Java采用JDBC的方式连接Hive(SparkSQL)
Posted yangyang8848
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java采用JDBC的方式连接Hive(SparkSQL)相关的知识,希望对你有一定的参考价值。
前两天,由于系统的架构设计的原因,想通过Java直接访问Hive数据库,对于我这个Java以及Hadoop平台的菜鸟来说,的确是困难重重,不过,还好是搞定了。感觉也不是很麻烦。这篇文章,作为一个感想记录下来。( 作者:yangyang8848)
一、Hive的访问方式
一般情况下,Hive是不能直接Java连接并访问的,后来出现来一个SparkSQL的东东,变得可以通过JDBC的方式访问连接。首先,我先介绍一些从Linux下访问的方法:
1、远程登录到Linux平台:

2、进入到hive数据库中,我们执行一条查询语句:
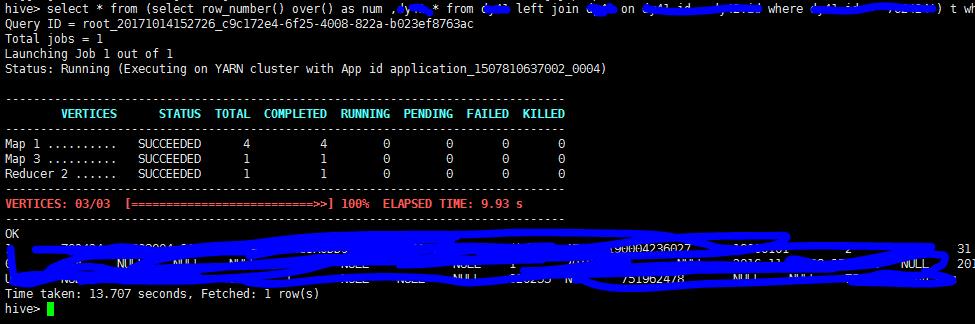
通过上图可以看到,系统执行了Map/Reduce操作,并最后显示相关的结果。
这里有一个干货哦:Hive查询语句不支持类似于mysql中的分页查询的,因此,这里采用了另外一种办法进行分页,自己看图片学习啦~!
3、下边我们采用Beeline远程连接SqarkSQL然后访问Hive数据。
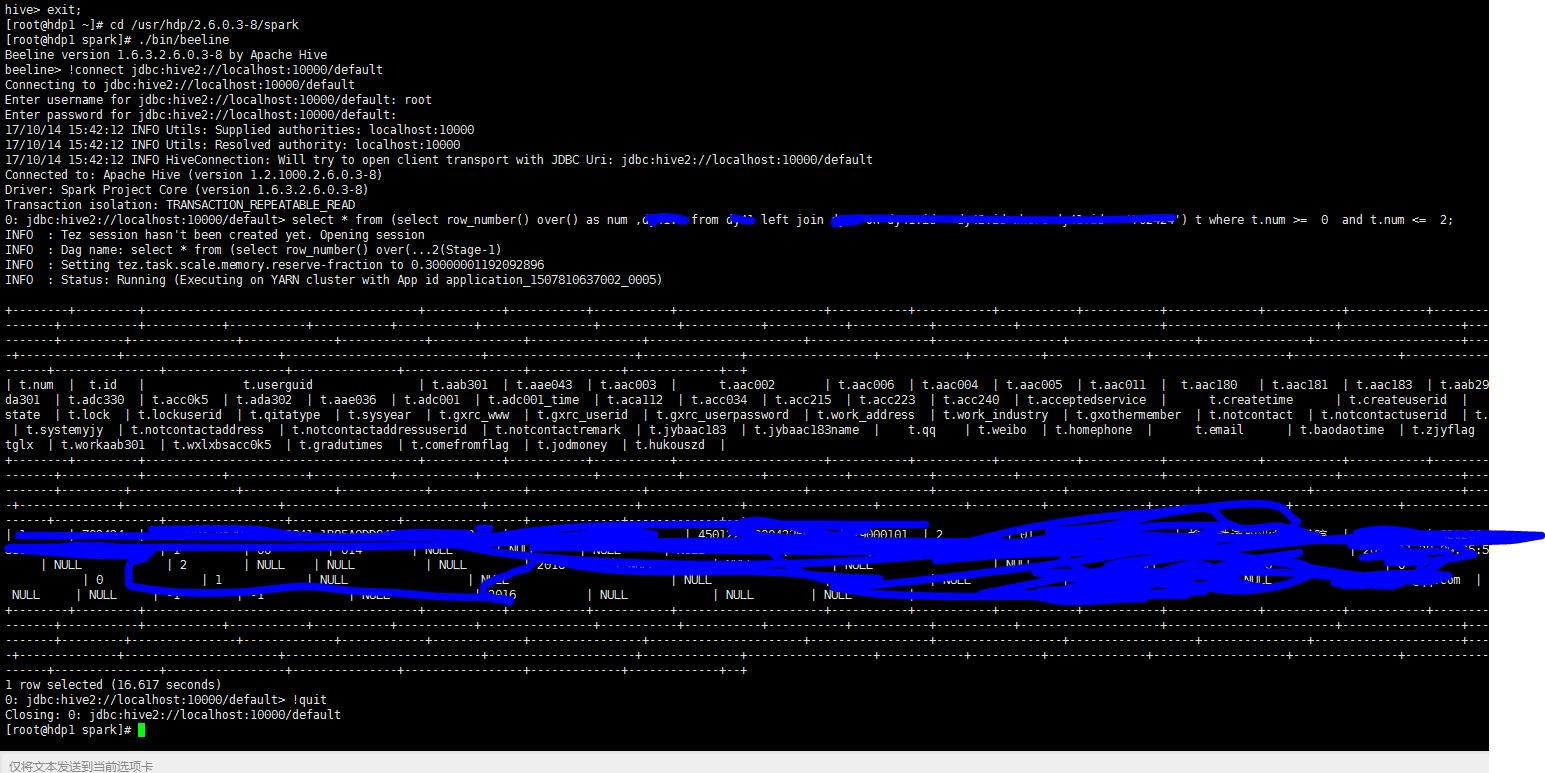
通过上边页面可以看到,系统可以正确将数据查询出来。
二、使用Java代码进行连接访问。
如果想要通过Java进行访问,首先要在引用一下三个Jar包:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
需要注意的是,包的版本一定要确认好,切勿版本过高
如果发生以下错误:
org.apache.thrift.TApplicationException: Required field \'client_protocol\' is unset! Struct:TOpenSessionReq(client_protocol:null)
则极可能的原因是你项目的hive-jdbc版本和服务器不一致的原因造成的,替换成和服务器一致的版本就可以了,
