如何使用SPSS对Logistic回归中分类变量进行处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用SPSS对Logistic回归中分类变量进行处理相关的知识,希望对你有一定的参考价值。
1、数据录入SPSS。

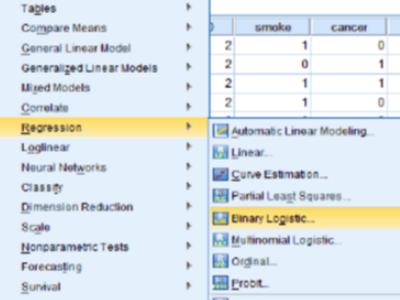
2、选择Analyze→Regression→Binary Logistic。
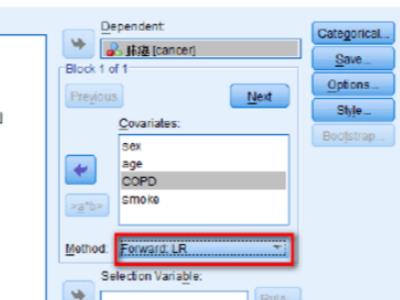
3、主对话框设置:将因变量cancer送入Dependent框中,将纳入模型的自变量sex, age, BMI和COPD变量Covariates中。本研究中,纳入age变量仅仅是为了调整该变量带来的混杂(不关心该变量的OR值),因此将age直接将改变量纳入Logistic回归模型。
4、Categorical设置:该选项可将多分类变量(包括有序多分类和无序多分类)变换成哑变量,指定某一分类为参照。本研究中,COPD是多分类变量,我们指定“无COPD病史”的研究对象为参照组,分别比较“轻/中度”和“重度”组相对于参照组患肺癌的风险变化。
5、点击Categorical→将左侧Covariates中的COPD变量送入右侧Categorical Covariates中。

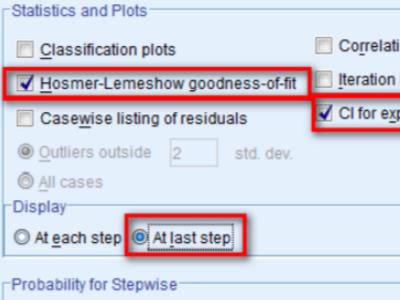
6、Hosmer-Lemeshow goodness-of-fit:检验模型的拟合优度; CI for exp(B):结果给出OR值的95%可信区间; Display→At last step:仅展示变量筛选的最后一步结果。 →Continue→回到主界面→OK。
二值logistic回归:
选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。那么我们为了模型的准确,就把这个交互效应也选到模型里去。我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。默认的是进入,就是强迫所有选择的变量都进入到模型里边。除去进入法以外,还有三种向前法,三种向后法。一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。再下边的选择变量则是用来选择你的个案的。一般也不用管它。
选好主面板以后,单击分类(右上角),打开分类对话框。在这个对话框里边,左边的协变量的框框里边有你选好的自变量,右边写着分类协变量的框框则是空白的。你要把协变量里边的字符型变量和分类变量选到分类协变量里边去(系统会自动生成哑变量来方便分析,什么事哑变量具体参照前文)。这里的字符型变量指的是用值标签标注过得变量,不然光文字,系统也没法给你分析啊。选好以后,分类协变量下边还有一个更改对比的框框,我们知道,对于分类变量,spss需要有一个参照,每个分类都通过和这个参照进行比较来得到结果,更改对比这个框框就是用来选择参照的。默认的对比是指示符,也就是每个分类都和总体进行比较,除了指示符以外还有简单,差值等。这个框框不是很重要,默认就可以了。
点击继续。然后打开保存对话框,勾选概率,组成员,包含协方差矩阵。点击继续,打开选项对话框,勾选分类图,估计值的相关性,迭代历史,exp(B)的CI,在模型中包含常数,输出——在每个步骤中。如果你的协变量有连续型的,或者小样本,那还要勾选Hosmer-Lemeshow拟合度,这个拟合度表现的会较好一些。
继续,确定。
然后,就会输出结果了。主要会输出六个表。
