java之容器(集合)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java之容器(集合)相关的知识,希望对你有一定的参考价值。
知识点:
容器的作用和概览
- 数组总结回顾
作用
是一种容器,可以在其中放置对象或基本类型数据。从而,实现使用数组管理一组对象。
优势
是一种简单的线性序列,可以快速的访问数组元素,效率高。如果从效率和类型检查的角度讲,数组是最好的。
劣势
不灵活:容量事先定义好,不能随着需求的变化而扩容。
比如:我们在一个用户管理系统中,要把今天注册的所有用户取出来,那么这个用户有多少个?我们在写程序时是无法确定的。
因此,数组远远不能满足我们的需求。
我们需要一种灵活的,容量可以随时扩充的容器来装载我们的对象。容器类,又叫集合框架。
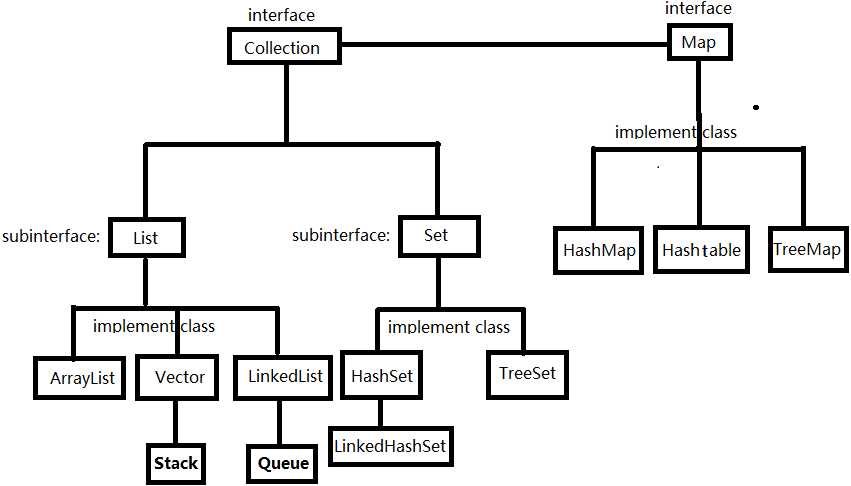
说明:
Collection接口:表示一组对象,它是集中、收集的意思,就是把一些数据收集起来。
Collection接口的两个子接口:List、Set
List接口:[不唯一(容器的元素可以重复存在[不是通过哈希表存储:数组或链表])、有序(存储顺序<且都有下标>]
List接口有序的解释:1)此接口的用户可以对列表中的每个元素的插入的位置进行精确的控制.
2)用户可以根据元素的索引(在列表中的位置)访问元素.
3)区别与Set:通常允许有重复的元素即列表允许满足:e1.equals(e2)的存在(如果允许有null、可以允许有多个存在)。
[ArrayList和LinkedList允许有多个null值的元素]而Set的集合[只能存在一个null元素]
4)多了一些跟顺序有关的方法:
比如:add方法中多了在指定索引位置添加元素的操作:add(int index,E element);
多了get方法:在指定下标位置获取元素get(int index);
多了indexOf(Object o);方法用于返回指定元素在列表中第一次出现的位置(索引值)。
多了lastIndexOf(Object o);方法返回指定元素在列表中最后一次出现的位置。
多了remove(int index,E element);方法和set(int index,E element);方法用于移除指定索引处的元素以及设置指定索引处的元素
。。。。。。。
5)实现类:ArrayList、Vector(Stack)、LinkedList(Queue)
解释ArrayList、Vector和LinkedList:
1)三者底层实现形式不同:
ArrayList和Vector:底层是有数组实现的List;LinkedList:底层是有双向链表实现的List
2)三者特点的区别:
ArrayList是查询效率高,增、删、改效率低,线程不安全。
Vector(查询效率高 ,增、删、改效率低)主要是线程安全的,用于多线程中。
LinkedList查询效率低,主要是增、删、改效率高,线程不安全
Set接口:HashSet[唯一(具有相同哈希码(hashCode()方法返回值相等)和内容相同(equals()方法判断是true)的元素只有一个存在、无序(存储在非连续的内存空间中)]
:TreeSet[存储的元素如果实现Comparable接口就会按照重写的compareTo(E o)方法比较来存储元素如果没有实现Comparable接口、就会根据指定比较器 Comparator对元素进行比较]
Set接口唯一的解释:1)存储的时候会根据对象的hash码来选择存取的位置。如果对象的类型和内容相同,则只会存储一个。
2)实现类:HashSet(包含LinkedHashSet)和TreeSet:
解释HashSet、LinkedHashSet和TreeSet:
1)三者底层实现形式不同:
HashSet和LinkedHashSet:底层采用Hashtable哈希表存储结构[插入无序];而LinkedHashSet同时使用链表维护次序[有序]。
TreeSet:采用二叉树(红黑树)的存储结构[原理二叉树有大小顺序;如果要放入的元素比当前节点值大的,应放在右子节点上;否则 放在其左子节点上]
2)三者的特点区别:
HashSet优点是添加、查询、删除速度快,缺点是无序;而LinkedHashSet具有其优点而又有有序(添加顺序)的特点
TreeSet优点是有序(排序后的升序)、查询速度比List快(按照内容查询/采用折半查找),缺点是查询速度没有HashSet快。
Map接口:[采用键值的方式存储数据<无序(HashMap(LinkedHashMap<添加有序>)/Hashtable插入顺序无序、TreeMap<大小顺序有序>)>]
ArrayList实现类的应用1:
1 package cn.zzsxt.collection_list_arraylist; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 /** 7 * Collection接口:[存储一组不唯一、无序的对象] 8 * List接口[存储不唯一、有序(插入顺序)的对象]:底层是用数组来实现的,本质上一个可变的数组,分配连续的内存空间 9 * ------->实现类:ArrayList: 10 * Set接口[存储唯一、无序的对象]: 11 * Map接口[存储键值对(key-->value)]: 12 */ 13 /** 14 * Collection接口 15 * 常用的方法: 16 * add(Object e) 确保此 collection 包含指定的元素(可选操作)。 17 * size():获取集合中元素的个数 18 * remove(Object e):移除元素 19 * clear():清空集合中元素 20 * contains(Object e):判断集合中是否包含指定的元素 21 * isEmpty():判断集合是否为空 22 * iterator():获取集合对应的迭代器。 23 * --List接口:不唯一,有序(插入顺序) 24 * ----ArrayList类:可变长度的数组,本质上是通过数组实现的,在内存中存储空间是连续 25 * ------优点:随机访问或遍历时效率较高 26 * ------缺点:插入和删除时需要大量对元素的位置进行移动,效率较低。 27 * ArrayList常用的构造方法 28 * ArrayList() 构造一个初始容量为 10 的空列表。 29 * ArrayList(int initialCapacity) 构造一个具有指定初始容量的空列表。 30 * 常用的方法: 31 * add(Object e):将元素添加到集合中。 32 * add(int index, E element) 将指定的元素插入此列表中的指定位置。 