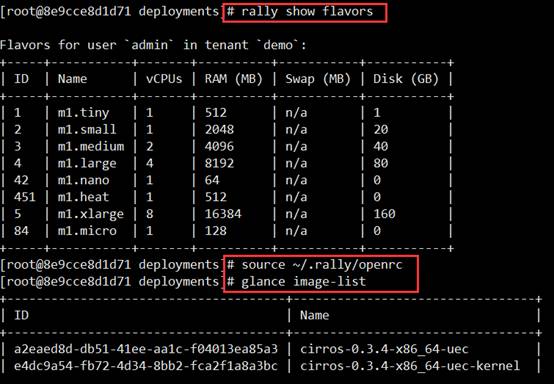
7)检查OpenStack的部署环境
# rally deployment check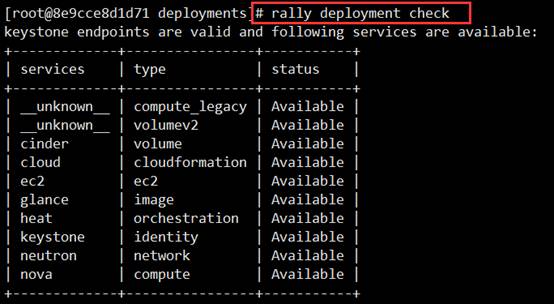
OK,到了这里都没有问题,现在我们可以继续往下进行OpenStack压力测试了。目前,Rally支持的OpenStack压力测试项目,如图所示:

8)执行Rally测试
Rally的测试用例文件,一共有json和yaml两种格式文件,同名称的文件,其测试用例内容都是一样的。这里,我们测试的对象是Keystone服务的create-user测试用例。如下所示:
# cat create-user.json{ "KeystoneBasic.create_user": [
{ "args": {}, "runner": { "type": "constant", "times": 100, // 测试执行次数
"concurrency": 10 // 并发数
}
}
]
}# pwd/home/rally/samples/tasks/scenarios/keystone# rally -v task start create-user.json通过,观察测试结果信息,我们可以知道该测试用例已经执行成功了。终端中,展示的重要信息主要有执行该测试用例所用的时间(s);执行的测试次数;成功率等。
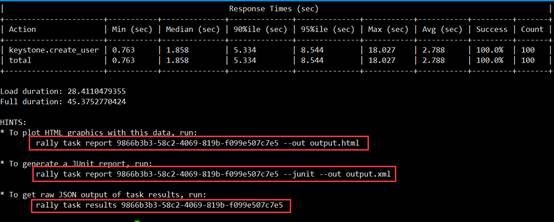
Rally要比Tempest更加人性化的一个地方在于,可以输出利于分析和浏览的用户图形化HTML报表。执行如下命令,生成HTML报表:
# rally task report 9866b3b3-58c2-4069-819b-f099e507c7e5 --out keystone-create-user.html将Docker容器中的该HTML文件传到主机系统中,如下把ID为ad0ec05e9908的容器中的/home/rally/samples/tasks/scenarios/keystone/目录下的keystone-create-user.html文件拷贝到主机的当前目录下:
# docker cp ad0ec05e9908:/home/rally/samples/tasks/scenarios/keystone/keystone-create-user.html ./ # ls keystone-create-user.html由于打开Rally的HTML测试报告,会在线调用Google的AngularJS生成报表,因此需要在科学上网的情况下浏览,使用Firfox或者Chrome浏览器打开该HTML文件。如下图所示:
