论文阅读笔记——End-to-end Learning of Action Detection from Frame Glimpses in Videos
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记——End-to-end Learning of Action Detection from Frame Glimpses in Videos相关的知识,希望对你有一定的参考价值。
论文题目:End-to-end Learning of Action Detection from Frame Glimpses in Videos
出处:arXiv,目前尚未有正式出版
作者及单位:
Serena Yeung1, Olga Russakovsky1,2, Greg Mori3, Li Fei-Fei1
1Stanford University, 2Carnegie Mellon University, 3Simon Fraser University
相关工作:视频中的行为检测大部分现存工作采用:构建帧级的分类器,对一段视频在不同的时间尺度上进行详尽的检测,之后采用后处理,例如持续时间的先验和非极大值抑制。这些对行为定位的非直接建模在精度和计算效率上都不能达到令人满意的效果。
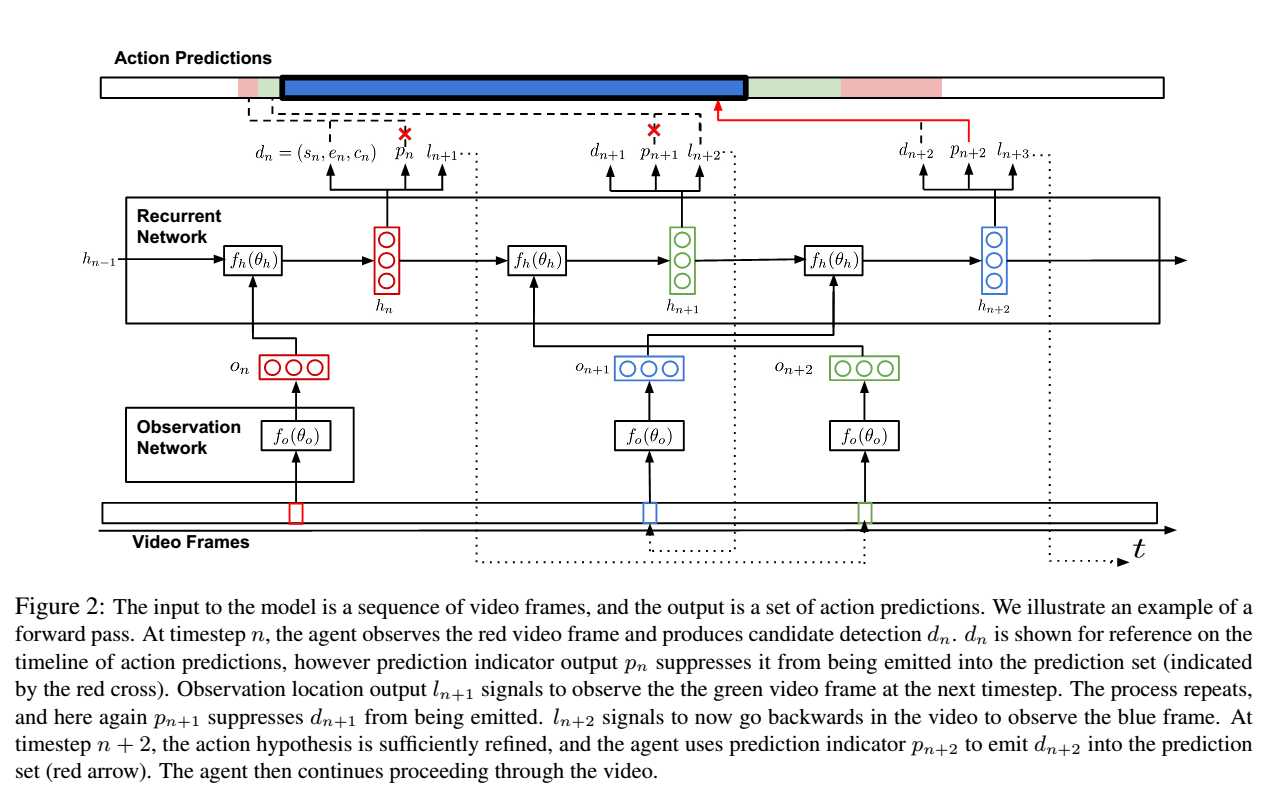
本文方法:作者提出一种直接分析行为的时域边界的end-to-end的方法。作者的直觉:行为检测是一项持续,循环往复的观察和提炼的任务。人类在提供单帧或者几帧观察,能够对行为什么时候发生有一个预测。然后会后跳或者回退一些帧来核实并且快速的缩小行为位置的区间。如Figure 1,

模型:具体的模型结构如Figure 2所示,模型有两个主要组成部分,observation network和recurrent network。observation network用来编码视频帧,本文采用VGG来编码,采用最后一层全连接层长度为1024的向量变表示视频帧,如Figure 2中的On,VGG需进行fine-tune。recurrent network采用三层的LSTM-RNN网络,每层隐层单元数均为1024。每个时间步,输出d(n)=(s(n),e(n),c(n)),p(n)和l(n+1)。其中d(n)为检测到的第n个时间窗口的信息,s为开始的位置,e为结束位置,c为置信度,p为binary value,标识d(n)是否emit,即是否是真的是行为片段,l(n+1)为下一个要“attend”的视频帧的位置(此处,我认为这个模型也是attention模型,l(n+1)为权重),注意,l(n+1)可能跳回到前面的视频帧,即作者所谓的回调来做refinement。
训练:d可以使用bp训练,p和l不可微,采用增强学习来学习。
数据:采用THUMOS’14 Dataset和ActivityNet Dataset,结果相对之前的方法有较大的提高。
结论:提出了一个端到端的行为检测的方法。
以上是关于论文阅读笔记——End-to-end Learning of Action Detection from Frame Glimpses in Videos的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读:End-To-End Memory Networks
An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features-阅读笔记
《Sparse R-CNN:End-to-End Object Detection with Learnable Proposals》论文笔记
论文阅读 End-to-End Semi-Supervised Learning for Video Action Detection
论文阅读 End-to-End Semi-Supervised Learning for Video Action Detection
论文阅读 End-to-End Semi-Supervised Learning for Video Action Detection