kettle实现从api接口全量抽取数据到数据库中
Posted 大威天龙豁哈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kettle实现从api接口全量抽取数据到数据库中相关的知识,希望对你有一定的参考价值。
1.获取api接口的url地址,这个客户会提供相应的api接口
2.根据接口的信息在数据库中建表和字段

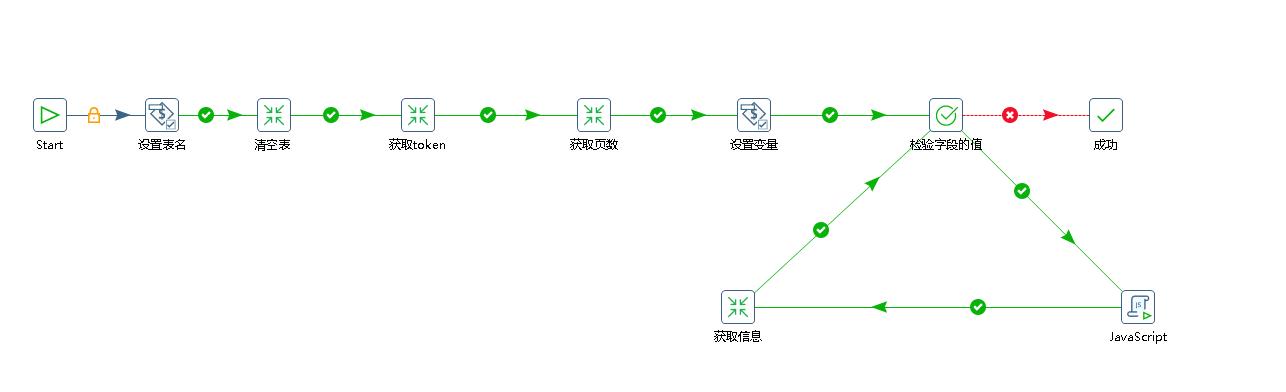
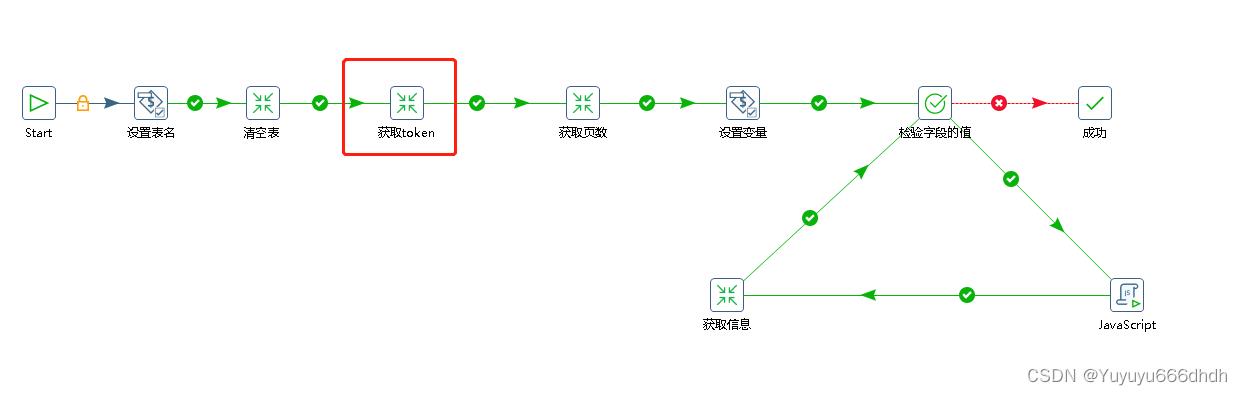
3.kettle作业整体流程图如下
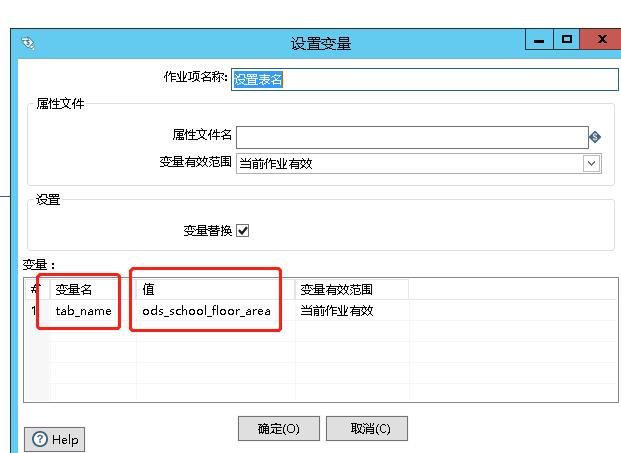
4.设置表名,变量名是tab_name(这个起什么名字都可以)
