Python-爬虫-基本库(requests)使用
Posted ygzhaof_100
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-爬虫-基本库(requests)使用相关的知识,希望对你有一定的参考价值。
requests库比urllib跟家方便操作Cookie、登录验证、代理设置等;
例如:
1 #requests库,get请求 2 import requests 3 #请求数据 4 data={ 5 \'name\':"JONES", 6 \'age\':34 7 } 8 r = requests. get(\'http://httpbin.org/get\',params=data) 9 print(type(r)) 10 print(r.status_code) 11 print (type(r.text)) 12 print(r. text) 13 print(r.cookies) 14 print(r.json())#获取一个json对象 15 print(type(r.json()))
除了get方法以外,可以通过post、put、delete、head、options方法实现不同方式的请求;
注意:上面如果相应结果不是json格式,则r.json()方法会报异常错误;
抓取一个网页,例如:
1 #requests库,get请求 2 import requests 3 import re 4 headers={\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\', 5 \'Host\': \'www.zhihu.com\', 6 \'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0\' 7 } 8 r = requests. get(\'https://www.zhihu.com/explore\',headers=headers) 9 pattern=re.compile(\'explore-feed.*?question_link.*?>(.*?)</a>\',re.S) 10 titles=re.findall(pattern,r.text) 11 print(titles) 12 print(type(r)) 13 print(r.status_code) 14 print (type(r.text)) 15 #print(r. text) 16 print(r.cookies) 17 18 #抓取一个二进制的图片 19 import requests 20 r=requests.get(\'https://github.com/favicon.ico\') 21 print(r. text) 22 print(r.content) 23 # f=open(\'abc.ico\',\'wb\') 24 # f.write(r.content) 25 # f.close() 26 with open(\'abc.ico\',\'wb\') as f: 27 f.write(r.content) 28 f.close()
通过设置:\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0\'
来模拟一个浏览器访问服务,否则无法访问;
响应常见状态码如下:
成功状态:
200(‘ok’,\'okay\',\'all_ok\',\'all_okay\',\'all_good\',\'\\\\o/\',\'√\')
客户端错误状态码:
404(‘not_found’,\'-o-\')
服务器端错误:
500(‘internal_server_error’,\'server_error\',\'/o\\\\\',\'×\')
例如:
if not r.status_code==requests.codes.ok :
print(\'Request Error\')
else:
print(\'Request Successfully\')
#############################
高级用法:
例如,上传文件:
#文件上传
files={\'file\':open(\'abc.ico\',\'rb\')}
