ElasticSearch还能性能调优,涨见识涨见识了!!!
Posted 博学谷狂野架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch还能性能调优,涨见识涨见识了!!!相关的知识,希望对你有一定的参考价值。
ElasticSearch 性能调优

作者: 博学谷狂野架构师
GitHub地址:GitHub地址 (有我们精心准备的130本电子书PDF)
概述
性能优化是个涉及面非常广的问题,不同的环境,不同的业务场景可能会存在不同的优化方案,本文只对一些相关的知识点做简单的总结,具体方案可以根据场景自行尝试。
配置文件调优
通过
elasticsearch.yml配置文件调优
内存锁定
允许 JVM 锁住内存,禁止操作系统交换出去
由于JVM发生swap交换会导致极大降低ES的性能,为了防止ES发生内存交换,我们可以通过锁定内存来实现,这将极大提高查询性能,但同时可能造成OOM,需要对应做好资源监控,必要的时候进行干预。
修改ES配置
修改ES的配置文件elasticsearch.yml,设置bootstrap.memory_lock为true
COPY#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-3
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 允许内存锁定,提高ES性能
bootstrap.memory_lock: true修改JVM配置
修改jvm.options,通常设置-Xms和-Xmx的的值为“物理内存大小的一半和32G的较小值”
这是因为,es内核使用lucene,lucene本身是单独占用内存的,并且占用的还不少,官方建议设置es内存,大小为物理内存的一半,剩下的一半留给lucene
COPY-Xms2g
-Xmx2g关闭操作系统的swap
临时关闭
COPYsudo swapoff -a 永久关闭
注释掉或删除所有swap相关的内容
COPYvi /etc/fstab
修改文件描述符
修改/etc/security/limits.conf,设置memlock为unlimited
COPYelk hard memlock unlimited
elk soft memlock unlimited修改系统配置
设置虚拟内存
修改
/etc/systemd/system.conf,设置vm.max_map_count为一个较大的值
COPYvm.max_map_count=10240000修改文件上限
修改
/etc/systemd/system.conf,设置DefaultLimitNOFILE,DefaultLimitNPROC,DefaultLimitMEMLOCK为一个较大值,或者不限定
COPYDefaultLimitNOFILE=100000
DefaultLimitNPROC=100000
DefaultLimitMEMLOCK=infinity重启ES
服务发现优化
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群
组播发现应该永远不被使用在生产环境了,否则你得到的结果就是一个节点意外的加入到了你的生产环境,仅仅是因为他们收到了一个错误的组播信号,ES是一个P2P类型的分布式系统,使用gossip协议,集群的任意请求都可以发送到集群的任一节点,然后es内部会找到需要转发的节点,并且与之进行通信,在es1.x的版本,es默认是开启组播,启动es之后,可以快速将局域网内集群名称,默认端口的相同实例加入到一个大的集群,后续再es2.x之后,都调整成了单播,避免安全问题和网络风暴;
单播discovery.zen.ping.unicast.hosts,建议写入集群内所有的节点及端口,如果新实例加入集群,新实例只需要写入当前集群的实例,即可自动加入到当前集群,之后再处理原实例的配置即可,新实例加入集群,不需要重启原有实例;
节点zen相关配置:discovery.zen.ping_timeout:判断master选举过程中,发现其他node存活的超时设置,主要影响选举的耗时,参数仅在加入或者选举 master 主节点的时候才起作用discovery.zen.join_timeout:节点确定加入到集群中,向主节点发送加入请求的超时时间,默认为3sdiscovery.zen.minimum_master_nodes:参与master选举的最小节点数,当集群能够被选为master的节点数量小于最小数量时,集群将无法正常选举。
故障检测( fault detection )
故障检测情况
以下两种情况下回进行故障检测
COPY* 第一种是由master向集群的所有其他节点发起ping,验证节点是否处于活动状态
* 第二种是:集群每个节点向master发起ping,判断master是否存活,是否需要发起选举配置方式
故障检测需要配置以下设置使用
discovery.zen.fd.ping_interval:节点被ping的频率,默认为1s。discovery.zen.fd.ping_timeout等待ping响应的时间,默认为 30s,运行的集群中,master 检测所有节点,以及节点检测 master 是否正常。discovery.zen.fd.ping_retriesping失败/超时多少导致节点被视为失败,默认为3。
队列数量优化
不建议盲目加大es的队列数量,要根据实际情况来进行调整
如果是偶发的因为数据突增,导致队列阻塞,加大队列size可以使用内存来缓存数据,如果是持续性的数据阻塞在队列,加大队列size除了加大内存占用,并不能有效提高数据写入速率,反而可能加大es宕机时候,在内存中可能丢失的上数据量。
查看线程池情况
通过以下可以查看线程池的情况,哪些情况下,加大队列size呢?
