ES-pinyin分词器安装
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES-pinyin分词器安装相关的知识,希望对你有一定的参考价值。
参考技术A 该安装地址可以参考github开源项目 elasticsearch-analysis-pinyin运行上面的测试示例,结果如下:
这个插件包含:analyzer: pinyin ,tokenizer: pinyin 和token-filter: pinyin ,同时支持部分自定义选项.
分词器以及ik中文分词器
文章目录
分词器以及ik中文分词器
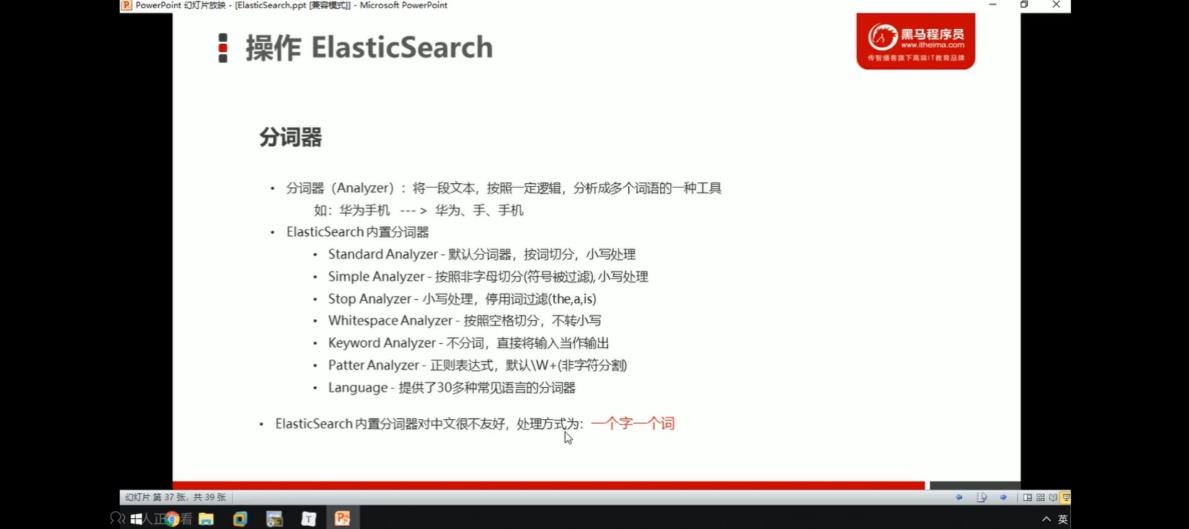
概念
ik分词器的安装
因为es自带的分词器对英文非常友好,但是对中文很不友好,所以我们需要安装一个ik分词器。
特点
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包;
是一个基于Maven构建的项目;
具有60万字/秒的告诉处理能力;
支持用户词典扩展定义;
环境准备
Elasticsearch需要使用ik,就要先构建ik的jar包,这里要用到maven包管理工具,而maven需要java环境,而Elasticsearch内置了jdk,所以可以将JAVA_HOME设置为Elasticsearch内置的jdk。
设置jdk环境变量
vim /etc/profile
#在文件末尾添加jdk的环境变量
