总结爬虫1-requests
Posted 路u
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了总结爬虫1-requests相关的知识,希望对你有一定的参考价值。
爬虫1-requests
1. requests的基本用法
- requests需要提前导入,才能使用
1.1 请求网络数据:requests.get(请求地址)
response = requests.get('https://cd.zu.ke.com/zufang')
1.2 设置解码方法(罗马的是需要设置 - 一定要在获取请求结果之前设置)
response.encoding = ''
在charset中找
1.3 获取请求结果
1)获取请求结果对应的文本数据 - 爬网页
print(response.text)
2)获取二进制格式的请求结果 - 在下载视频、图片、音频的时候使用
print(response.content)
3)获取请求结果json转换的结果 - json接口
print(response.json())
- 获取json接口,
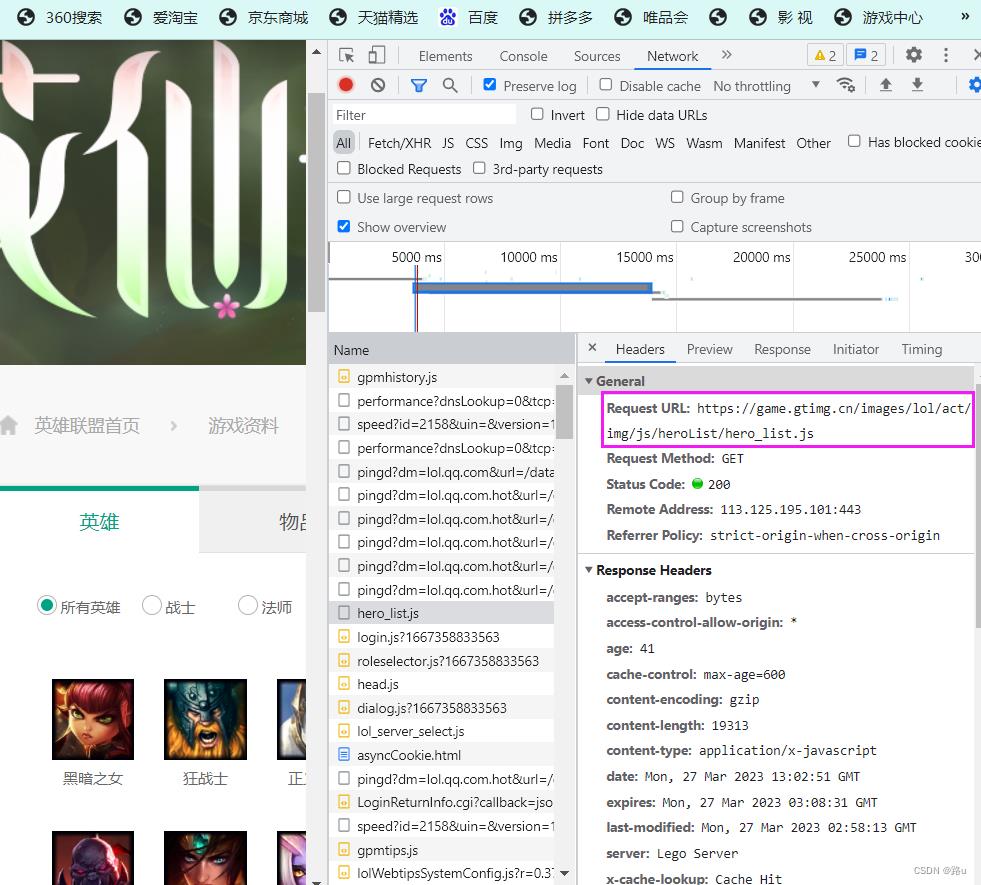
2. 请求头
2.1 发送请求
-
添加header:
1)浏览器伪装(user-agent) : (同一个浏览器每一个网页都一样)
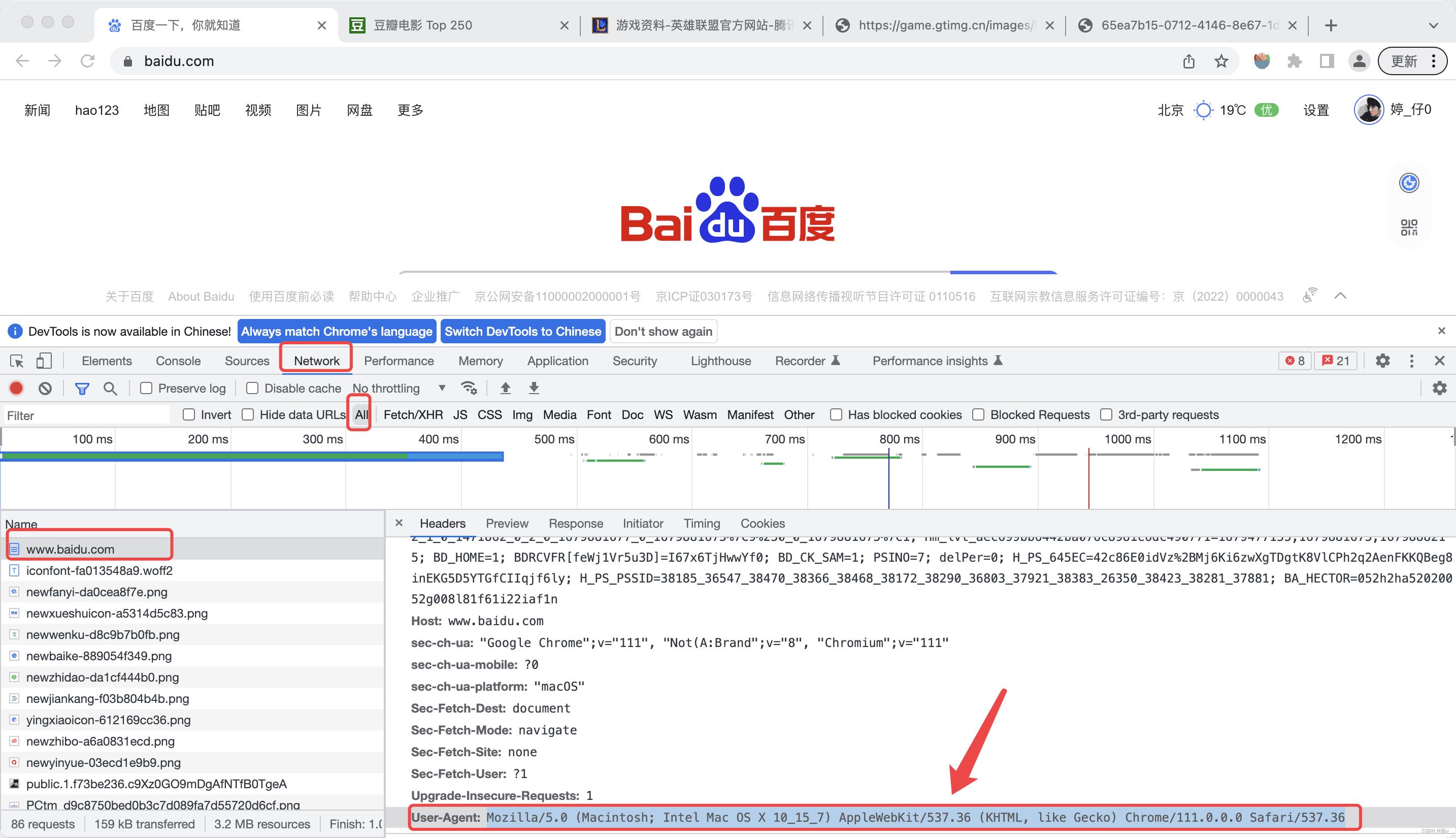
2)免密登录(cookie):每一个网页的cookie不同,要根据爬取的网站才获取cookie
3)设置代理(proxies)
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/96.0.4664.45 Safari/537.36',
'cookie': 'bid=k2ZM8BsMnBw; __yadk_uid=kuYdd9ci7gbp4IGSVFpXep5zJF2xPRLW; __gads=ID=3fa60cbcf3a3e4ac-228404d3a3dc000c:T=1676856096:RT=1676856096:S=ALNI_MZrDlvc4QU_FJ2_YtfAEdogQ3jWSw; ll="118318"; _vwo_uuid_v2=D74D83E5DB96CE49326D9A9162340763F|685d74866267af8e22bb298719a33931; douban-fav-remind=1; ap_v=0,6.0; __gpi=UID=00000bc658cd70cb:T=1676856096:RT=1679901363:S=ALNI_MbfTYZk10fRVgqzDw8mqwHRFVwUvw; __utma=30149280.1255981879.1676856093.1679402814.1679901363.6; __utmc=30149280; __utmz=30149280.1679901363.6.