MNN源码阅读--Tensor数据结构解析和运行示例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MNN源码阅读--Tensor数据结构解析和运行示例相关的知识,希望对你有一定的参考价值。
参考技术Atensor就是容纳推理框架中间数据的一个数据结构,常用的有关函数如下:
这其中第一个参数是tensor的维度信息,第二个参数是是否指定数据指针,第三个参数是数据在内存中的排布信息,如果是CAFFE证明是NCHW类型,如果是TENSORFLOW证明是NHWC类型,默认的类型是TENSORFLOW类型,这里经常会有一些坑,比如最终想要得到一个1 3 1024*1024的数据时候,如果没有指定是CAFFE类型的数据排布,而是使用默认的情况(TENSORFLOW),读出来的数据channel维度就在最后。
得到各种维度和长度:
得到shape向量和数据总数:
得到数据指针:
Interpreter就是一个MNN的从模型得到的一个网络,有关Interpreter的tenosr操作,肯定就是涉及到输入的tesnor和输出的tensor的设置,由于可能在不同的设备上运行,因此可能有内存拷贝的操作。
获取Interpreter的输入tensor:
获取Interpreter的输出tensor:
将host的tensor数据拷贝给Interpreter的tensor
将Interpreter的tensor数据拷贝给host tensor
OneFlow源码解析:Tensor类型体系与Local Tensor

撰文|郑建华
更新|赵露阳
tensor和op是神经网络模型最基本的组件:op是模型的节点,tensor是连接节点的边。然而,构建一个tensor并不仅仅是构造一个对象那么简单,至少要考虑以下问题:
-
要支持节点本地的local tensor,以及分布式的global tensor;
-
要支持eager和lazy执行模式;
-
要支持不同的数据类型,包括float、double、int等;
-
要支持不同设备。
1
创建tensor的方法
与PyTorch类似,在OneFlow中也可以通过两种主要的方式来创建tensor:Tensor和tensor。这两种方式最终都会创建出OneFlow内部的C++ Tensor对象,即对应Python层的flow.Tensor类型。
1.1 Tensor
Python层的Tensor是在tensor.py(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/python/oneflow/framework/tensor.py#L23)中引入的,通过python c api注册的Tensor类型对象,此对象在MakeTensorType
(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/framework/tensor.cpp#L623)中被定义和返回。
在MakeTensorType中主要通过PyTensorObject_init创建了Tensor对象:
static int PyTensorObject_init(PyObject* self, PyObject* args, PyObject* kwargs)
HANDLE_ERRORS
auto* temp = functional::_legacy_tensor_ctor(NULL, args, kwargs);
if (PyErr_Occurred()) throw py::error_already_set();
auto* _self = (PyTensorObject*)self;
_self->data = PyTensor_Unpack(temp);
_self->data->set_pyobject(self);
// reset temp data to prevent clearing the pyobject
// when the temp is deallocated
((PyTensorObject*)temp)->data.reset();
Py_XDECREF(temp);
return 0;
END_HANDLE_ERRORS_RET(-1)
通过functional::_legacy_tensor_ctor函数创建了OneFlow内部的c++ Tensor对象:oneflow::one::Tensor,并作为data绑定至Python的Tensor类型。在MakeTensorType中,还通过PyMethodDef(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/framework/tensor.cpp#L639-L641)为Tensor注册了很多C++方法,如:
static PyMethodDef PyTensorObject_methods[] =
"storage_offset", PyTensorObject_storage_offset, METH_NOARGS, NULL,
"stride", PyTensorObject_stride, METH_NOARGS, NULL,
"is_contiguous", PyTensorObject_is_contiguous, METH_NOARGS, NULL,