33 * get(int index) 返回此列表中指定位置上的元素。下标从0开始 34 * addAll(Collection<? extends E> c) 按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。 35 * set(int index, E element)用指定的元素替代此列表中指定位置上的元素。 36 * remove(int index)移除此列表中指定位置上的元素。 37 * remove(Object o) 移除此列表中首次出现的指定元素(如果存在)。 38 * --Set接口:唯一,无序 39 * Map接口:采用键值对进行存储。 40 */ 41 42 public class TestArrayList { 43 public static void main(String[] args) { 44 // Collection list = new ArrayList(); 45 List list = new ArrayList(); 46 List list2 = new ArrayList(); 47 list.add("aa"); 48 list.add("bb"); 49 list.add("cc"); 50 list.add(2, "dd"); 51 list.remove("aa"); 52 list.remove(0); 53 System.out.println(list.contains("ss")); 54 System.out.println(list.contains("aa")); 55 list2.addAll(list); 56 // list.clear(); 57 list.set(1, "11"); 58 for (int i = 0; i < list.size(); i++) { 59 String str = (String)list.get(i); 60 System.out.println(str); 61 } 62 System.out.println(); 63 for (int i = 0; i < list2.size(); i++) { 64 String str = (String)list2.get(i); 65 System.out.println(str); 66 } 67 System.out.println(); 68 ArrayList subList = new ArrayList(); 69 subList.add("hello"); 70 subList.set(0, "word"); 71 for (Object object : subList) { 72 String str = (String)object; 73 System.out.println(str); 74 } 75 } 76 }
ArrayList应用2:
1 package cn.zzsxt.collection_list_arraylist; 2 3 import java.util.ArrayList; 4 /** 5 *java.util.ArrayList类 6 *add(Object obj):添加元素 7 *Object get(int index):获取指定下标位置的元素. 8 *注意:在调用add方法添加元素时,该元素会向上转型为Object类型,所有使用get方法获取是返回值为Object 9 */ 10 public class TestArrayList2 { 11 public static void main(String[] args) { 12 Student stu = new Student("zhangsan",22); 13 Student stu2 = new Student("zhangsan2",24); 14 Student stu3 = new Student("zhangsan3",26); 15 ArrayList arrayList = new ArrayList(); 16 arrayList.add(stu); 17 arrayList.add(stu2); 18 arrayList.add(stu3); 19 for (int i = 0; i < arrayList.size(); i++) { 20 Student stus = (Student)arrayList.get(i); 21 System.out.println(stus.getName()+"---"+stus.getAge()); 22 } 23 System.out.println(); 24 for (Object object : arrayList) { 25 Student stus = (Student)object; 26 System.out.println(stus.getName()+"---"+stus.getAge()); 27 } 28 } 29 }
泛型:JDK1.5之后的新特性
作用:用来限定集合中的元素类型
语法:集合类型 <E> 集合变量名 = new 集合实现类名<E>();
注意:一旦集合使用了泛型,集合中的元素类型就固定啦。
泛型在集合中的应用1:
1 package cn.zzsxt.collection_list_arraylist; 2 3 import java.util.ArrayList; 4 /** 5 * 泛型:JDK1.5之后的新特性 6 * --->用来限定集合中元素类型 7 * --->语法:List<E> list = new ArrayList<E>(); 8 * --->一旦对集合使用泛型,该集合容纳的类型就固定啦。 9 * --->特点:1.可以避免强制转换 10 * 2.可以消除黄色的警报。 11 */ 12 public class TestArrayList3 { 13 public static void main(String[] args) { 14 Student stu = new Student("zhangsan",22); 15 Student stu2 = new Student("zhangsan2",24); 16 Student stu3 = new Student("zhangsan3",26); 17 ArrayList<Student> arrayList = new ArrayList<Student>(); 18 arrayList.add(stu); 19 arrayList.add(stu2); 20 arrayList.add(stu3); 21 //方法1:使用一般的for循环来遍历实现List接口的集合中的元素 22 for (int i = 0; i < arrayList.size(); i++) { 23 Student stus = arrayList.get(i);//使用泛型后不需要强制转换 24 System.out.println(stus.getName()+"---"+stus.getAge()); 25 } 26 System.out.println(); 27 //方法2:使用增强的for循环来遍历实现List接口的集合中的元素 28 for (Student stus : arrayList) { 29 System.out.println(stus.getName()+"---"+stus.getAge()); 30 } 31 } 32 }