值ods_school_floor_area是第2步你在数据库中建的表的名字
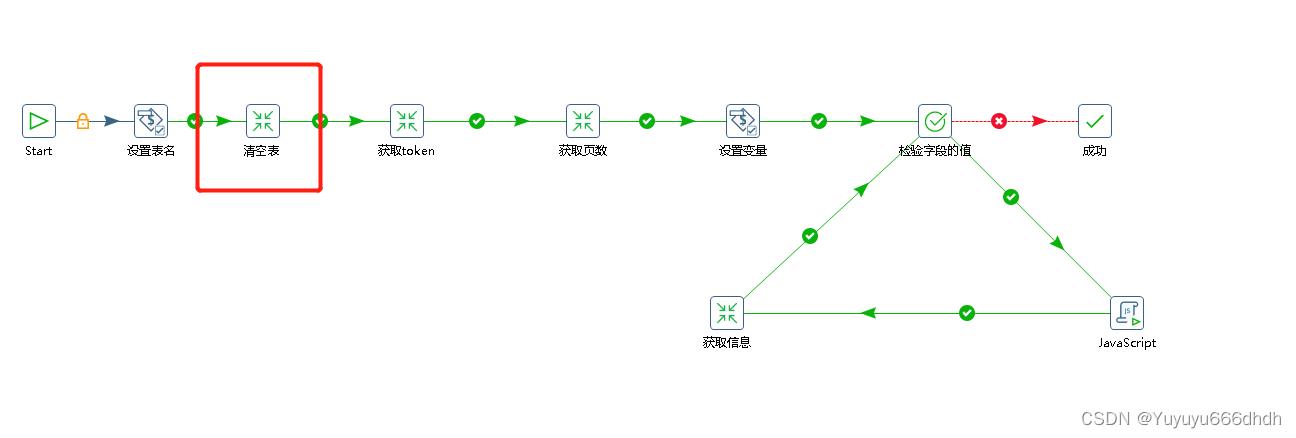
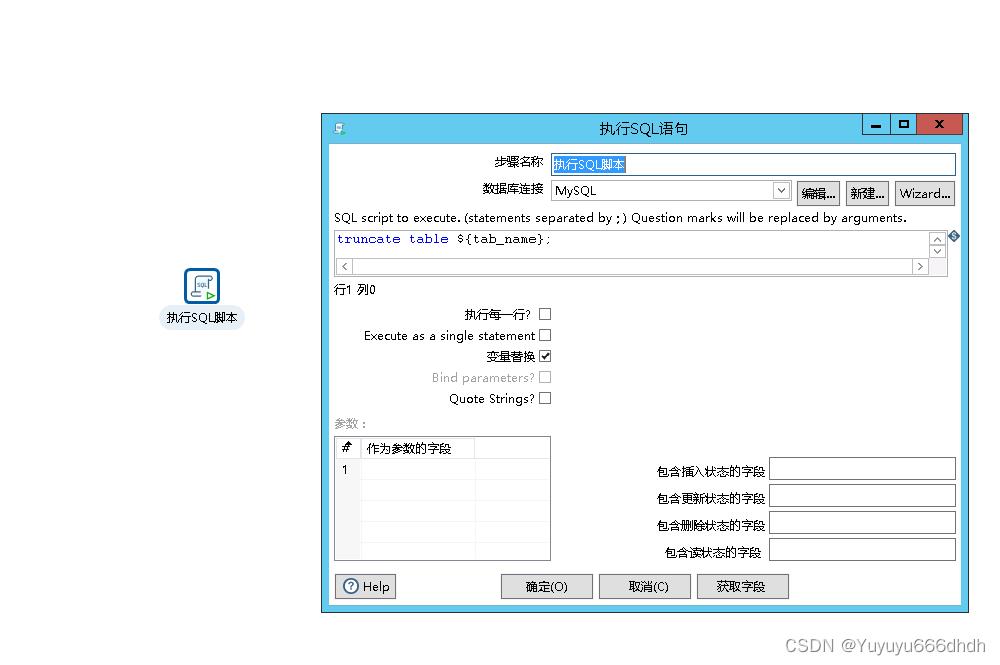
5.清空表作业下面新建一个执行SQL脚本,写入truncate table $tab_name; 这个的意思是删除表,表的名字引用的变量(我这里有很多表所以把表名设置了变量,这样不用每一个清空表都建立一个转换,如果你只有一个表的话可以不用变量名,直接删除表名)
6.获取token作业下新建转换
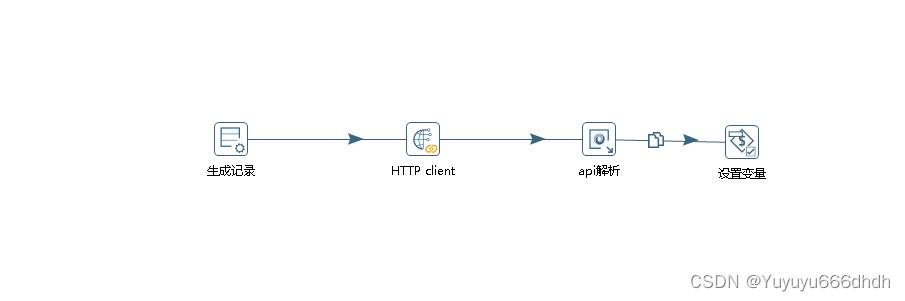
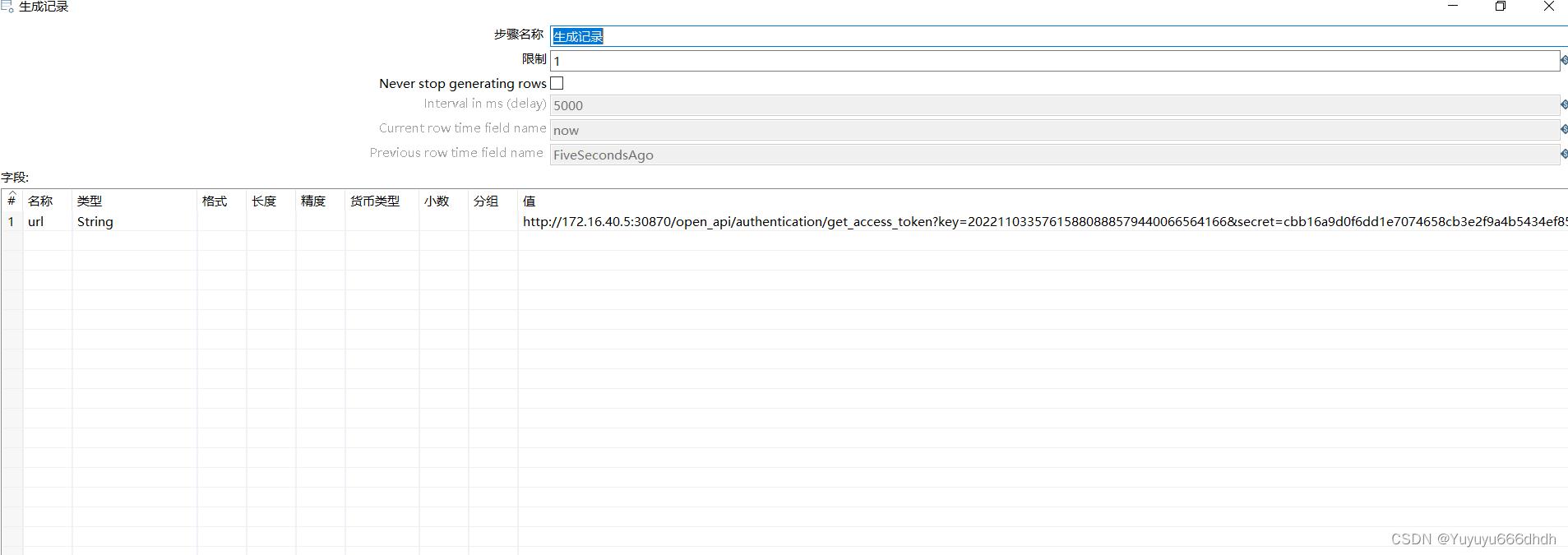
7.获取token作业下的生成记录
