论文阅读Learning to Rank Proposals for Siamese Visual Tracking
Posted c1assy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Learning to Rank Proposals for Siamese Visual Tracking相关的知识,希望对你有一定的参考价值。
Learning to Rank Proposals for Siamese Visual Tracking:2021 TIP
引入
There are two main challenges for visual tracking:
首先,待跟踪目标具有类不可知性和任意性,关于目标的先验信息很少。
其次,仅仅向跟踪器提供一个初始图像,tracker需要适应目标的外观变化和处理外部干扰,如遮挡。
上述挑战可以部分地通过鉴别discriminative correlation filter(DCF)方法来处理。通常,这些方法适应于给定的目标域并且以在线方式执行跟踪。然而,在线跟踪可能会引入不相关的背景,增加drifting risk。
孪生网络通过学习目标与搜索区域之间的相似度映射,将视觉跟踪作为模板匹配任务来处理。 In fact, 孪生追踪器mostly adopt the template pyramid strategy to estimate the target box. 然而,这种模板金字塔策略基本上局限于对目标的外观进行建模(当目标规模变化剧烈时,效果不佳)。
SiamRPN将跟踪任务分解为分类和定位问题,避免了图像金字塔尺度估计的耗时操作。更重要的是,通过使用RPN,可以估计不同纵横比下的目标尺寸。
However,在SiamRPN中,所有的训练样本来自预定义的anchors(proposals),并且正样本和负样本的随机子集被馈送到Siamese网络以优化平均损失。在训练阶段有两个限制:
- The number of negative samples is usually much larger than that of positive ones. Many non-semantic negative samples can be easily classified and contribute to the reduction of the average loss, which may prevent the classifier from discriminating hard negative samples, e.g., semantic distractors
- All positive samples, whose overlapping ratios with a set of anchors are above a pre-defined threshold, are treated equally and expected to match the positive label as closely as possible.
为了克服上述局限性,我们提出了一种简单而有效的策略–样本关注度排序(SRA)来对训练样本的重要性进行排序。更具体地说,具有与正样本相似的语义特征的硬负样本被分配较大的权重以训练分类分支。这种简单的重新加权方案有助于增强跟踪器的鉴别能力。同时,根据IoU计算阳性样本的权重。实际上,当正样本充分覆盖目标并且包含较少的背景像素时,it plays a more important role in representing the target model.
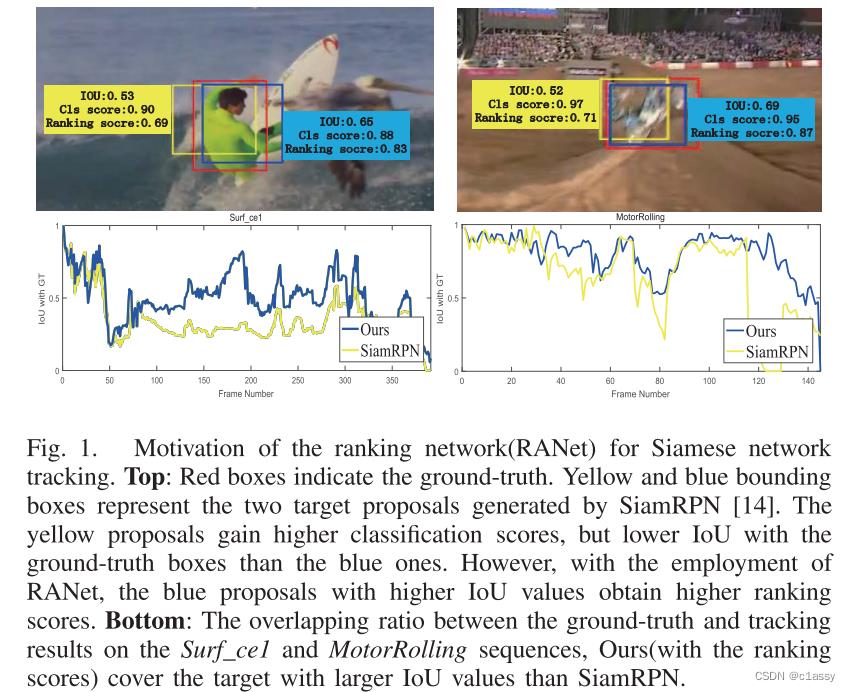
在SiamRPN 及其后续跟踪器中,从多个预定义锚中选择具有最高分类得分的proposal作为跟踪目标。然而,如图1所示,最终选择的proposal可能不具有最大的IoU。因此,仅考虑proposal的分类分数而不考虑任何位置信息可能产生次优解决方案。
related works
Proposal Selection and Sampling Strategies
- In the Siamese tracking field, the most widely adopted sampling strategy is random sampling, i.e., random selection from the whole training samples. In general, there are more negative samples than positive ones. So a fixed ratio is set to balance two kinds of samples.
- Another popular idea is to focus on hard samples that have large loss during offline
training like DaSiamRPN [17] or online choose hard samples in a special target domain such as ATOM [13]
there are many sampling attention strategies in object detection like DR-loss [36]and AP-loss [37],. However, they are not suitable for class-agnostic tracking tasks.
we propose a novel Sample Ranking Attention(SRA) strategy to re-weigh training samples.
this paper designs a ranking network, which can be integrated into Siamese tracking network in an end-to-end manner, instead of the two-stage process of object detection, so that bounding box and classification information are integrated together to produce more reliable proposal selection.
PROPOSED METHOD
基于SiamRPN