COPYGET /_cat/thread_pool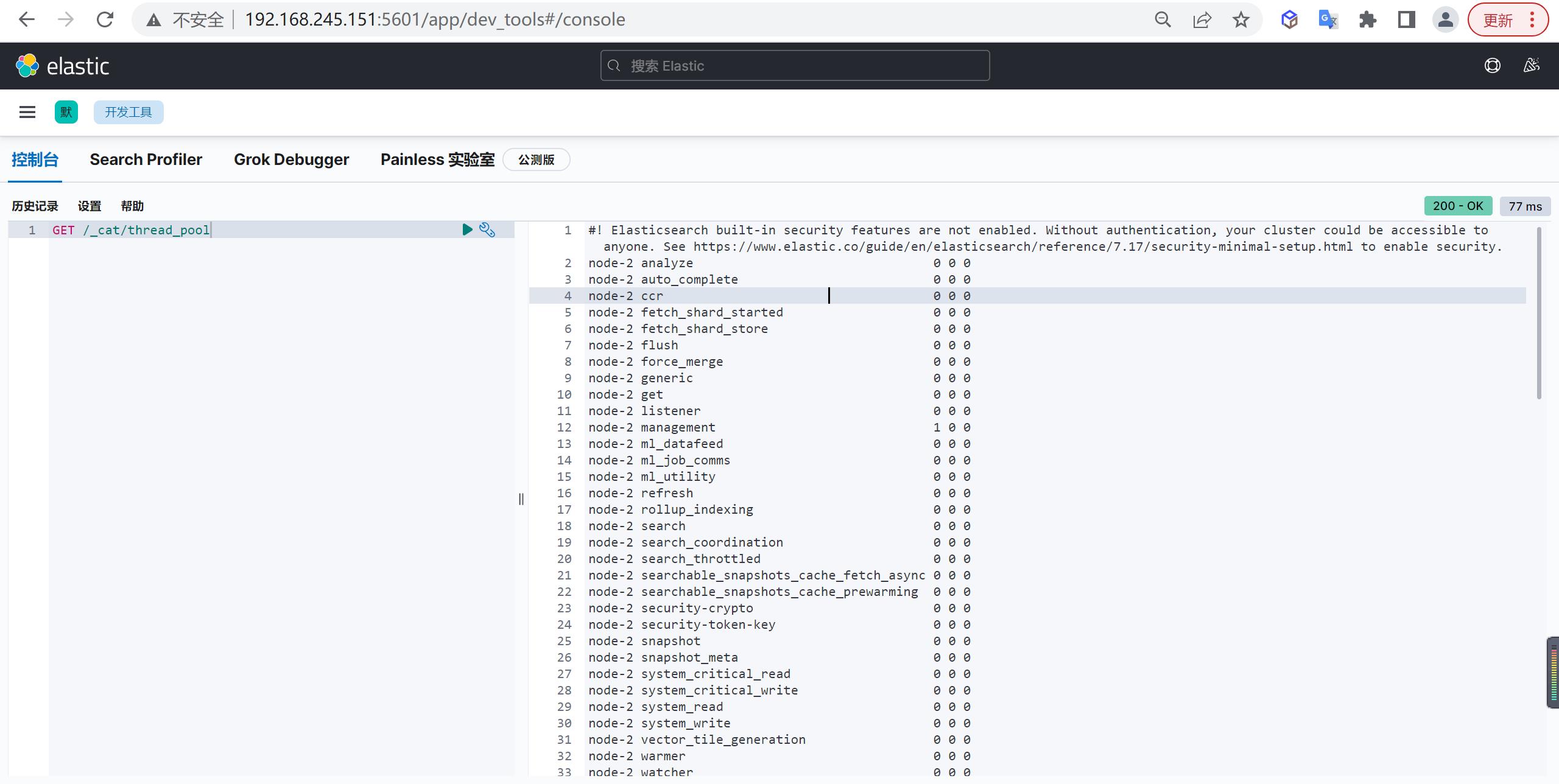
观察api中返回的queue和rejected,如果确实存在队列拒绝或者是持续的queue,可以酌情调整队列size。
内存使用
配置熔断限额
设置indices的内存熔断相关参数,根据实际情况进行调整,防止写入或查询压力过高导致OOM
indices.breaker.total.limit: 50%,集群级别的断路器,默认为jvm堆的70%indices.breaker.request.limit: 10%,单个request的断路器限制,默认为jvm堆的60%indices.breaker.fielddata.limit: 10%,fielddata breaker限制,默认为jvm堆的60%。
配置缓存
根据实际情况调整查询占用cache,避免查询cache占用过多的jvm内存,参数为静态的,需要在每个数据节点配置
indices.queries.cache.size: 5%,控制过滤器缓存的内存大小,默认为10%,接受百分比值,5%或者精确值,例如512mb。
创建分片优化
如果集群规模较大,可以阻止新建shard时扫描集群内全部shard的元数据,提升shard分配速度
cluster.routing.allocation.disk.include_relocations: false,默认为true
系统层面调优
jdk版本
选用当前版本ES推荐使用的ES,或者使用ES自带的JDK
jdk内存配置
首先,-Xms和-Xmx设置为相同的值,避免在运行过程中再进行内存分配,同时,如果系统内存小于64G,建议设置略小于机器内存的一半,剩余留给系统使用,同时,jvm heap建议不要超过32G(不同jdk版本具体的值会略有不同),否则jvm会因为内存指针压缩导致内存浪费
关闭交换分区
关闭交换分区,防止内存发生交换导致性能下降(部分情况下,宁死勿慢)
swapoff -a
文件句柄
Lucene 使用了 大量的 文件,同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字,所有这一切都需要足够的文件描述符,默认情况下,linux默认运行单个进程打开1024个文件句柄,这显然是不够的,故需要加大文件句柄数 ulimit -n 65536
mmap
Elasticsearch 对各种文件混合使用了 NioFs( 注:非阻塞文件系统)和 MMapFs ( 注:内存映射文件系统)。
请确保你配置的最大映射数量,以便有足够的虚拟内存可用于 mmapped 文件。这可以暂时设置:sysctl -w vm.max_map_count=262144 或者你可以在 /etc/sysctl.conf 通过修改 vm.max_map_count 永久设置它。
磁盘
如果你正在使用 SSDs,确保你的系统 I/O 调度程序是配置正确的
当你向硬盘写数据,I/O 调度程序决定何时把数据实际发送到硬盘,大多数默认linux 发行版下的调度程序都叫做 cfq(完全公平队列),但它是为旋转介质优化的:机械硬盘的固有特性意味着它写入数据到基于物理布局的硬盘会更高效。
这对 SSD 来说是低效的,尽管这里没有涉及到机械硬盘,但是,deadline 或者 noop 应该被使用,deadline 调度程序基于写入等待时间进行优化, noop 只是一个简单的 FIFO 队列。
COPYecho noop > /sys/block/sd/queue/scheduler磁盘挂载
COPYmount -o noatime,data=writeback,barrier=0,nobh /dev/sd* /esdata*其中,noatime,禁止记录访问时间戳;data=writeback,不记录journal;barrier=0,因为关闭了journal,所以同步关闭barrier;nobh,关闭buffer_head,防止内核影响数据IO
磁盘其他注意事项
使用 RAID 0,条带化 RAID 会提高磁盘I/O,代价显然就是当一块硬盘故障时整个就故障了,不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面,不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
