OneFlow源码解析:Global Tensor
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OneFlow源码解析:Global Tensor相关的知识,希望对你有一定的参考价值。

撰文 | 郑建华
更新|赵露阳
上文中讲到的类似于PyTorch中的普通Tensor,在OneFlow中称为Local Tensor。Local Tensor是单卡视角下的普通Tensor。与之相对,OneFlow中还有一个独有的概念——Global Tensor。
Global Tensor是指被placement和SBP属性所指定的,一个全局视角下的逻辑Tensor。Global Tensor的shape是逻辑形状,其真实数据根据placement和SBP的规则分布在多个rank上。
Global Tensor既可以通过普通的Local Tensor通过tensor.to_global()转换得到,也可以直接用数据或Numpy来构造。
下面的小节将通过一个示例(https://docs.oneflow.org/master/parallelism/03_consistent_tensor.html),
展示从普通数据构造Global Tensor的过程,以及分别描述SBP、Placement和Global Tensor构造的细节。
1
Global Tensor示例
开启2个终端,终端一、二分别设置环境变量:
# 终端一
export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=0 LOCAL_RANK=0
# 终端二
export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=1 LOCAL_RANK=1终端一、二分别执行相同代码:
import oneflow as flow
p = flow.placement("cpu", ranks=[0, 1])
sbp = flow.sbp.split(0)
x = flow.tensor([[1,2,3],[4,5,6]], placement=p, sbp=sbp)
print(x.shape)
print(x.to_local())终端一、二的输出如下:
# 终端一
oneflow.Size([2, 3])
tensor([[1, 2, 3]], dtype=oneflow.int64)
# 终端二
oneflow.Size([2, 3])
tensor([[4, 5, 6]], dtype=oneflow.int64)这个例子中:
export xxx环境变量告诉oneflow环境用于通信的IP和Port,以及全局共有2个rank(WORLD_SIZE=2),终端一所在的是rank0,终端二所在的是rank1。
p = flow.placement("cpu", ranks=[0, 1])设置了global tensor将会被放置于rank0和rank1。
sbp = flow.sbp.split(0)设置了global tensor的sbp属性为split,即按第0维度进行切分。
x = flow.tensor([[1,2,3],[4,5,6]], placement=p, sbp=sbp)从python list数据配合sbp和placement构造了一个global tensor x。
这里,x是由[[1,2,3],[4,5,6]]构造而来,其shape为(2,3),所以我们print(x.shape)得到的是:oneflow.Size([2, 3]),x是一个global tensor,其shape表示全局范围内的逻辑形状。
然后,在特定rank上执行x.to_local()表示将global tensor转为当前rank上的local tensor,由于x的sbp是split(0),表示tensor按第0维切分,即[1,2,3]存放于rank0;[4,5,6]存放于rank1。
所以,print(x.to_local())得到终端一的输出为:
tensor([[1, 2, 3]], dtype=oneflow.int64)
终端二的输出为:
tensor([[4, 5, 6]], dtype=oneflow.int64)
当然,上述只是一个小例子,用于理解global tensor以及sbp和placement属性的概念,真实应用场景下,通常都会直接用local tensor通过tensor.to_global(https://oneflow.readthedocs.io/en/master/generated/oneflow.Tensor.to_global.html?highlight=to_global)的方式,来创建global tensor并使用。
2
SBP
SBP由split, broadcast, partial的首字母组合而成,SBP是一种规则,其描述了逻辑tensor(global tensor)在物理设备上的分布策略。
split表示global tensor在各个rank(物理设备)都存在分片,每个分片可以看作是将global tensor沿着某一维度切分得到的本rank分量(rank由placement指定)。
broadcast表示global tensor在每个rank上完全一样,等价于从某个rank复制并广播至所有rank。
partial表示global tensor与物理设备上的tensor的形状相同,但是物理设备上的值,只是global tensor的一部分,global tensor的值需要这些rank上的local tensor进行 sum、max、mean等类似操作。
Python端flow.sbp
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/python/oneflow/sbp.py)
包定义了split等3种类型。其C++ binding代码在sbp_symbol.cpp(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/sbp_symbol.cpp#L106-L108)中。这些类型都是SbpParallel(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/sbp_parallel.proto#L57)类型,是protobuf message对象。三种类型通过oneof parallel_type(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/sbp_parallel.proto#L58)共享存储。
其中broadcast和partial_sum都是空消息,赋值时需要调用mutable方法
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/sbp_parallel.cpp#L83)显式表明oneof字段具体是哪种类型。split的值表示在tensor的哪个轴上切分数据。轴的index值是一个[[0, 5]之间的整数]。所有的split SbpParallel对象被保存到一个静态vector
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/sbp_symbol.cpp#L47)中。