字段名(什么都可以)这里叫url
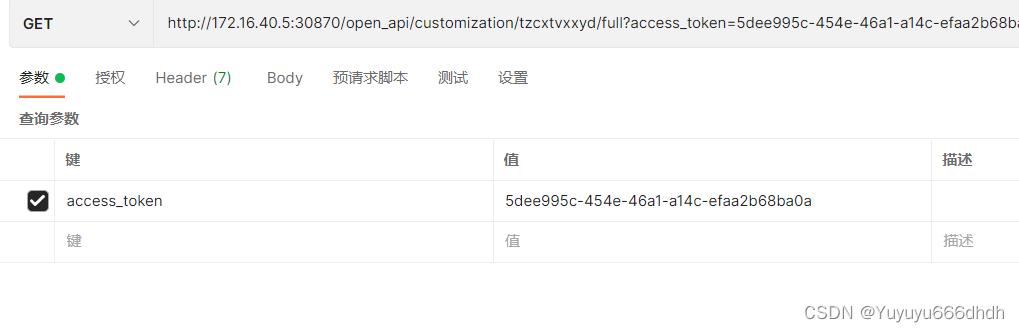
值是你api接口 的url地址加上App key、App secret(客户提供的App key、App secret)
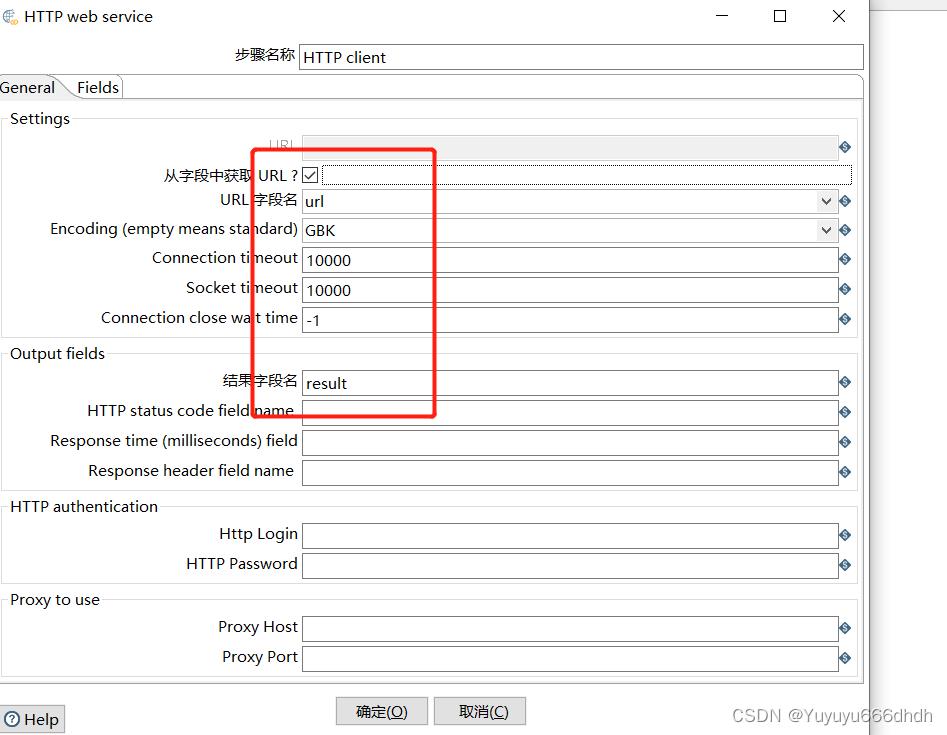
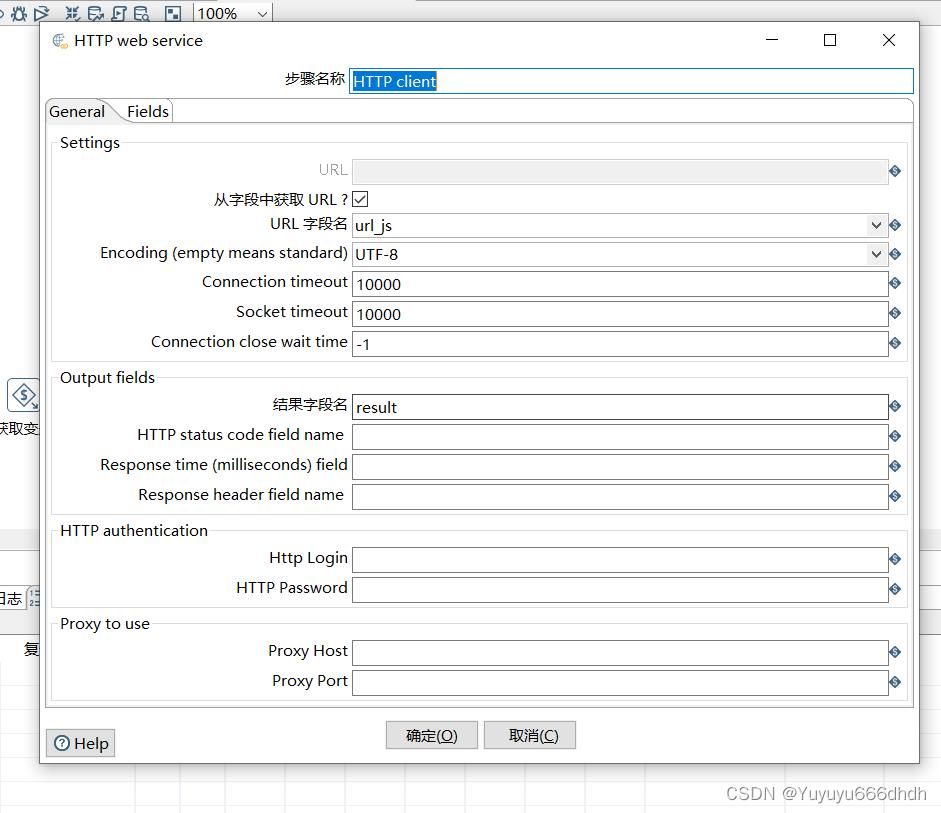
8.HTTP client
字段中获取url打勾
url字段名是第7步你起的字段名
Encoding这里改为GBK,(是因为客户的数据库编码是GBK格式,默认的是utf-8)
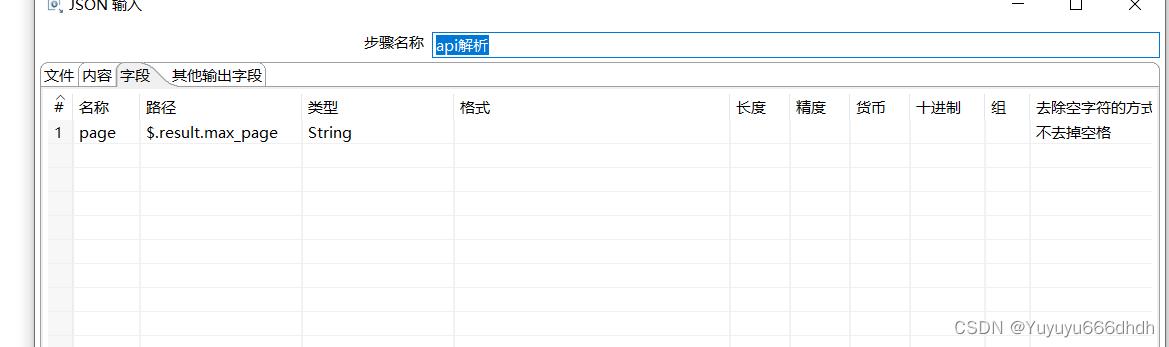
结果字段名是接口返回名result(这里根据接口返回名为准,客户这里返回名叫result)