使用方式调优
当elasticsearch本身的配置没有明显的问题之后,发现es使用还是非常慢,这个时候,就需要我们去定位es本身的问题了,首先祭出定位问题的第一个命令:
Index(写)调优
副本数置0
如果是集群首次灌入数据,可以将副本数设置为0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程
COPYPUT /my_temp_index/_settings
"number_of_replicas": 0
自动生成doc ID
通过Elasticsearch写入流程可以看出,如果写入doc时如果外部指定了id,则Elasticsearch会先尝试读取原来doc的版本号,以判断是否需要更新,这会涉及一次读取磁盘的操作,通过自动生成doc ID可以避免这个环节
合理设置mappings
将不需要建立索引的字段index属性设置为not_analyzed或no。
- 对字段不分词,或者不索引,可以减少很多运算操作,降低CPU占用,尤其是binary类型,默认情况下占用CPU非常高,而这种类型进行分词通常没有什么意义。
- 减少字段内容长度,如果原始数据的大段内容无须全部建立 索引,则可以尽量减少不必要的内容。
- 使用不同的分析器(analyzer),不同的分析器在索引过程中 运算复杂度也有较大的差异。
调整_source字段
_source` 字段用于存储 doc 原始数据,对于部分不需要存储的字段,可以通过 includes excludes过滤,或者将`_source`禁用,一般用于索引和数据分离,这样可以降低 I/O 的压力,不过实际场景中大多不会禁用`_source对analyzed的字段禁用norms
Norms用于在搜索时计算doc的评分,如果不需要评分,则可以将其禁用
COPYtitle":
"type": "string",
"norms":
"enabled": false
调整索引的刷新间隔
该参数缺省是1s,强制ES每秒创建一个新segment,从而保证新写入的数据近实时的可见、可被搜索到,比如该参数被调整为30s,降低了刷新的次数,把刷新操作消耗的系统资源释放出来给index操作使用
COPYPUT /my_index/_settings
"index" :
"refresh_interval": "30s"
这种方案以牺牲可见性的方式,提高了index操作的性能。
批处理
批处理把多个index操作请求合并到一个batch中去处理,和mysql的jdbc的bacth有类似之处

比如每批1000个documents是一个性能比较好的size,每批中多少document条数合适,受很多因素影响而不同,如单个document的大小等,ES官网建议通过在单个node、单个shard做性能基准测试来确定这个参数的最优值
Document的路由处理
当对一批中的documents进行index操作时,该批index操作所需的线程的个数由要写入的目的shard的个数决定
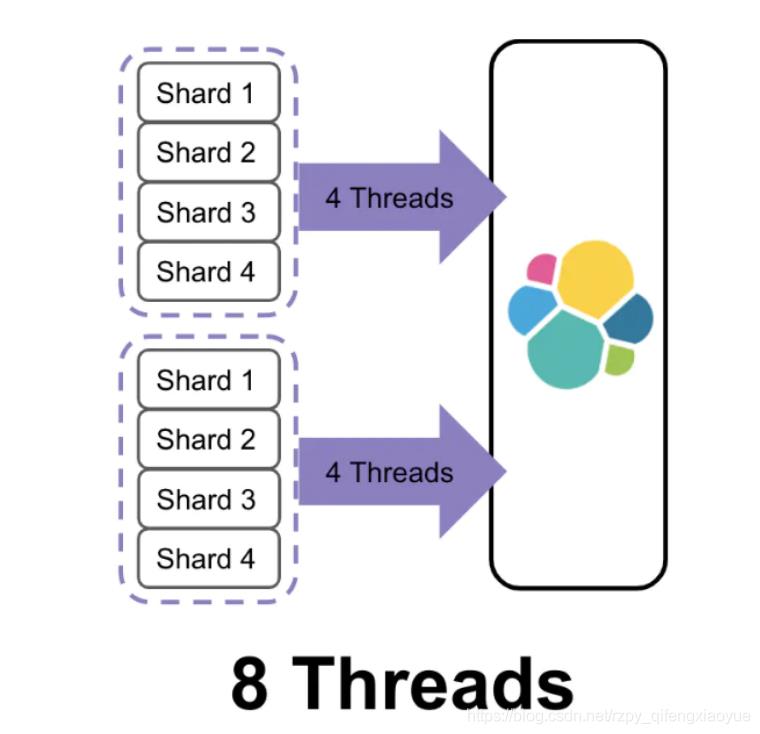
有2批documents写入ES, 每批都需要写入4个shard,所以总共需要8个线程,如果能减少shard的个数,那么耗费的线程个数也会减少,例如下图,两批中每批的shard个数都只有2个,总共线程消耗个数4个,减少一半。
默认的routing就是id,也可以在发送请求的时候,手动指定一个routing value,比如说put/index/doc/id?routing=user_id

值得注意的是线程数虽然降低了,但是单批的处理耗时可能增加了。和提高刷新间隔方法类似,这有可能会延长数据不见的时间
Search(读)调优
在存储的Document条数超过10亿条后,我们如何进行搜索调优
数据分组
很多人拿ES用来存储日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引,如下图,基于天建索引
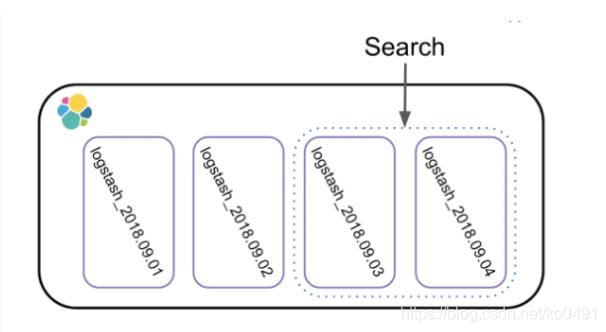
当搜索单天的数据,只需要查询一个索引的shards就可以,当需要查询多天的数据时,需要查询多个索引的shards,这种方案其实和数据库的分表、分库、分区查询方案相比,思路类似,小数据范围查询而不是大海捞针。
