Java NIO学习笔记七 Non-blocking Server
Posted 适AT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java NIO学习笔记七 Non-blocking Server相关的知识,希望对你有一定的参考价值。
Java NIO:Non-blocking Server
即使你了解了Java NIO非阻塞功能的工作(怎么样Selector,Channel, Buffer等等),设计一个无阻塞服务器仍然很难。非阻塞IO包含了相比阻塞IO的要有难度。本章非阻塞服务器教程将讨论非阻塞服务器的主要挑战,并为他们描述一些潜在的解决方案。
本教程中描述的想法是围绕Java NIO设计的。但是,我认为,只要有这样的构造,这些想法可以用其他语言重复使用Selector。据我所知,这样的结构是由底层操作系统提供的,所以很有可能您可以使用其他语言访问此操作。
非阻塞服务器 - GitHub存储库
我创建了一个简单的概念验证概念,在本教程中提出的想法,并将其放在GitRebu存储库中,可供查看。这是GitHub信息库:
https://github.com/jjenkov/java-nio-server
非阻塞IO管道
非阻塞IO管道是处理非阻塞IO组件的链。这包括以非阻塞方式读写IO。以下是简化的非阻塞IO管道的流程图:
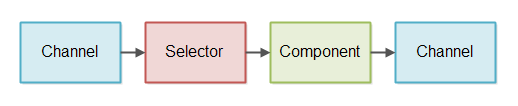
组件使用选择器来检测通道何时读取数据。然后组件读取输入数据,并根据输入生成一些输出。输出Channel再次写入。
非阻塞IO管道不需要同时读写数据。一些管道只能读取数据,而一些管道只能写入数据。
上图仅显示单个组件。非阻塞IO管道可能具有多个组件进程传入数据。非阻塞IO管道的长度取决于管道需要做什么。
非阻塞IO管道也可能同时从多个Channels 读取。例如,从多个SocketChannels 读取数据。
上图中的控制流程也简化了。它是发起数据的读出从该部件Channel经过Selector。事实不是图中所展示的Channel将数据推Selector进入到组件中。
非阻塞与阻塞IO管道
非阻塞和阻塞IO管道之间的最大区别是如何从底层Channel(套接字或文件)读取数据 。
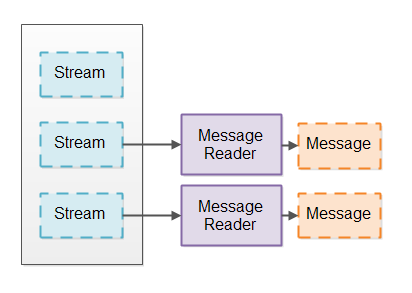
IO管道通常从一些流(从套接字或文件)读取数据,并将该数据分解成一致的消息。这类似于将数据流打破使用标记器进行解析。相反,您将数据流分解成更大的消息。我们把将流打破成消息的组件称为消息读取器。
消息阅读器将流分成消息的简易流程图:

阻塞IO管道可以使用InputStream接口,其中一次可以从底层Channel读取一个字节,并且其中的InputStream接口处于阻塞状态,直到有数据准备好读取。这导致阻塞Message Reader实现。
使用阻塞IO接口流大大简化了Message Reader的实现。阻塞消息读取器不必处理数据流中没有读取数据的情况,或者仅部分消息是从流中读取,并且消息需要稍后恢复解析。
类似地,阻塞消息写入器(将消息写入流的组件)不必处理仅写入部分消息的,以及稍后需要恢复消息写入的情况。
阻止IO管道缺点
虽然阻塞消息阅读器容易实现,但是对于需要分割成消息的每个流需要单独的线程是不幸的缺点。因此每个流的IO接口阻塞,直到有一些数据从中读取是必要的。这意味着单个线程不能尝试从一个流中读取,如果没有数据,则从另一个流中读取。一旦线程尝试从流中读取数据,线程将阻塞,直到实际上有一些数据要读取。
如果IO管道是处理大量并发连接的服务器的一部分,则服务器每个活动进入连接的将需要一个线程。如果服务器在任何时间只有几个并发连接,这可能不是一个问题。但是,如果服务器具有数百万个并发连接,则这种类型的设计不会很好地扩展。每个线程的堆栈将占用320K(32位JVM)和1024K(64位JVM)内存。所以,1000000线程将占用1 TB内存!而在这之前,服务器已经使用内存来处理传入的消息(例如,为消息处理期间使用的对象分配的内存)。
