深入Java集合学习系列:Hashtable的实现原理
Posted 朝北教室的风筝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入Java集合学习系列:Hashtable的实现原理相关的知识,希望对你有一定的参考价值。
hashmap的扩容因子是0.75 原因 参考:HashMap默认加载因子为什么选择0.75?(阿里)
Hashtable 是一个很常见的数据结构类型,前段时间阿里的面试官说只要搞懂了HashTable,hashMap,HashSet,treeMap,treeSet这几个数据结构,阿里的数据结构面试没问题。
一查才发现,这里面的知识确实不少,都很经典,因此做一个专题
通过此文章,可以了解到一下内容(我去美团,京东,阿里基本每次都问这几个问题)
(1) Hashtable的存储结构 (数组+链表)
(2)Hashtable的扩容原理,扩容因子0.75,bucket的初始大小11.(扩容的函数为2N+1,hashMap的扩容函数是2N,之所以是2的倍数,是因为,Hashtable为了保证速度,扩容直接位移<<1这样就是2的倍数)
(3)添加,查找操作的深层次原理,
(4)搜素的几种方法,以及为什么会产生这几种搜索方法。
首先总览一下:
Hashtable与Map关系如下图:
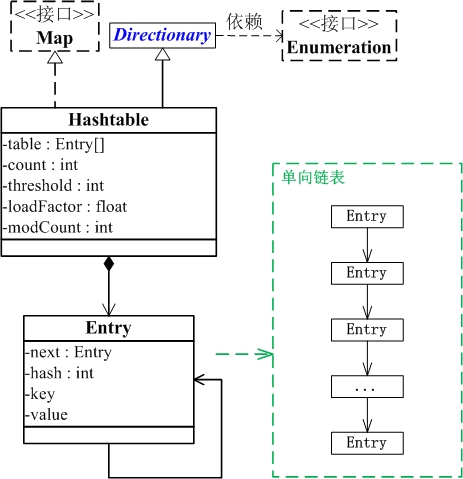
从图中可以看出:
(1) Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
(2) Hashtable是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
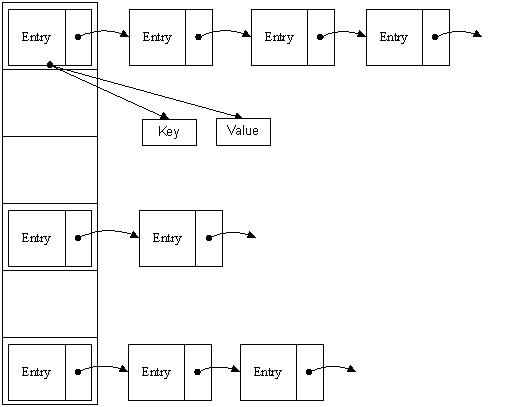
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射, 都是数组+链表的形式存储数据:
定义如下:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { .... public Hashtable() { this(11, 0.75f); } }
由此能看出两点:
(1)、Hashtable默认 bucket 容量是 11 ,扩容因子是0.75.
也就是说 如果 现在我们创建一个Hashtable,如果里面有8个数值 ,因为:8>=11*0.75;那么,在添加到第8个数值的时候,Hashtable会扩容,
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
这是Hashtable的构造函数:默认初始容量是11,而加载因子是0.75;
protected void rehash() { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; // overflow-conscious code int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) // Keep running with MAX_ARRAY_SIZE buckets return; newCapacity = MAX_ARRAY_SIZE; }}
红色的字体表明 Hashtable 扩容的函数是直接左移动1位,并加一,也就是:扩大为原来的2n+1;
(2)、Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable包含的方法 :elements() ,其作用是返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() { return this.<V>getEnumeration(VALUES); } // 获取Hashtable的枚举类对象 private <T> Enumeration<T> getEnumeration(int type) { if (count == 0) { return Collections.emptyEnumeration(); } else { return new Enumerator<>(type, false); } }
从中,我们可以看出:
(1) 若Hashtable的实际大小为0,则返回“空枚举类”对象emptyEnumerator;
(2) 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口,请注意这两个接口,这是我们后面介绍搜索方法时,会涉及到的)
我们先看看emptyEnumerator对象是如何实现的
private static Enumeration emptyEnumerator = new EmptyEnumerator(); // 空枚举类 // 当Hashtable的实际大小为0;此时,又要通过Enumeration遍历Hashtable时,返回的是“空枚举类”的对象。 private static class EmptyEnumerator implements Enumeration<Object> { EmptyEnumerator() { } // 空枚举类的hasMoreElements() 始终返回false public boolean hasMoreElements() { return false; } // 空枚举类的nextElement() 抛出异常 public Object nextElement() { throw new NoSuchElementException("Hashtable Enumerator"); } }
我们在来看看Enumeration类,Enumerator的作用是提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口”。因为,它同时实现了 “Enumerator接口”和“Iterator接口”。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> { Entry<?,?>[] table = Hashtable.this.table; int index = table.length; Entry<?,?> entry; Entry<?,?> lastReturned; int type; .... }
3、以下为Hashtable 包含的函数,函数都是同步的,每个前面都有synchronized,这意味着它是线程安全的。
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
....