开始的方案是建一个index,当数据量增大的时候,就扩容增加index的shard的个数,当shards增大时,要搜索的shards个数也随之显著上升,基于数据分组的思路,可以基于client进行数据分组,每一个client只需依赖自己的index的数据shards进行搜索,而不是所有的数据shards,大大提高了搜索的性能,如下图:

使用Filter替代Query
在搜索时候使用Query,需要为Document的相关度打分,使用Filter,没有打分环节处理,做的事情更少,而且filter理论上更快一些。
如果搜索不需要打分,可以直接使用filter查询,如果部分搜索需要打分,建议使用’bool’查询,这种方式可以把打分的查询和不打分的查询组合在一起使用,如
COPYGET /_search
"query":
"bool":
"must":
"term":
"user": "kimchy"
,
"filter":
"term":
"tag": "tech"
ID字段定义为keyword
一般情况,如果ID字段不会被用作Range 类型搜索字段,都可以定义成keyword类型,这是因为keyword会被优化,以便进行terms查询,Integers等数字类的mapping类型,会被优化来进行range类型搜索,将integers改成keyword类型之后,搜索性能大约能提升30%
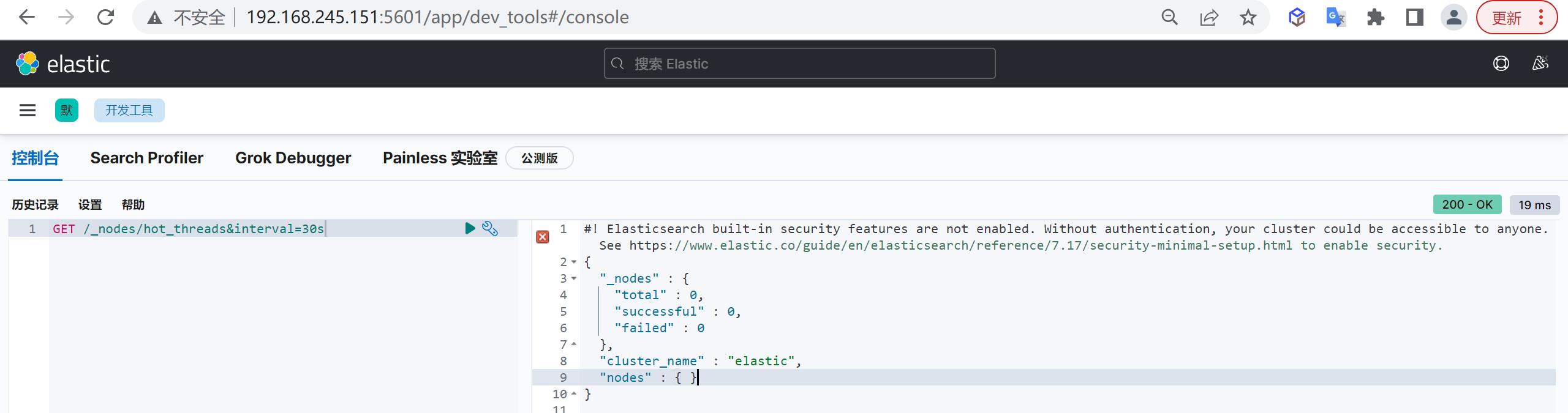
hot_threads
可以使用以下命令,抓取30s区间内的节点上占用资源的热线程,并通过排查占用资源最多的TOP线程来判断对应的资源消耗是否正常
COPYGET /_nodes/hot_threads&interval=30s一般情况下,bulk,search类的线程占用资源都可能是业务造成的,但是如果是merge线程占用了大量的资源,就应该考虑是不是创建index或者刷磁盘间隔太小,批量写入size太小造成的。
pending_tasks
有一些任务只能由主节点去处理,比如创建一个新的索引或者在集群中移动分片,由于一个集群中只能有一个主节点,所以只有这一master节点可以处理集群级别的元数据变动
在99.9999%的时间里,这不会有什么问题,元数据变动的队列基本上保持为零,在一些罕见的集群里,元数据变动的次数比主节点能处理的还快,这会导致等待中的操作会累积成队列,这个时候可以通过pending_tasks api分析当前什么操作阻塞了es的队列,比如,集群异常时,会有大量的shard在recovery,如果集群在大量创建新字段,会出现大量的put_mappings的操作,所以正常情况下,需要禁用动态mapping。
COPYGET /_cluster/pending_tasks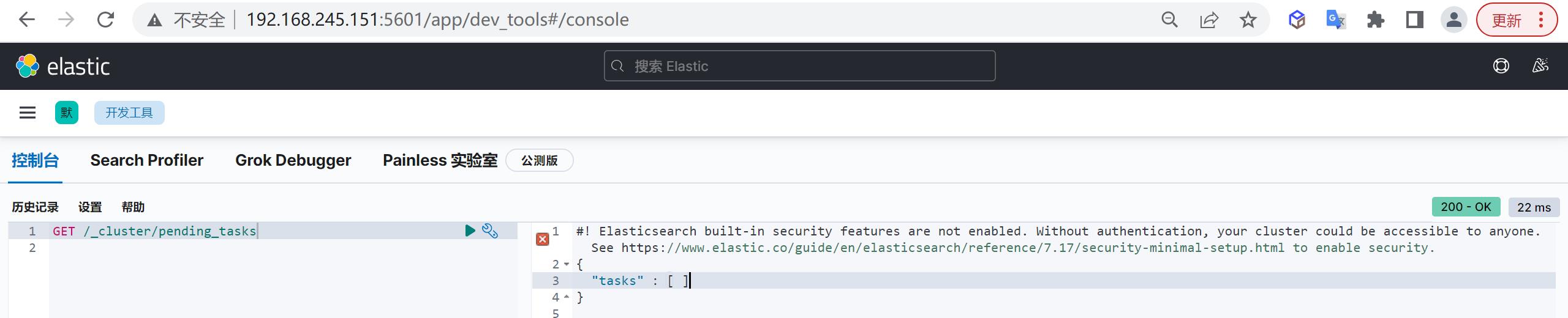
字段存储
当前es主要有doc_values,fielddata,storefield三种类型,大部分情况下,并不需要三种类型都存储,可根据实际场景进行调整:
当前用得最多的就是doc_values,列存储,对于不需要进行分词的字段,都可以开启doc_values来进行存储(且只保留keyword字段),节约内存,当然,开启doc_values会对查询性能有一定的影响,但是,这个性能损耗是比较小的,而且是值得的;
fielddata构建和管理 100% 在内存中,常驻于 JVM 内存堆,所以可用于快速查询,但是这也意味着它本质上是不可扩展的,有很多边缘情况下要提防,如果对于字段没有分析需求,可以关闭fielddata;
storefield主要用于_source字段,默认情况下,数据在写入es的时候,es会将doc数据存储为_source字段,查询时可以通过_source字段快速获取doc的原始结构,如果没有update,reindex等需求,可以将_source字段disable;
_all,ES在6.x以前的版本,默认将写入的字段拼接成一个大的字符串,并对该字段进行分词,用于支持整个doc的全文检索,在知道doc字段名称的情况下,建议关闭掉该字段,节约存储空间,也避免不带字段key的全文检索;