为了保持线程数量的减少,许多服务器使用一种设计,其中服务器保留一个线程池(例如100),从而一次从入站连接中读取消息。入站连接保留在队列中,并且线程按入站连接放入队列的顺序处理来自每个入站连接的消息。此设计如下图所示:
但是,此设计要求入站连接能够合理地发送数据。如果入站连接可能在较长时间内处于非活动状态,则大量非活动连接实际上可能会阻塞线程池中的所有线程。这意味着服务器响应迟缓,甚至无响应。
一些服务器设计尝试通过在线程池中的线程弹性数量数量来缓解这个问题。例如,如果线程池用尽线程,则线程池可能会启动更多的线程来处理负载。这方案意味着需要更多数量的慢速连接才能使服务器无响应。注意,您可以运行多少线程仍然有上限。所以,这将不会适应于1.000.000慢速连接。
基本无阻塞IO管道设计
非阻塞IO管道可以使用单个线程来读取多个流的消息。这要求流可以切换到非阻塞模式。当处于非阻塞模式时,如果你尝试从其读取数据时,流可能返回0个或更多字节。如果流没有要读取的数据,则返回0个字节。当流实际上有一些要读取的数据时,返回1+字节。
为了避免检查有0个字节的流,我们使用Java NIO选择器。一个或多个SelectableChannel实例可以用Selector注册。当调用select()或selectNow()在其上Selector只给出SelectableChannel实例,实际上有数据读取的。此设计如下图所示:
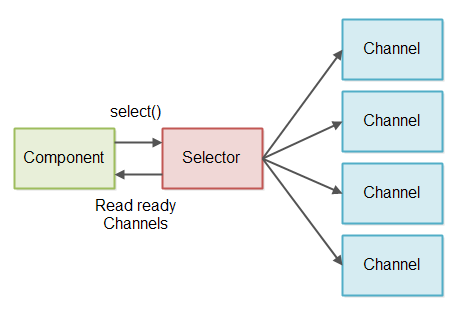
阅读部分消息
当我们从一个SelectableChannel数据块中读取数据时,我们不知道该数据块是否包含少于或者多于一个消息。数据块可能潜在地包含一个部分消息(小于一条消息),一条完整消息,或者多于一条消息,例如1.5或2.5条消息。各种部分消息的可能性如下所示:
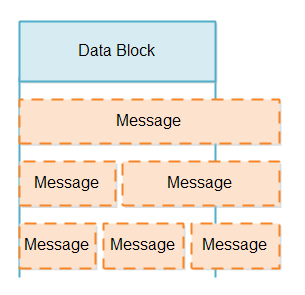
处理部分消息有两个难点:
A.检测数据块中是否有完整消息。
B.在部分消息到达消息的其余部分之前应该如何处理。
检测完整消息要求消息读取器查看数据块中的数据,查看数据是否至少包含一条完整消息。如果数据块包含一个或多个完整消息,则可以将这些消息发送到管道中进行处理。寻找完整信息的过程将会重复,所以这个过程必须尽可能快。
无论何时在数据块中存在部分消息,无论是本身还是在一个或多个完整消息之后,需要存储该部分消息,直到该消息的其余部分从该消息到达Channel。
检测完整消息和存储部分消息都是消息读取器的责任。为了避免混淆来自不同Channel实例的消息数据,我们将使用一个Message Reader Channel。设计如下所示:
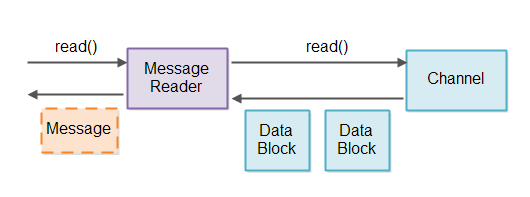
在检索到Channel具有要从中读取的数据的实例之后,与之相关联Selector的消息读取器Channel读取数据并尝试将其分解成消息。如果这样导致任何完整的消息被读取,这些消息可以被传递到读取流水线到需要处理它们的任何组件。
消息阅读器当然是协议特定的。消息读取器需要知道其尝试读取的消息的消息格式。如果我们的服务器实现可以通过协议重复使用,则需要能够将消息读取器实现插入 - 可能通过以某种方式接受消息读取器工厂作为配置参数。
存储部分消息
现在我们已经确定消息读取器有责任存储部分消息,直到收到完整的消息,我们需要弄清楚这个部分消息存储应该如何实现。
我们应该考虑两个设计考虑因素:
1.我们要尽可能少地复制信息数据。拷贝越多,性能越差。
2.我们希望将完整的消息存储在连续的字节序列中,使解析消息更容易。
每个消息读取器的缓冲区
显然,部分消息需要存储在缓冲器中。简单的实现将是在每个消息读取器中内部简单地具有一个缓冲区。但是,缓冲区应该有多大?它将需要足够大,以便能够存储甚至最大的允许的消息。所以,如果最大的允许消息是1MB,那么每个消息读取器中的内部缓冲区将需要至少为1MB。
当我们达到数以百万计的连接时,每个连接使用1MB并不会奏效。1.000.000 x 1MB还是1TB内存!如果最大邮件大小是16MB呢?或者128MB?