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmb=30149280.1.10.1679901363; regpop=1; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1679901371%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DX_nO-Ewoq5IHLBPULTNzAT9xT-5Bb73E8zsn50qOoA3I0Ab4Cjj2kK0YV6rNpxJTImgcJCrIby8H9ewHZa0h6_%26wd%3D%26eqid%3De5e6c09d0000530d00000006642142aa%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.864103406.1676856093.1679402814.1679901371.6; __utmb=223695111.0.10.1679901371; __utmc=223695111; __utmz=223695111.1679901371.6.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_id.100001.4cf6=64602560a59fdbe5.1676856087.6.1679904212.1679402814.'
response = requests.get('https://movie.douban.com/top250', headers=headers)
2.2 获取结果
result = response.text
print(result)
3. 下载图片
3.1 获取网络图片数据
response = requests.get('https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fc-ssl.duitang.com%2Fuploads%2Fitem%2F202004%2F20%2F20200420114430_iqnkz.thumb.1000_0.png&refer=http%3A%2F%2Fc-ssl.duitang.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1682496725&t=ae6c568421a44745ee7bff843e688026')
result = response.content
print(type(result)) # <class 'bytes'>
3.2 保存图片数据到本地文件
with open('files/a.jpg', 'wb') as f:
f.write(result)
4. 下载视频
# 下载音频
# 1.获取网络图片数据
response = requests.get(url='https://game.gtimg.cn/images/lol/act/img/vo/choose/1.ogg')
result = response.content
print(type(result)) # <class 'bytes'>
# 2. 保存图片数据到本地文件
with open('files/b.mp4', 'wb') as f:
f.write(result) # <class 'bytes'>
2. 保存图片数据到本地文件
with open('files/b.mp4', 'wb') as f:
f.write(result)
以上是关于总结爬虫1-requests的主要内容,如果未能解决你的问题,请参考以下文章