norms:搜索时进行评分,日志场景一般不需要评分,建议关闭;
事务日志
Elasticsearch 2.0之后为了保证不丢数据,每次 index、bulk、delete、update 完成的时候,一定会触发同步刷新 translog 到磁盘上,才给请求返回 200 OK
异步刷新
采用异步刷新,这个改变在提高数据安全性的同时当然也降低了一点性能,如果你不在意这点可能性,还是希望性能优先,可以在 index template 里设置如下参数
COPY
"index.translog.durability": "async"
其他参数
index.translog.sync_interval
对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的,比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync ,默认为5s,小于的值100ms是不允许的。
index.translog.flush_threshold_size
translog存储尚未安全保存在Lucene中的所有操作,虽然这些操作可用于读取,但如果要关闭并且必须恢复,则需要重新编制索引,此设置控制这些操作的最大总大小,以防止恢复时间过长,达到设置的最大size后,将发生刷新,生成新的Lucene提交点,默认为512mb。
refresh_interval
执行刷新操作的频率,这会使索引的最近更改对搜索可见,默认为1s,可以设置-1为禁用刷新,对于写入速率要求较高的场景,可以适当的加大对应的时长,减小磁盘io和segment的生成;
禁止动态mapping
动态mapping的缺点
- 造成集群元数据一直变更,导致 不稳定;
- 可能造成数据类型与实际类型不一致;
- 对于一些异常字段或者是扫描类的字段,也会频繁的修改mapping,导致业务不可控。
映射配置
动态mapping配置的可选值及含义如下
- true:支持动态扩展,新增数据有新的字段属性时,自动添加对于的mapping,数据写入成功
- false:不支持动态扩展,新增数据有新的字段属性时,直接忽略,数据写入成功
- strict:不支持动态扩展,新增数据有新的字段时,报错,数据写入失败
批量写入
批量请求显然会大大提升写入速率,且这个速率是可以量化的,官方建议每次批量的数据物理字节数5-15MB是一个比较不错的起点,注意这里说的是物理字节数大小。
文档计数对批量大小来说不是一个好指标,比如说,如果你每次批量索引 1000 个文档,记住下面的事实:1000 个 1 KB 大小的文档加起来是 1 MB 大,1000 个 100 KB 大小的文档加起来是 100 MB 大。
这可是完完全全不一样的批量大小了,批量请求需要在协调节点上加载进内存,所以批量请求的物理大小比文档计数重要得多,从 5–15 MB 开始测试批量请求大小,缓慢增加这个数字,直到你看不到性能提升为止。
然后开始增加你的批量写入的并发度(多线程等等办法),用iostat 、 top 和 ps 等工具监控你的节点,观察资源什么时候达到瓶颈。如果你开始收到 EsRejectedExecutionException ,你的集群没办法再继续了:至少有一种资源到瓶颈了,或者减少并发数,或者提供更多的受限资源(比如从机械磁盘换成 SSD),或者添加更多节点。
索引和shard
es的索引,shard都会有对应的元数据,
因为es的元数据都是保存在master节点,且元数据的更新是要hold住集群向所有节点同步的,当es的新建字段或者新建索引的时候,都会要获取集群元数据,并对元数据进行变更及同步,此时会影响集群的响应,所以需要关注集群的index和shard数量,
使用建议
建议如下
- 使用shrink和rollover api,相对生成合适的数据shard数;
- 根据数据量级及对应的性能需求,选择创建index的名称,形如:按月生成索引:test-YYYYMM,按天生成索引:test-YYYYMMDD;
- 控制单个shard的size,正常情况下,日志场景,建议单个shard不大于50GB,线上业务场景,建议单个shard不超过20GB;
段合并
段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O