Iterator接口:[位于java.util.Iterator的类包]
作用:对Collection(implements Iteratable)进行迭代的迭代器
常用的方法:hashNext();判断是否有下个元素
next();返回迭代的下一个元素
Iterator接口的应用[用于遍历容器中的元素]1:
1 package cn.zzsxt.collection_list_arraylist; 2 3 import java.util.ArrayList; 4 import java.util.Calendar; 5 import java.util.Iterator; 6 import java.util.List; 7 /** 8 *Iterator接口:在java.util.Iterator包中 9 * 对Collection[implements Iterable接口] 进行迭代的迭代器 10 * boolean hasNext(); 如果仍有元素可以迭代,则返回true 11 * E next(); 返回迭代的下一个元素 12 */ 13 public class TestIterator { 14 public static void main(String[] args) { 15 List<String> list = new ArrayList<String>(); 16 list.add("zhang"); 17 list.add("qian"); 18 list.add("wang"); 19 list.add("li"); 20 //方法3:通过迭代器来遍历集合中的元素--->使用while循环 21 Iterator<String> iterator = list.iterator(); 22 // Calendar calendar = Calendar.getInstance(); 23 while(iterator.hasNext()) { 24 String str = iterator.next(); 25 System.out.println(str); 26 } 27 System.out.println("*********************************"); 28 //方法3:通过迭代器来遍历集合中的元素--->使用for循环 29 for(Iterator<String> iterator2=list.iterator();iterator2.hasNext();) { 30 String str2 = iterator2.next(); 31 System.out.println(str2); 32 } 33 } 34 }
LinkedList的应用1:
1 package cn.zzsxt.collection_list_linkedlist; 2 3 import java.util.Iterator; 4 import java.util.LinkedList; 5 /** 6 * List接口 7 * ----ArrayList类:在内存中存储位置是连续的,线性结构(可变长度的数组),随机访问或遍历效率较高,但插入和删除元素效率较低. 8 * ----LinkedList类:在内存中存储位置是不连续的,链表结构,插入和删除元素时效率较高,但随机访问或遍历效率较低。 9 * 常用方法: 10 * add(Object o):将指定元素添加到此列表的结尾。 11 * add(int index, E element)在此列表中指定的位置插入指定的元素。 12 * addFirst(E e) 将指定元素插入此列表的开头。(LinkedList特有的) 13 * addLast(E e)将指定元素添加到此列表的结尾。(LinkedList特有的) 14 * getFirst() 返回此列表的第一个元素。 15 * getLast() 返回此列表的最后一个元素。 16 * removeFirst() 移除并返回此列表的第一个元素。 17 * removeLast() 移除并返回此列表的最后一个元素。 18 */ 19 public class TestLinkedList { 20 public static void main(String[] args) { 21 LinkedList<String> linkedList = new LinkedList<String>(); 22 linkedList.add("java"); 23 linkedList.add("html"); 24 linkedList.addFirst("c"); 25 linkedList.addLast("Oracle"); 26 System.out.println("linkedList容器中的第一元素:"+linkedList.getFirst()); 27 System.out.println("linkedList容器中的最后一个元素:"+linkedList.getLast()); 28 System.out.println(); 29 linkedList.removeLast(); 30 linkedList.removeFirst(); 31 //遍历方法1/2/3:通过下标[下标从0开始到] 32 for (int i = 0; i < linkedList.size(); i++) { 33 String string = linkedList.get(i); 34 System.out.println(string); 35 } 36 System.out.println(); 37 //增强的for-each循环[循环遍历的数据类型 变量:存放变量的容器或者数组] 38 for (String string : linkedList) { 39 System.out.println(string); 40 } 41 System.out.println(); 42 //通过迭代器[初始化迭代器(取得linkedList容器的迭代器),循环条件判断(迭代器中是否有元素),循环体(移动游标取出容器中的元素)] 43 for(Iterator<String> iterator = linkedList.iterator();iterator.hasNext();) { 44 String string = iterator.next(); 45 System.out.println(string); 46 } 47 } 48 }