sr=requests.post("http://httpbin.org/post",files=files)
print(sr.text)
响应结果:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAAB 。。。 AAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAA。。。="
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "6661",
"Content-Type": "multipart/form-data; boundary=411e5e7f2f319c860f57b1f6d7839f7e",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"json": null,
"origin": "ip这里略",
"url": "http://httpbin.org/post"
}
使用requests库处理Cookie:
下面两个请求,一个请求访问博客园地址,没有加headers设置,且登录前访问的url,注意:由于博客园首页地址会被重定向;因此会报异常,所以没设置headers,要设置则会报错(TomanyRedirc错误);
第二个请求则是登录成功后, 浏览器Debug查看cookie,加入headers,直接访问登陆后的列表;抓取我的博客园中发布的博客题目列表;
1 import requests 2 import re 3 #访问博客园:https://i.cnblogs.com/ 直接加入headers属性后,由于该地址会重定向,因此会报错误TooManyRedirect异常 4 #根据响应结果,在获取重定向URL 5 #登录前,发送的请求 6 r=requests.get("https://i.cnblogs.com/")#,allow_redirects=False)#allow_redirects=False忽略重定向,就不会报TooManyRedirct,结果不是我们要的 7 print(r.cookies) 8 for key,value in r.cookies.items(): 9 print(key+\'=\'+value) 10 print(r.text) 11 print("重定向URL为:",r.url) 12 13 #登录成功后,获取登录成功后响应的Cookie,然后发送请求,获取个人发布的所有博客标题列表 14 headers = {\'Accept\': \'Accept text/html,application/xhtml+xml,*/*\', 15 \'Host\': \'i.cnblogs.com\', 16 \'User-Agent\': \'User-Agent Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko\', 17 \'Cookie\':\'td_cookie=18446744071949694669; SERVERID=a15b3bd10716e69d8be538bb89e87a05|1545789639|1545788153; _ga=GA1.2.2025196660.1543803050; __gads=ID=0acaebdef222f985:T=1543803056:S=ALNI_Mb4z_obzMRA-KI6xe7ms4H9T1F6aA; _gid=GA1.2.1065648169.1545718072; .CNBlogsCookie=1C1655941CDFCB0648208766D9FA57E2114A6F237B40201383F6906E7C528F42536F097A19008BBEA6DCCEAE1A6C0D2F9EF07AF5FDFD9E6D7F7A8BBE8655A75F0376CE8E8A1B712CC57F47D55C2ABCCD5C54D16A99779E980761B8C28070D088EC28C310; .Cnblogs.AspNetCore.Cookies=CfDJ8KlpyPucjmhMuZTmH8oiYTOnSN3OilBek6jhgR41R5Mez_H24LhyvqvRFrMeN_1T8cVypF0H9RrB4jhc0M5RpHR7-eqTd93eAvka-nV2OSFItlJwuO_-IOuZJYJU5FODierauD6wokWHE1o7bHvNixE-u9jzhi4m8nv5AgMMlN5JbDeJqbEh6o7zJQ8ho00nRQGjIQtOsPFIzDwWqHaD8dhUvPQ_js3IEb8rtrO_rNws27gJ0LZWRXZIq2FmNow2YtiF7xXgPngu_Ttk4WveBAVtyHxWy3U4RA2FR69UXdgw\' 