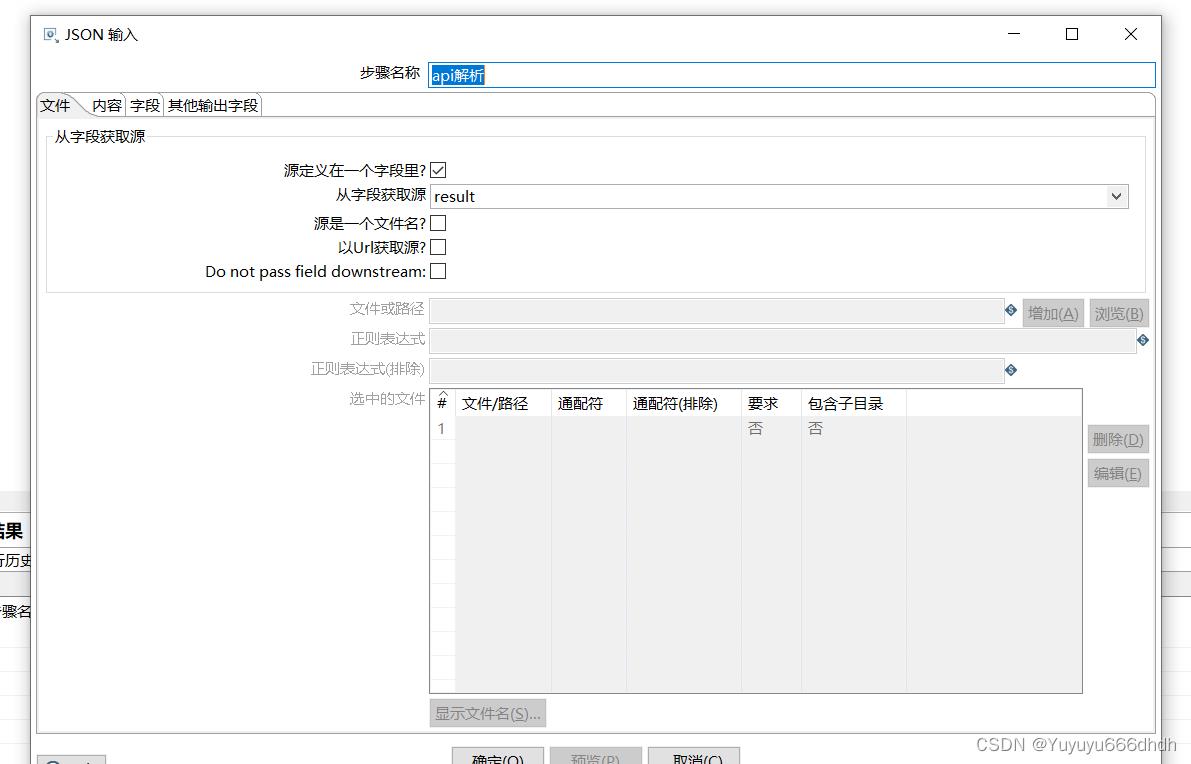
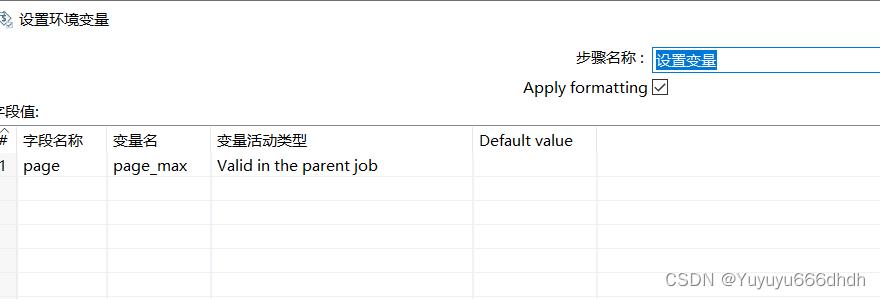
9.API解析
从字段获取源选择第8步的返回名result
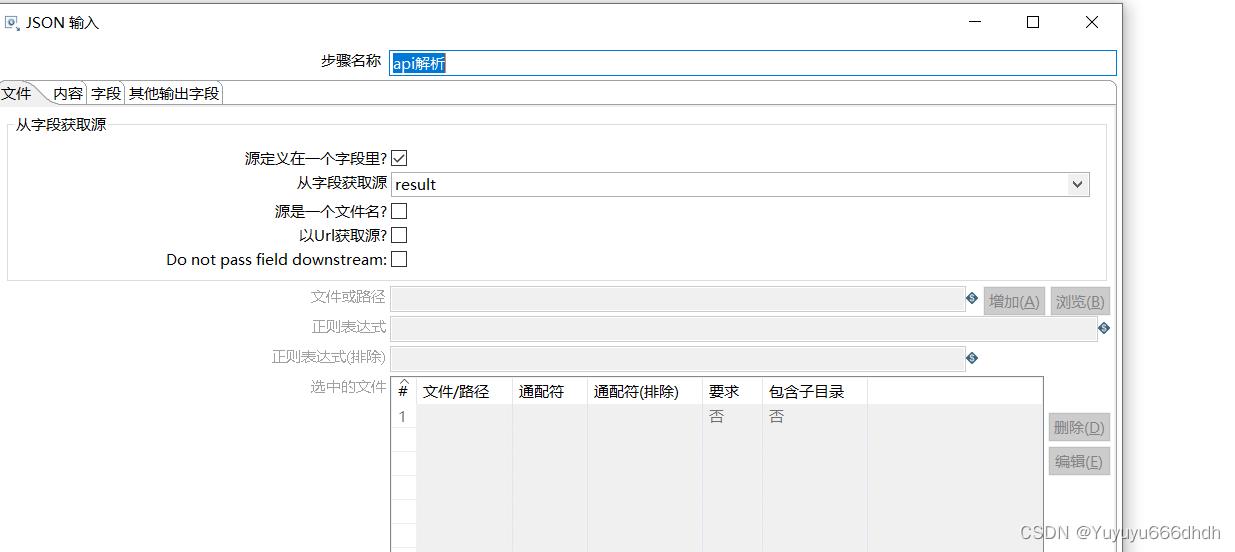
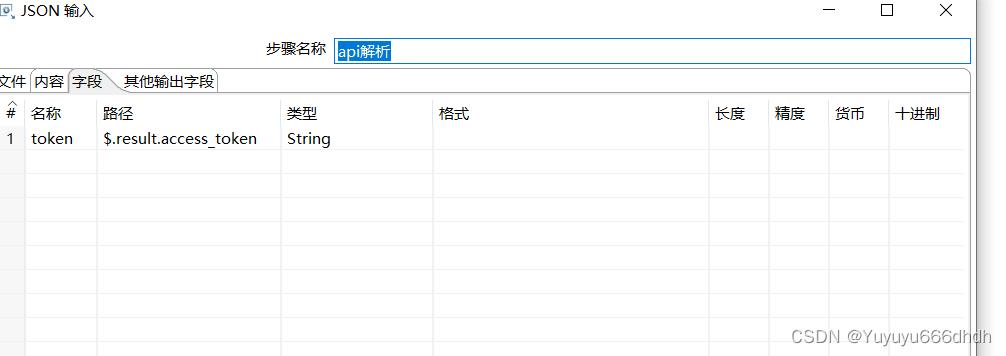
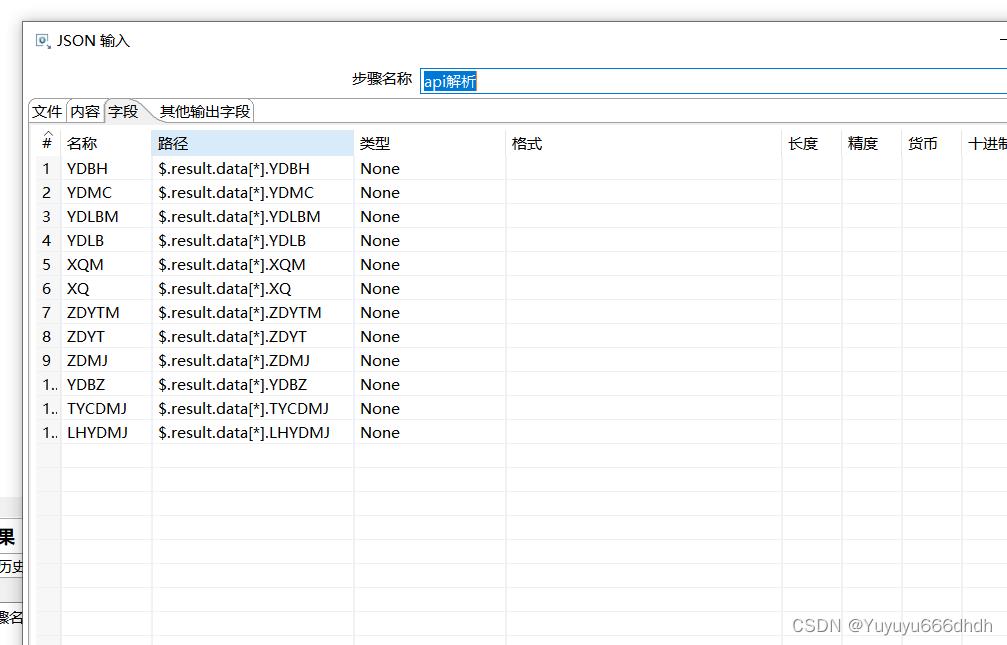
10.字段名称为token,路径是接口下的$.result.access_token
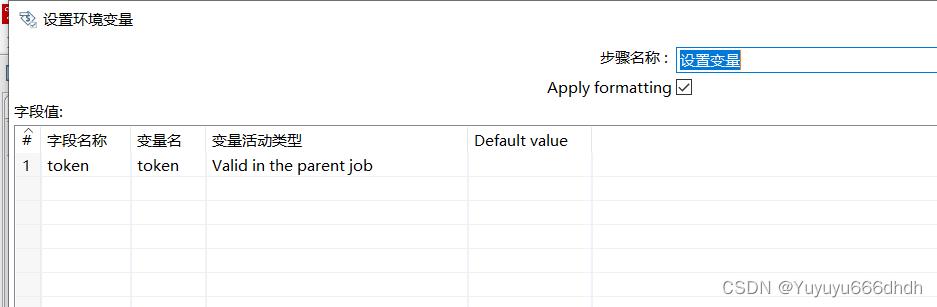
11.token设置一个变量名
12.获取页数