LinkedList的应用2:
1 package cn.zzsxt.collection_list_linkedlist; 2 3 import java.util.Iterator; 4 import java.util.LinkedList; 5 6 public class TestLinkedListPractice { 7 public static void main(String[] args) { 8 Dog dog1 = new Dog("欧欧",90); 9 Dog dog2 = new Dog("亚亚",100); 10 Dog dog3 = new Dog("美美",89); 11 Dog dog4 = new Dog("丽丽",99); 12 LinkedList<Dog> linkedList = new LinkedList<Dog>(); 13 linkedList.add(dog1); 14 linkedList.add(dog2); 15 linkedList.add(dog3); 16 linkedList.add(dog4); 17 System.out.println("共有"+linkedList.size()+"只狗狗"); 18 System.out.println("分别是:"); 19 System.out.println("昵称"+"\\t"+"亲密度"); 20 for(Iterator<Dog> iterator = linkedList.iterator();iterator.hasNext();) { 21 Dog dog = iterator.next(); 22 System.out.println(dog.getName()+"\\t"+dog.getDu()); 23 } 24 linkedList.remove(2); 25 // linkedList.remove(2); 26 linkedList.removeLast(); 27 System.out.println("====================================="); 28 System.out.println("删除之后,还有:"+linkedList.size()+"狗狗"); 29 System.out.println("昵称"+"\\t"+"亲密度"); 30 for(Iterator<Dog> iterator2 = linkedList.iterator();iterator2.hasNext();) { 31 Dog dog = iterator2.next(); 32 System.out.println(dog.getName()+"\\t"+dog.getDu()); 33 } 34 System.out.println("====================================="); 35 boolean is = linkedList.contains(dog2); 36 if(is) { 37 System.out.println("集合中包含亚亚的信息"); 38 } 39 } 40 }
LinkedList的应用3:
用于实现一个堆栈:
1 package cn.zzsxt.collection_list_linkedlist; 2 3 import java.util.LinkedList; 4 import java.util.List; 5 /** 6 *栈LIFO/FILO:后进先出(Last In First Out),先进后出(First In Last Out) 7 * 类似于玩具枪的弹夹,第一个压进去的子弹最后一个弹出 8 *入栈(压栈):将元素添加到栈中。 9 *出栈(弹栈):将元素从栈的顶部移除。 10 *队列FIFO:先进先出(First In First Out) 11 */ 12 public class MyStack { 13 LinkedList list = new LinkedList(); 14 public void push(Object obj) { 15 // list.addLast(obj); 16 list.addFirst(obj); 17 } 18 19 public Object pop() { 20 // Object obj = list.removeLast(); 21 Object obj = list.removeFirst(); 22 return obj; 23 } 24 25 public static void main(String[] args) { 26 MyStack stack = new MyStack(); 27 stack.push("aa"); 28 stack.push("bb"); 29 stack.push("cc"); 30 Object obj1 = stack.pop(); 31 Object obj2 = stack.pop(); 32 Object obj3 = stack.pop(); 33 System.out.println(obj1); 34 System.out.println(obj2); 35 System.out.println(obj3); 36 } 37 }
Vector实现类的应用:
1 package cn.zzsxt.collection_list_linkedlist; 2 3 import java.util.List; 4 import java.util.Vector; 5 /** 6 * Vector类也是接口List的实现类 7 * 与ArrayList和LinkedList的区别: 8 * 1.Vector类是线性结构与ArrayList相同,而LinkedList是链表结构 9 * 2.Vector是线程安全的而ArrayList是非线程安全的。 10 * 3.LinkedList在添加、删除元素时效率比较高,而随机访问和查找时效率较低。 11 * 4.ArrayList与Vector在随机访问和查找元素时效率较高,而添加和删除元素时,效率低。 12 * 13 */ 14 public class TestVector { 15 public static void main(String[] args) { 16 List<String> vector = new Vector<String>(); 17 vector.add("aa"); 18 vector.add("bb"); 19 vector.add("cc"); 20 for (int i = 0; i < vector.size(); i++) { 21 String str = vector.get(i); 22 System.out.println(str); 23 } 24 } 25 }
