字符编码,ASCIIUnicode与UTF-8的理解
Posted lqxing1994
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符编码,ASCIIUnicode与UTF-8的理解相关的知识,希望对你有一定的参考价值。
首先我们先要明白的两点是:1、计算机中的信息都是由二进制的0和1储存的;2、我们再计算机屏幕上看到的各种字符都是计算机系统按照一定的规则将二进制数字转换而来的。
一、基本概念。
1、字符集(charset):简单来说就是计算机支持的所有字符的集合。但字符集并不是一成不变的,随着计算机在全世界的普及,计算机需要支持的字符越来越多。
2、编码系统(规则):本质上是一套规则,用来规定一个特定的字符对应的是哪一个二进制数字。所以编码系统是一个映射的集合,每一个映射的两端分别是一个字符和一个二进制数字。
3、编码(encoding):编码就是字符根据编码系统转换成二进制数字的行为。
4、解码(decoding):解码就是计算机里的二进制数字根据编码系统转换成字符从而显示在屏幕上的行为。
二、大话ASCII、Unicode与UTF-8。
在计算机刚开始诞生的时候,全世界只有美国人在用,于是美国人为了让计算机在屏幕上显示正常人能看懂的字符,于是便打算搞一套规则对应一些字符。
那时候,美国人规定了一个0或1叫比特(bit),它是计算机信息的最小单位;8个比特称为1个字节(byte)。
1个字节总共能表示28=256个字符。
但美国人想要显示的字符不多,加起来也不过127个。于是美国人便规定了1个字符用1个字节表示,很容易发现27=128,所以第一个bit永远都是0。
美国人那是看到这一套方案工作良好,于是便为它命名为ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。
这里要注意的一点是,ASCII是包括了ASCII字符集和ASCII编码规则的,ASCII字符集是美国计算机系统上能支持的所有字符的集合,而ASCII编码规则则是ASCII字符集与二进制数字一一对应的映射。
后来,越来越多的国家开始使用计算机了。比如,中国一些在海外留学的学霸海归后,顺便把计算机搬回了中国使用。但出现了一个很尴尬的问题,并不是所有的人都能很轻松地用英文来工作,而且全英文的文件也不利于信息的传播。于是中国的工程师便自己搞了套编码规则,他们规定:原来ASCII里面的127个字符的字符集和字符编码依然保留,在此基础上,凡是出现大于128的字节,该字节就和它下一个字节共同表示1个中文字符。
我们简单算一下根据这个编码规则能表示出多少字符:128×28=32768,3万多个可用空间对于中文字符来说是够用的了。于是中国的相关组织便把这一套方案命名为GBK(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification,汉字内码扩展规范)。
这里还是要注意一下,GBK也是包括了GBK字符集和GBK编码规则的。
从此以后,聪明的各国人民也按照差不多的思路,开始编写了属于自己国家的字符集和编码规则了。但这样会产生一个很严重的问题,比如说我本来在一个使用GBK的电脑上编辑的文件放到了一个支持日本字符的计算机上,文件里的内容就无法正常显示了。因为文件保存的是0和1,编码按GBK的编码,解码却按照其他编码规则来,会使得文件里得内容不能正常显示。要说为什么不能正常显示呀?因为他们电脑里支持的字符集根本就没有中文!