合并在后台定期操作,因为他们可能要很长时间才能完成,尤其是比较大的段,这个通常来说都没问题,因为大规模段合并的概率是很小的。
如果发现merge占用了大量的资源,可以设置:index.merge.scheduler.max_thread_count: 1 特别是机械磁盘在并发 I/O 支持方面比较差,所以我们需要降低每个索引并发访问磁盘的线程数,这个设置允许 max_thread_count + 2 个线程同时进行磁盘操作,也就是设置为 1 允许三个线程,对于 SSD,你可以忽略这个设置,默认是 Math.min(3, Runtime.getRuntime().availableProcessors() / 2) ,对 SSD 来说运行的很好。
业务低峰期通过force_merge强制合并segment,降低segment的数量,减小内存消耗;关闭冷索引,业务需要的时候再进行开启,如果一直不使用的索引,可以定期删除,或者备份到hadoop集群;
自动生成_id
当写入端使用特定的id将数据写入es时,es会去检查对应的index下是否存在相同的id,这个操作会随着文档数量的增加而消耗越来越大,所以如果业务上没有强需求,建议使用es自动生成的id,加快写入速率。
routing
对于数据量较大的业务查询场景,es侧一般会创建多个shard,并将shard分配到集群中的多个实例来分摊压力,正常情况下,一个查询会遍历查询所有的shard,然后将查询到的结果进行merge之后,再返回给查询端。
此时,写入的时候设置routing,可以避免每次查询都遍历全量shard,而是查询的时候也指定对应的routingkey,这种情况下,es会只去查询对应的shard,可以大幅度降低合并数据和调度全量shard的开销。
使用alias
生产提供服务的索引,切记使用别名提供服务,而不是直接暴露索引名称,避免后续因为业务变更或者索引数据需要reindex等情况造成业务中断。
避免宽表
在索引中定义太多字段是一种可能导致映射爆炸的情况,这可能导致内存不足错误和难以恢复的情况,这个问题可能比预期更常见,index.mapping.total_fields.limit ,默认值是1000
避免稀疏索引
因为索引稀疏之后,对应的相邻文档id的delta值会很大,lucene基于文档id做delta编码压缩导致压缩率降低,从而导致索引文件增大,同时,es的keyword,数组类型采用doc_values结构,每个文档都会占用一定的空间,即使字段是空值,所以稀疏索引会造成磁盘size增大,导致查询和写入效率降低。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、转发、在看。您的支持是我坚持写作最大的动力。
作者: 博学谷狂野架构师
GitHub地址:GitHub地址 (有我们精心准备的130本电子书PDF)
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
String 还能这样性能调优,我直呼内行
❝String 还能优化啥?你是不是框我?
莫慌,今天给大家见识一下不一样的 String,从根上拿捏直达 G 点。
并且码哥分享一个例子:通过性能调优我们能实现百兆内存轻松存储几十 G 数据。
String对象是我们每天都「摸」的对象类型,但是她的性能问题我们却总是忽略。
爱她,不能只会简单一起玩耍,要深入了解String 的内心深处,做一个「心有猛虎,细嗅蔷薇」的暖男。
通过以下几点分析,我们一步步揭开她的神秘面纱,让 String 直接起飞:
字符串对象的特性;
String 的不可变性;
大字符串构建技巧;
String.intern 节省内存;
字符串分割技巧;
String 身体解密
想要深入了解,就先从基本组成开始……
「String 缔造者」对 String 对象做了大量优化来节省内存,从而提升 String 的性能:
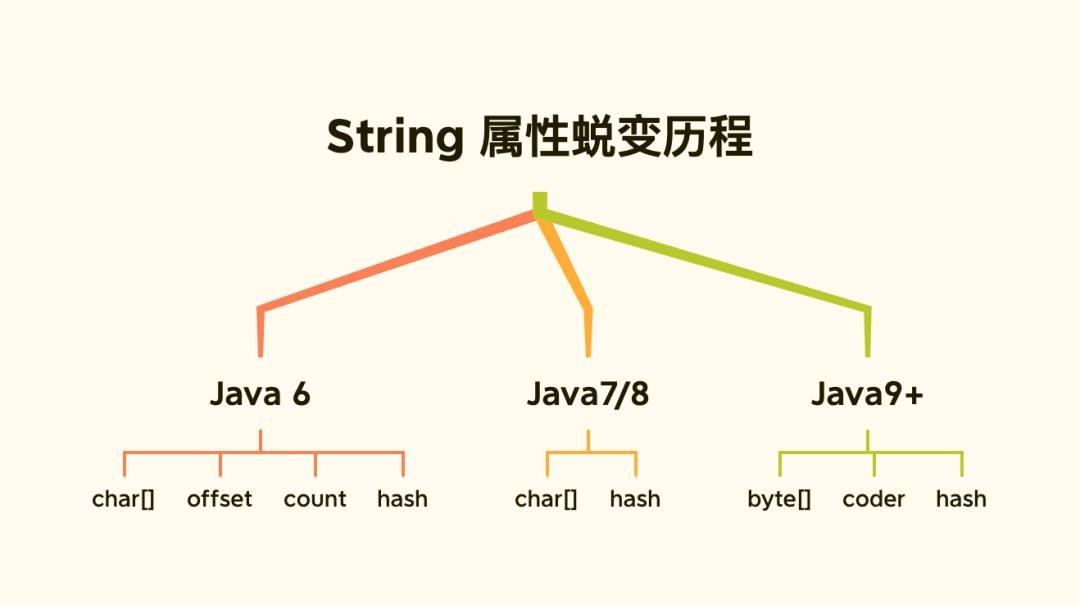
Java 6 及之前
数据存储在 char[]数组中,String通过 offset 和 count两个属性定位 char[] 数据获取字符串。
这样可以高效快速的定位并共享数组对象,并且节省内存,但是有可能导致内存泄漏。
❝共享 char 数组为啥可能会导致内存泄漏呢?