"contiguous", PyTensorObject_contiguous, METH_NOARGS, NULL,
"contiguous_", PyTensorObject_contiguous_, METH_NOARGS, NULL,
"pin_memory", PyTensorObject_pin_memory, METH_NOARGS, NULL,
"is_pinned", PyTensorObject_is_pinned, METH_NOARGS, NULL,
"requires_grad_", (PyCFunction)PyTensorObject_requires_grad_, METH_VARARGS | METH_KEYWORDS,
NULL,
"retain_grad", PyTensorObject_retain_grad, METH_NOARGS, NULL,
"detach", PyTensorObject_detach, METH_NOARGS, NULL,
"clone", PyTensorObject_clone, METH_NOARGS, NULL,
"zero_", PyTensorObject_zero_, METH_NOARGS, NULL,
"register_hook", PyTensorObject_register_hook, METH_O, NULL,
"_register_post_grad_accumulation_hook", PyTensorObject__register_post_grad_accumulation_hook,
METH_O, NULL,
"global_id", PyTensorObject_global_id, METH_NOARGS, NULL,
"check_meta_consistency", PyTensorObject_check_meta_consistency, METH_NOARGS, NULL,
"to_numpy", PyTensorObject_to_numpy, METH_NOARGS, NULL,
"type", (PyCFunction)PyTensorObject_type, METH_VARARGS | METH_KEYWORDS, NULL,此外,在Python层通过RegisterMethods(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/python/oneflow/framework/tensor.py#L502)也为Tensor注册了一些Python实现的Tensor方法或属性(如tensor.numpy),在OneFlow包初始化时会通过RegisterMethod4Class
(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/python/oneflow/framework/register_class_method_util.py#L23)完成这些Python方法和属性的注册。RegisterMethod4Class的调用流程如下:
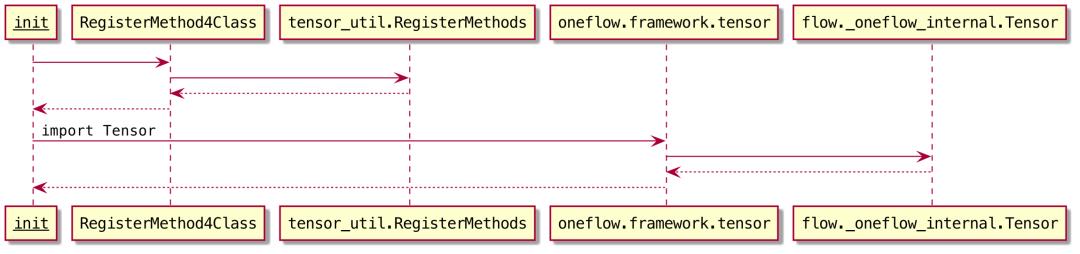
相比于Python实现来说,Tensor的++实现的方法/属性通常具有较高的性能。
1.2 tensor函数
Tensor是类型,而tensor则是函数,flow.tensor函数在oneflow/api/python/functional/tensor_api.yaml中被定义:
- name: "tensor"
signature: [
"Tensor (PyObject* data, *, DataType dtype=None, Device device=None,
Bool requires_grad=False, Bool pin_memory=False) => TensorWithData",
"Tensor (PyObject* data, *, DataType dtype=None, Placement placement,
SbpList sbp, Bool requires_grad=False) => GlobalTensorWithData",
]
bind_python: True其C++实现位于tensor_api.yaml.pybind.cpp中,这是构建阶段自动生成的文件。
通过函数签名可以看到,flow.tensor()有两种重载的方法:
-
TensorWithData
-
GlobalTensorWithData
它们分别用于构造local tensor和global tensor的构造。和上面的Tensor类似,flow.tensor返回的也是OneFlow内部的oneflow::one::Tensor对象(绑定至Python的Tensor对象)。
1.3 手动构建tensor的两种方式
和PyTorch类似,在OneFlow中常用创建tensor的方式也分为两种:
-
flow.Tensor
-
flow.tensor
创建方式示例:
import oneflow
import numpy as np
oneflow.tensor([[1., -1.], [1., -1.]])