Stack现实类:
Stack 类表示后进先出(LIFO)的对象堆栈。它通过五个操作对类 Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的 push 和 pop 操作,以及取堆栈顶点的 peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的 search 方法。
首次创建堆栈时,它不包含项。
--------------------------------------------------------------------------------------------------------------------------------------------------------------
实现类HashSet的应用:
1 package cn.zzsxt.collection_set_hashset; 2 3 import java.util.HashSet; 4 import java.util.Iterator; 5 import java.util.Set; 6 /** 7 *Collection接口的实现接口: 8 * Set接口:(无序、唯一) 9 * 有实现类: 10 * --->1)HashSet:[包含LinkedHashSet] 11 * 底层是HashCode码表[散列表]存储的(缺点是无序) 12 * 优点:查询、删除、添加效率高 13 * 常用的方法: 14 * 构造方法:HashSet();/HashSet(Collection<? extends E> c) 15 * 实例方法:add/remove/iterator/size/clear/contains/isEmpty 16 * --->2)TreeSet: 17 * 18 */ 19 /** 20 *Set接口:无序,唯一(不重复) 21 *----HashSet:采用hash表(散列表)方式进行存储数据。 22 * 优点:查询,添加,删除速度较快。 23 * 缺点:无序(添加顺序) 24 *常用的构造方法: 25 * HashSet() 构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。 26 * HashSet(int initialCapacity) 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。 27 *常用的方法: 28 * add(E e)如果此 set 中尚未包含指定元素,则添加指定元素。 29 * clear() 从此 set 中移除所有元素。 30 * contains(Object o) 如果此 set 包含指定元素,则返回 true。 31 * iterator() 返回对此 set 中元素进行迭代的迭代器。 32 * size()返回此 set 中的元素的数量(set 的容量)。 33 * remove(Object o)如果指定元素存在于此 set 中,则将其移除。 34 */ 35 public class TestHashSet { 36 public static void main(String[] args) { 37 Set<String> set = new HashSet<String>(); 38 set.add("java"); 39 set.add("html"); 40 set.add("mysql"); 41 //遍历集合的方法1、2 42 for(String string:set) { 43 System.out.println(string); 44 } 45 System.out.println(); 46 //方法2:使用迭代器 47 for(Iterator<String> iterator = set.iterator();iterator.hasNext();) { 48 String str = iterator.next(); 49 System.out.println(str); 50 } 51 } 52 }
HashSet存储对象唯一且无序的应用:
1 package cn.zzsxt.collection_set_hashset; 2 3 public class Student { 4 private String name; 5 private int age; 6 7 public Student() { 8 super(); 9 // TODO Auto-generated constructor stub 10 } 11 12 public Student(String name, int age) { 13 super(); 14 this.name = name; 15 this.age = age; 16 } 17 18 public String getName() { 19 return name; 20 } 21 22 public void setName(String name) { 23 this.name = name; 24 } 25 26 public int getAge() { 27 return age; 28 } 29 30 public void setAge(int age) { 31 this.age = age; 32 } 33 34 @Override 35 public int hashCode() { 36 System.out.println("hashCode方法被调用了..."); 37 final int prime = 31; 38 int result = 1; 39 result = prime * result + age; 40 result = prime * result + ((name == null) ? 0 : name.hashCode()); 41 return result; 42 } 43 44 @Override 45 public boolean equals(Object obj) { 46 System.out.println("equals方法被调用了..."); 47 if (this == obj) 48 return true; 49 if (obj == null) 50 return false; 51 if (getClass() != obj.getClass()) 52 return false; 53 Student other = (Student) obj; 54 if (age != other.age) 55 return false; 56 if (name == null) { 57 if (other.name != null) 58 return false; 59 } else if (!name.equals(other.name)) 60 return false; 61 return true; 62 } 63 64 }