可调整缓冲区
另一个选择是实现一个可调整大小的缓冲区用于每个消息读取器内。一个可调整大小的缓冲区将开始小,如果一个消息对于缓冲区太大,缓冲区将被扩展。这样一来,每个连接不一定需要一个例如1MB的缓冲区。每个连接只需要占用大量内存,因为它们需要保存下一条消息。
实现缓存区的可调我们将在后面的几章讨论.
通过复制调整大小
实现可调整大小的缓冲区的第一种方法是从一个例如4KB的小缓冲区开始。如果消息不能适应4KB缓冲区,则可以分配更大的缓冲区,例如8KB,并将来自4KB缓冲区的数据复制到较大的缓冲区中。
通过复制调整大小的优缺点:
优点:是消息的所有数据都保存在单个连续的字节数组中。这使得解析消息更容易。
缺点:是它会导致大量的数据复制用于更大的消息。
为了减少数据复制,您可以分析流过系统的消息的大小,以找到一些可以减少复制量的缓冲区大小。例如,您可能会看到大多数消息都小于4KB,因为它们只包含非常小的请求/响应。这意味着第一个缓冲区大小应该是4KB。
那么你可能会看到,如果一条消息大于4KB,那通常是因为它包含一个文件。您可能会注意到,大部分流经系统的文件都不到128KB。那么使第二个缓冲区大小为128KB是有意义的。
最后你可能会看到,一旦一个消息高于128KB,消息的大小就没有真正的模式,所以也许最后的缓冲区大小应该是最大的消息大小。
根据流经系统的消息大小,这3种缓冲区大小可以减少数据复制。4KB以下的讯息永远不会被复制。对于1.000.000并发连接,导致1.000.000 x 4KB = 4GB,这在今天(2015年)的大多数服务器中是可能的。4KB和128KB之间的消息将被复制一次,只有4KB数据将被复制到128KB缓冲区。128KB和最大邮件大小之间的邮件将被复制两次。第一次4KB将被复制,第二次128KB将被复制,所以总共132KB复制最大的消息。假设没有超过128KB的这么多信息可能是可以接受的。
一旦消息完全处理完毕,分配的内存应该再次被释放。这样,从同一个连接接收到的下一条消息将以最小的缓冲区大小再次开始。这是必要的,以确保在连接之间可以更有效地共享内存。很可能并不是所有的连接都将同时需要大的缓冲区。
调整大小追加
调整缓冲区大小的另一种方法是使缓冲区由多个数组组成。当您需要调整缓冲区大小时,您只需分配另一个字节数组并将数据写入该数组。
有两种方式来增长这样一个缓冲区。一种方法是分配单独的字节数组并保留这些字节数组的列表。另一种方法是分配较大的共享字节数组的片段,然后保留分配给缓冲区的片段的列表。就个人而言,我觉得切片方法稍好些,但差别很小。
通过在其中附加单独的数组或片来增加缓冲区的优点是在写入过程中不需要复制数据。所有数据可以直接从套接字(Channel)直接复制到数组或片中。
以这种方式生长缓冲区的缺点是数据不存储在单个连续阵列中。这使得消息解析更加困难,因为解析器需要同时查找每个单独数组的末尾和所有数组的结束。由于您需要在写入的数据中查找消息的结尾,所以该模型并不容易使用。
TLV编码消息