String(int offset, int count, char value[])
this.value = value;
this.offset = offset;
this.count = count;
public String substring(int beginIndex, int endIndex)
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
调用 substring() 的时候虽然创建了新的字符串,但字符串的值 value 仍然指向的是内存中的同一个数组,如下图所示:
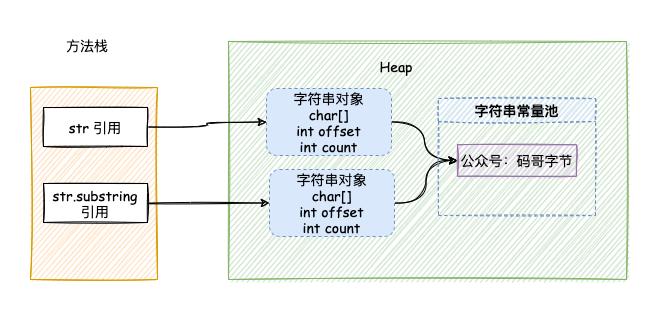
如果我们仅仅是用 substring 获取一小段字符,而原始 string字符串非常大的情况下,substring 的对象如果一直被引用。
此时 String 字符串也无法回收,从而导致内存泄露。
如果有大量这种通过 substring 获取超大字符串中一小段字符串的操作,会因为内存泄露而导致内存溢出。
JDK7、8
去掉了 offset 和 count两个变量,减少了 String 对象占用的内存。
substring 源码:
public String(char value[], int offset, int count)
this.value = Arrays.copyOfRange(value, offset, offset + count);
public String substring(int beginIndex, int endIndex)
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
substring() 通过 new String() 返回了一个新的字符串对象,在创建新的对象时通过 Arrays.copyOfRange() 深度拷贝了一个新的字符数组。
如下图所示:
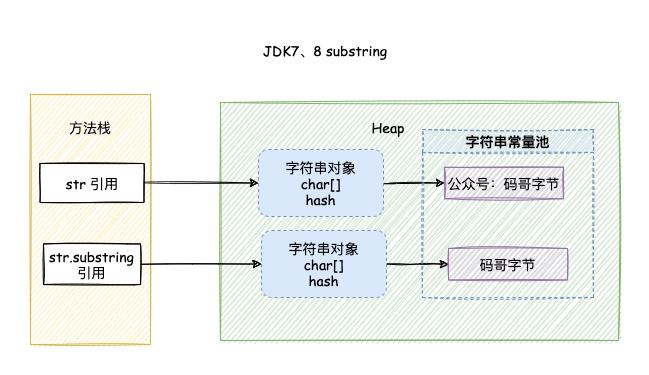
String.substring 方法不再共享 char[]数组的数据,解决了可能内存泄漏的问题。
Java 9
将 char[]字段改为 byte[],新增 coder属性。
❝码哥,为什么这么改呢?
一个 char 字符占 2 个字节,16 位。存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。
为了节约内存空间,于是使用了 1 个字节占 8 位的 byte 数组来存放字符串。
勤俭节约的女神,谁不爱……
新属性 coder 的作用是:在计算字符串长度或者使用 indexOf()方法时,我们需要根据编码类型来计算字符串长度。
coder 的值分别表示不同编码类型:
0:表示使用
Latin-1(单字节编码);1:使用
UTF-16。
String 的不可变性
了解了String 的基本组成之后,发现 String 还有一个比外在更性感的特性,她被 final关键字修饰,char 数组也是。
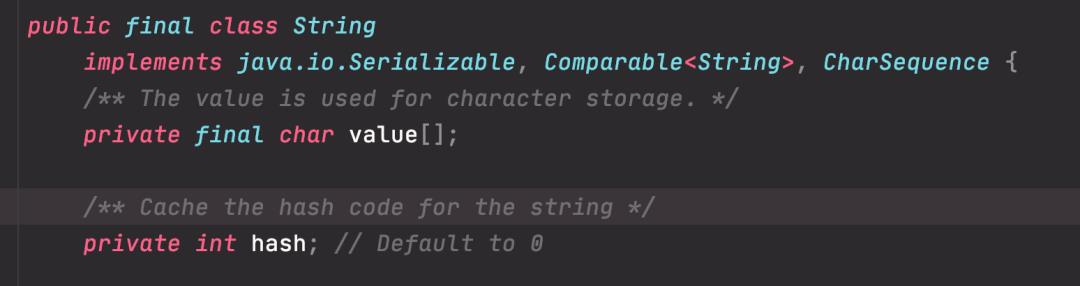
我们知道类被 final 修饰代表该类不可继承,而 char[]被 final+private 修饰,代表了 String 对象不可被更改。
String 对象一旦创建成功,就不能再对它进行改变。
final 修饰的好处
安全性
当你在调用其他方法时,比如调用一些系统级操作指令之前,可能会有一系列校验。
如果是可变类的话,可能在你校验过后,它的内部的值又被改变了,这样有可能会引起严重的系统崩溃问题。
高性能缓存
String不可变之后就能保证 hash值得唯一性,使得类似 HashMap容器才能实现相应的 key-value 缓存功能。
实现字符串常量池
由于不可变,才得以实现字符串常量池。
字符串常量池指的是在创建字符串的时候,先去「常量池」查找是否创建过该「字符串」;
如果有,则不会开辟新空间创建字符串,而是直接把常量池中该字符串的引用返回给此对象。
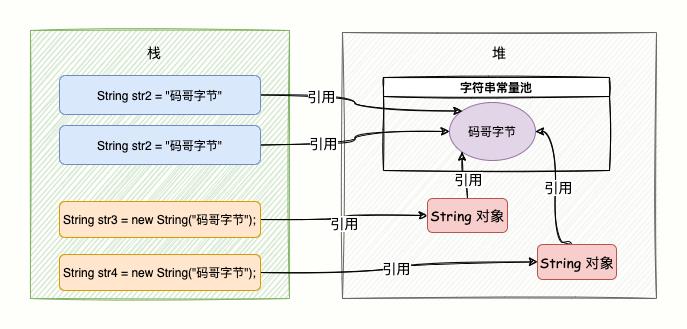
创建字符串的两种方式:
String str1 = “码哥字节”;
String str2 = new String(“码哥字节”);
当代码中使用第一种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用。
否则新的字符串将在常量池中被创建,并返回该引用。
这样可以减少同一个值的字符串对象的重复创建,节约内存。
第二种方式创建,在编译类文件时,"码哥字节" 字符串将会放入到常量结构中,在类加载时,“码哥字节" 将会在常量池中创建;
在调用 new 时,JVM 命令将会调用 String 的构造函数,在堆内存中创建一个 String 对象,同时该对象指向「常量池」中的“码哥字节”字符串,str 指向刚刚在堆上创建的 String 对象;
如下图(str1、str2):
❝什么是对象和对象引用呀?
str 属于方法栈的字面量,它指向堆中的 String 对象,并不是对象本。
对象在内存中是一块内存地址,str 则是指向这个内存地址的引用。
也就是说 str 并不是对象,而只是一个对象引用。
❝码哥,字符串的不可变到底指的是什么呀?