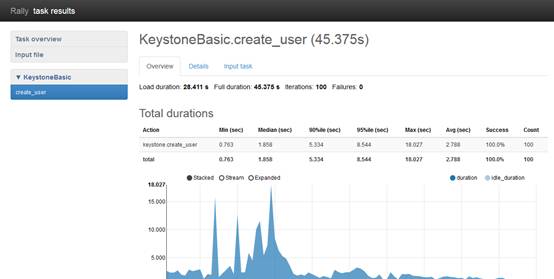
2.如何不科学上网,也能看测试报表
如果,不想在科学上网的情况下,也能浏览HTML测试报表,那该怎么办呢。别急,笔者琢磨出了一个移花接木之法,。——即替换Google的JS框架。
为了能在不科学上网的情况下查看报表,因此下面,我们需要修改源码程序。下面呢,我就分享下吧。
1)切换目录
# cd /usr/lib/python2.7/site-packages/rally2)查找Google的js url路径
# grep googleapis -R .
./ui/templates/task/report.mako:<script type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/angularjs/1.3.3/angular.mins"></script>./ui/templates/verification/report.mako:<script type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jqueryin.js"></script>3)替换 googleapis
# vim ./ui/templates/verification/report.mako
## -*- coding: utf-8 -*-
<%inherit file="/base.mako"/>
<%block name="title_text">Tempest report</%block>
<%block name="libs">
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/jquery/2.1.4/jquery.min.js"></script>
</%block>
# vim ./ui/templates/task/report.mako
## -*- coding: utf-8 -*-
<%inherit file="/base.mako"/>
<%block name="html_attr"> ng-app="BenchmarkApp"</%block>
<%block name="title_text">Benchmark Task Report</%block>
<%block name="libs">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/nvd3/1.1.15-beta/nv.d3.min.css">
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/angular.js/1.3.15/angular.min.js"></script>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.4.13/d3.min.js"></script>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/nvd3/1.1.15-beta/nv.d3.min.js"></script>
</%block>4)OK,这样以后我们再次运行Rally测试时,就可以不用科学上网,也能直接查看测试出来的报表了。
四.保存和使用Rally Docker
1)保存Rally Docker镜像
当我们制作好了Rally镜像之后,如果不做commit保存起来,那么container停止以后再启动,这些更改就消失了。在完成操作之后,输入 exit命令来退出这个容器。
# exitExit现在,我们可以使用 docker commit 来保存镜像。
# docker commit -m="OpenStack Rally Docker" -a="Xu chao" 8e9cce8d1d71 openstack/rally:v1这里的-m标识我们指定提交的信息,-a标识来指定一个作者,openstack/rally是一个新的镜像名,v1是版本号。
现在,我们可以使用 docker images 命令来查看我们的新镜像openstack/rally。
# docker images2)使用我们的新镜像来运行Rally docker
# docker run -i -t openstack/rally:v1 /bin/bash[root@3d6864153dc0 /]# exitexit3)最后,我们使用docker save 命令将镜像导出到本地文件,默认目录为执行docker命令的用户家目录下。
# docker save -o rally_centos7.tar openstack/rally:v1# lsrally_centos7.tar4)当我们把自己做好的镜像上传到Docker Hub公共库或内部私有库中后,别人便可以直接导入镜像,离线使用了。
# docker load < rally_centos7.tar5)将镜像推送到Docker Hub上
由于,上传的镜像必须以docker hub注册的用户名开头,因此这里,我需要重新命名镜像。
# docker commit ad0ec05e9908 xiaoxu780/openstack_rally33c3c6cf1641a57e22df645387d1bfc74fb4ac011c17896f2e1d044f56116eb9查看本地有哪些镜像
# docker imagesREPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
xiaoxu780/openstack_rally latest 33c3c6cf1641 26 seconds ago 635.9 MB
openstack/rally v1 abb601c4cc96 21 hours ago 635.9 MB
docker.io/centos 7 eeb3a076a0be 5 days ago 196.7 MB选择推送的镜像
# docker push xiaoxu780/openstack_rallyDo you really want to push to public registry? [y/n]: y The push refers to a repository [docker.io/xiaoxu780/openstack_rally] (len: 0)
Sending image list
Pushing repository docker.io/xiaoxu780/openstack_rally (1 tags)
…………最后,登录Docker Hub 查看或搜索上传成功的xiaoxu780/openstack_rally镜像。
五、安装Rally的方式
1.单独安装
最简单的安装Rally的方式就是通过它的安装脚本进行安装。
# wget -q -O- https://raw.githubusercontent.com/openstack/rally/master/install_rally.sh | bash安装脚本会检测Rally所需要的软件是否已经安装在系统中;如果是以 root 用户执行而其中的一些依赖没有安装,那么脚本会询问您是否想要安装这些所需要的包。
默认情况下,当以标准用户执行时会将 Rally 安装到 ~/rally 目录下的一个虚拟环境中,或以 root 用户执行则安装到整个系统中。您可以使用 –target 选项将 Rally 安装到一个虚拟环境中:
# ./install_rally.sh --target /foo/bar您也可以以 root 用户执行脚本,不使用 –target 选项,而把 Rally 安装到整个系统中:
# ./install_rally.sh安装完成后,您还可以配置Rally的数据库(可选):
# rally-manage db recreate2.通过DevStack 安装
DevStack除了可以安装OpenStack、Tempest等之外,当然还可以安装 Rally。首先,克隆对应的仓库代码:
# git clone https://git.openstack.org/openstack-dev/devstack# git clone https://github.com/openstack/rally然后,配置 DevStack 以运行 Rally:
# cd devstack# cp samples/local.conf local.conf# echo "enable_service rally" >> local.conf最后,只需要运行 DevStack 即可:
$ ./stack.sh3.通过 Docker安装和使用
即是本篇所做内容。
SDCC 2016 数据库&架构技术峰会(深圳站)将于4月22日-23日举行,讲师和议题已全部确认。目前6折限时报名,详情请扫描下方二维码图。点击原文链接访问官网。
以上是关于如何使用OpenStack,Docker和Spark打造一个云服务的主要内容,如果未能解决你的问题,请参考以下文章
如何使用OpenStack,Docker和Spark打造一个云服务