# tensor([[ 1., -1.],
# [ 1., -1.]], dtype=oneflow.float32)
oneflow.tensor(np.array([[1, 2, 3], [4, 5, 6]]))
# tensor([[ 1, 2, 3],
# [ 4, 5, 6]], dtype=oneflow.int64)
flow.Tensor([[1,2,3],[4,5,6]])大多数情况下(和PyTorch类似的eager模式),可以通过指定device、dtype、shape等参数创建普通tensor(local tensor);
少数情况下(如OneFlow特有的eager global、lazy模式),需要global tensor时,可以通过指定sbp和placement的方式直接创建global tensor,也可通过tensor.to_global的方式将普通tensor转换为global tensor,可参考:
-
oneflow.tensor
(https://oneflow.readthedocs.io/en/master/generated/oneflow.tensor.html#)
-
global tensor
(https://docs.oneflow.org/master/parallelism/03_consistent_tensor.html)
2
OneFlow的tensor类型体系
上述内容中介绍的oneflow内部的C++ Tensor对象,实际上其定义位于:oneflow/core/framework/tensor.h,是一个抽象的Tensor类型。
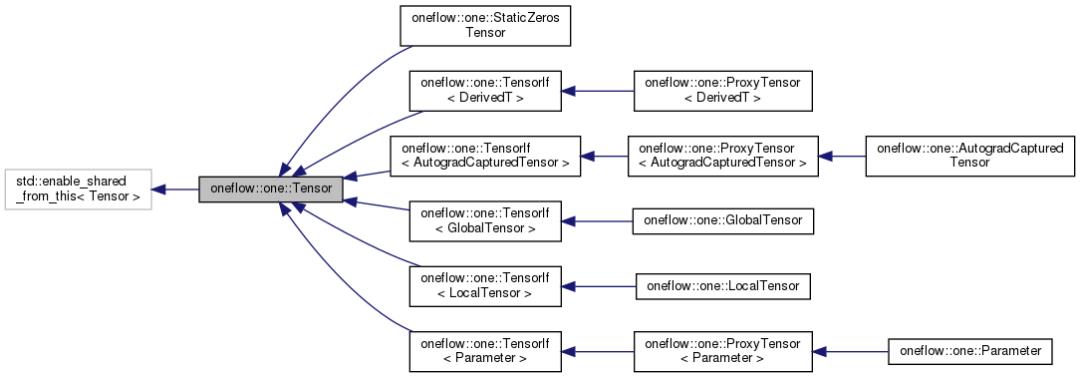
其中LocalTensor即为普通的单卡视角下的Tensor(和PyTorch的Tensor类似);GlobalTensor则为OneFlow所特有的全局视角下的Tensor(通常用于eager global模式或lazy模式下)。Tensor使用了Bridge模式,每个Tensor子类内部有一个TensorImpl字段,负责抽象Tensor的实际实现:
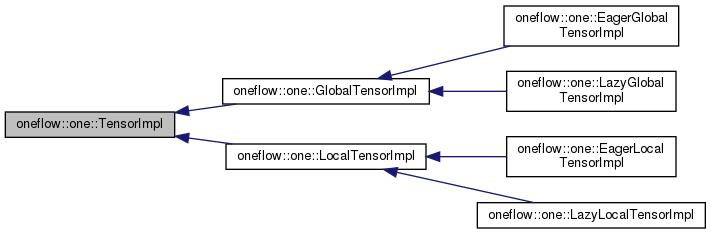
3
local tensor的构造