3
Placement的构造
placement属性指定逻辑tensor实际存放在哪些物理设备上,更具体的,是存放于哪些rank上。
在上述例子中:
flow.placement("cpu", ranks=[0, 1])创建了一个placement对象。第一个参数是设备类型,目前支持cpu或cuda。ranks[0, 1]表示tensor分布在rank 0和rank1上。
sbp = flow.sbp.split(0)表明tensor的数据分布是按split切分,且是沿着第0维进行切分。
ranks只列出了rank id(全局唯一),没有指定节点host。是因为rank与host关系已经根据环境变量所确定。环境变量RANK表示全局唯一的rank id,LOCAL_RANK表示节点内的本地rank id。在GPU环境下,一般一个进程对应一块设备(https://docs.oneflow.org/master/parallelism/04_launch.html#_1)。WORLD_SIZE表示所有节点的设备(进程)总数。
在通过import oneflow初始化oneflow时,会根据环境变量在各个节点间建立控制面通信连接(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/env_global_objects_scope.cpp#L173-L175),以及数据面通信连接。这样每个进程就知道有多少个节点、有多少个设备/进程、当前进程在整个集群的位置。
通过placement的构造函数绑定(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/placement_symbol.cpp#L202)可以知道,其对应的C++类型是ParallelDesc
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/parallel_desc.h#L42)。对象构造由函数CreateParallelDescSymbol(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/placement_symbol.cpp#L154)完成。主要调用流程如下:
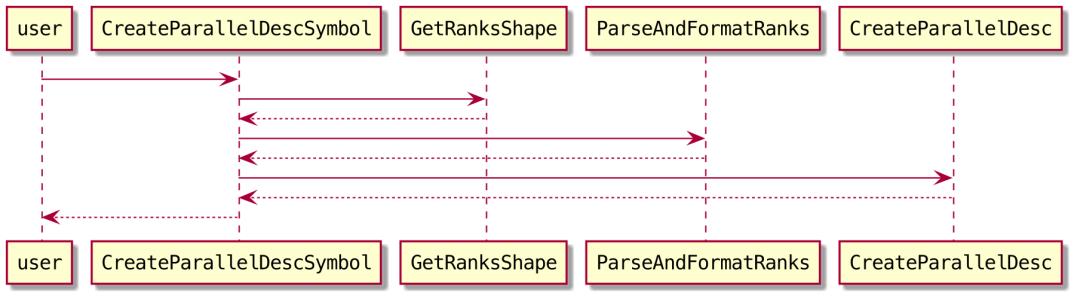
3.1 确定machine和device
ParseAndFormatRanks
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/placement_symbol.cpp#L113)会将ranks数组[0, 1]转为形如"machine_id:device_id"的字符串数组,供后续处理使用。这里的逻辑决定了如何根据ranks中的id,确定tensor数据在节点和设备上的分布:
machine_id=rank / NumOfProcessPerNode
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/rpc/lib/global_process_ctx.cpp#L56)
device_id=rank % NumOfProcessPerNode
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/rpc/lib/global_process_ctx.cpp#L84)
从上述公式可以看出,各个节点的设备/进程数量需要是一致的。
3.2 构造并缓存ParallelDesc对象
CreateParallelDesc
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/placement_symbol.cpp#L67)函数完成ParallelDesc的构造。其中MakeParallelConf
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/parallel_conf_util.cpp#L34)会先根据"machine_id:device_id"等数据构造一个cfg::ParallelConf对象,这是一个类似oneflow::ParallelConf(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/job/placement.proto#L12)的类型,文件位于build/oneflow/core/job/placement.cfg.h,是cmake构建过程中自动生成的文件。
cfg::ParallelConf等对象的接口类似protobuf message,但实现了hash方法,可以作为hash map的key。
之后的PhysicalRun
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/symbol/placement_symbol.cpp#L72)虽然涉及虚拟机,但实际执行的op指令应该是空的,实质性的逻辑只是调用builder的GetParallelDescSymbol(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/instructions_builder.cpp#L216),其中的核心逻辑是FindOrCreate(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/instructions_builder.cpp#L217),从缓存中查找ParallelDesc或创建新的缓存。
4
Global Tensor构造调用流程
下面以本文开始的例子分析一下构造global tensor的调用流程。这可能不是一个典型的场景,只是人为指定一个简单的数据便于展示和debug。
通过之前讨论local tensor时的类关系图可以知道,EagerGlobalTensorImpl内含一个local tensor的变量(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/tensor_impl.h#L339)。可以想象,构造global tensor时,会先构造一个local tensor、再做一些后续处理。
Python端创建tensor对象时,如果像本文开始的例子那样指定placement、sbp和数据,对应的Functor是GlobalTensorWithDataCtorFunctor
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/functional/tensor_api.cpp#L158)。核心逻辑在MakeGlobalTensorFromData(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L227)中,其主要调用流程如下:

上述各个部分的主要职能如下:
DataConsistencyCheck(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L251)会在tensor的placement涉及的各个节点间拷贝数据、校验数据是否一致。