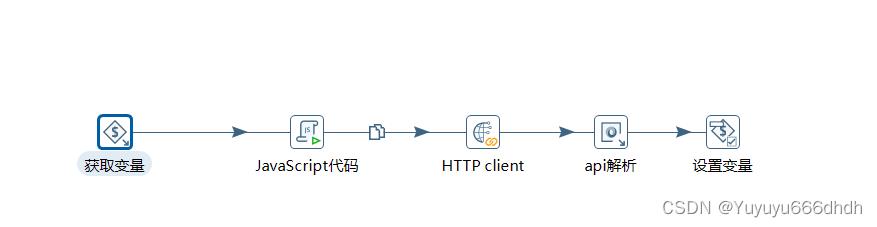
13.获取页数下的转换
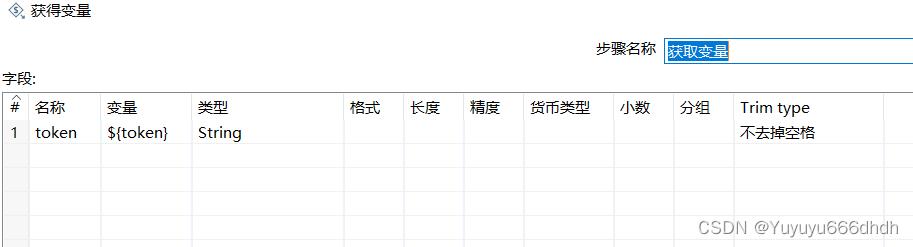
14.获取上一步的token变量
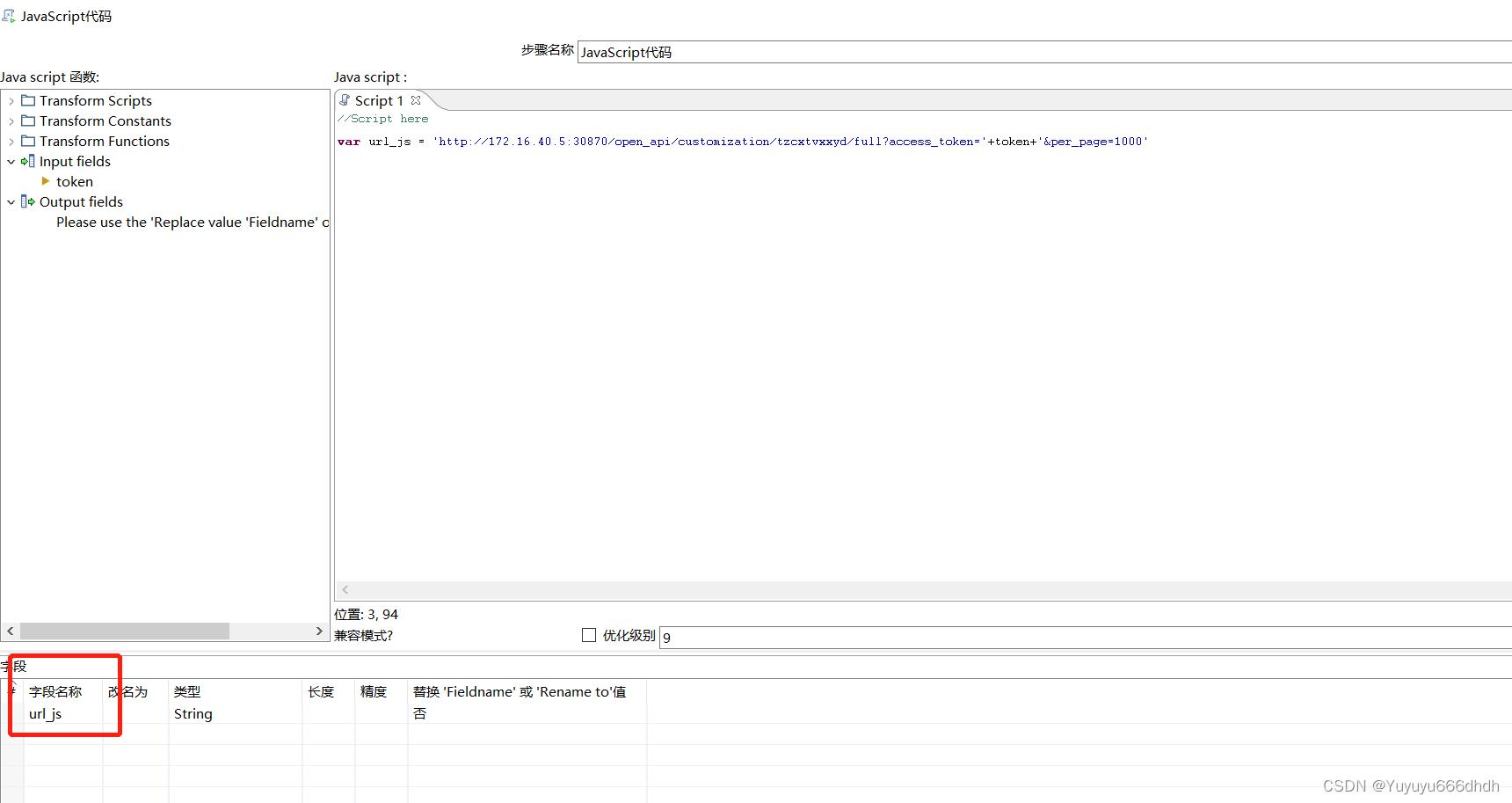
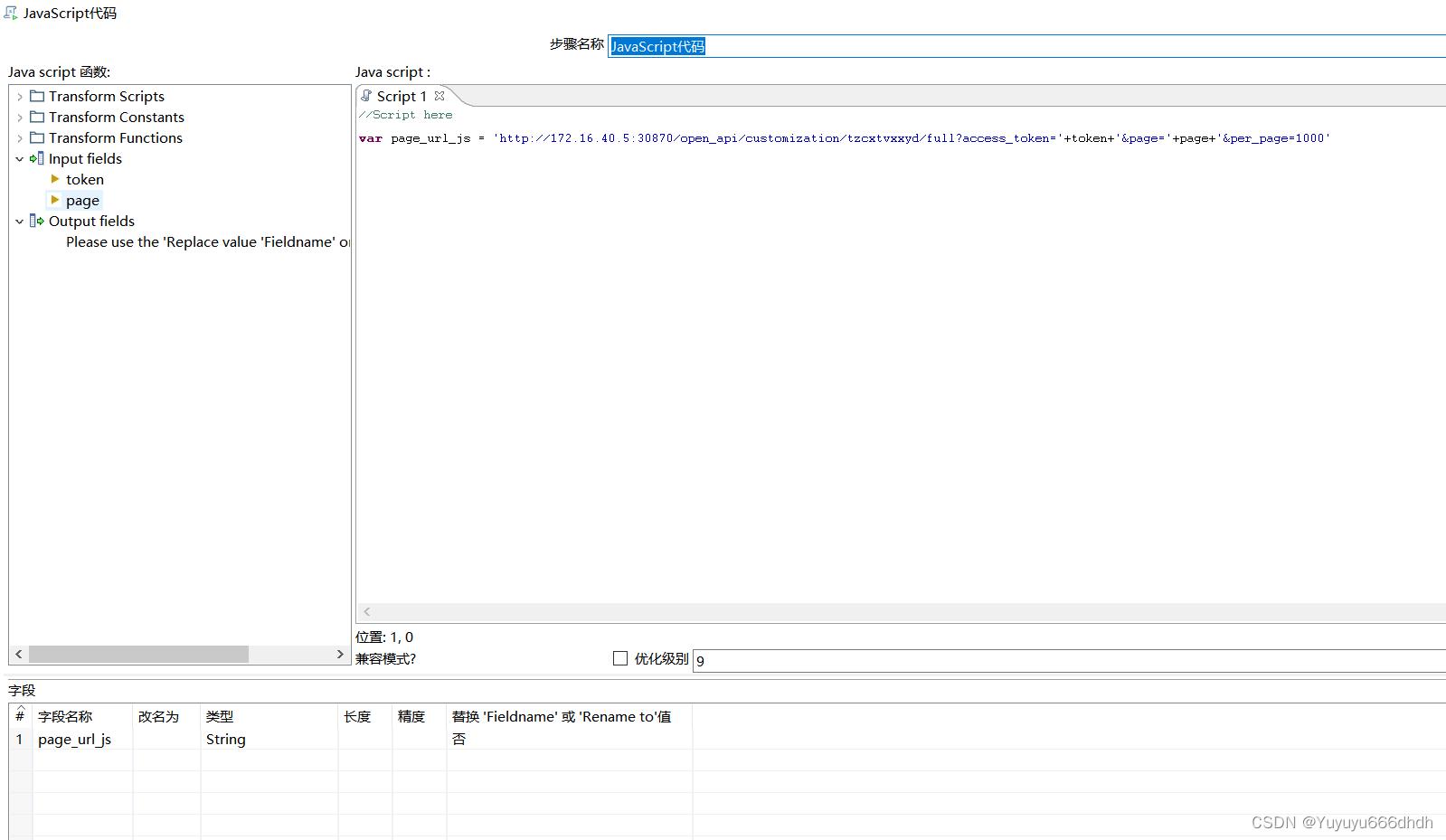
15.javascript代码,问号前面的是api接口网址,后面access_token是键值,后面的token是变量,最后的per_page表示当前的页面的数据条数。
字段名随便起这里叫url_js
16.HTTP client这里跟第8步差不多
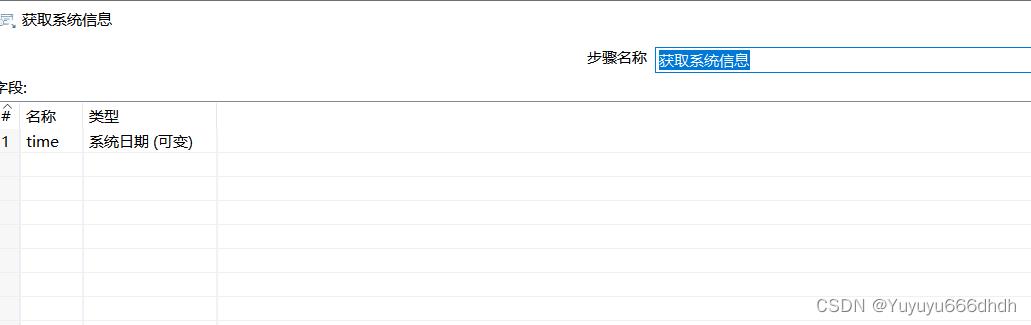
17.api解析