我们以flow.tensor([[1,2,3],[4,5,6]])为例,看一下tensor构造的过程。主要的流程如下:
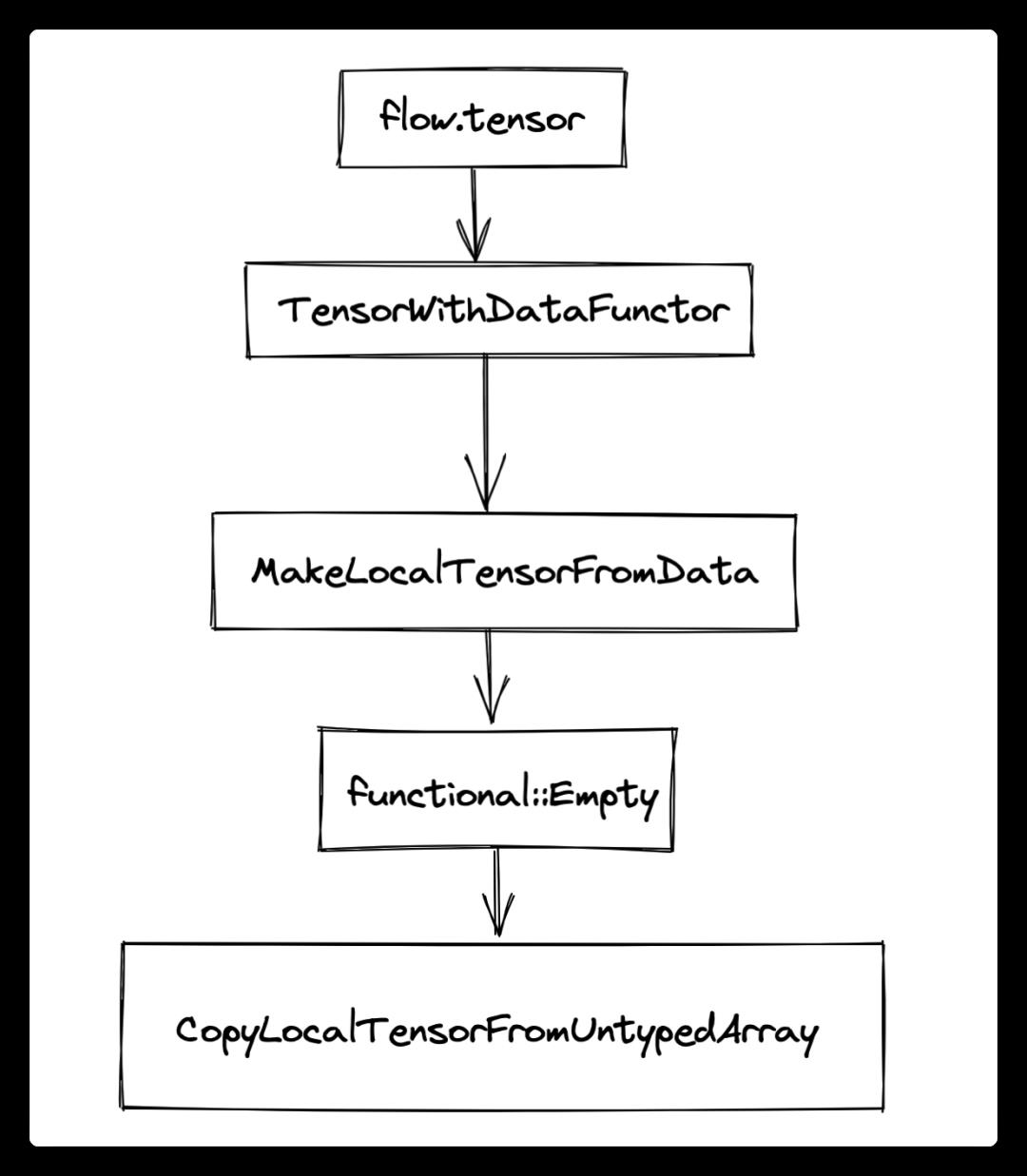
在这个例子中,由于使用的是flow.tensor方法创建tensor(且为普通的local tensor)所以会用到在oneflow/api/python/functional/tensor_api.yaml中定义的TensorWithData方法,其实现,是位于oneflow/api/python/functional/tensor_api.cpp的TensorWithDataFunctor:
class TensorWithDataFunctor
public:
Maybe<Tensor> operator()(PyObject* data, const Optional<Symbol<DType>>& dtype,
const Optional<Symbol<Device>>& device, const bool requires_grad,
const bool pin_memory) const
...
if (PyTensor_Check(data))
// Throw warnings like pytorch.
auto ret = PyErr_WarnEx(
PyExc_UserWarning,
"To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() "
"or sourceTensor.clone().detach().requires_grad_(True), rather than "
"oneflow.tensor(sourceTensor).",
1);
if (ret != 0) return Error::RuntimeError();
const auto& other = PyTensor_Unpack(data);
return MakeTensorFromOtherTensor(other, dtype, device, requires_grad, pin_memory);
else
// Make tensor from python sequence or numpy array.