一些协议消息格式使用TLV格式(类型,长度,值)进行编码。这意味着当消息到达时,消息的总长度被存储在消息的开头。这样你就可以立即知道为整个消息分配多少内存。
TLV编码使内存管理更加容易。您立即知道要为消息分配多少内存。只有部分使用的缓冲区结束时才会浪费内存。
TLV编码的一个缺点是在消息的所有数据到达之前分配消息的所有内存。因此,发送大邮件的慢速连接可以分配所有可用的内存,从而使您的服务器无响应。
此问题的解决方法是使用包含多个TLV字段的消息格式。因此,为每个字段分配存储器,而不是为整个消息分配存储器,并且仅当字段到达时才分配存储器。然而,一个大的字段可以对你的内存管理具有相同的效果,作为一个大的消息。
另一个解决方法是超时在10-15秒内未收到的消息。这可以使您的服务器从巧合,同时到达许多大消息恢复,但仍会使服务器反应迟一段时间。另外,有意的DoS(拒绝服务)攻击仍然可以为您的服务器完全分配内存。
TLV编码存在不同的变体。正是使用了多少字节,因此指定字段的类型和长度取决于每个单独的TLV编码。还有TLV编码首先放置字段的长度,然后是类型,然后是值(一个LTV编码)。虽然字段的顺序不同,但它仍然是TLV变体。
TLV编码使内存管理更容易的事实是HTTP 1.1是如此可怕的协议的原因之一。这是他们试图在HTTP 2.0中修复数据的问题之一,数据在LTV编码帧中传输。这也是为什么我们为 使用TLV编码的VStack.co项目设计了我们自己的网络协议。
写部分消息
在非阻塞IO管道中写入数据也是一个挑战。当您 以非阻塞模式调用write(ByteBuffer)时Channel,不能保证ByteBuffer正在写入的字节数。该write(ByteBuffer)方法返回写入多少个字节,因此可以跟踪写入的字节数。这就是挑战:跟踪部分写入的消息,以便最终发送一条消息的所有字节。
为了管理部分消息的写入,Channel我们将创建一个Message Writer。就像消息阅读器一样,我们将需要一个Message Writer,每个Channel我们写信息。在每个Message Writer中,我们跟踪正在写入的消息的字节数。
如果消息写入器的更多消息到达可以直接写入到消息写入器Channel的消息,消息需要在消息写入器内部排队。消息写入器然后将消息尽可能快地写入Channel。
这是一个图表,显示了部分消息写作到目前为止的设计:
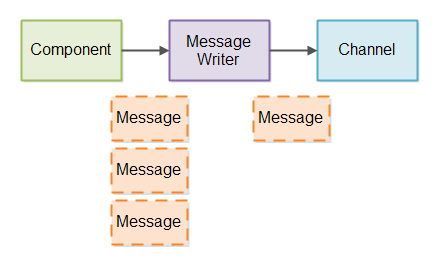
要使Message Writer能够发送仅部分早期发送的消息,则需要不时调用Message Writer,因此可以发送更多数据。
如果你有很多的连接,你将会有很多的Message Writer实例。检查例如一百万个Message Writer实例,看看他们是否可以写任何数据都很慢。首先,许多Message Writer实例很多都没有任何消息要发送。我们不想检查那些Message Writer实例。其次,并不是所有的Channel 实例都可以准备好写入数据。我们不想浪费时间尝试将数据写入Channel 不能接受任何数据的数据。
