Kettle-7.0增量抽取订单数据
Posted zisheng_wang_DATA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kettle-7.0增量抽取订单数据相关的知识,希望对你有一定的参考价值。
原文来自:http://www.ukettle.org/thread-594-1-1.html
业务需求:从mysql数据库中,抽取订单和订单明细数据,做一定的轻度清洗,并将清洗后的数据存放到指定目录下,清洗出来的错误数据存到另一个存error data的目录。
实现步骤:
1.使用表输入控件,数据库连接选择mysql如下图:

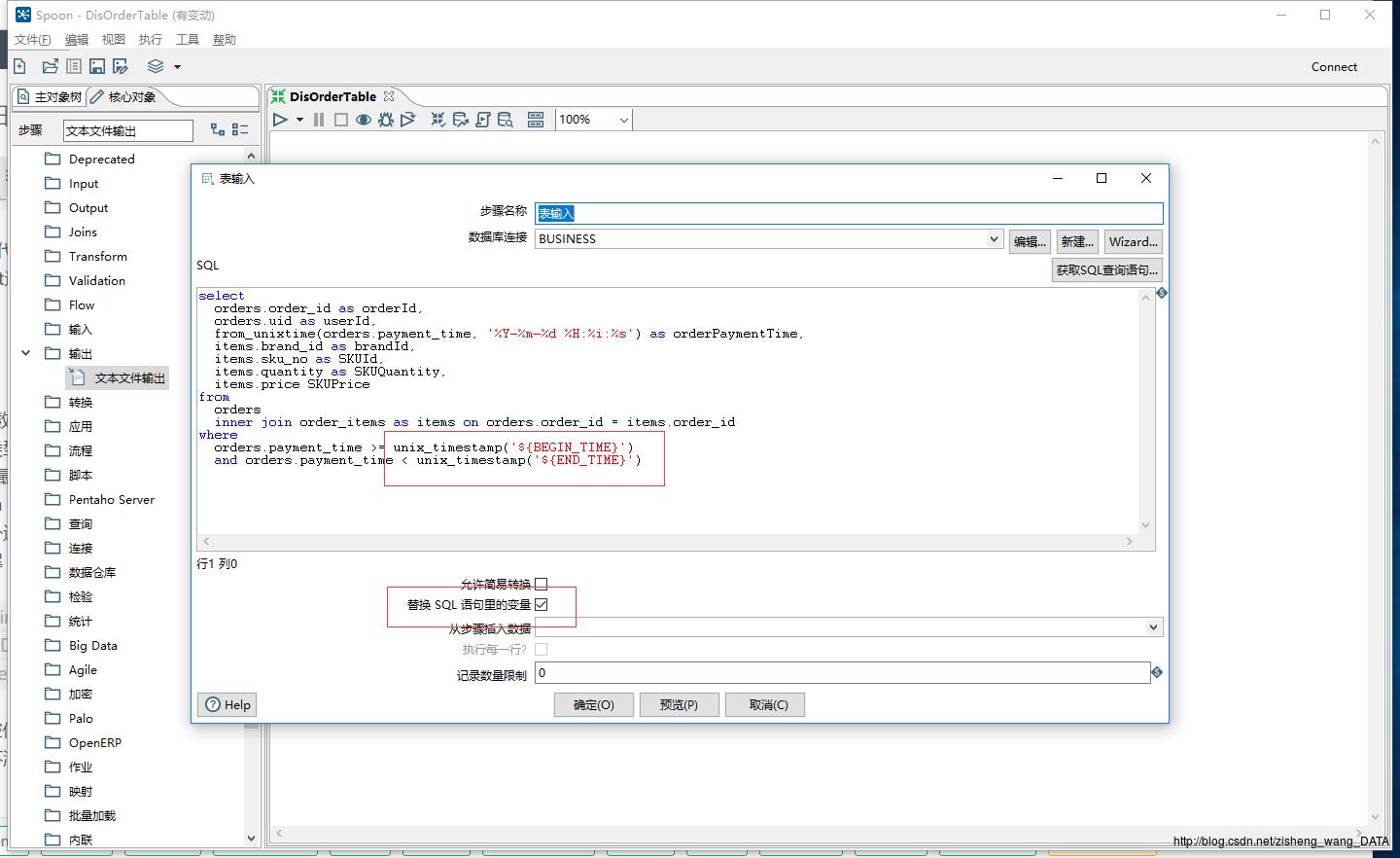
2.将取数的SQL逻辑写到代码填充处,并且取数的时间范围,用参数代替,并记得勾选replace variables in script这个选项,否则kettle.properties文件中的参数值不会被替换到SQL中。
3.这个控件的功能是完成数据校验,这儿举例,对购买商品数量这个字段,做了一个校验,其中:首先校验数据类型,类型必须是interger,不允许为字符串或者小数,其次对数值做了校验,最小值为1,最大值为9000000000000000000。