1 package cn.zzsxt.collection_set_hashset; 2 3 import java.util.HashSet; 4 import java.util.Set; 5 6 /** 7 *如果向set结合添加对象时,想将内容相同的重复项去掉,需要重写hashCode()和equals() 8 *hashCode()和equals()的关系 9 *在向Set集合中添加元素时 ,先调用hashCode()方法获取当前对象的hash码, 10 *根据对象的hash码与集合中对象的hash码进行比较,如果hash码相同在调用equals()方法进行比较内容是否相同。 11 *如果hash码不同,将不再调用equals方法。 12 *如果equals相同,hash码肯定相同;hash码相同,equals结果不一定相同。 13 */ 14 public class TestHashSet2 { 15 public static void main(String[] args) { 16 Student stu1 = new Student("zhangsan",20); 17 Student stu2 = new Student("zhangsan2",20); 18 Student stu3 = new Student("zhangsan",20); 19 Set<Student> set = new HashSet<Student>(); 20 set.add(stu1); 21 System.out.println("*************");//每添加一个对象到HashSet集合中就会调用重写的hashCode()方法来计算其哈希码值作为存储的位置。 22 set.add(stu2); 23 set.add(stu3);//如果存储的两个对象的hashCode码相同就要调用重写后的equals()方法看两个对象的内容是否相同来决定是否在相应哈希表位置上存储相应的对象,如果内容也相同的话,就不存储了 24 for (Student student : set) { 25 System.out.println(student.getName()+"------"+student.getAge()); 26 } 27 } 28 }
LinkedHashSet:哈希表+链表实现[唯一、有序(添加顺序)]
应用1:
1 package cn.zzsxt.collection_set_hashset; 2 3 import java.util.Iterator; 4 import java.util.LinkedHashSet; 5 import java.util.Set; 6 /** 7 *Set接口:[唯一、无序(插入顺序)] 8 *--->HashSet[唯一、无序(插入顺序)]:底层使用哈希表实现的 9 *------>LinkedHashSet: hash表+链表实现的[唯一、有序(添加顺序)] 10 *-------->常用构造方法:LinkedHashSet();构造一个带默认初始容量 (16) 和加载因子 (0.75) 的新空链接哈希 set 11 *-------->常用方法:add(E element);/remove(E element);/contains(E element)/size();/iterator();.... 12 */ 13 public class TestLinkedHashSet { 14 public static void main(String[] args) { 15 Set<String> set = new LinkedHashSet<String>(); 16 set.add("java"); 17 set.add("struts"); 18 set.add("mysql"); 19 set.add("oracle"); 20 21 System.out.println(set); 22 System.out.println(); 23 for(String string:set) { 24 System.out.println(string); 25 } 26 System.out.println(); 27 for(Iterator<String> iterator = set.iterator();iterator.hasNext();) { 28 String string = iterator.next(); 29 System.out.println(string); 30 } 31 } 32 }
TreeSet类是继承了AbstractSet类,实现了Set接口
应用1:
1 package cn.zzsxt.collection_set_treeset; 2 3 import java.util.Iterator; 4 import java.util.Set; 5 import java.util.TreeSet; 6 /** 7 *TreeSet类是继承AbstractSet实现了Set接口 8 * 原理:在向TreeSet容器中添加元素时,会比较元素跟根节点或父节点的大小 9 * 比父节点大/根节点大的放在其右边的子节点上; 10 * 比父节点小/根节点小的放在其左边的子节点上。 11 * [遍历时,会按照自然顺序输出] 12 * 优点:有序:(大小顺序)、查询速度比List的实现类要快,但没有HashSet快。 13 * 常用的构造方法: 14 * TreeSet();//构造一个空的TreeSet容器 15 * TreeSet(Comparator<super E> comparator);//构造一个空的TreeSet容器,它会根据指定的Comparator接口(中的compare(T o1,T o2)比较器进行排序。 