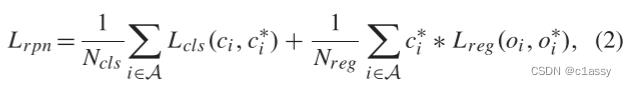
Sample Ranking Attention(SRA)
a positive sample with a higher IoU with the ground-truth should match its positive label better(closer) than other positive samples with lower IoUs. Hence, we propose IoU-SRA as an importance measurement to re-weigh positive samples.
For a positive sample
i
∈
A
p
o
s
i ∈ A_pos
i∈Apos , we calculate its IoU with the ground-truth and denotes the value as
v
i
i
o
u
v^iou_i
viiou, and obtain the IoU-SRA weight
w
i
w_i
wi to characterize the importance of the i -th positive sample as
w
i
=
1
+
v
i
i
o
u
−
τ
p
o
s
w_i = 1 +v^iou_i− τ_pos
wi=1+viiou−τpos,
the threshold
τ
p
o
s
τ_pos
τpos is used to separate positive and negative samples,是一个常数。
对于负样本,由(1)计算出来的
c
i
(
p
o
s
)
c_i(pos)
ci(pos)尽可能为0;
we propose a Score-SRA strategy to measure the importance of negative samples, under which the samples with higher
c
i
(
p
o
s
)
c_i(pos)
ci(pos) gain more attention during training(因为硬负样本能被正确分类对提升网络的效果更重要)
For each negative sample
i
∈
A
n
e
g
i ∈ A_neg
i∈Aneg, we calculate its Score-SRA weight
w
i
w_i
wi as
w
i
=
1
+
c
i
(
p
o
s
)
w_i = 1 + c_i(pos)
wi=1+ci(pos)

Ranking Network(RANet)
The above SRA can ensure that the important training samples are correctly classified.
RANet的目标是给具有较大IoU值的提案的较高排名得分,反之亦然。
The ranking score map
r
i
r_i
ri is calculated as
r
i
=
c
o
r
r
(
[
φ
(
z
)
]
r
a
n
k
,
[
φ
(
x
)
]
r
a
n
k
)
r_i= corr([φ(z)]_rank, [φ(x)]_rank)
ri=corr([φ(z)]rank,[φ(x)]rank)只考虑正样本:

the total training loss is
L
t
o
t
a
l
=
L
r
p
n
+
L
r
a
n
k
L_total = L_rpn + L_rank
Ltotal=Lrpn+Lrank
(其来源于铰链损失函数hinge loss)
Online Tracking Decision

在推断阶段,SiamRPN仅利用anchor的分类得分来确定当前目标位置。不同的是,我们考虑了anchor与ground truth之间的overlapping,并更加关注具有高IoU的正anchor。为了获得用于在线跟踪的更可靠的anchor,我们建议通过它们的加权和来融合归一化分类和排名得分图,如下所示:
s
i
=
β
r
i
+
(
1
−
β
)
c
i
(
p
o
s
)
s_i= βr_i+ (1 − β)c_i(pos)
si=βri+(1−β)ci(pos)where i is the anchor index,
r
i
r_i
ri and
c
i
(
p
o
s
)
c_i(pos)
ci(pos) denote the ranking and foreground classification score maps of all anchors, respectively.
s
i
s_i
si is the final score map used for anchor selection.
融合得分图的优点如图4所示,它表明SiamLTR通过使用等级得分更能够捕获具有较高IoU的bbox,SiamLTR能够更好地适应大规模变化,实现更精确的定位。
基于SiamRPN++:

As shown in Figure 5, three pairs of aggregated feature maps are fed into RANet to produce the ranking score maps
R
i
,
i
=
1
,
2
,
3
R_i,i=1,2,3
Ri,i=1,2,3. A weighted-fusion layer utilizes all the output maps
as

The weight
η
i
η_i
ηi is optimized offline together with the network and fixed in the inference phase. The weighted ranking score map Rall is treated as
r
i
r_i
ri in Eq6.
其他相同,推理阶段也相同。
以上是关于论文阅读Learning to Rank Proposals for Siamese Visual Tracking的主要内容,如果未能解决你的问题,请参考以下文章
CNN论文阅读 LeNet:Gradient-based learning applied to document recognition
论文阅读:曝光过度,曝光不足增强算法Learning to Correct Overexposed and Underexposed Photos
论文阅读 RSDNet: Learning to Predict Remaining Surgery Duration from Laparoscopic Videos Without Manual
论文阅读 RSDNet: Learning to Predict Remaining Surgery Duration from Laparoscopic Videos Without Manual
论文阅读笔记——End-to-end Learning of Action Detection from Frame Glimpses in Videos
论文阅读 End-to-End Semi-Supervised Learning for Video Action Detection