用于量子计算机的深度卷积神经网络
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用于量子计算机的深度卷积神经网络相关的知识,希望对你有一定的参考价值。
参考技术A
量子计算机将用于什么用途?量子计算机有望在许多领域帮助解决难题,包括机器学习。
本文详细讲述 量子计算机 上 卷积神经网络 (CNN)的理论实现。我们将此算法称为 QCNN ,我们证明了它可以比CNN 更快 地运行,并且精度 很高 。
为此,我们必须提出 卷积积 的 量子形式 ,找到实现非线性和池化的方法,以及对 表示图像 的 量子态 进行层析成像的新方法,以 保留有意义的信息 。
简而言之,我们可以说 量子物理系统可以描述为 维度为2^n的某些希尔伯特空间中的 向量 ,其中n是粒子数。实际上,这些向量表示许多可能的观察结果的叠加。
另一方面,机器学习,尤其是神经网络,正在粗略地使用向量和矩阵来理解或处理数据。 量子机器学习(QML)旨在使用量子系统对向量进行编码,并使用新的量子算法对其进行学习 。一个关键的概念是在许多矢量上使用量子叠加,我们可以同时处理它们。
我不会更深入地介绍量子计算或QML。有关更多详细信息,可以参考NeurIPS 2019中有关 Quantum k-means的 一篇文章 :
卷积神经网络(CNN)是一种流行且高效的神经网络,用于图像分类,信号处理等。在大多数层中,将 卷积积 应用于图像或张量的输入上。通常后面是 非线性层和池化层 。
3D张量输入X ^ 1(RGB图像)和4D张量内核K ^ 1之间的卷积。
在本章中,我将重点介绍一层,解释什么是量子CNN。
这里的核心思想是我们可以根据矩阵乘法来重新构造卷积积。
该算法首先以量子叠加方式加载矩阵的 所有行和列 。然后,我们使用先前开发的 Quantum Inner Product Estimation估算 输出的每个像素。在实践中,这就像只计算一个输出像素(图中的红点),但是以 量子叠加的方式进行计算可以使它们同时全部都具有 !然后,我们可以同时对它们中的每一个应用非线性。
不幸的是,我们所拥有的只是一个量子状态,其中所有像素并行存在,并不意味着我们可以访问所有像素。如果我们打开"量子盒"并查看结果(一个度量),我们 每次都会随机地只看到一个输出像素 。在打开盒子之前,这里都有"四处漂浮"的东西,就像著名的薛定谔的死活猫。
为了解决这个问题,我们引入了一种 只检索最有意义的像素的方法 。实际上,量子叠加中的每个输出像素都有一个幅度,与我们测量系统时 被看到 的幅度有关。在我们的算法中,我们强制此幅度等于像素值。 因此,具有高值的输出像素更有可能被看到。
在CNN中,输出中的高值像素非常重要。它们代表输入中存在特定模式的区域。通过了解不同模式出现的位置,神经网络可以理解图像。因此,这些 高价值像素承载着有意义的信息 ,我们可以舍弃其他希望CNN适应的 像素 。
图像上量子效应(噪声,随机性,采样)的小示例。凭直觉,我们仅对高值像素采样后仍可以"理解"图像。
请注意,在对这些输出像素进行采样时,我们可以在存储它们时应用任何类型的 合并 (有关技术细节,请参见论文)。我们将这些像素存储在经典内存中,以便可以将它们重新加载为 下一层的 输入。
传统上,CNN层需要时间 Õ( 输出大小 x 内核大小 ) 。这就是为什么例如使用许多大内核来训练这些网络变得昂贵的原因。我们的 量子CNN 需要时间 为O( ( σ X 输出大小) X Q) ,其中 σ 是我们从输出(<1)绘制样品的比率,和 Q 表示量子精度参数和数据相关的参数一束。有 没有在内核大小更依赖 (数量和尺寸),这可能允许进行更深入的CNN。
通过量子CNN的这种设计,我们现在也想用量子算法对其进行训练。训练包括遵循梯度下降规则更新内核参数。在这里也可以找到一种更快的量子算法,它几乎等同于具有某些额外误差的通常的梯度下降。
QCNN和量子反向传播看起来不错,但暗示了很多近似,噪声和随机性。尽管有这些伪像,CNN仍然可以学习吗?我们比较了小型经典CNN的训练和QCNN在学习对手写数字进行分类(MNIST数据集)的任务上的模拟。这表明 QCNN可以以相似的精度学习 。
量子和经典CNN训练曲线之间的比较。 σ 是从每一层后的输出提取的高值像素的比率。期望 σ 太小,QCNN可以很好地学习。请注意,此数值模拟很小,只能给出直觉,不是证明。
在这项工作中,我们设计了第一个量子算法,通过引入量子卷积乘积和检索有意义的信息的新方法,几乎可以重现任何经典的CNN体系结构。它可以允许使用更深,更大的输入或内核来大大加快CNN的速度。我们还开发了量子反向传播算法,并模拟了整个训练过程。
请读者思考的问题:我们可以在其他数据集使用大型架构上训练QCNN吗?