return MakeLocalTensorFromData(data, dtype, device, requires_grad, pin_memory);
;由于这里传入的data是一个Python的list对象,所以最终会调用MakeLocalTensorFromData方法,创建tensor主要的逻辑都在这个函数中。其中大量调用Python和Numpy的接口,检查PyObject的数据类型,获取Shape
(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L184)和DataType(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L185),如果用户没有制定device,默认会设置为CPU设备(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L191)。
后面主要是调用EmptyFunctor
(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L194)和SwitchCopyLocalTensorFromUntypedArray(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L195)。前者为tensor分配内存,后者进行数据拷贝,两个步骤都会通过虚拟机指令完成。其中EmptyFunctor会走普通的OpCall指令、而CopyLocalTensorFromUntypedArray会根据是否需要同步copy走到AccessBlobByCallback/SyncAccessBlobByCallback指令。
为什么要通过虚拟机指令完成呢?无论是内存资源的分配,还是数据拷贝,CPU和CUDA等不同设备上的操作都不一样。之前讨论Op/Kernel时已经看到,在OneFlow中所有动静态图任务执行、eager模式下op/kernel执行、内存/显存的分配和释放、device、stream等统一由虚拟机进行管理。
3.1 分配内存:EmptyFunctor
matmul和relu(inplace=false时)等操作在执行过程中也会创建output tensor。之前讨论relu时重点关注了op和kernel的计算逻辑,而忽略了tensor相关的内容。
而这里只需要先构造一个空tensor对象,不需要其它计算,所以是一个Empty操作,Empty op对应的kernel——EmptyKernel(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/user/kernels/empty_kernel.cpp#L30)没有实质性的计算逻辑,只是先根据shape、dtype、device信息创建一个空tensor,等待后续将实际的数据从内存中copy至此空tensor,从而完成整个tensor的创建过程。
EmptyFunctor同样和其他functor一样,最终会被Dispacth至对应的interpreter被解释执行,这里由于是eager模式下的local tensor,EmptyFunctor最终会进入eager local interpreter,交给NaiveInterpret(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/framework/op_interpreter/eager_local_op_interpreter.cpp#L74)方法处理。流程如下:
1. 在构造EagerLocalTensorImpl(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/framework/op_interpreter/eager_local_op_interpreter.cpp#L110)对象,用于存放tensor结果。但这只是一个壳子,还没有为tensor的数据分配存储空间。
2. 之后会初始化EagerBlobObject(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/framework/op_interpreter/eager_local_op_interpreter.cpp#L114)、TensorStorage(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/framework/tensor_impl.cpp#L120),这样tensor主要的字段基本构建完毕
3. 然后构造OpCall指令、提交虚拟机PhysicalRun(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/framework/op_interpreter/eager_local_op_interpreter.cpp#L134-L136),等待vm的调度执行。
OpCall对应的指令策略最终会进入oneflow/core/vm/op_call_instruction_policy.cpp,并在Prepare方法中通过AllocateOutputBlobsMemory方法对TensorStorage完成实际的内存分配;在Compute方法中启动(empty op对应的)实际的kernel执行。
3.2 拷贝数据:SwitchCopyLocalTensorFromUntypedArray
SwitchCopyMirroredTensorFromUntypedArray其实是MAKE_SWITCH_ENTRY(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L150)宏展开后的函数名。宏展开后的代码如下。实际会调用CopyLocalTensorFromUntypedArray(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.cpp#L68)。
template<typename... Args>
static Maybe<void> SwitchCopyLocalTensorFromUntypedArray(
const std::tuple<DataType>& switch_tuple, Args&& ... args)
static const std::map<std::tuple<DataType>, std::function<Maybe<void>(Args && ...)>>
case_handlers
SwitchCase(DataType::kFloat),
[](Args&&... args)
return CopyLocalTensorFromUntypedArray<float>(std::forward<Args>(args)...);
,
// ...