第一个表是模型系数综合检验表,要看他模型的p值是不是小于0.05,判断我们这个logistic回归方程有没有意义。
第二个表示模型汇总表。这个表里有两个R^2,叫做广义决定系数,也叫伪R^2,作用类似于线性回归里的决定系数,也是表示这个方程能够解释模型的百分之多少。由于计算方法不同,这两个广义决定系数的值往往不一样,但是出入并不会很大。
在下边的分类表则表述了模型的稳定性。这个表最后一行百分比校正下边的三个数据列出来在实际值为0或者1时,模型预测正确的百分比,以及模型总的预测正确率。一般认为预测正确概率达到百分之五十就是良好(标准真够低的),当然正确率越高越好。
在然后就是最重要的表了,方程中的变量表。第一行那个B下边是每个变量的系数。第五行的p值会告诉你每个变量是否适合留在方程里。如果有某个变量不适合,那就要从新去掉这个变量做回归。根据这个表就可以写出logistic方程了:P=Exp(常量+a1*变量1+a2*变量2.。。。)/(1+Exp(常量+a1*变量1+a2*变量2.。。。))。如果大家学过一点统计,那就应该对这个形式的方程不陌生。提供变量,它最后算出来会是一个介于0和1的数,也就是你的模型里设定的值比较大的情况发生的概率,比如你想推算会不会治愈,你设0治愈,1为没有治愈。那你的模型算出来就是没有治愈的概率。如果你想直接计算治愈的概率,那就需要更改一下设定,用1去代表治愈。
此外倒数后两列有一个EXP(B),也就是OR值,哦,这个可不是或者的意思,OR值是优势比。在线性回归里边我们用标准化系数来对比两个自变量对于因变量的影响力的强弱,在logistic回归里边我们用优势比来比较不同的情况对于因变量的影响。举个例子。比如我想看性别对于某种病是否好转的影响,假设0代表女,1代表男,0代表不好转,1代表好转。发现这个变量的OR值为2.9,那么也就是说男人的好转的可能是女人好转的2.9倍。注意,这里都是以数值较大的那个情况为基准的。而且OR值可以直接给出这个倍数。如果是0,1,2各代表一类情况的时候,那就是2是1的2.9倍,1是0的2.9倍,以此类推。OR值对于方程没什么贡献,但是有助于直观的理解模型。在使用OR值得时候一定要结合它95%的置信区间来进行判断。
此外还有相关矩阵表和概率直方图,就不再介绍了。
多项logistic回归:
选择分析——回归——多项logistic,打开主面板,因变量大家都知道选什么,因变量下边有一个参考类别,默认的第一类别就可以。再然后出现了两个框框,因子和协变量。很明显,这两个框框都是要你选因变量的,那么到底有什么区别呢?嘿嘿,区别就在于,因子里边放的是无序的分类变量,比如性别,职业什么的,以及连续变量(实际上做logistic回归时大部分自变量都是分类变量,连续变量是比较少的。),而协变量里边放的是等级资料,比如病情的严重程度啊,年龄啊(以十年为一个年龄段撒,一年一个的话就看成连续变量吧还是)之类的。在二项logistic回归里边,系统会自动生成哑变量,可是在多项logistic回归里边,就要自己手动设置了。参照上边的解释,不难知道设置好的哑变量要放到因子那个框框里去。
然后点开模型那个对话框,哇,好恐怖的一个对话框,都不知道是干嘛的。好,我们一点点来看。上边我们已经说过交互作用是干嘛的了,那么不难理解,主效应就是变量本身对模型的影响。明确了这一点以后,这个对话框就没有那么难选了。指定模型那一栏有三个模型,主效应指的是只做自变量和因变量的方程,就是最普通的那种。全因子指的是包含了所有主效应和所有因子和因子的交互效应的模型(我也不明白为什么只有全因子,没有全协变量。这个问题真的很难,所以别追问我啦。)第三个是设定/步进式。这个是自己手动设置交互项和主效应项的,而且还可以设置这个项是强制输入的还是逐步进入的。这个概念就不用再啰嗦了吧啊?
