java实现多表的自定义查询。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java实现多表的自定义查询。相关的知识,希望对你有一定的参考价值。
现在有很多张表,在页面上显示所有表的属性,用户可以根据自己的需要选择想要的字段进行显示,并选择一些属性进行条件过滤。表与表之间有些存在关系,有些不存在关系。怎样在后台拼接sql语句,根据用户的选择从数据库拉选出用户自定义的数据。
现在你是不知道用户选了那些要显示的属性字段,哪些条件字段,所以在后台怎样进行表连接拼接sql语句是个头疼的问题。
大概是下图的样子:
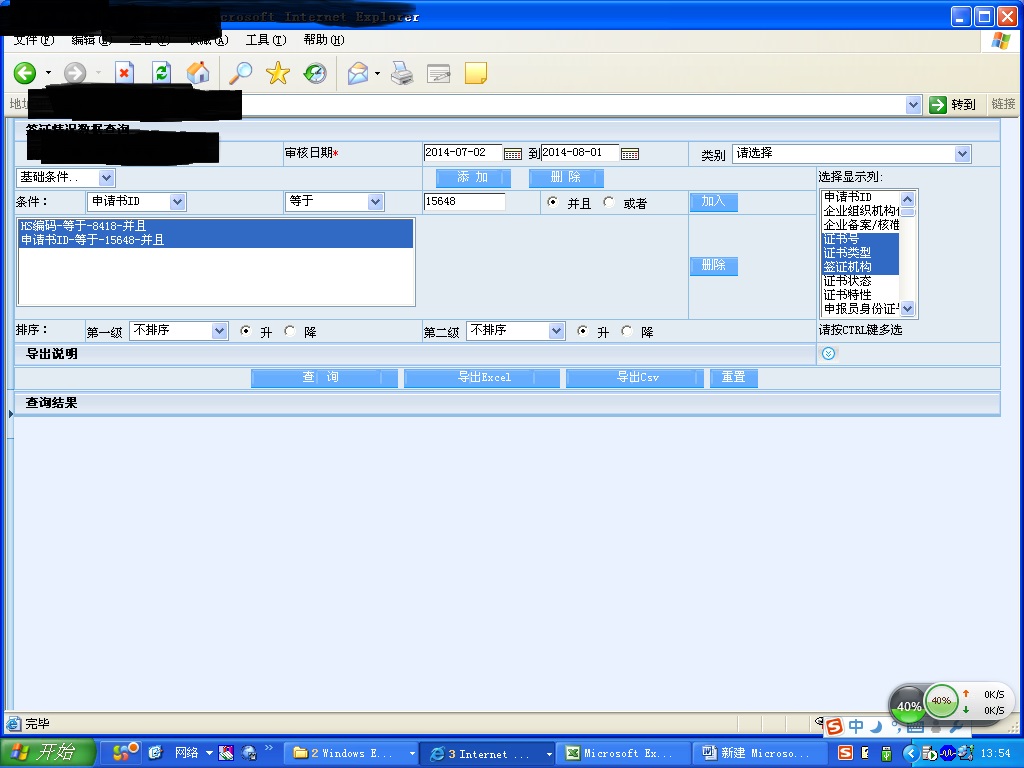
from 前台用户选择要查询的表(T1) 别名 [,T2,T3]
[
连接关系(内连,左连)(inner join, left join) 表(T2) on
连接条件(表1别名.列名=表2别名.列名)
]
where 1=1 and [查询条件(表1别名.列名=xxx,...)]
