Dubbo源码1(SPI)
Posted eric
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo源码1(SPI)相关的知识,希望对你有一定的参考价值。
SPI:
http://blog.csdn.net/quhongwei_zhanqiu/article/details/41577159
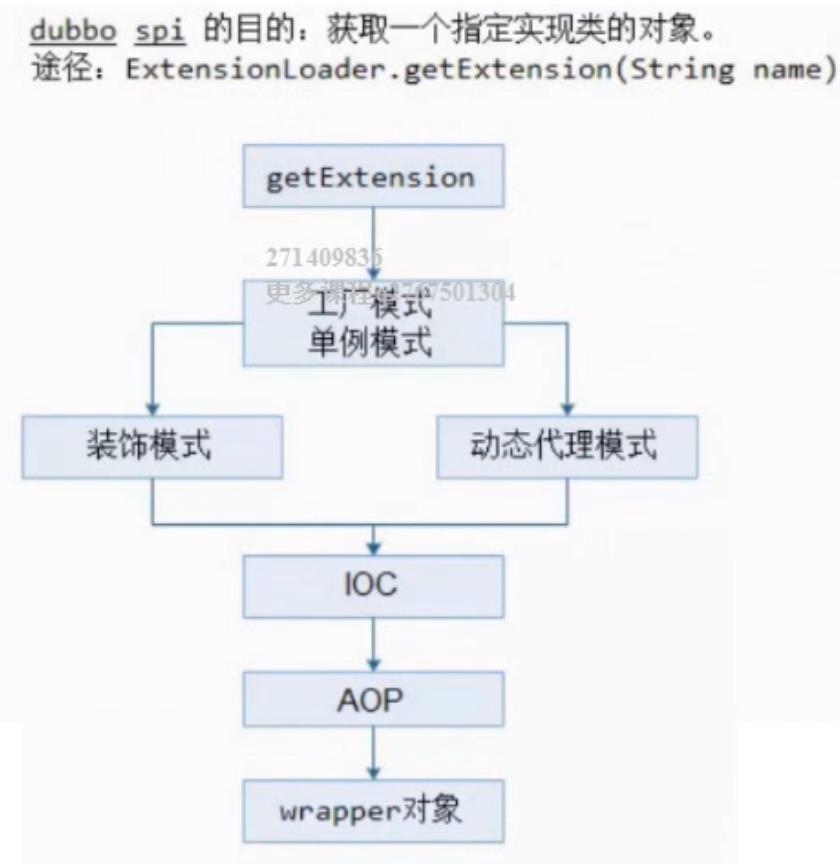
Dubbo的SPI目的:获取一个指定实现类的对象,ExtensionLoader.getExtension(String name)
实现路径:
getExtensionLoader(Class<T> type) 就是为该接口new 一个ExtensionLoader,然后缓存起来。
getAdaptiveExtension() 获取一个扩展类,如果@Adaptive注解在类上就是一个装饰类;如果注解在方法上就是一个动态代理类,例如Protocol$Adaptive对象。
getExtension(String name) 获取一个指定对象。
Dubbo SPI与JDK SPI区别:
dubbo在原来的基础上设计了以下功能
1.原始JDK spi不支持缓存;dubbo设计了缓存对象:spi的key与value 缓存在 cachedInstances对象里面,它是一个ConcurrentMap
2.原始JDK spi不支持默认值,dubbo设计默认值:@SPI("dubbo") 代表默认的spi对象,例如Protocol的@SPI("dubbo")就是 DubboProtocol,
通过 ExtensionLoader.getExtensionLoader(Protocol.class).getDefaultExtension()那默认对象
3.jdk要用for循环判断对象,dubbo设计getExtension灵活方便,动态获取spi对象,
例如 ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(spi的key)来提取对象
4.原始JDK spi不支持 AOP功能,dubbo设计增加了AOP功能,在cachedWrapperClasses,在原始spi类,包装了XxxxFilterWrapper XxxxListenerWrapper
5.原始JDK spi不支持 IOC功能,dubbo设计增加了IOC,通过构造函数注入,代码为:wrapperClass.getConstructor(type).newInstance(instance)
为什么要设计adaptive?注解在类上和注解在方法上的区别?
adaptive设计的目的是为了识别固定已知类和扩展未知类。
1.注解在类上:代表人工实现,实现一个装饰类(设计模式中的装饰模式),它主要作用于固定已知类,
目前整个系统只有2个,AdaptiveCompiler、AdaptiveExtensionFactory。
a.为什么AdaptiveCompiler这个类是固定已知的?因为整个框架仅支持Javassist和JdkCompiler。
b.为什么AdaptiveExtensionFactory这个类是固定已知的?因为整个框架仅支持2个objFactory,一个是spi,另一个是spring
2.注解在方法上:代表自动生成和编译一个动态的Adpative类,它主要是用于SPI,因为spi的类是不固定、未知的扩展类,所以设计了动态$Adaptive类.
例如 Protocol的spi类有 injvm dubbo registry filter listener等等 很多扩展未知类,
它设计了Protocol$Adaptive的类,通过ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(spi类);来提取对象
Dubbo里面所有的对象生成都是通过SPI,Extension方式。
以上是关于Dubbo源码1(SPI)的主要内容,如果未能解决你的问题,请参考以下文章