特别使互联网得快速发展,使得这个问题越来越明显。
于是,国际标准化组织(International Organization for Standardization,ISO)为了让计算机能够尽可能地能够显示出全世界得字符,他们就到处收集世界各国的字符,编成了一个集大成的字符集,这个字符集就叫Unicode字符集。原本,ISO用4个字节来制定这套字符集的编码规则,最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节),但这是又出现了一个很严重的问题,就是如果用2个字节来表示一个字符,那么第一个字符我就必须用15个0和1个1来表示,就像:00000000 00000001,这样不仅看上去觉得很不爽,而且有1个字节的0在文件储存或传输时非常消耗成本,因此Unicode字符集虽然是很好,但是在文件的储存和传输方面是十分不经济的。
由此,UTF-8便应运而生。UTF-8是Unicode字符集的一种相比于原来编码规则更适合文件储存和传输的编码规则。
UTF-8是一套字节可变得编码规则,它用1~6个字节来表示一个字符。UTF-8的编码规则只有两条:
1、单字节字符,字节的第一位设为0,后面7位都是可用的二进制位。很容易看出,UTF-8前127个编码与ASCII编码是一样的。
2、n字节字符,第一个字节的前n位都是1,第n+1位是0,第一个字节后面的字节的前两位都是10,剩下没有提及的都是可用的二进制位。这一条规则也使得UTF-8编码即使是一种可变字节的编码,但也能都被计算机正确识别的原因。
下面是UTF-8的编码规则,字母x表示可用的编码位。
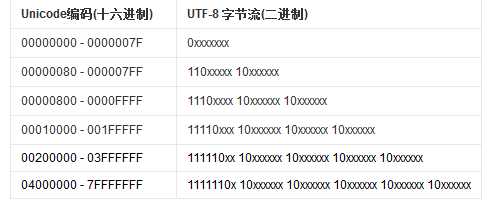
简单一句来说明Unicode与UTF-8的区别:Unicode是一个全世界大部分现存字符的字符集,它有多套编码规则,其中UTF-8是Unicode使用于文件储存和传输方面的编码规则。
三、工作中的编码。
前面第二点说了这么多ASCII、GBK、Unicode和UTF-8的前世今生,那么最重要的是我们工作中应该如何巧妙地处理文件的编码呢?
首先我们理清一下现在计算机系统通用的字符编码工作方式:
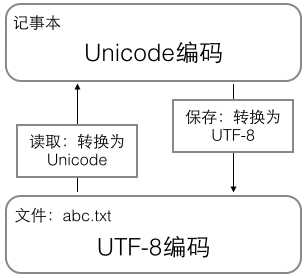
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
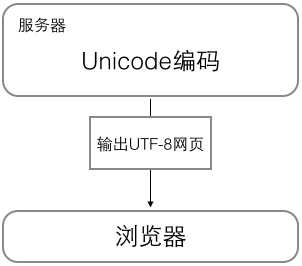
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
为什么有时候会出现乱码的问题?
首先要明白,我们屏幕上显示的是Unicode字符,而屏幕下面是Unicode编码规则对应的二进制数字。
我们一般会出现乱码的情况时,我由一个文件因为都是中文,所以我就在我电脑上用GBK编码保存了这个文件,于是计算机系统便用Unicode到GBK的一套转换算法帮我把文件保存了。目前为止一切的情况都是好的。
但我把我这个文件发到我一个朋友的电脑上,由于他平时都是看的英文文件,所以打开文件的软件默认是用ASCII编码,这时他的计算机系统拿着二进制文件,一股脑地每1个字节(8bit)翻译成英文,这当然是会出问题地啦,甚至可能会出现后128位的数字而显示不出来,但计算机是很死脑筋的,你说了用ASCII的编码规则翻译它就只会每1个字节翻译成一个字符,所以最后显示出来屏幕的时候,我们就会看到乱码了。
除此之外,如果我们用了错误的编码保存也会造成信息的丢失或者报错。还是那个中文文件,如果我保存用的是ASCII编码,计算机系统就会每一个字节帮我检查,当出现了大于128的字节时,就可能会删去该字节。最常见的是我们编程是,当用到了中文字符,如果我们的编程软件默认用ASCII编码,这时是会报错的,因为计算机不能识别文件中的中文。
所以我们应该怎样避免乱码的情况?一般来说我们最好的选择是,如果文件中出现了除英文字符以外的字符,我们都用UTF-8编码保存,并且在文本中注明文件的编码方式是用UTF-8,这样当传输给别人的时候别人就会用UTF-8编码来打开文件的了。同时我们也要知道,如果别人的文件上写了这个文件用GBK来编码,我们打开文件也应该用GBK编码,否则也会出现乱码。
具体参考:
4、博客园,gavin_l - unicode,gbk,utf-8的区别
5、百度经验 - 区分:编码方式 字符集 Unicode UTF-8
本人才疏学浅,若文中有理解错误的点,恳求指正。
--------本篇完!
以上是关于字符编码,ASCIIUnicode与UTF-8的理解的主要内容,如果未能解决你的问题,请参考以下文章
字符编码的来源,asciiunicode和utf-8编码的关系