Elasticsearch 分布式搜索引擎 -- 安装IK分词器ik分词器-拓展词库 / 停用词库
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 分布式搜索引擎 -- 安装IK分词器ik分词器-拓展词库 / 停用词库相关的知识,希望对你有一定的参考价值。
文章目录
1. 安装IK分词器
1.1 分词器介绍

运行结果:
发现中文分词就是一个字一个字的分,而英文可以很好的按照单词来分:
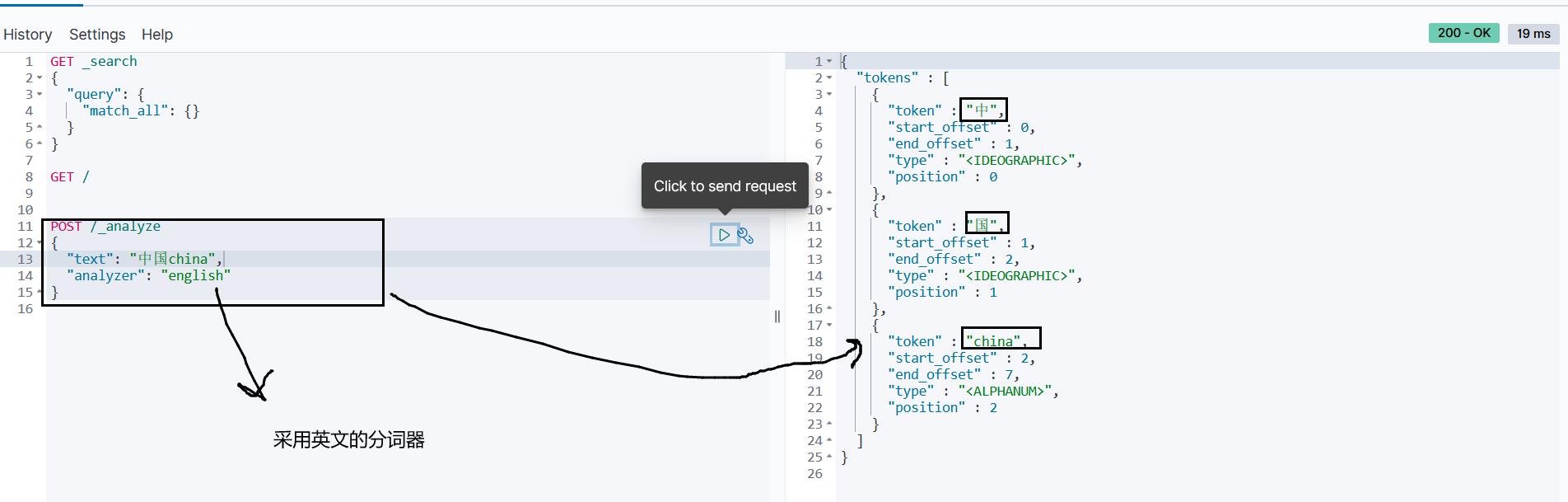
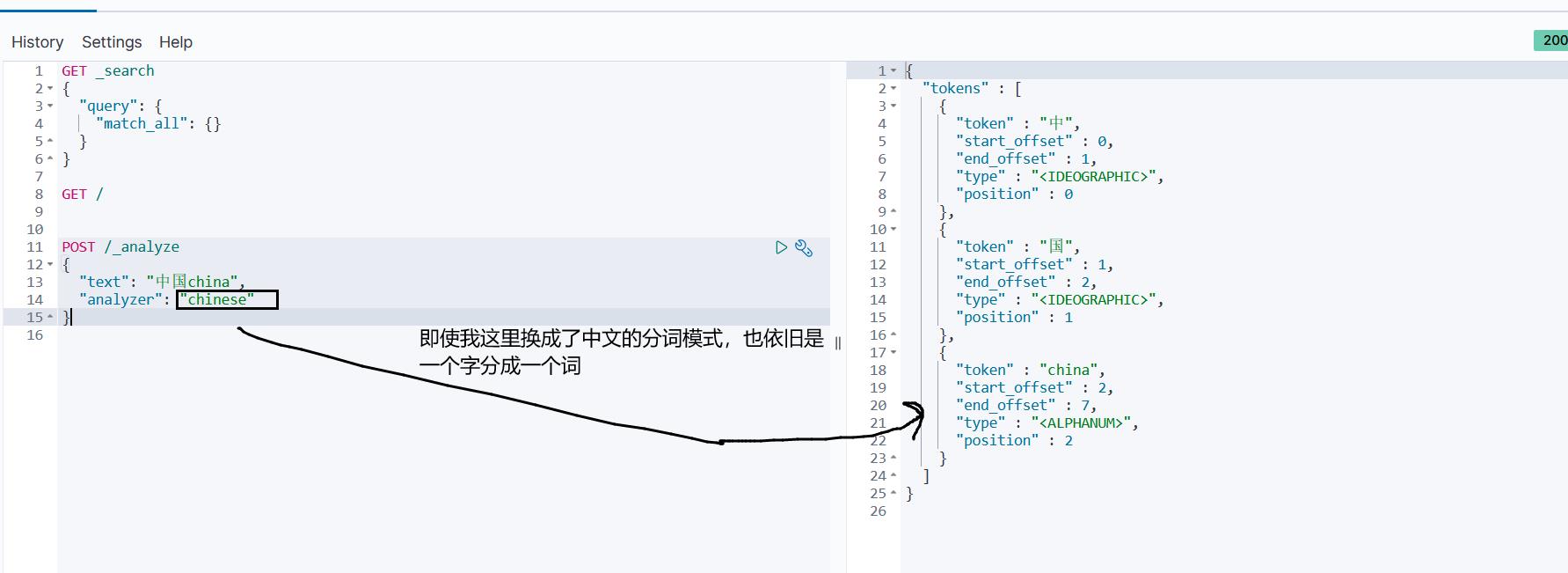

