Java 字符编码 ASCIIUnicode和UTF-8
Posted 王景迁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 字符编码 ASCIIUnicode和UTF-8相关的知识,希望对你有一定的参考价值。
1 ASCII码
统一规定英语字符与二进制位之间的关系。ASCII码一共规定了128个字符的编码。例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号)只占用了一个字节的后面7位,最前面的1位统一规定为0。
2 非ASCII编码
表示非英语的其他语言时,128个符号是不够的。例如,在法语中,字母上方有注音符号,无法用ASCII码表示。于是,一些欧洲国家就决定:利用字节中闲置的最高位编入新的符号。例如,法语中的é的编码为130(二进制是10000010)。这样可以表示256个符号。
但是,不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。例如,130在法语编码中代表é,在希伯来语编码中代表字母Gimel (ג),在俄语编码中代表另一个符号。0-127表示的符号是一样的,不一样的是128-255这一段。汉字多达10万左右,需要使用多个字节表示一个汉字。例如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个汉字。虽然都是用多个字节表示一个符号,但是GB类的汉字编码与下面的Unicode和UTF-8是没关系的。
3 Unicode
世界上存在多种编码方式,同一个二进制数字可以被解释成不同的符号。之所以电子邮件经常出现乱码,是因为发信人和收信人使用的编码方式不一样。作为所有符号的编码,Unicode纳入了世界上所有的符号,给予每一个符号一个独一无二的编码。它是一个庞大的集合,可以容纳100多万个符号。例如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询http://www.unicode.org/或者汉字对应表。
Unicode的问题
Unicode只是一个符号集,只规定了符号的二进制编码,但没有规定存储方式。例如,汉字严的Unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101)即需要2个字节。不同的符号需要的字节数量不同。存在如下2个问题:
1 如何区别Unicode和ASCII?
计算机怎么知道3个字节表示一个符号,而不是分别表示3个符号呢?
2 容易出现空间浪费
英文字母仅需一个字节。如果Unicode统一规定每个符号用3个或4个字节表示,那么存储英文字母时会出现2个或3个字节全是0,浪费空间。
于是,出现了Unicode的多种实现方式。
4 UTF-8
UTF-8是互联网上使用最广的一种Unicode实现方式。其他实现方式包括UTF-16(字符用2个字节或4个字节表示)和UTF-32(字符用4个字节表示)。UTF-8是一种可变长的编码方式,使用1~4个字节表示一个符号,根据不同的符号调整字节数量。
UTF-8的编码规则:
1 对于单字节的符号,字节的第一位设为0,后面7位是这个符号的Unicode编码。因此,对于英语字母,UTF-8编码和ASCII码是相同的。
2 对于n个字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位均设为10。剩下的二进制位由这个符号的Unicode编码从后向前依次填入,空位补0。
编码规则总结见下表,字母x表示可编码的位:
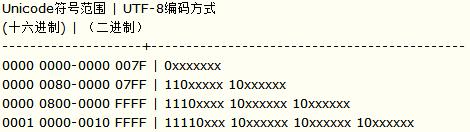
以汉字严为例,如何实现UTF-8编码:
已知严的Unicode是4E25(100111000100101),根据上表,4E25处在第3行的范围内(0000 0800-0000 FFFF),所以严的UTF-8编码需要3个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,空位补0。于是,严的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制是E4B8A5。
5 代码点和代码单元
从Java5开始,代码点(code point)是指与一个编码表中的某个字符对应的代码值。在Unicode标准中,代码点采用十六进制书写,并加上前缀U+,例如U+0041是字母A的代码点。多语言中每个字符用16位表示,称为代码单元(code unit)。在Java中,char类型用UTF-16编码描述一个代码单元。使用代码单元而非字符,与Unicode字符集的增补相关。替代区域(surrogate area)[U+D800~U+DBFF表示第一个代码单元,U+DC00〜U+DFFF表示第二个代码单元]。可以快速知道一个代码单元是一个字符的编码,还是一个辅助字符的第一或第二部分。例如,对于整数集合的数学符号,它的代码点是U+1D568,是用两个代码单元U+D835和U+DD68编码的。
String的length方法得到的是UTF-16编码对应的代码单元数量,而非字符个数;charAt方法得到的是指定位置的代码单元,而非字符。获取字符个数需要调用codePointCount方法,获取单个字符需要调用codePointAt方法。
考虑字符串:Ƶ is the set of integers.
使用UTF-16编码表示Ƶ需要两个代码单元。执行char ch = sentence.charAt(1);语句得到的不是空格,而是第二个代码单元Z。为了避免发生这种情况,请不要使用char类型。
参考资料
以上是关于Java 字符编码 ASCIIUnicode和UTF-8的主要内容,如果未能解决你的问题,请参考以下文章
字符编码的来源,asciiunicode和utf-8编码的关系