18 } 19 i=1 20 while True: 21 22 res=requests.get("https://i.cnblogs.com/",headers=headers,params={\'page\':i}) 23 #print(res.text) 24 pattern=re.compile("post_title_link_.*?>(.*?)</a>",re.S) 25 titles=re.findall(pattern,res.text) 26 if (len(titles) == 0): 27 break 28 print(\'################################\') 29 print("我的博客列表标题>>第%s页>>>%s" %(i,titles)) 30 print("详情:") 31 32 for title in titles: 33 print(title) 34 i+=1
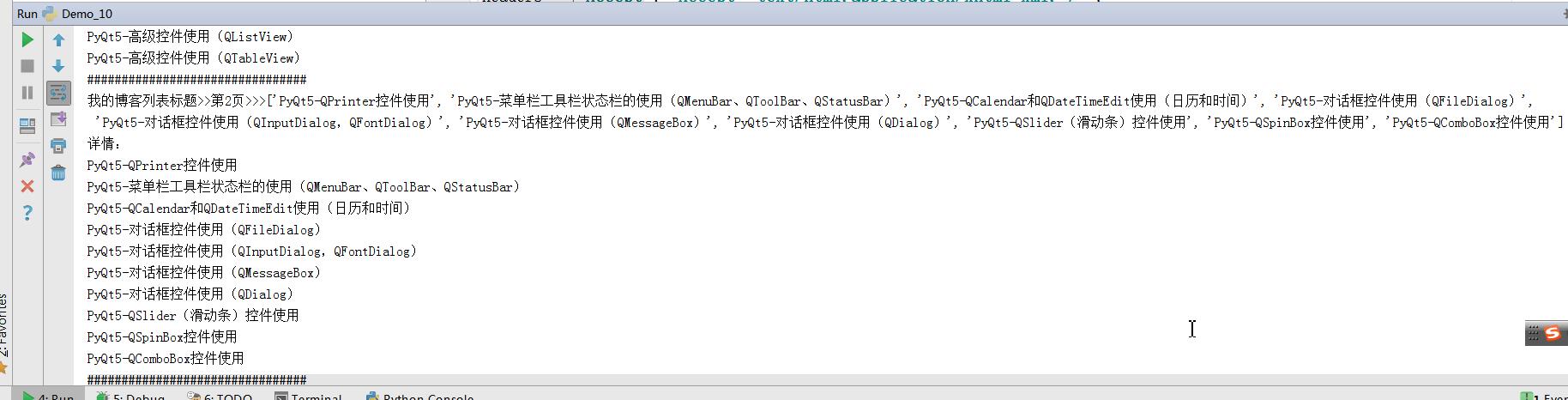
上面cookie字符串,设置在了headers中,然后跟着请求发送给服务器端;
也可以通过RequestCookieJar对象,传递:
代码片段: #不再headers中设置cookie那么也可以像下面一样,将cookie字符串拆分,通过RequestCookieJar对象封着后提交 cookies=\'td_cookie=18446744071949694669; SERVERID=a15b3bd10716e69d8be538bb89e87a05|1545789639|1545788153; _ga=GA1.2.2025196660.1543803050; __gads=ID=0acaebdef222f985:T=1543803056:S=ALNI_Mb4z_obzMRA-KI6xe7ms4H9T1F6aA; _gid=GA1.2.1065648169.1545718072; .CNBlogsCookie=1C1655941CDFCB0648208766D9FA57E2114A6F237B40201383F6906E7C528F42536F097A19008BBEA6DCCEAE1A6C0D2F9EF07AF5FDFD9E6D7F7A8BBE8655A75F0376CE8E8A1B712CC57F47D55C2ABCCD5C54D16A99779E980761B8C28070D088EC28C310; .Cnblogs.AspNetCore.Cookies=CfDJ8KlpyPucjmhMuZTmH8oiYTOnSN3OilBek6jhgR41R5Mez_H24LhyvqvRFrMeN_1T8cVypF0H9RrB4jhc0M5RpHR7-eqTd93eAvka-nV2OSFItlJwuO_-IOuZJYJU5FODierauD6wokWHE1o7bHvNixE-u9jzhi4m8nv5AgMMlN5JbDeJqbEh6o7zJQ8ho00nRQGjIQtOsPFIzDwWqHaD8dhUvPQ_js3IEb8rtrO_rNws27gJ0LZWRXZIq2FmNow2YtiF7xXgPngu_Ttk4WveBAVtyHxWy3U4RA2FR69UXdgw\' cookiejar=requests.cookies.RequestsCookieJar() for items in cookies.split(";"): k,v =items.split(\'=\',1)#=号分割,分割成2个字段 cookiejar.set(k,v)
1 res=requests.get("https://i.cnblogs.com/",headers=headers,params={\'page\':i},cookies=cookiejar)#通过cookies提交cookie
以上结果是一样的;
如何在同一个session下访问一个网站的不同URL?