1.2 安装IK分词器
处理中文分词,一般会使用 IK分词器。

按照步骤为:
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart es
1.3 测试
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
1.3.1 ik_smart
POST /_analyze
"text": "小猴子喜欢吃大香蕉",
"analyzer": "ik_smart"
运行结果:
"tokens" : [
"token" : "小猴子",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
,
"token" : "喜欢吃",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
,
"token" : "大",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 2
,
"token" : "香蕉",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
]
1.3.2 ik_max_word
POST /_analyze
"text": "小猴子喜欢吃大香蕉",
"analyzer": "ik_max_word"
运行结果:
"tokens" : [
"token" : "小猴子",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
,
"token" : "猴子",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
,
"token" : "喜欢吃",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
,
"token" : "喜欢",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
,
"token" : "吃",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
,
"token" : "大",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 5
,
"token" : "香蕉",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 6
]
1.4 ik分词器:词库说明
分词器的原理是里面罗列了一个字典,把已经有的这些词语给他存进去,然后字符串取匹配这个字典来进行分词。但是这样存在一些问题,比如:分词器的作者不可能知道这个世界上面所有的词语、有一些词语是最近跟着潮流才产生的,作者不可能直接一有一次就去更新一次分词器的词库。
测试:
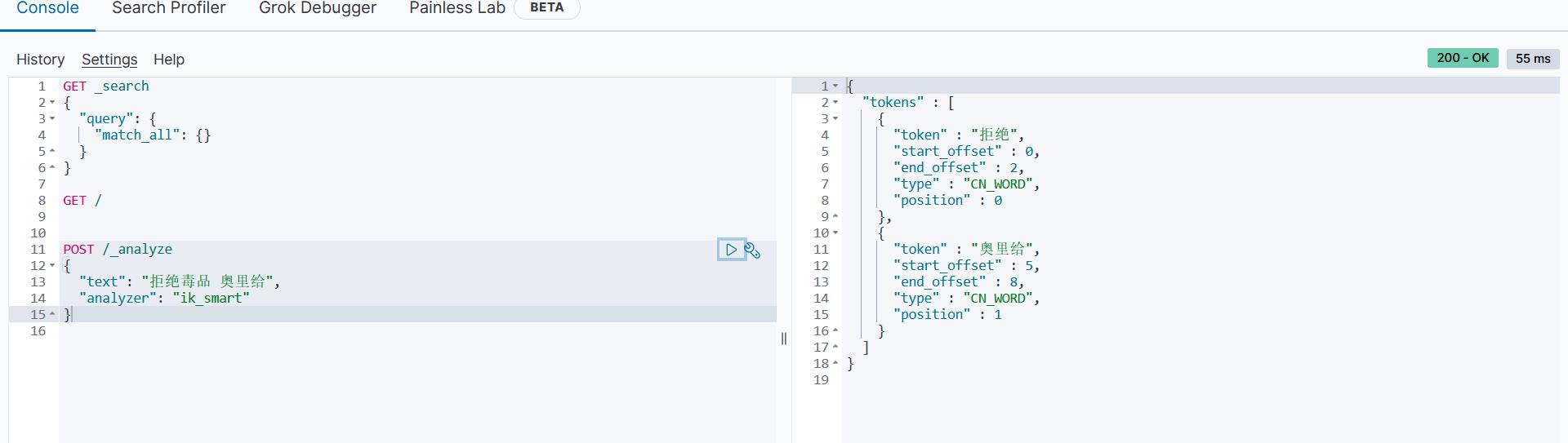
POST /_analyze
"text": "拒绝毒品 奥里给",
"analyzer": "ik_smart"
运行结果:
我们发现,对于 奥里给 这种词语,直接被拆分为了[奥、里、给],而且也把毒品 这2个字搜索出来了。
"tokens" : [
"token" : "拒绝",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
,
"token" : "毒品",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
,
"token" : "奥",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 2
,
"token" : "里",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
,
"token" : "给",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
]
1.4 ik分词器-拓展词库 / 停用词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的lkAnalyzer.cfg.xml文件:

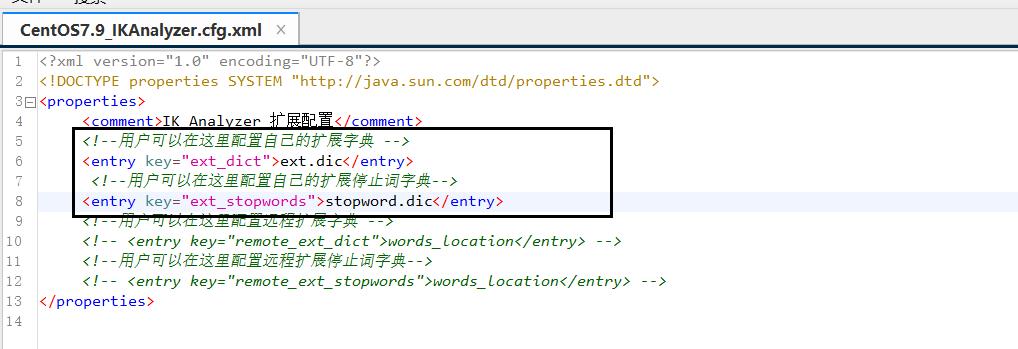
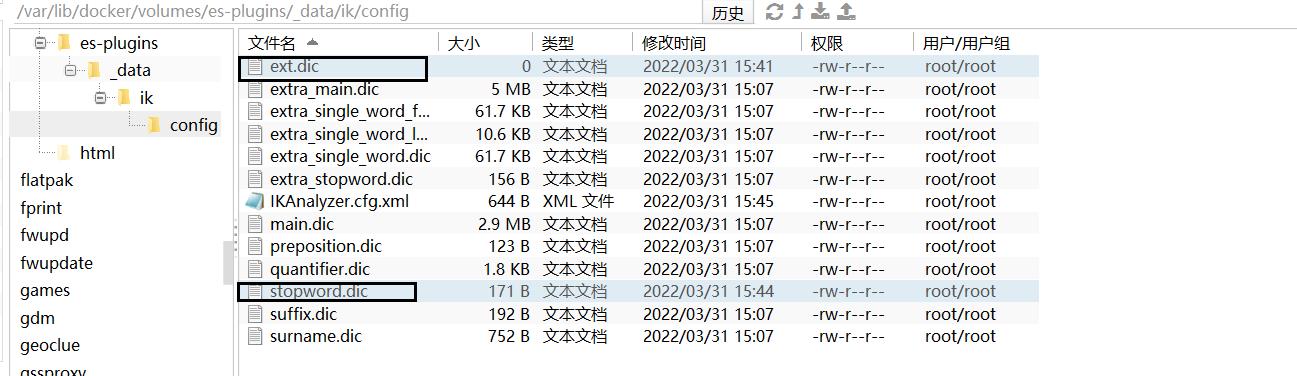
然后在名为ext.dic的文件中,添加想要拓展的词语。在名为stopword.dic的文件里面添加想要停用的词语(如果没有这2个文件,就在当前目录新建这2个文件):


修改完后重启容器
docker restart elasticsearch
测试:
POST /_analyze
"text": "拒绝毒品 奥里给",
"analyzer": "ik_smart"
运行结果:
1.5 小结

以上是关于Elasticsearch 分布式搜索引擎 -- 安装IK分词器ik分词器-拓展词库 / 停用词库的主要内容,如果未能解决你的问题,请参考以下文章