String str = "Java";
str = "Java,yyds"第一次赋值 「Java」,第二次赋值「Java,yyds」,str 值确实改变了,为什么我还说 String 对象不可变呢?
这是因为 str 只是 String 对象的引用,并不是对象本身。
真正的对象依然还在内存中,没有被改变。
优化实战
了解了 String 的对象实现原理和特性,是时候要深入女神内心,结合实际场景,如何更上一层楼优化 String 对象的使用。
大字符串如何构建
既然 String 对象是不可变,所以我们在频繁拼接字符串的时候是否意味着创建多个对象呢?
String str = "癞蛤蟆撩青蛙" + "长的丑" + "玩的花";是不是以为先生成「癞蛤蟆撩青蛙」对象,再生成「癞蛤蟆撩青蛙长的丑」对象,最后生成「癞蛤蟆撩青蛙长得丑玩的花」对象。
实际运行中,只有一个对象生成。
❝这是为什么呢?
虽然代码写的丑陋,但是编译器自动优化了代码。
再看下面例子:
String str = "小青蛙";
for(int i=0; i<1000; i++)
str += i;
上面的代码编译后,你可以看到编译器同样对这段代码进行了优化。
Java 在进行字符串的拼接时,偏向使用 StringBuilder,这样可以提高程序的效率。
String str = "小青蛙";
for(int i=0; i<1000; i++)
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
即使如此,还是循环内重复创建 StringBuilder对象。
敲黑板
所以做字符串拼接的时候,我建议你还是要显式地使用 String Builder 来提升系统性能。
如果在多线程编程中,String 对象的拼接涉及到线程安全,你可以使用 StringBuffer。
运用 intern 节省内存
直接看intern() 方法的定义与源码:

intern() 是一个本地方法,它的定义中说的是,当调用 intern 方法时,如果字符串常量池中已经包含此字符串,则直接返回此字符串的引用。
否则将此字符串添加到常量池中,并返回字符串的引用。
如果不包含此字符串,先将字符串添加到常量池中,再返回此对象的引用。
❝什么情况下适合使用
intern()方法?
Twitter 工程师曾分享过一个 String.intern() 的使用示例,Twitter 每次发布消息状态的时候,都会产生一个地址信息,以当时 Twitter 用户的规模预估,服务器需要 20G 的内存来存储地址信息。
public class Location
private String city;
private String region;
private String countryCode;
private double longitude;
private double latitude;
考虑到其中有很多用户在地址信息上是有重合的,比如,国家、省份、城市等,这时就可以将这部分信息单独列出一个类,以减少重复,代码如下:
public class SharedLocation
private String city;
private String region;
private String countryCode;
public class Location
private SharedLocation sharedLocation;
double longitude;
double latitude;
通过优化,数据存储大小减到了 20G 左右。
但对于内存存储这个数据来说,依然很大,怎么办呢?
Twitter 工程师使用 String.intern() 使重复性非常高的地址信息存储大小从 20G 降到几百兆,从而优化了 String 对象的存储。
核心代码如下:
SharedLocation sharedLocation = new SharedLocation();
sharedLocation.setCity(messageInfo.getCity().intern());
sharedLocation.setCountryCode(messageInfo.getRegion().intern());
sharedLocation.setRegion(messageInfo.getCountryCode().intern());弄个简单例子方便理解:
String a =new String("abc").intern();
String b = new String("abc").intern();
System.out.print(a==b);输出结果:true。
在加载类的时候会在常量池中创建一个字符串对象,内容是「abc」。
创建局部 a 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串。
在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
创建 b 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串。
在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用给局部变量。
而刚在堆内存中的两个对象,由于没有引用指向它,将会被垃圾回收。
所以 a 和 b 引用的是同一个对象。
字符串分割有妙招
Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的。
使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
Java 正则表达式使用的引擎实现是 NFA(Non deterministic Finite Automaton,确定型有穷自动机)自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking),而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
所以我们应该慎重使用 Split() 方法,我们可以用String.indexOf()方法代替 Split() 方法完成字符串的分割。
总结与思考
我们从 String 进化历程掌握了她的组成,不断的改变成员变量节约内存。
她的不可变性从而实现了字符串常量池,减少同一个字符串的重复创建,节约内存。
但也是因为这个特性,我们在做长字符串拼接时,需要显示使用 StringBuilder,以提高字符串的拼接性能。
最后,在优化方面,我们还可以使用 intern 方法,让变量字符串对象重复使用常量池中相同值的对象,进而节约内存。
通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?代码如下:
String str1 = "abc";
String str2 = new String("abc");
String str3 = str2.intern();
assertSame(str1 == str2);
assertSame(str2 == str3);
assertSame(str1 == str3)跟码哥一起学习,道路上不迷路。
以上是关于ElasticSearch还能性能调优,涨见识涨见识了!!!的主要内容,如果未能解决你的问题,请参考以下文章
域名还能绑定动态IP?真是又涨见识了,再也不用购买固定IP了,赶快收藏
域名还能绑定动态IP?真是又涨见识了,再也不用购买固定IP了,赶快收藏