另外底部的框出来的两个按钮,第一个new validation,是创建一个新的校验规则,第二个remove validation是删除当前选中的校验规则。另外还可以设定其他的校验规则,比如数值是否允许为空,是否允许以某个字符串开始或者结尾,等。需要小伙伴们自己打开这个控件去尝试一下。

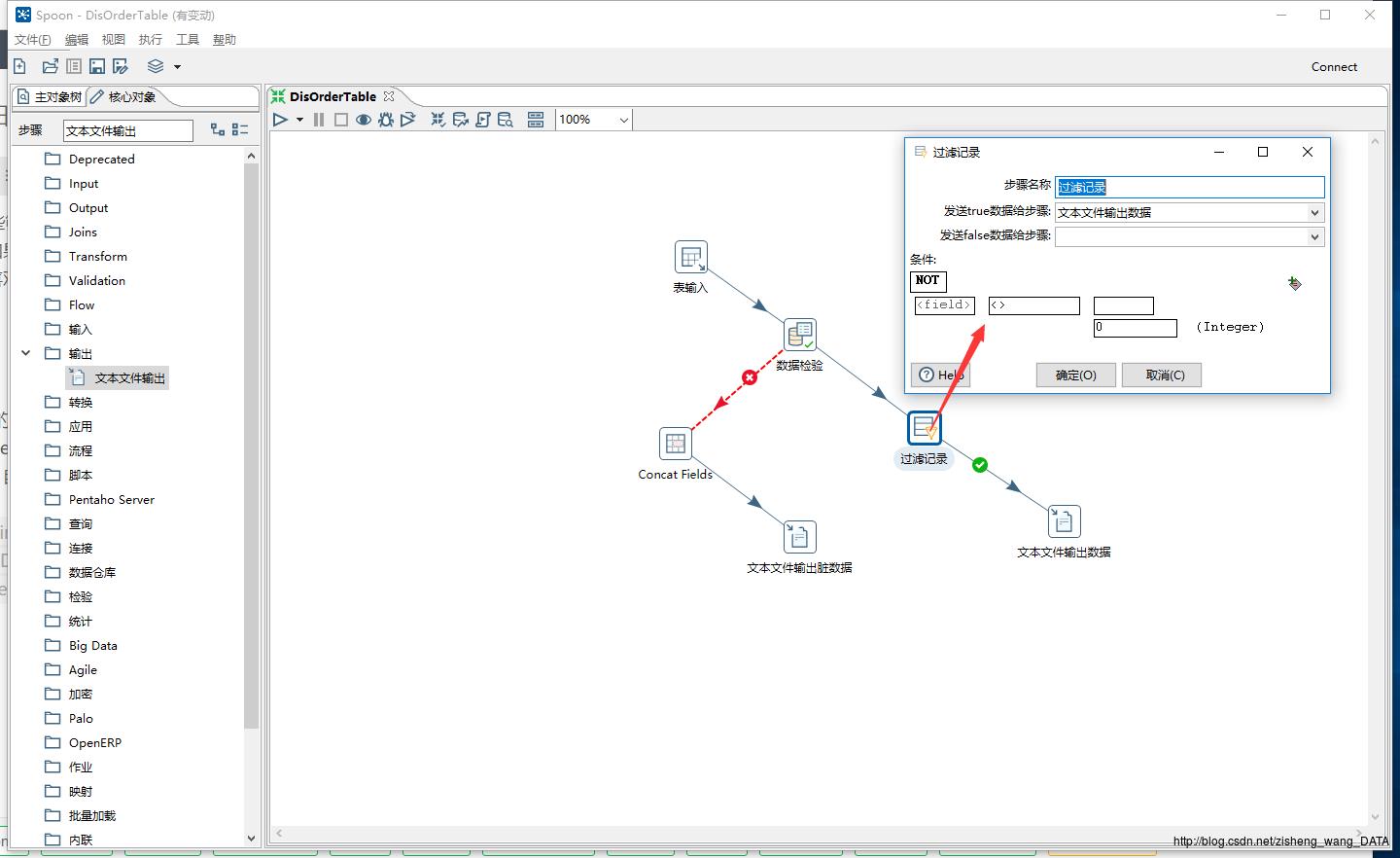
4.通过CheckOrders这个控件之后,有两条分支,第一条蓝色的,是校验之后,满足规则的数据,第二条红色的,是不满足校验规则的数据,可以用过点击这条分支(hop)来更改数据的输出控件。

5.我们先说第二条分支–>错误数据的处理,Concat这个控件的功能是完成字段拼接,将多个字段,使用指定的分隔符拼接成一个目标字段。
target field name : 拼接后目标字段的名称,这儿我给它的字段命名为 “data”.
length of target field:是限制输出字段的长度,如果拼接后字段长度太长,可能会在数据处理上造成一些影响,比如脏数据入库,可能会因为长度过长而报错。在kettle中,0是表示不限制长度,而非长度为0.