16 * 常用的方法: 17 * size(); 18 * iterator(); 19 * add(E element); 20 * remove(E element); 21 * contains(E element); 22 * 23 */ 24 public class TestTreeSet { 25 public static void main(String[] args) { 26 Set<Integer> set = new TreeSet<Integer>(); 27 set.add(1); 28 set.add(20); 29 set.add(30); 30 set.add(10); 31 //遍历输入 32 for (Integer integer : set) { 33 System.out.println(integer); 34 } 35 36 System.out.println(); 37 for(Iterator<Integer> iterator = set.iterator();iterator.hasNext();) { 38 Integer i = iterator.next(); 39 System.out.println(i); 40 } 41 } 42 }
应用2:使用元素的自然顺序对元素进行排序(实现了Comparable接口)
package cn.zzsxt.collection_set_treeset; /** * 实现比较的两个方法1:要比较的对象实现Comparable接口[重写compareTo(T o)方法-->定义比较规则的方法] * */ public class Student implements Comparable<Student>{ private String name; private int age; public Student() { super(); } public Student(String name, int age) { super(); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public int hashCode() { System.out.println("hashCode被调用了..."); final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { System.out.println("equals被调用了..."); if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } @Override public int compareTo(Student o) { System.out.println("compareTo()方法被调用了..."); return age-o.age; // return name.equals(o.name) ? 0 : 1; } } package cn.zzsxt.collection_set_treeset; import java.util.TreeSet; /** * *TreeSet:使用元素的自然顺序对元素进行排序, * 或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。 * TreeSet():构造一个新的空 set,该 set 根据其元素的自然顺序进行排序。插入该 set 的所有元素都必须实现 Comparable接口 * ---->所有这些元素都必须是可互相比较的:对于 set 中的任意两个元素 e1 和 e2,执行 e1.compareTo(e2) 都不得抛出 ClassCastException。 */ public class TestTreeSet2 { public static void main(String[] args) { TreeSet<Student> treeSet = new TreeSet<Student>(); Student stu1 = new Student("zhangsan1",20); Student stu2 = new Student("zhangsan2",18); Student stu3 = new Student("zhangsan3",25); Student stu4 = new Student("zhangsan1",20); treeSet.add(stu1); System.out.println("-----------------"); treeSet.add(stu2); System.out.println("-----------------"); treeSet.add(stu3); System.out.println("-----------------"); treeSet.add(stu4); for (Student student : treeSet) { System.out.println(student.getName()+"--"+student.getAge()); } } }
应用3:使用指定的比较器(实现Comparator接口)规定的比较规则(compare(T o1,T o2))对元素进行排序:
1 package cn.zzsxt.collection_set_treeset; 2 /** 3 * 实现比较的两个方法1:要比较的对象实现Comparable接口[重写compareTo(T o)方法-->定义比较规则的方法] 4 * 5 */ 6 public class Student implements Comparable<Student>{ 7 private String name; 8 private int age; 9 public Student() { 10 super(); 11 } 12 public Student(String name, int age) { 13 super(); 14 this.name = name; 15 this.age = age; 16 } 17 public String getName() { 18 return name; 19 } 20 public void setName(String name) { 21 this.name = name; 22 } 23 public int getAge() { 24 return age; 25 } 26 public void setAge(int age) { 27 this.age = age; 28 } 29 30 @Override 31 public int hashCode() { 32 System.out.println("hashCode被调用了..."); 33 final int prime = 31; 34 int result = 1; 35 result = prime * result + age; 36 result = prime * result + ((name == null) ? 