点击继续,打开统计量对话框,勾选个案处理摘要,伪R方,步骤摘要,模型拟合度信息,单元格可能性,分类表,拟合度,估计,似然比检验,继续。打开条件,全勾,继续,打开选项,勾选为分级强制条目和移除项目。打开保存,勾选包含协方差矩阵。确定(总算选完了)。
结果和二项logistic回归差不多,就是多了一个似然比检验,p值小于0.05认为变量有意义。然后我们直接看参数估计表。假设我们的因变量有n个类,那参数估计表会给出n-1组的截距,变量1,变量2。我们我们用Zm代表Exp(常量m+am1*变量1+am2*变量2+。。。),那么就有第m类情况发生的概率为Zn/1+Z2+Z3+……+Zn(如果我们以第一类为参考类别的话,我们就不会有关于第一类的参数,那么第一类就是默认的1,也就是说Z1为1)。
有序回归(累积logistic回归):
选择菜单分析——回归——有序,打开主面板。因变量,因子,协变量如何选取就不在重复了。选项对话框默认。打开输出对话框,勾选拟合度统计,摘要统计,参数估计,平行线检验,估计响应概率,实际类别概率,确定,位置对话框和上文的模型对话框类似,也不重复了。确定。
结果里边特有的一个表是平行线检验表。这个表的p值小于0.05则认为斜率系数对于不同的类别是不一样的。此外参数估计表得出的参数也有所不同。假设我们的因变量有四个水平,自变量有两个,那么参数估计表会给出三个阈值a1,a2,a3(也就是截距),两个自变量的参数m,n。计算方程时,首先算三个Link值,Link1=a1+m*x1+n*x2,Link2=a2+m*x1+n*x2,Link3=a3+m*x1+n*x2,(仅有截距不同)有了link值以后,p1=1/(1+exp(link1)),p1+p2=1/(1+exp(link2)),p1+p2+p3=1/(1+exp(link3)),p1+p2+p3+p4=1..
通过上边的这几个方程就能计算出各自的概率了。
Logistic回归到这里基本就已经结束了。大家一定要记熟公式,弄混可就糟糕了。希望能对你有所帮助呦。本回答被提问者和网友采纳 参考技术B
如果X为定类数据,通常情况下需要将X进行虚拟变量设置,可以使用spssau的生成变量功能,一键生成。

probit回归与logistic回归有啥区别
probit与logistic的区别为:意思不同、用法不同、侧重点不同。
一、意思不同
1、probit:概率单位。
2、logistic:数理(符号)逻辑。
二、用法不同
1、probit:
probit模型服从正态分布。两个模型都是离散选择模型的常用模型。但logit模型简单直接,应用更广。而且,当因变量是名义变量时,Logit和Probit没有本质的区别,一般情况下可以换用。区别在于采用的分布函数不同,前者假设随机变量服从逻辑概率分布,而后者假设随机变量服从正态分布。

2、logistic:Logit模型是最早的离散选择模型,也是目前应用最广的模型。Logit模型是Luce(1959)根据IIA特性首次导出的;Marschark(1960)证明了Logit模型与最大效用理论的一致性;Marley(1965)研究了模型的形式和效用非确定项的分布之间的关系。
三、侧重点不同
1、probit:根据常态频率分配平均数的偏差计算统计单位。
2、logistic:离散选择法模型之一,Logit模型是最早的离散选择模型。
参考技术A probit回归和logistic回归几乎可以用于相同的数据,对于二分类因变量,这两种方法的结果十分类似。那他们到底有什么区别呢?如 果从分布角度来讲,logit函数和probit的函数几乎重叠,但反映的含义不同,logit等于p/(1-p),这里p是结局发生的概率,而 probit的函数是F-1(p),注意-1是上标。F是累积的标准正态分布函数,所以F-1就是累积标准正态分布函数的逆函数或反函数。