以下访问代码都已经经过了测试,拿走直接用,哈哈:
public static int hiveJDBC_RowCount(String sql,Map<Integer,String> params){
try {
ResourceBundle rb = ResourceBundle.getBundle("config");
Class.forName(rb.getString("hivedriverClassName")).newInstance();
Connection conn = DriverManager.getConnection(rb.getString("hiveurl"),rb.getString("hiveusername"),rb.getString("hivepassword"));
java.sql.PreparedStatement pstsm = conn.prepareStatement(sql);
for(Integer key : params.keySet()){
pstsm.setString(key, params.get(key));
}
ResultSet resultSet = pstsm.executeQuery();
int rowNum = 0;
if(resultSet.next()){
rowNum = resultSet.getInt(1);
}
return rowNum;
} catch (Exception e) {
System.out.println(e);
return 0;
}
}
hivedriverClassName=org.apache.hive.jdbc.HiveDriver hiveurl=jdbc:hive2://192.168.31.243:10000/default hiveusername=root hivepassword=
以上是关于Java采用JDBC的方式连接Hive(SparkSQL)的主要内容,如果未能解决你的问题,请参考以下文章
使用Spark实现推主机群Hive数据到租户集群Hive的高性能Hive2Hive数据集成Java需编写JDBC连接Hive解析元数据