}
由此我们也能看出:Hashtable的key、value都不可以为null。
看源码:如果value为空 抛出异常,如果 key为空 key.hashCode会抛出异常
我们都知道:Hashtable 的key 和value 都不能为空,HashMap的key 和value 都可以为空,就是这个原因。
此外,Hashtable中的映射不是有序的。
4、 Hashmap一样,Hashtable也是一个散列表,它也是通过“拉链法”解决哈希冲突的。
Hashtable的“拉链法”相关内容
Hashtable数据存储数组,是由一个Entry数组组成的,而 Entry 本身是多个key,value的链表,其中链表中的每个值都有个next指针,指向本链表的下一个元素。
private transient Entry[] table;
Hashtable中的key-value都是存储在table数组中的。 如下所示,数据节点Entry的数据结构
private static class Entry<K,V> implements Map.Entry<K,V> { // 哈希值 int hash; K key; V value; // 指向的下一个Entry,即链表的下一个节点 Entry<K,V> next; // 构造函数 protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } protected Object clone() { return new Entry<K,V>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } public K getKey() { return key; } public V getValue() { return value; } // 设置value。若value是null,则抛出异常。 public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } // 覆盖equals()方法,判断两个Entry是否相等。 // 若两个Entry的key和value都相等,则认为它们相等。 public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ (value==null ? 0 : value.hashCode()); } public String toString() { return key.toString()+"="+value.toString(); } }
从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说Hashtable是通过拉链法解决哈希冲突的。
Entry 实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数。这些都是基本的读取/修改key、value值的函数。
拿put()方法举例: put() 的作用是对外提供接口,让Hashtable对象可以通过put()将“key-value”添加到Hashtable中。
流程大体是先判断 hash值,然后判断equals值
PUT流程图: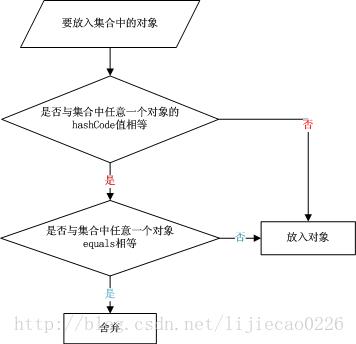
如果对hashcode和equals 方法的区别不了解可以参考:Java == ,equals 和 hashcode 的区别和联系(阿里面试)
put 方法的整个流程为:
- 判断 value 是否为空,为空则抛出异常;
- 计算 key 的 hash 值,并根据 hash 值获得 key 在 table 数组中的位置 index,如果 table[index] 元素不为空,则进行迭代,如果遇到相同的 key,则直接替换,并返回旧 value;
- 否则,我们可以将其插入到 table[index] 位置。
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}
通过一个实际的例子来演示一下这个过程:
假设我们现在Hashtable的容量为5,已经存在了(5,5),(13,13),(16,16),(17,17),(21,21)这 5 个键值对,目前他们在Hashtable中的位置如下:
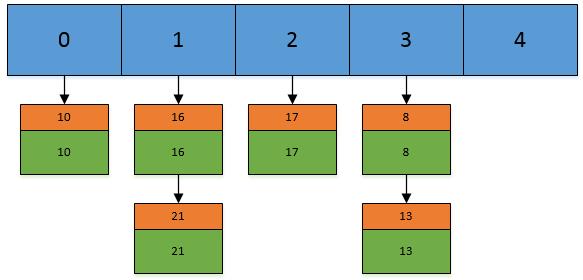
现在,我们插入一个新的键值对,put(16,22),假设key=16的索引为1.但现在索引1的位置有两个Entry了,所以程序会对链表进行迭代。迭代的过程中,发现其中有一个Entry的key和我们要插入的键值对的key相同,所以现在会做的工作就是将newValue=22替换oldValue=16,然后返回oldValue=16.

然后我们现在再插入一个,put(33,33),key=33的索引为3,并且在链表中也不存在key=33的Entry,所以将该节点插入链表的第一个位置。

再看一下Get()方法,我们知道Hashtable的时间复杂度是O(1),但你知道它是如何通过散列码的方式做到O(1)的吗?