18.字段这里名称为page,路径是返回内容的最大页数
19.设置变量,变量名为最大页码数max_page
 20.这里设置变量页数page
20.这里设置变量页数page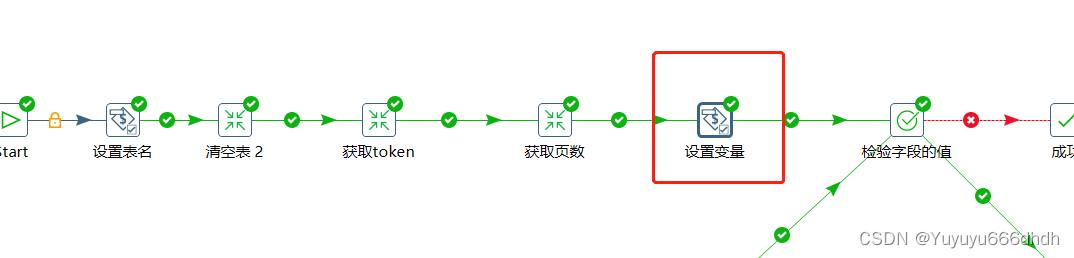
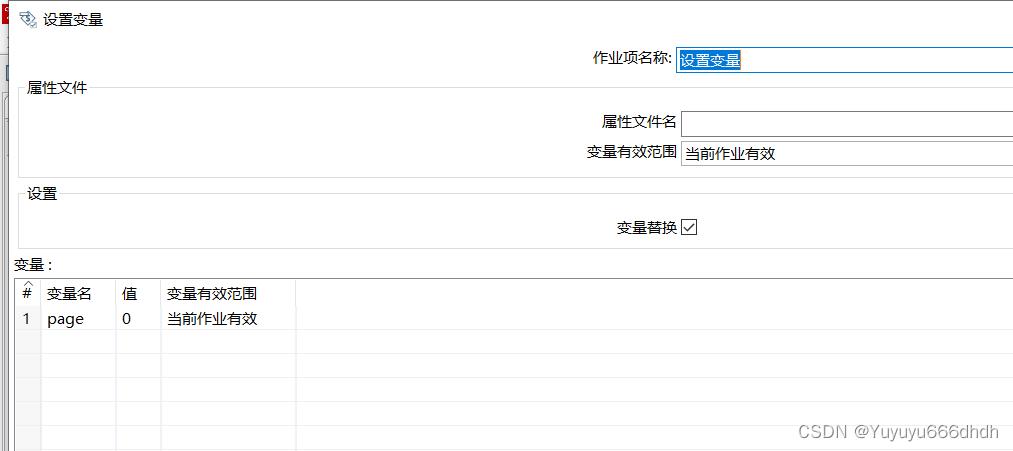
21.检验字段的值,变量名选择第20步的page,成功条件的值选择第19步的max_page
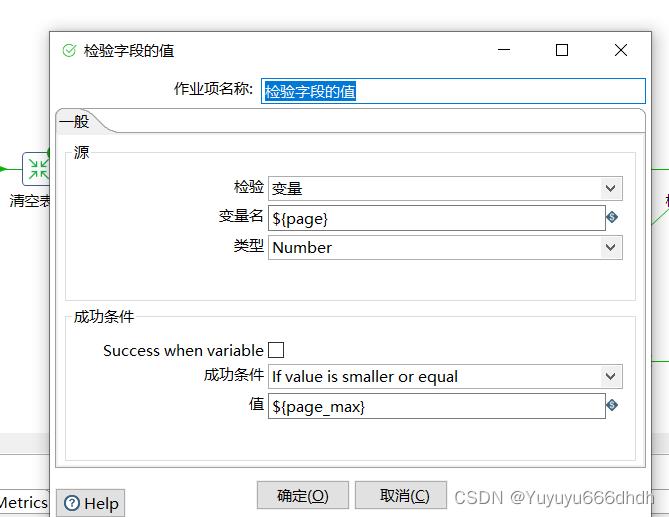
22.JavaScript
23.最后一步获取信息
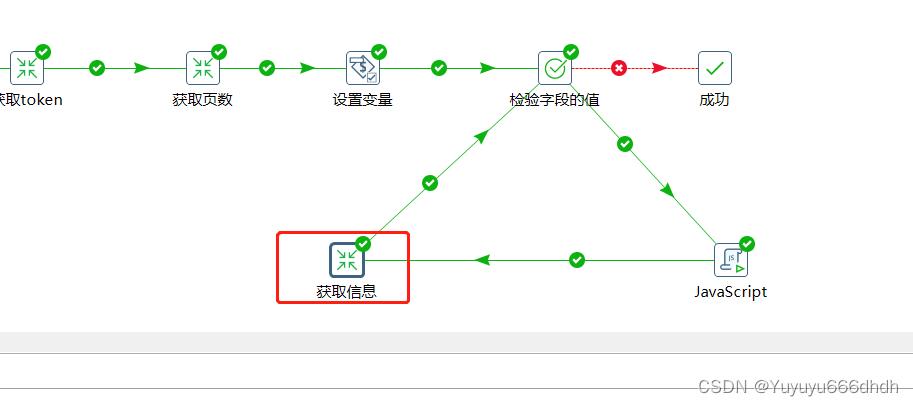
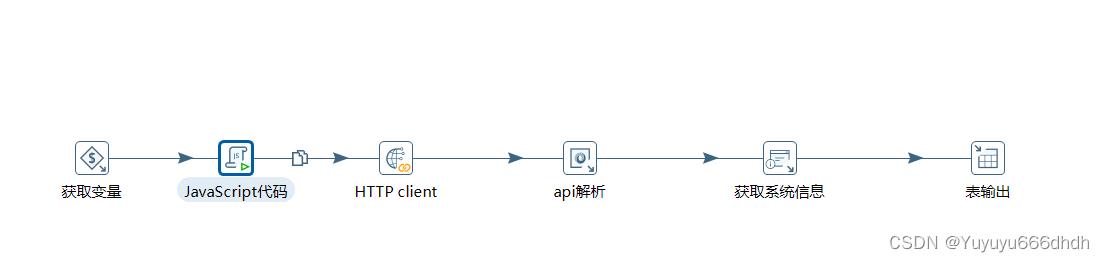