[order by 表1别名.列名]
PS:方括号的内容为可选
补充回答:
怎么会不知道用户选了什么列呢?比如图中选了证书号,证书类型,签证机构,它选中肯定会对应一个值的,把这个值设成列名不就可以直接拼接了吗 参考技术A 你是要做一个通用的页面,不需要为每个表定制页面,用来显示表中的所有数据行是吧? 参考技术B 多表查询,只有有关系的才能一起吧。。。。。你可以贴出来看下撒。追问
现在你是不知道用户选了那些要显示的属性字段,哪些条件字段,所以在后台怎样进行表连接拼接sql语句是个头疼的问题。
多对多表的增删改查与drf的分页
类的约束
继承 必须继续 定义 不然报错
# 约束子类中必须实现f1 class Base(object):
def f1(self):
raise NotImplementedError('必须要定义此规则')
class Foo(Base):
def f1(self):
print(123)
obj = Foo()
obj.f1()面向对象的继承
class Base(object):
def f1(self):
print('base.f1')
self.f2()
def f2(self):
print('base.f2')
class Foo(Base):
def f2(self):
print('foo.f2')
obj = Foo()
obj.f1()class Base(object):
x1 = 123
def f1(self):
print(self.x1)
class Foo(Base):
x1 = 456
obj = Foo()
obj.f1()class APIView(object):
version_class = 123
def get_version(self):
print(self.version_class)
class UserView(APIView):
version_class = 666
obj = UserView()
obj.get_version()class APIView(object):
version_class = 123
def dispatch(self,method):
self.initial()
getattr(self,method)()#反射
def initial(self):
print(self.version_class)
class UserView(APIView):
version_class = 666
def get(self):
print('userview.get')
obj = UserView()
obj.dispatch('get')
结果
print(self.version_class)
print('userview.get')class URLPathVersion(object):
def determin_version(self):
return 'v1'
class APIView(object):
version_class = None
def dispatch(self,method):
version = self.initial()
print(version)
getattr(self,method)()
def initial(self):
self.process_version()
def process_version():
obj = self.version_class()
return obj.determine_version()
class UserView(APIView):
version_class = URLPathVersion
def get(self):
print('userview.get')
obj = UserView()
obj.dispatch('get')处理 多对多实列
查询 单条或多条
modul
from django.db import models
class Category(models.Model):
"""
文章分类
"""
name = models.CharField(verbose_name='分类',max_length=32)
class Article(models.Model):
"""
文章表
"""
status_choices = (
(1,'发布'),
(2,'删除'),
)
status = models.IntegerField(verbose_name='状态',choices=status_choices,default=1)
title = models.CharField(verbose_name='标题',max_length=32)
summary = models.CharField(verbose_name='简介',max_length=255)
content = models.TextField(verbose_name='文章内容')
category = models.ForeignKey(verbose_name='分类',to='Category')
tag = models.ManyToManyField(verbose_name='标签',to='Tag',null=True,blank=True)
class Tag(models.Model):
"""标签"""
title = models.CharField(verbose_name='标签',max_length=32)
url
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^new/article/$', views.NewArticleView.as_view()),
url(r'^new/article/(?P<pk>d+)/$', views.NewArticleView.as_view()),
]约束 展示
class NewArticleSerializer(serializers.ModelSerializer):
tag_info = serializers.SerializerMethodField()
class Meta:
model = models.Article
# fields = '__all__' #会自动展示
fields = ['title','summary','tag_info']#自定义显示 必须自己加 tag_info
def get_tag_info(self,obj):#展示的第3种方法 obj对象
return [row for row in obj.tag.all().values('id','title')]#字典加列表的形式
obj.字段.all().values('要显示的字段1','要显示的字段2')view
class NewArticleView(APIView):
def get(self,request,*args,**kwargs):
pk = kwargs.get('pk')
if not pk:
queryset = models.Article.objects.all()
ser = serializer.NewArticleSerializer(instance=queryset,many=True)
return Response(ser.data)
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.NewArticleSerializer(instance=article_object, many=False)
return Response(ser.data)
def post(self,request,*args,**kwargs):
ser = serializer.FormNewArticleSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def put(self, request, *args, **kwargs):
"""全部更新"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object, data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def patch(self,request,*args,**kwargs):
"""局部"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object, data=request.data,partial=True)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def delete(self,request,*args,**kwargs):
pk = kwargs.get('pk')
models.Article.objects.filter(id=pk).delete()
return Response('删除成功')
增加 编辑 更新
要注意的是 约束 可以用不一样的 为了避免展示与增加不一样
约束
class FormNewArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = '__all__'
增加 编辑必须为 __all__view
class NewArticleView(APIView):
def post(self,request,*args,**kwargs):
"""增加"""
ser = serializer.FormNewArticleSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def put(self, request, *args, **kwargs):
"""全部更新"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object, data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def patch(self,request,*args,**kwargs):
"""局部"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object, data=request.data,partial=True)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def delete(self,request,*args,**kwargs):
pk = kwargs.get('pk')
models.Article.objects.filter(id=pk).delete()
return Response('删除成功')
总结
根据业务需求不同 所以 serializers可以写多个 来应对分页器
为什么要使用分页
其实这个不说大家都知道,大家写项目的时候也是一定会用的,
我们数据库有几千万条数据,这些数据需要展示,我们不可能直接从数据库把数据全部读取出来,
这样会给内存造成特别大的压力,有可能还会内存溢出,所以我们希望一点一点的取,
那展示的时候也是一样的,总是要进行分页显示,我们之前自己都写过分页。
那么大家想一个问题,在数据量特别大的时候,我们的分页会越往后读取速度越慢,
当有一千万条数据,我要看最后一页的内容的时候,怎么能让我的查询速度变快。
DRF给我们提供了三种分页方式,我们看下他们都是什么样的~~
分页组件的使用
DRF提供的三种分页
drf 内置分页器 有几种方式 只有获取多条数据时才有用
方式1
定义配置文件settings
REST_FRAMEWORK = {
"PAGE_SIZE":2,#代表2
}modul
原来的
url
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
# 分页
url(r'^page/article/$', views.PageArticleView.as_view()),
url(r'^page/view/article/$', views.PageViewArticleView.as_view()),
]
view
from rest_framework.pagination import PageNumberPagination
from rest_framework.pagination import LimitOffsetPagination
from rest_framework import serializers
class PageArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset = models.Article.objects.all()
# 方式一:仅数据
#分页对象
page_object = PageNumberPagination()
# 调用 分页对象.paginate_queryset方法进行分页,得到的结果是分页之后的数据
# result就是分完页的一部分数据
result = page_object.paginate_queryset(queryset,request,self)
# 序列化分页之后的数据
ser = PageArticleSerializer(instance=result,many=True)
return Response(ser.data)
方式2
from rest_framework.pagination import PageNumberPagination
from rest_framework.pagination import LimitOffsetPagination
from rest_framework import serializers
class PageArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset = models.Article.objects.all()
# 方式二:数据 + 分页信息
page_object = PageNumberPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return page_object.get_paginated_response(ser.data)
方式3
from rest_framework.pagination import PageNumberPagination#第1种方式
from rest_framework.pagination import LimitOffsetPagination
#第2种方式
from rest_framework import serializers
class PageArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset = models.Article.objects.all()
# 方式三:数据 + 部分分页信息
page_object = PageNumberPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return Response({'count':page_object.page.paginator.count,'result':ser.data})分页的另一种方式
from rest_framework.pagination import PageNumberPagination
from rest_framework.pagination import LimitOffsetPagination
from rest_framework import serializers
class PageArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
#重 定义 防止 一次取过多
class HulaLimitOffsetPagination(LimitOffsetPagination):
max_limit = 20
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset = models.Article.objects.all()
#就是类不同
page_object = HulaLimitOffsetPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return Response(ser.data)分页出现的警告问题 了解
url
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^page/view/article/$', views.PageViewArticleView.as_view()),
]seting
REST_FRAMEWORK = {
"PAGE_SIZE":2,#代表2
"DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination"#为什么要配置
}view
from rest_framework.generics import ListAPIView
class PageViewArticleSerializer(serializers.ModelSerializer):
class Meta: model = models.Article
fields = "__all__"
class PageViewArticleView(ListAPIView):
queryset = models.Article.objects.all()
serializer_class = PageViewArticleSerializer总结
drf 有分页功能 对查询的数据自动分页 有3种方法以上是关于java实现多表的自定义查询。的主要内容,如果未能解决你的问题,请参考以下文章
第七周 Java语法总结之数据库大全_DDL_DML_DQL_约束_备份与还原_表的关系_三大范式_多表查询(内连接_外连接_子查询)_musql事务_隔离级别