Hashtable 直接用hash取了hashtable模,用模做了index,然后定位到bucket桶的数组位置,这个位置上面可能有一个hashcode相同的entry链表;然后对这链表进行遍历,找到key等于指定值的entry,因此 时间复杂度为O(1),HashMap,HashTable,HashSet 只要是以Hash为基础的数据结构都是O(1)
参考:HashMap, HashTable,HashSet,TreeMap 的时间复杂度
get() 的作用就是获取key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
相比较于 put 方法,get 方法则简单很多。其过程就是首先通过 hash()方法求得 key 的哈希值,然后根据 hash 值得到 index 索引(上述两步所用的算法与 put 方法都相同)。然后迭代链表,返回匹配的 key 的对应的 value;找不到则返回 null。
5、刚才提到 Hashtable 继承了 继承了字典类型:Dictionary类型。而字典类型依赖于: Enumerator
Enumerator实现了方法:Enumeration<T>, Iterator<T>
private class Enumerator<T> implements Enumeration<T>, Iterator<T> { Entry<?,?>[] table = Hashtable.this.table; int index = table.length; Entry<?,?> entry; Entry<?,?> lastReturned; int type; /** * Indicates whether this Enumerator is serving as an Iterator * or an Enumeration. (true -> Iterator). */ boolean iterator;
因此:搜索有五种方法进行搜素:
(1) 利用Iterator迭代器,遍历Hashtable的键值对
第一步:根据entrySet()获取Hashtable的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
Iterator iter=table.entrySet().iterator(); while(iter.hasNext()){ Entry entry =(Entry) iter.next(); //获取key String key=(String)entry.getKey(); Object value=entry.getValue(); System.out.println("key="+key+" value="+value); }
(2) 通过Iterator遍历Hashtable的键
第一步:根据keySet()获取Hashtable的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象 // table中的key是String类型,value是Integer类型 String key = null; Integer integ = null; Iterator iter = table.keySet().iterator(); while (iter.hasNext()) { // 获取key key = (String)iter.next(); // 根据key,获取value integ = (Integer)table.get(key); }
(3)、通过Iterator遍历Hashtable的值
第一步:根据value()获取Hashtable的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象 // table中的key是String类型,value是Integer类型 Integer value = null; Collection c = table.values(); Iterator iter= c.iterator(); while (iter.hasNext()) { value = (Integer)iter.next(); }
(4)、 通过Enumeration遍历Hashtable的键
第一步:根据keys()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.keys();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
(5)、 通过Enumeration遍历Hashtable的值
第一步:根据elements()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
遍历测试程序如下:
import java.util.Collection; import java.util.Enumeration; import java.util.Hashtable; import java.util.Iterator; import java.util.Map.Entry; public class hashtabletest { public static void main(String[] args) { // TODO Auto-generated method stub Hashtable table =new Hashtable(); table.put("张三",20); table.put("李四",30); table.put("王五", 50); // 4.1 遍历Hashtable的键值对 // // 第一步:根据entrySet()获取Hashtable的“键值对”的Set集合。 // 第二步:通过Iterator迭代器遍历“第一步”得到的集合。 Iterator iter=table.entrySet().iterator(); while(iter.hasNext()){ Entry entry =(Entry) iter.next(); //获取key String key=(String)entry.getKey(); Object value=entry.getValue(); System.out.println("key="+key+" value="+value); } // //4.2 通过Iterator遍历Hashtable的键 //第一步:根据keySet()获取Hashtable的“键”的Set集合。 //第二步:通过Iterator迭代器遍历“第一步”得到的集合。 Iterator itkey=table.keySet().iterator(); while(itkey.hasNext()){ String key=(String) itkey.next(); Object value=table.get(key); System.out.println("key=="+key+" value="+value); } // 4.3 通过Iterator遍历Hashtable的值 // // 第一步:根据value()获取Hashtable的“值”的集合。 // 第二步:通过Iterator迭代器遍历“第一步”得到的集合。 Collection c= table.values(); Iterator itvalue=c.iterator(); while(itvalue.hasNext()){ Object value =itvalue.next(); System.out.println(" value="+value); } // 4.4 通过Enumeration遍历Hashtable的键 // // 第一步:根据keys()获取Hashtable的集合。 // 第二步:通过Enumeration遍历“第一步”得到的集合。 Enumeration enu=table.keys(); while(enu.hasMoreElements()){ System.out.println("elements="+enu.nextElement()); } // 4.5 通过Enumeration遍历Hashtable的值 // 第一步:根据elements()获取Hashtable的集合。 // 第二步:通过Enumeration遍历“第一步”得到的集合。 Enumeration entry=table.elements(); while(entry.hasMoreElements()){ System.out.println(" element111s ="+entry.nextElement()); } } }
结果为:
key=王五 value=50 key=张三 value=20 key=李四 value=30 key==王五 value=50 key==张三 value=20 key==李四 value=30 value=50 value=20 value=30 elements=王五 elements=张三 elements=李四 element111s =50 element111s =20 element111s =30
6、其他的函数
(1) contains() 和 containsValue()
contains() 和 containsValue() 的作用都是判断Hashtable是否包含“值(value)”
public boolean containsValue(Object value) {
return contains(value);
}
remove() remove() 的作用就是删除Hashtable中键为key的元素
Hashtable实现的Cloneable接口 Hashtable实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个Hashtable对象并返回。
Hashtable实现的Serializable接口,分别实现了串行读取、写入功能。
串行写入函数就是将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
串行读取函数:根据写入方式读出将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
以上是关于深入Java集合学习系列:Hashtable的实现原理的主要内容,如果未能解决你的问题,请参考以下文章
Java 集合深入理解 (十四) :Hashtable实现原理研究
深入理解JAVA集合系列二:ConcurrentHashMap源码解读