;
return case_handlers.at(switch_tuple)(std::forward<Args>(args)...);
;CopyLocalTensorFromUntypedArray方法如下:
template<typename T>
Maybe<void> CopyLocalTensorFromUntypedArray(const std::shared_ptr<Tensor>& tensor,
PyObject* array)
return CopyBetweenLocalTensorAndNumpy<T>(tensor, array, CopyFromNumpyArray, "mut",
/*block_host_until_done=*/false);
其内部实际调用了CopyBetweenLocalTensorAndNumpy方法。
CopyBetweenLocalTensorAndNumpy
顾名思义,这个方法主要是用在numpy和tensor之间进行数据copy的。其中第3个参数:CopyFromNumpyArray实际是一个函数回调的callback方法,其主要通过SyncAutoMemcpy进行array和tensor(blob)之间的内存拷贝:
void CopyFromNumpyArray(ep::Stream* stream,
const std::shared_ptr<vm::EagerBlobObject>& eager_blob_object,
const NumPyArrayPtr& array_ptr)
SyncAutoMemcpy(stream, eager_blob_object->mut_dptr(), array_ptr.data(),
eager_blob_object->ByteSizeOfBlobBody(), eager_blob_object->mem_case(),
memory::MakeHostMemCase());
继续看CopyBetweenLocalTensorAndNumpy(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/api/python/utils/tensor_utils.h#L93)方法,其中最关键的是:
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void>
return builder->AccessBlobByCallback(
tensor,
[array_ptr, Copy](ep::Stream* stream,
const std::shared_ptr<vm::EagerBlobObject>& eager_blob_object)
Copy(stream, eager_blob_object, array_ptr);
,
modifier);
));通过InstructionsBuilder构建了AccessBlobByCallback指令,参数为上面通过EmptyFuncor创建的空tensor、callback的函数指针及参数、以及modifier(string "mut"表示可动态修改)。
AccessBlobByCallback
和OpCall类似,InstructionsBuilder调用AccessBlobByCallback时,也会实际构造对应的vm指令策略——AccessBlobArgCbInstructionPolicy并派发至vm,等待被调度和实际执行:
template<typename T>
Maybe<void> InstructionsBuilder::AccessBlobByCallback(
const T tensor,
const std::function<void(ep::Stream*, const std::shared_ptr<vm::EagerBlobObject>&)>& callback,
const std::string& modifier)
const std::shared_ptr<vm::EagerBlobObject>& eager_blob_object = JUST(tensor->eager_blob_object());
Symbol<Device> device = JUST(GetDevice(tensor));
...
Symbol<Stream> stream = JUST(GetDefaultStreamByDevice(device));
JUST(SoftSyncStream(eager_blob_object, stream));
auto instruction = intrusive::make_shared<vm::Instruction>(
// Never replace `stream` with producer_stream or last_used_stream.
JUST(Singleton<VirtualMachine>::Get()->GetVmStream(stream)),
std::make_shared<vm::AccessBlobArgCbInstructionPolicy>(eager_blob_object, callback,
modifier));
instruction_list_->EmplaceBack(std::move(instruction));
return Maybe<void>::Ok();
等该条AccessBlobArgCbInstructionPolicy指令实际执行时,会在指令的Compute(https://github.com/Oneflow-Inc/oneflow/blob/2e6a72c8734b9929191306df35b4284e9caa8126/oneflow/core/vm/access_blob_arg_cb_instruction_policy.h#L79)方法中调用callback完成从tensor的blob <-> numpy的ndarray之间的数据copy,至此拷贝过程结束,flow.tensor的创建全部完成。
(本文经授权后发布。原文:
https://segmentfault.com/a/1190000041989895)
参考资料
-
OneFlow源码:https://github.com/Oneflow-Inc/oneflow
其他人都在看
 https://github.com/Oneflow-Inc/oneflow
https://github.com/Oneflow-Inc/oneflow以上是关于MNN源码阅读--Tensor数据结构解析和运行示例的主要内容,如果未能解决你的问题,请参考以下文章
OneFlow源码解析:Tensor类型体系与Local Tensor