export JAVA_HOME=/opt/elasticsearch-7.16.2/jdk
export PATH=$PATH:$JAVA_HOME/bin
#保存退出后,重新加载profile
source /etc/profile
下载maven安装包并解压

设置path
打开文件
vim /etc/profile.d/maven.sh
将下面的内容复制到文件,保存
export MAVEN_HOME=/opt/apache-maven-3.8.4
export PATH=$MAVEN_HOME/bin:$PATH
设置好Maven的路径之后,需要运行下面的命令使其生效
source /etc/profile.d/maven.sh
验证maven是否安装成功
mvn -v

下载IK分词器并安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
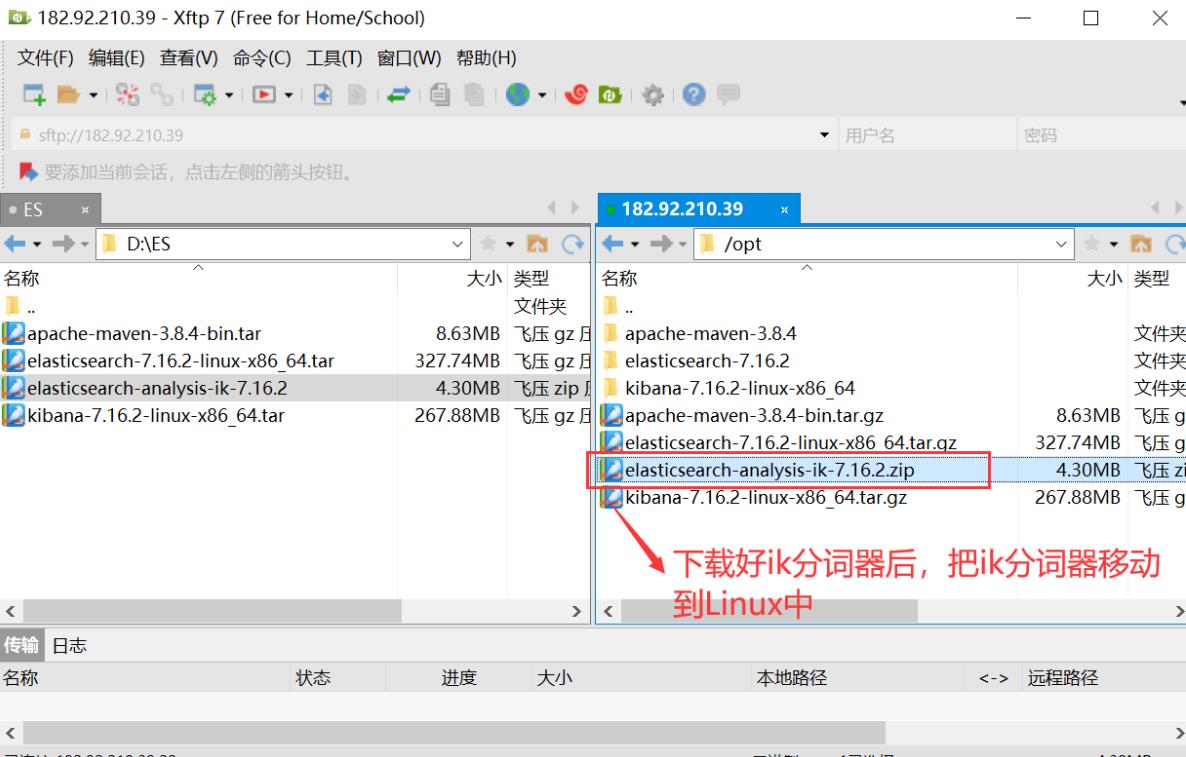
然后把zip包安装到elasticsearch/plugins目录下新建的目录analysis-ik,并解压,如下图:

然后解压ik分词器,因为ik分词器是zip包,所以需要使用unzip命令解压,如下图:

解压之后需要把ik的config目录中的所有内容复制到elasticsearch-7.16.2的config配置文件中,如下图:
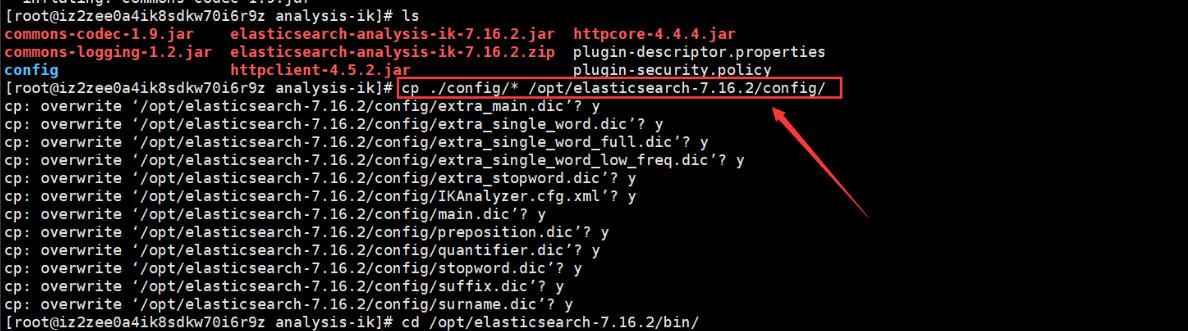
最后记得一定要重启Elasticsearch服务!!!