在requests库中,通过get或者post方法可以模拟网页来访问一个URL,如果多次访问该网站的多个URL,则相当于是在不同会话下进行的访问,等同于
打开了多个浏览器访问不同URL;
例如:第一个请求利用post方法登录这个网站,后来第二个请求get来获取个人信息;此时两次请求会创建两次会话,即不同的Session;如何保证这两个请求时维持在同一
会话;
(1)两次请求设置同一个cookies来解决,烦琐,放弃
(2)利用Session对象解决
例如:
两次请求,在不同的session会话:
两次请求,在同一个session会话:
1 import requests 2 #访问同一个站点的两个url,不在同一个会话session 3 requests.get("http://httpbin.org/cookies/set/number/123456") 4 r=requests.get("http://httpbin.org/cookies") 5 print(r.text) 6 7 #访问同一个站点,不同url,在同一个会话内;则使用session 8 session=requests.Session() 9 session.get(\'http://httpbin.org/cookies/set/number/123456\') 10 rs=session.get(\'http://httpbin.org/cookies\') 11 print(rs.text)
结果:
{
"cookies": {}
}
{
"cookies": {
"number": "123456"
}
}
关于SSL证书验证,requests提供了关于证书验证的功能,当放松HTTP请求时,会自动检查SSL证书,我们可以使用verify参数控件是否检查此证书;该参数默认为True,即会自动验证;
12306早期没有使用国际SSL认证标准,因此访问时会有验证错误,要求下载证书;现在直接访问即可;
注意:
response = requests.get (\'https://www.12306.cn\',verify=False)
print(response.status_code)
设置verify可以忽略认证,但是会有警告:

提醒我们给他指定证书,下面方式可以屏蔽掉警告:
1 import urllib3 2 import requests 3 #12306已经支持SSL认证,不需要设置verify=False,下面只是演示 4 #但是设置为False后会有警告,下面来演示如何屏蔽警告 5 urllib3.disable_warnings()#忽略警告 6 response = requests.get (\'https://www.12306.cn\',verify=False) 7 print(response.status_code)
1 import urllib3 2 import requests 3 import logging 4 #12306已经支持SSL认证,不需要设置verify=False,下面只是演示 5 #但是设置为False后会有警告,下面来演示如何屏蔽警告 6 logging.captureWarnings(True)#通过捕获警告日志方式忽略警告 7 response = requests.get (\'https://www.12306.cn\',verify=False) 8 print(response.status_code)
代理设置(此处大概介绍,后续会单独说)
可以通过proxies属性类设置代理,此处略,后续单独说;
超时设置:
由于网络状态不好或者服务器网络响应慢导致无法响应,甚至接收不到响应报错,可设置timeout参数来设置响应时间;
例如:r=requests.get(‘https:www.baidu.com’,timeout=1) #实际设置连接、读取 总和为1秒
如果单独设置则:r=requests.get(‘https:www.baidu.com’,timeout=(5,11,20))
如果想一直等待下去,则timeout=None,这也是其默认值;
关于认证:
例如:开启tomcat,访问http://localhost:8080/manager/html
此时会显示
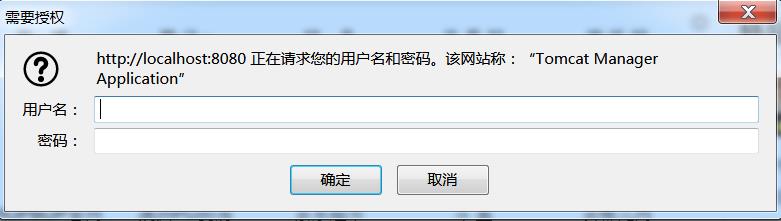
此时如下程序进行验证:
不认证是访问:
1 import requests 2 from requests.auth import HTTPBasicAuth 3 #访问同一个站点的两个url,不在同一个会话session 4 r=requests.get("http://localhost:8080/manager/html") 5 print(r.status_code)
结果401状态码
认证访问:
1 import requests 2 from requests.auth import HTTPBasicAuth 3 #访问同一个站点的两个url,不在同一个会话session 4 r=requests.get("http://localhost:8080/manager/html",auth=HTTPBasicAuth(\'admin\',\'admin\')) 5 print(r.status_code)
结果200状态码
或者auth=(\'admin\',\'admin\')替代auth=HTTPBasicAuth(\'admin\',\'admin\')
Prepared Request对象
Request对象可以将url、data、hreaders封装,在调用Session的prepare_request()方法转为Prepared Request对象,然后调用
send()方法发送请求;这样可以讲请求作为独立对象看待,有利于后期队列调度不同请求;
1 #PreparedRequest对象 2 from requests import Request,Session 3 url="http://httpbin.org/post" 4 data={\'name\':"JONES"} 5 headers={ 6 \'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0\' 7 } 8 req=Request(\'POST\',url,data=data,headers=headers) 9 session=Session() 10 prep=session.prepare_request(req) 11 r=session.send(prep) 12 print(r.text)
以上是关于Python-爬虫-基本库(requests)使用的主要内容,如果未能解决你的问题,请参考以下文章