functional::Empty
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L256)会根据shape和dtype构造一个local tensor,并等待随后填充数据(这里和之前讨论local tensor的过程一致)。
SwitchCopyLocalTensorFromUntypedArray(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L257)为empty的local tensor填充数据,数据既可以是本例中的python list,也可以是numpy的ndarray。
functional::Cast
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L267)进行数据类型dtype的转换。
functional::LocalToGlobal
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L272-L274)把local tensor转为global tensor,但这个只是用于broadcast 至指定placement的临时的global tensor(sbp list全部为broadcast,用于广播)。
functional::ToGlobal
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/api/python/utils/tensor_utils.cpp#L277-L279)将临时的global tensor根据placement和sbp,ToGlobal转换为最终的global tensor。
5
用flow.randn构造Global Tensor
下面看一个通过op构造global tensor的例子
# 终端一
# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=0 LOCAL_RANK=0
# 终端二
# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=1 LOCAL_RANK=1
import oneflow as flow
p = flow.placement("cpu", ranks=[0, 1])
sbp = flow.sbp.split(0)
x = flow.randn(4, 5, placement=p, sbp=sbp)
print(x.shape) # (4,5)
print(x.to_local().shape) # (2,5)randn op在local和global下分别对应着不同的functor实现:
# oneflow/core/functional/functional_api.yaml
- name: "randn"
signature: [
"Tensor (Shape size, *, DataType dtype=None, Device device=None,
Generator generator=None, Bool requires_grad=False) => RandN",
"Tensor (Shape size, *, Placement placement, SbpList sbp, DataType dtype=None,
Generator generator=None, Bool requires_grad=False) => GlobalRandN",
]
bind_python: True普通的flow.randn对应RandNFunctor,而global版本(带placement和sbp参数)的randn则对应的是GlobalRandNFunctor。
可以看到:
GlobalRandNFunctor
(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/functional/impl/random_functor.cpp#L194)中主要dispatch了"normal" op,在Eager Global的mode下, 会交给EagerGlobalInterpreter进行各种推导和准备工作(Interpret[https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/op_interpreter/eager_global_op_interpreter.cpp#L110]),并在Interpret方法里通过PhysicalRun,将normal op执行的指令交给虚拟机调度并执行。
EagerGlobalTensorImpl::New(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/op_interpreter/eager_global_op_interpreter.cpp#L138)时会调用GetPhysicalShape(https://github.com/Oneflow-Inc/oneflow/blob/fca713f45a2f55379eb4284848a8f62d0f266283/oneflow/core/framework/tensor_impl.cpp#L207)获取local tensor的shape。
这里,我们可以合理猜测,在每个rank上都会经过同样的Interpret、调用同样的normal op,生成本rank下部分的randn结果——local tensor,其shape都为(2, 5),经过组装得到global tensor x,其shape为(4, 5)。经过debug验证了上述猜测是正确的。从这个例子中,大致可以得到结论:
1.Global Tensor其实是基于Local Tensor以及SBP和placement的一层封装,其shape为全局逻辑形状;其数据由各个ranks所持有(ranks由placement指定)。
2.每个rank上的数据分片都是独立的Local Tensor,经过SBP规则的组装,得到上层的Global Tensor。
3.Global Tensor的计算实际上就是通过不同rank上数据分片(Local Tensor)独立经过kernel计算、boxing机制等组合完成的。
参考资料:
OneFlow源码
(https://github.com/Oneflow-Inc/oneflow/commit/fca713f45a2f55379eb4284848a8f62d0f266283)
Global Tensor:https://docs.oneflow.org/master/parallelism/03_consistent_tensor.html
集群的全局视角:https://docs.oneflow.org/master/parallelism/02_sbp.html
其他人都在看
九大深度学习库;谷歌文字生成视频的两大利器
点击“阅读原文”,欢迎体验OneFlow v0.8.0

以上是关于OneFlow源码解析:Global Tensor的主要内容,如果未能解决你的问题,请参考以下文章
OneFlow源码解析:Tensor类型体系与Local Tensor
Global Tensor和实习总结|OneFlow学习笔记