使用IK分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1.ik_max_word
会将文本做最细颗粒度的拆分,如下图:
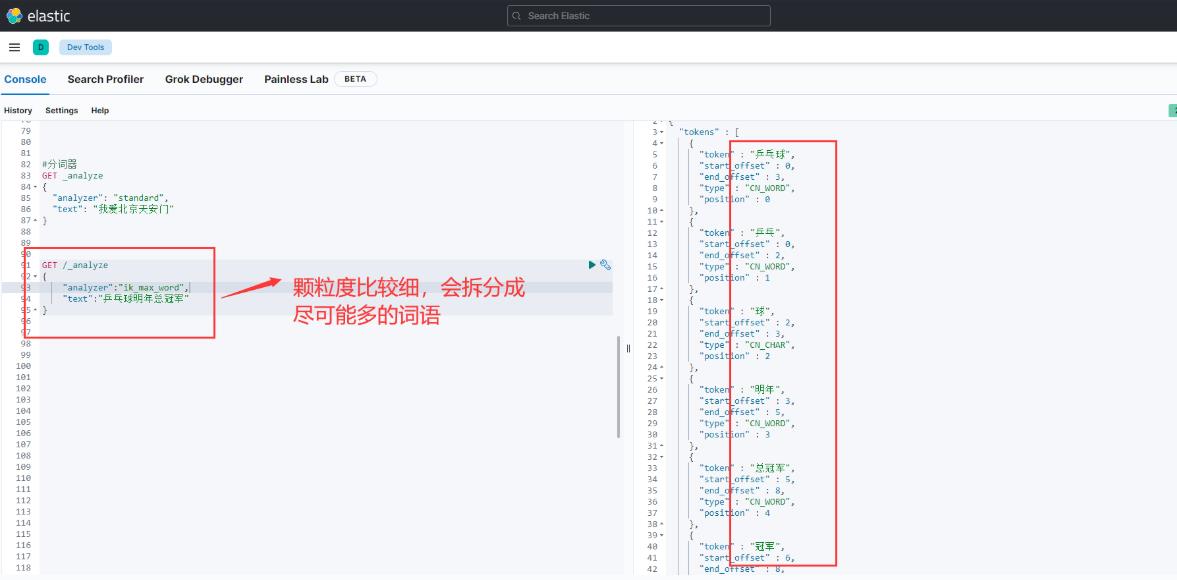
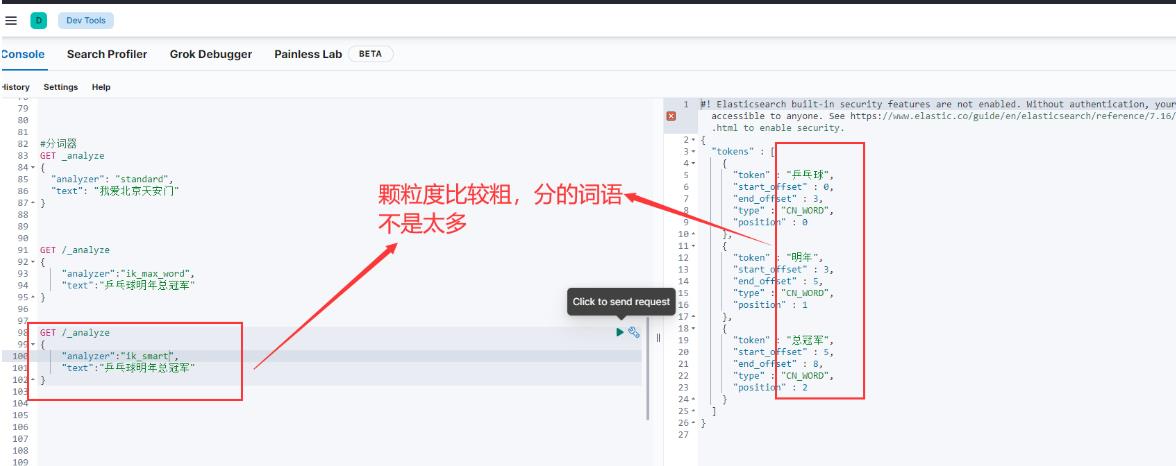
2.ik_smart
这个分词模式的颗粒度比较粗,如下图:
查询文档
词条查询:term