要检查是否Channel准备好写作,您可以使用a注册频道Selector。但是,我们不想用所有Channel实例注册Selector。想象一下,如果您有1.000.000个连接,大多是空闲的,并且所有的1.000.000个连接都已注册Selector。那么当你打电话时,select()大部分这些Channel 实例都会被写好(他们大都闲着,记得吗?)。然后,您必须检查所有这些连接的Message Writer,以查看他们是否有任何数据要写入。
为了避免检查消息的所有Message Writer实例,以及所有Channel实例,无论如何都不会发送任何消息,我们使用这两步的方法:
- 当消息写入消息写入器时,消息写入器注册它
Channel与Selector(如果尚未注册)相关联。 - 当您的服务器有时间时,它会检查
Selector哪些注册的Channel实例已准备好进行写入。对于每个写入就绪,Channel它的相关消息写入器被请求写入数据Channel。如果一个消息写入器将其所有消息写入其中Channel,Channel则从另一个消息 中注销Selector。
这个小的两步方法确保只有Channel具有写入消息的实例实际上已被注册Selector。
总结:
非阻塞服务器需要不时检查传入的数据,以查看是否收到新的完整消息。服务器可能需要多次检查,直到收到一个或多个完整的消息。一次检查是不够的。
同样,非阻塞服务器需要不时检查是否有任何数据要写入。如果是,服务器需要检查是否有任何相应的连接准备好将该数据写入它们。只有在第一次排队消息时才检查是不够的,因为消息可能被部分写入。
所有这些非阻塞服务器最终都需要定期执行的三个“管道”:
- 读取管道,用于从打开的连接检查新的传入数据。
- 处理任何收到的完整消息的进程流程。
- 写入流水线检查是否可以将任何传出的消息写入任何打开的连接。
这三条管道在循环中重复执行。您可能可以稍微优化执行。例如,如果没有排队的消息可以跳过写入管道。或者,如果我们没有收到新的,完整的消息,也许您可??以跳过流程管道。
以下是说明完整服务器循环的图:
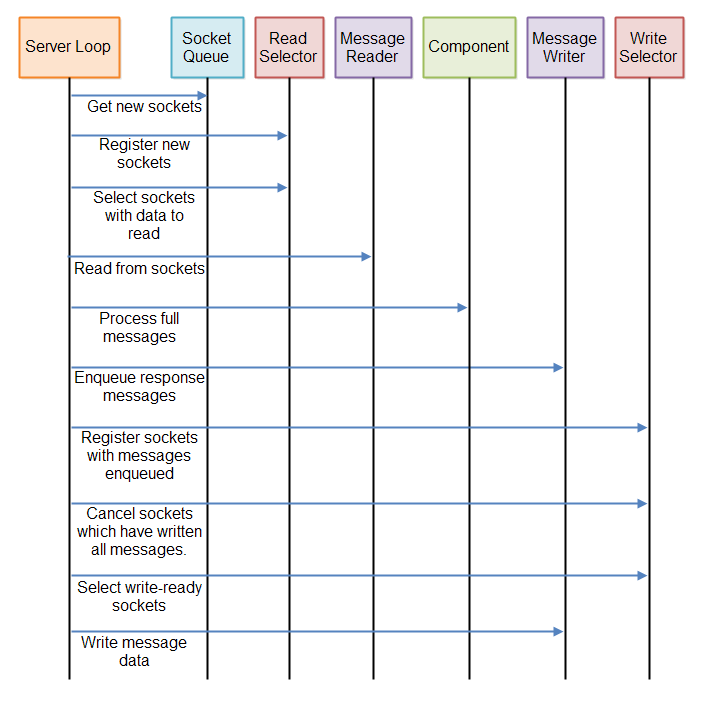
如果仍然发现这有点复杂,请记住查看GitHub资料库:
https://github.com/jjenkov/java-nio-server
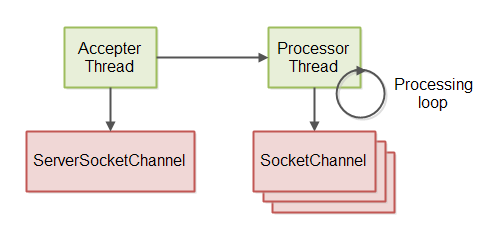
服务器线程模型
GitHub存储库中的非阻塞服务器实现使用具有2个线程的线程模型。第一个线程接受来自a的传入连接ServerSocketChannel。第二个线程处理接受的连接,意思是读取消息,处理消息并将响应写回连接。这个2线程模型如下所示:
以上是关于Java NIO学习笔记七 Non-blocking Server的主要内容,如果未能解决你的问题,请参考以下文章