separator:分隔符。将多个字段拼接,需要指定分隔符,方便以后对数据解析。
fields:需要拼接的字段列表,可以通过get fields这个按钮来获取。
advanced:高级设置,有兴趣的可以去深度研究一下。

6.这个控件的功能是做一些筛选,我这儿是筛选出品牌ID不为0的数据,如果为0,就直接废弃。这儿需要注意的是,如果只需要筛选出满足条件的数据集,就可以省略true和false数据集的目标控件,有些伙伴喜欢把false的数据集指向一个空操作,这个我个人觉得比较多此一举。
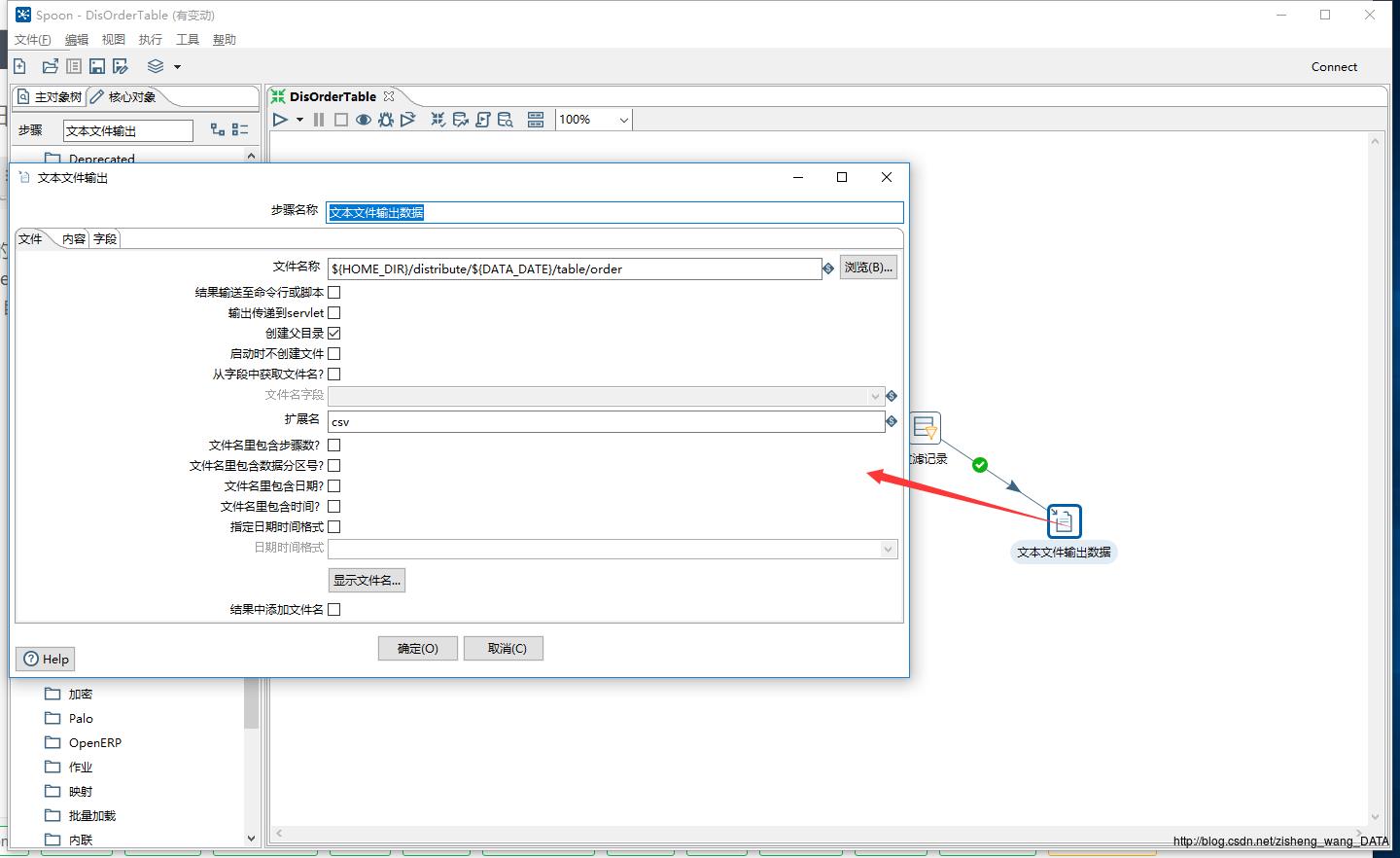
7.这个控件是将满足条件的增量数据存放到指定的文本中,这儿文本的目录是使用的参数形式,读取kettle.properties文件中配置的目录,输出的文件以csv为后缀,具体的配置,大家可以下载附件中的转换,自行研究。
以上是关于Kettle-7.0增量抽取订单数据的主要内容,如果未能解决你的问题,请参考以下文章