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索。
全文查询:match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
term词条查询
term词条查询的例子如下图:

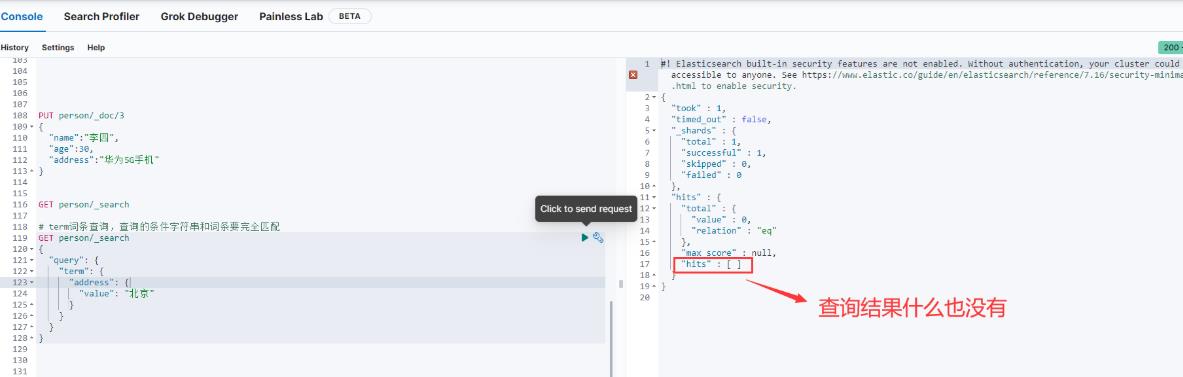
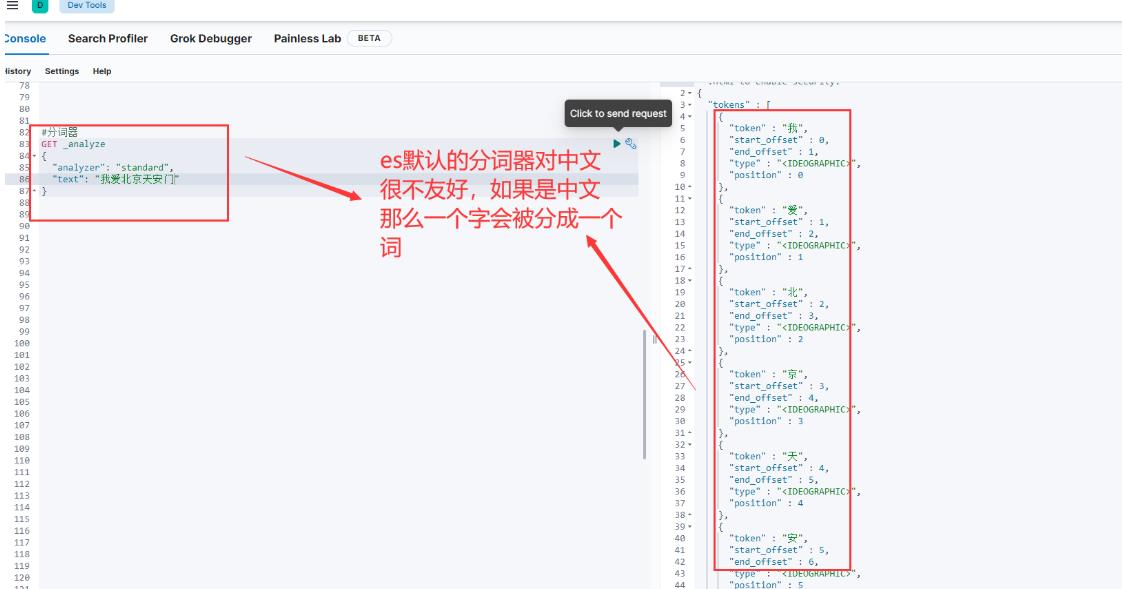