从 解释的角度来讲,logit更容易理解一些,因为p/(1-p)就是我们常说的odds,两个odds相比就是odds ratio,也就是我们最常用的OR值。所以当我们做出结果后,logistic回归所反应的实际意义就非常直观。而相比之下,probit的含义表示自 变量对累积标准正态分布函数的逆作用,这个就太让人看不懂了。当然,实际上我们也可以通过正态分布值求出probit回归中的p,作为概率预测,只是比 logistic回归要稍微麻烦一些。
但这两个方法之间也是有关联的,通常情况下,probit回归估计出的参数值乘以1.814,大致会等于logistic回归中的参数值。
实 际中具体选择哪个方法呢?据笔者所查阅的文献,尚未发现有理论依据,更多的仍是根据个人习惯。从文献的应用情况来看,logistic回归的应用远远多于 probit回归,这主要是因为logistic回归的易解释性,而不是logistic回归比probit回归更好或更适合数据。
但 probit回归并不是说就要被logistic回归替代了,从预测的角度来看,probit回归还是有较强的使用价值的。其预测概率效果与 logistic回归一样的好。如果你确实想知道到底你的数据用哪一个方法好,也不是没有办法,你可以看一下你的残差到底是符合logit函数呢还是符合 probit函数,当然,凭肉眼肯定是看不出来的,因为这两个函数本来就很接近,你可以通过函数的假定,用拟合优度检验一下。但通常,估计不会有人非要这 么较真,因为没有必要。如果你的因变量是二分类,你无论用哪种方法,都不能说错。萝卜青菜,各有所爱而已。本回答被提问者和网友采纳 参考技术B
Logistic回归比probit回归的应用广泛,同一数据两者的结果非常接近。
选择使用哪种方法没有统一的标准,主要看专业领域更常使用哪种方法。
Probit最常使用的是二分类probit,可在spssau中在线分析。
如果从分布角度来讲,logit函数和probit的函数几乎重叠,但反映的含义不同,logit等于p/(1-p),这里p是结局发生的概率,而 probit的函数是F-1(p),注意-1是上标。F是累积的标准正态分布函数,所以F-1就是累积标准正态分布函数的逆函数或反函数。
从解释的角度来讲,logit更容易理解一些,因为p/(1-p)就是我们常说的odds,两个odds相比就是odds ratio,也就是我们最常用的OR值。所以当我们做出结果后,logistic回归所反应的实际意义就非常直观。而相比之下,probit的含义表示自 变量对累积标准正态分布函数的逆作用,这个就太让人看不懂了。当然,实际上我们也可以通过正态分布值求出probit回归中的p,作为概率预测,只是比 logistic回归要稍微麻烦一些。
关联:这两个方法之间是有关联的,通常情况下,probit回归估计出的参数值乘以1.814,大致会等于logistic回归中的参数值。
probit回归模型:最简单的probit模型就是指被解释变量Y是一个0,1变量,事件发生地概率是依赖于解释变量,即P(Y=1)=f(X),也就是说,Y=1的概率是一个关于X的函数,其中f(.)服从标准正态分布。
logistic回归模型:(logistic regression)属于概率型非线性回归,它是研究二分类观察结果与一些影响因素之间关系的一种多变量分析方法。在流行病学研究中,经常需要分析疾病与各危险因素之间的定量关系,为了正确说明这种关系,需要排除一些混杂因素的影响。
以上是关于如何使用SPSS对Logistic回归中分类变量进行处理的主要内容,如果未能解决你的问题,请参考以下文章