VGG:用于大规模图像识别的超深卷积网络
Abstract
main contribution:使用非常小的卷积滤波器(3x3)增加网络的深度,通过将深度推到16-19层,显著提升了网络的效果
achievement:在2014年ImageNet挑战赛上面分别获得定位和分类的第一名和第二名,可以很好的推广到其它数据集
Convnet Configuration
Input:224 x 224 RGB图像,预处理是每个像素减去通过训练集计算的平均RGB值
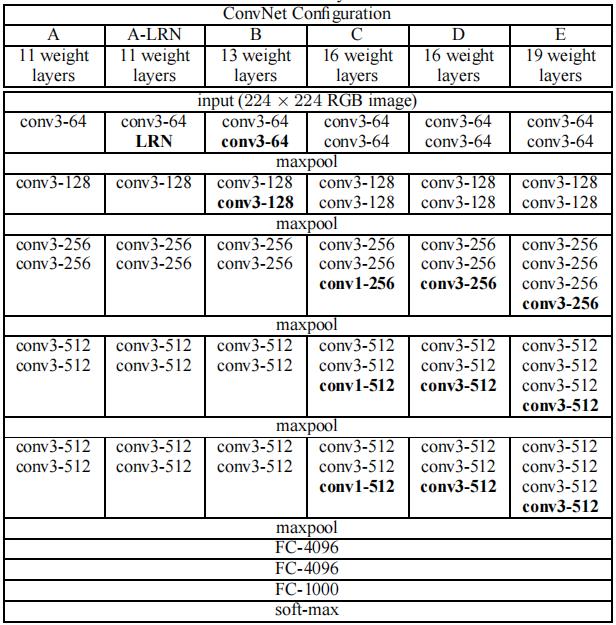
通过将一个7x7的卷积层替换为3个3x3的卷积层,有两个好处。第一,加入了三个线性层而不是一个单一的层,使得决策函数更具有鉴别性。其次,减少了参数的数量,假设3个3x3的卷积层,输入输出都是C通道,一共有3*(3*3*C*C) = 27C^2个参数。但是对于一个7x7的卷积层,一共有49C^2个参数。
Classification Experiments
Conclusion
网络结构非常简单,整个网络都使用了相同大小的卷积核(3x3)和最大池化尺寸(2x2),减少了网络参数,但是仍然会导致占用很多内存。可以根据论文里面的网络配置进行复现,也可以直接调用torchvision里面的模型,如下所示:
class VGG(nn.Module):def __init__(self, features, num_classes=1000, init_weights=True):super(VGG, self).__init__()self.features = featuresself.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes),)if init_weights:self._initialize_weights()def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def make_layers(cfg, batch_norm=False):layers = []in_channels = 3for v in cfg:if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)if batch_norm:layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]else:layers += [conv2d, nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)cfgs = {'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],}def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):if pretrained:kwargs['init_weights'] = Falsemodel = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)if pretrained:state_dict = load_state_dict_from_url(model_urls[arch],progress=progress)model.load_state_dict(state_dict)return modeldef vgg16(pretrained=False, progress=True, **kwargs):r"""VGG 16-layer model (configuration "D")`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)def vgg16_bn(pretrained=False, progress=True, **kwargs):r"""VGG 16-layer model (configuration "D") with batch normalization`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
以上是关于用于量子计算机的深度卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章
DL笔记|使用卷积神经网络构建转录因子结合位点预测模型(deepbind)