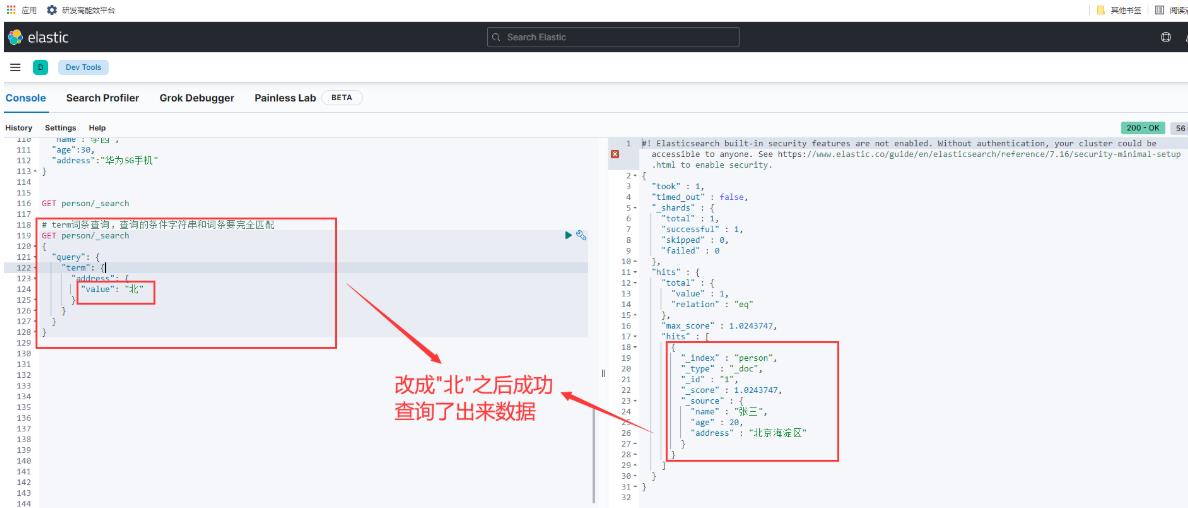
为什么什么结果都没有查出来呢?主要是因为ES默认使用的是standar分词器,会把中文一个字一个字的分,所以查不到,如果我们查询的是"北"就能成功查询出来数据了,如下图:
因此我们在创建索引的时候,就要手动的添加索引为ik分词器,要不然ES使用的一直是默认的standar分词器。
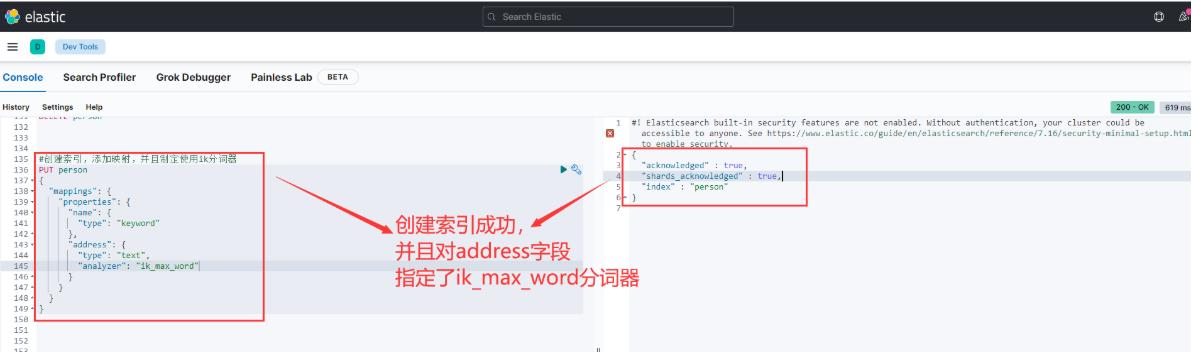
然后添加三条文档,如下图:
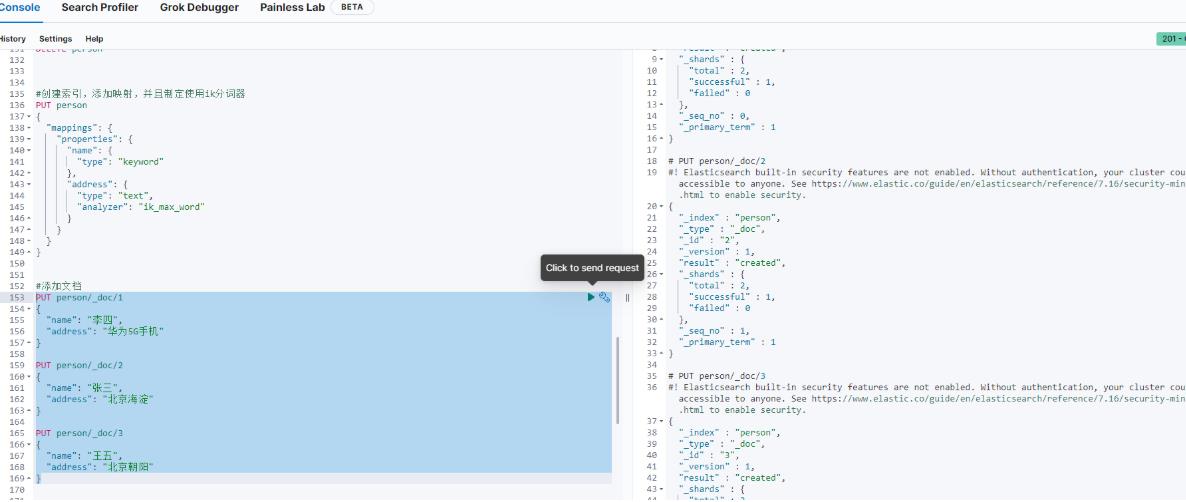
查询一下结果,如下图:

重新搜索“北京”关键词,如下图:
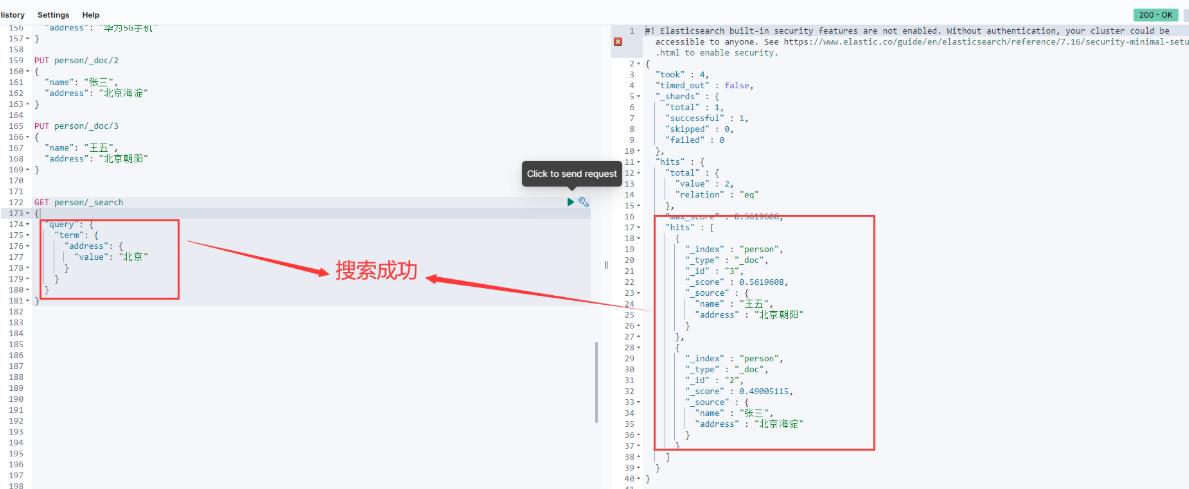
但是如果我现在搜索的词条是"北京昌平",因为我们的文档中没有address字段为"北京昌平"的分词,所以结果什么也查不到,如下图:
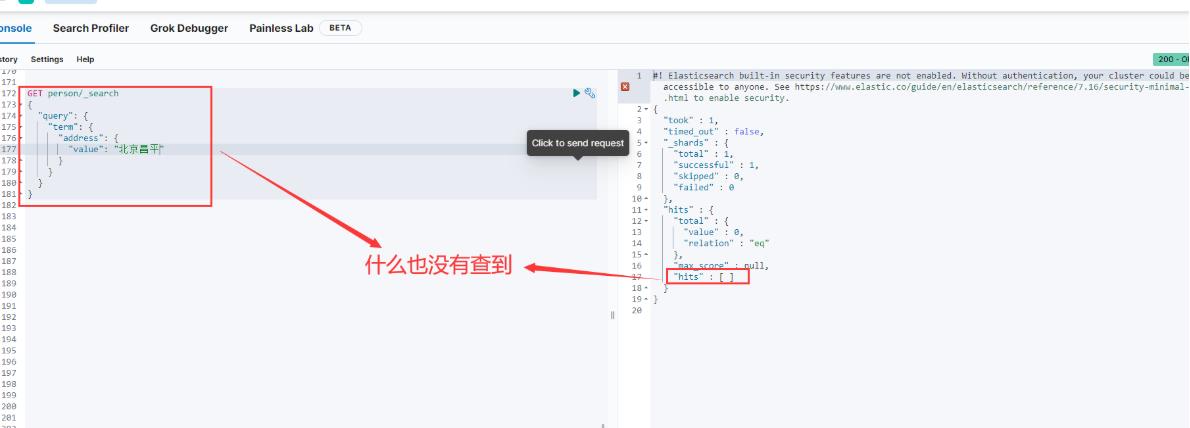