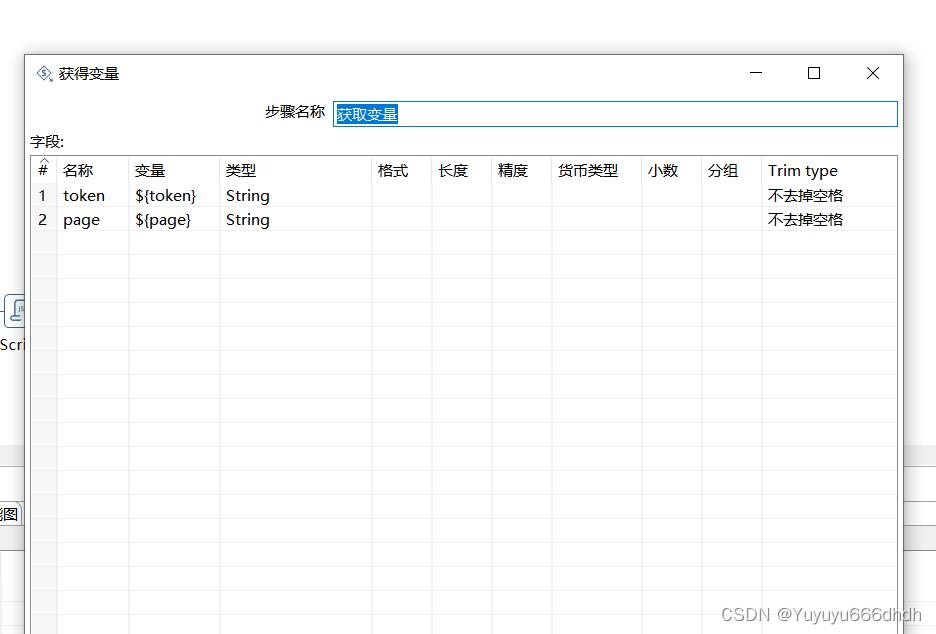
24.获取变量
25.JavaScript代码和前面15步一样,字段名称换一个
26.HTTP client
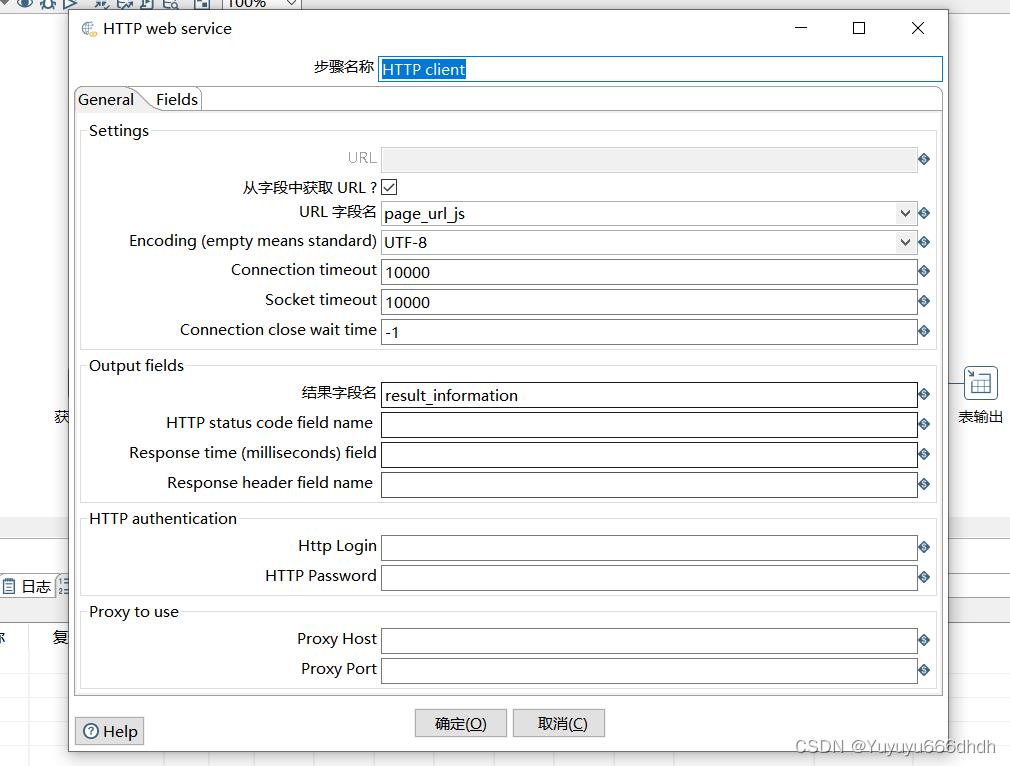
27.api解析
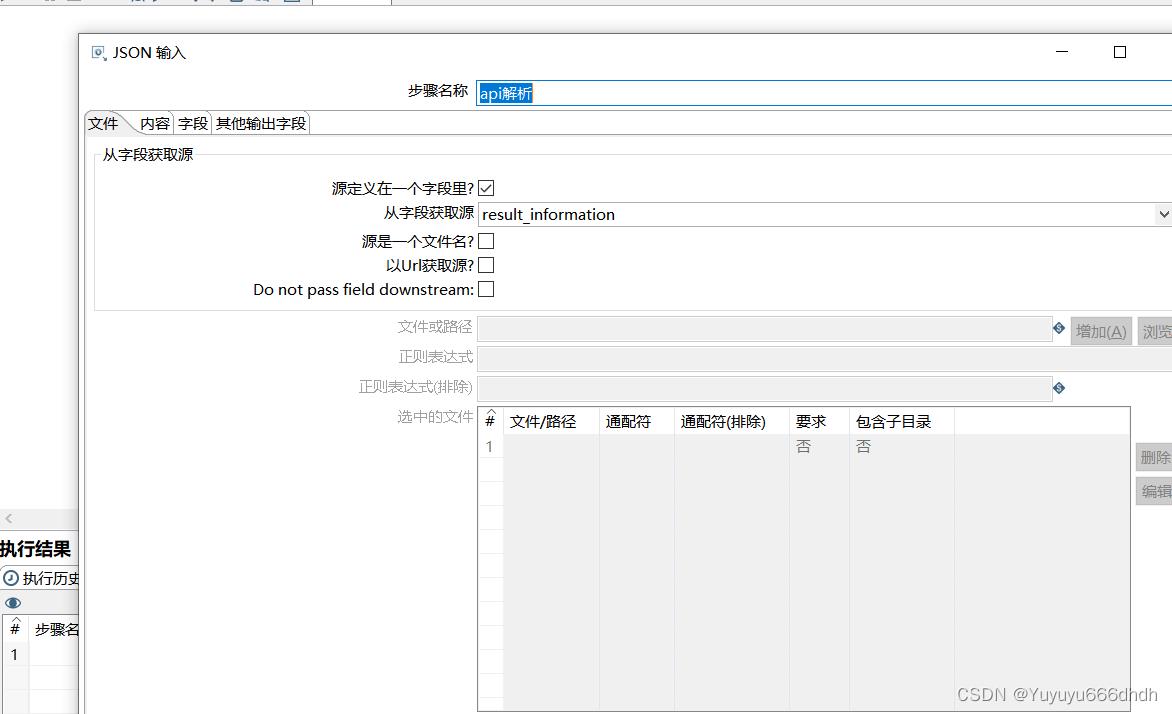
28.字段 ,这里的名称对应第2步数据库中的字段名,路径也是差不多的返回内容+返回数据信息+字段名
29.获取系统时间,用来获取etl抽取时间
30.表输出选择目标表
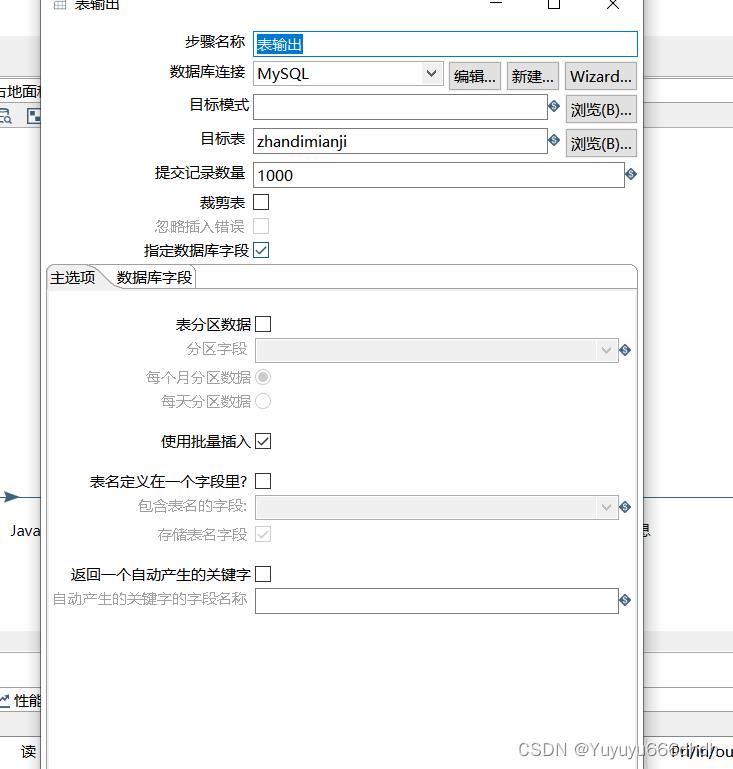
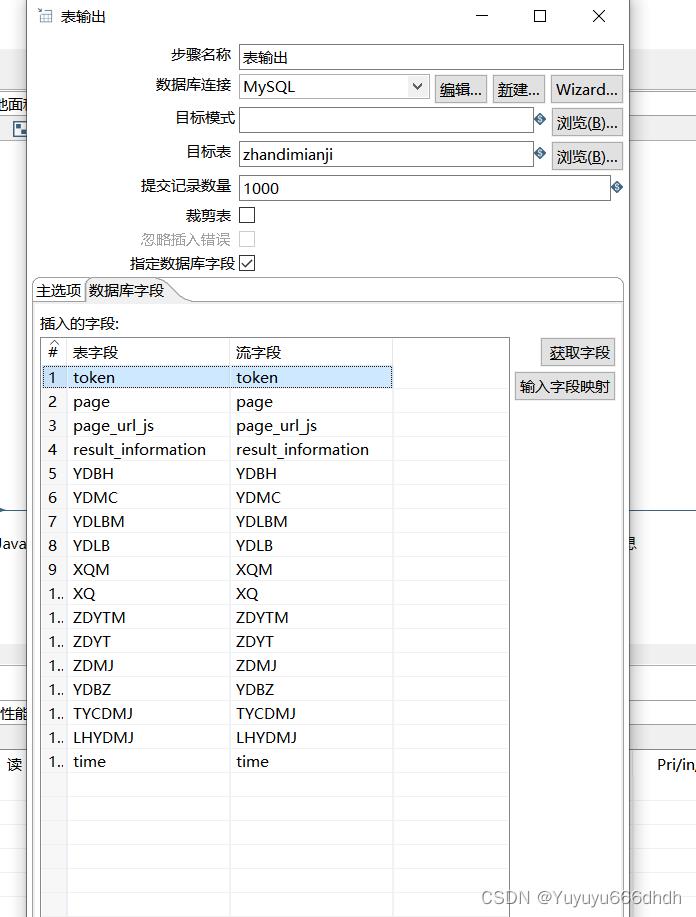