这就是term词条查询,它的搜索关键字会被当做一个整体,不会继续分词,然后拿这个整体去分词库中查询。但是下面的match全文查询不是这样的,它会先把搜索关键字分词,然后拿所有的分词结果去分词库中查询,最后再把查询结果拼接在一起。
match全文查询
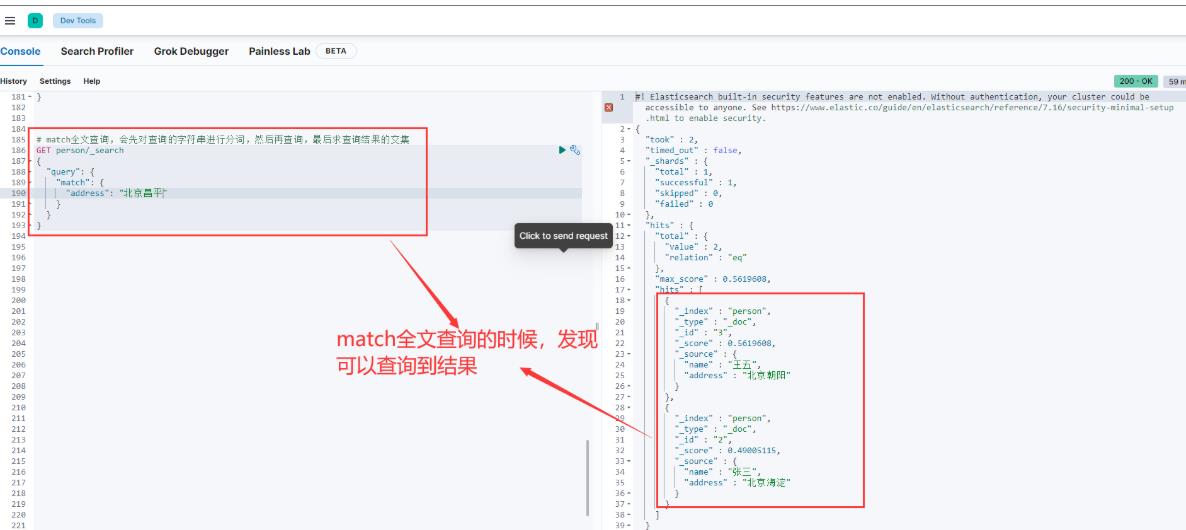
上面是查询结果的并集,不是查询结果的交集。
以上是关于ES-pinyin分词器安装的主要内容,如果未能解决你的问题,请参考以下文章
(06)ElasticSearch 分词器介绍及安装中文分词器