31.数据库字段把多余的删掉只留数据库内的字段,1234都删掉,在数据库内多建立一个time字段,然后留一个time字段用来查看ETL的抽取时间
kettle全量抽取---抽取MySQL数据到HDFS
问题描述:抽取到的.parquet文件在HDFS上的/user/hive/warehouse/itcast_ods.db/目录下,.parquet文件和表在同一级目录,且hive分区未正常生成。
解决方案-----由于配置时的粗心,导致hive表的分区未正常建立。在全量抽取作业的全量抽取数据转换部分,配置Parquet output:
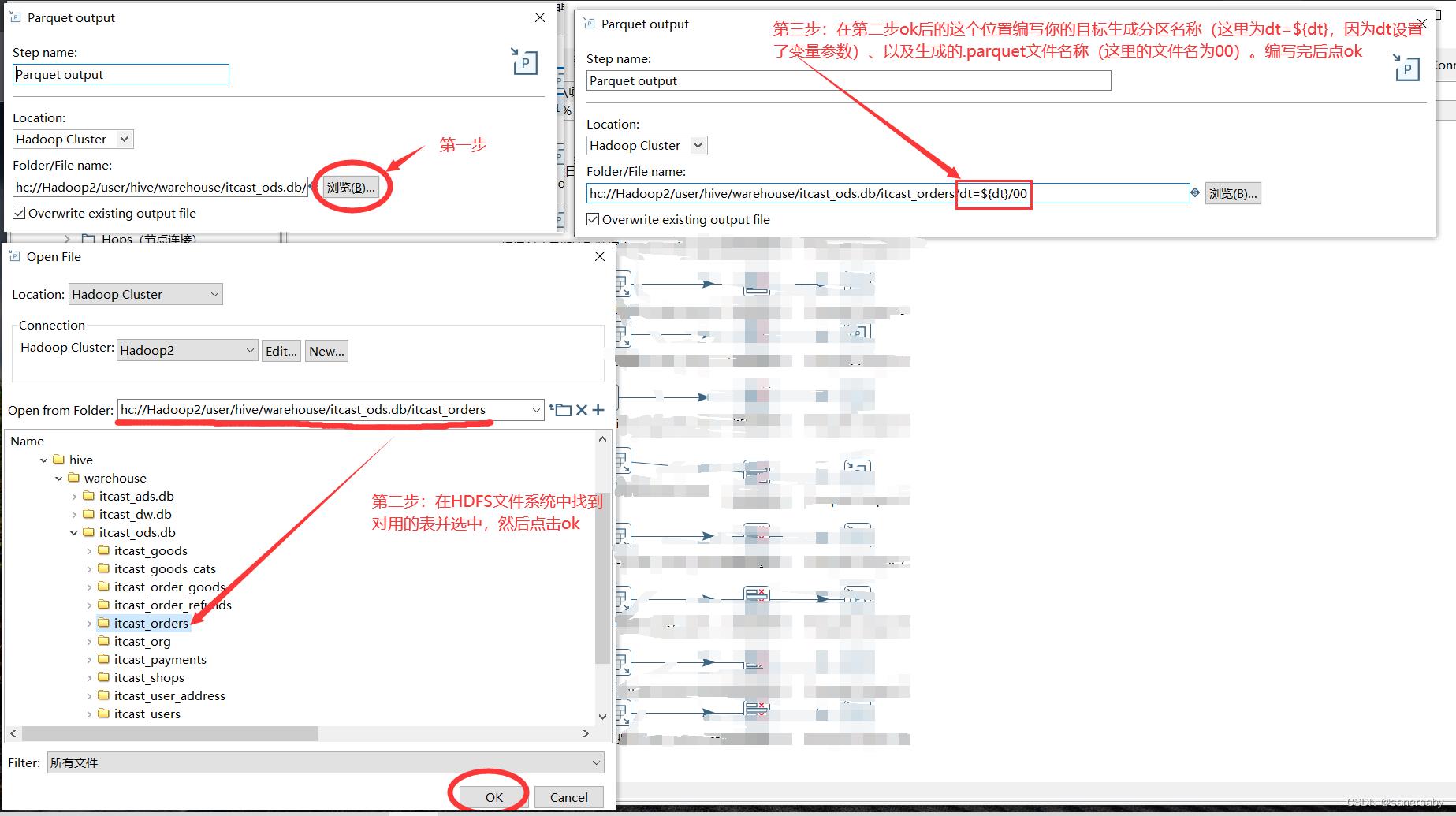
如图配置完后,保存并重新执行作业即可。
以上是关于kettle实现从api接口全量抽取数据到数据库中的主要内容,如果未能解决你的问题,请参考以下文章