0 : name.hashCode()); 37 return result; 38 } 39 @Override 40 public boolean equals(Object obj) { 41 System.out.println("equals被调用了..."); 42 if (this == obj) 43 return true; 44 if (obj == null) 45 return false; 46 if (getClass() != obj.getClass()) 47 return false; 48 Student other = (Student) obj; 49 if (age != other.age) 50 return false; 51 if (name == null) { 52 if (other.name != null) 53 return false; 54 } else if (!name.equals(other.name)) 55 return false; 56 return true; 57 } 58 @Override 59 public int compareTo(Student o) { 60 System.out.println("compareTo()方法被调用了..."); 61 return age-o.age; 62 // return name.equals(o.name) ? 0 : 1; 63 } 64 } 65 66 67 package cn.zzsxt.collection_set_treeset; 68 69 import java.util.TreeSet; 70 /** 71 * 72 *TreeSet:使用元素的自然顺序对元素进行排序, 73 * 或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。 74 * TreeSet():构造一个新的空 set,该 set 根据其元素的自然顺序进行排序。插入该 set 的所有元素都必须实现 Comparable接口 75 * ---->所有这些元素都必须是可互相比较的:对于 set 中的任意两个元素 e1 和 e2,执行 e1.compareTo(e2) 都不得抛出 ClassCastException。 76 */ 77 public class TestTreeSet2 { 78 public static void main(String[] args) { 79 TreeSet<Student> treeSet = new TreeSet<Student>(); 80 Student stu1 = new Student("zhangsan1",20); 81 Student stu2 = new Student("zhangsan2",18); 82 Student stu3 = new Student("zhangsan3",25); 83 Student stu4 = new Student("zhangsan1",20); 84 treeSet.add(stu1); 85 System.out.println("-----------------"); 86 treeSet.add(stu2); 87 System.out.println("-----------------"); 88 treeSet.add(stu3); 89 System.out.println("-----------------"); 90 treeSet.add(stu4); 91 for (Student student : treeSet) { 92 System.out.println(student.getName()+"--"+student.getAge()); 93 } 94 } 95 } 96 应用3:使用指定的比较器(实现Comparator接口)规定的比较规则(compare(T o1,T o2))对元素进行排序: 97 98 package cn.zzsxt.collection_set_treeset; 99 100 import java.util.Comparator; 101 /** 102 * 实现对象比较的第二个方法2:自定义一个实现了比较器Comparator的类。在创建容器TreeSet的构造方法时,调用带有指定比较器的构造方法。 103 * 就可以使用重写了Comparator比较器接口的比较方法:compare(T o1,T o2);来实现指定规则的排序 104 * 105 */ 106 public class TeacherComparator implements Comparator<Teacher> { 107 108 @Override 109 public int compare(Teacher o1, Teacher o2) { 110 return -(o1.getWorkOfYear()-o2.getWorkOfYear()); 111 } 112 113 } 114 ============================================ 115 package cn.zzsxt.collection_set_treeset; 116 117 public class Teacher { 118 private String name; 119 private int workOfYear; 120 public Teacher() { 121 super(); 122 } 123 public Teacher(String name, int workOfYear) { 124 super(); 125 this.name = name; 126 this.workOfYear = workOfYear; 127 } 128 public String getName() { 129 return name; 130 } 131 public void setName(String name) { 132 this.name = name; 133 } 134 public int getWorkOfYear() { 135 return workOfYear; 136 } 137 public void setWorkOfYear(int workOfYear) { 138 this.workOfYear = workOfYear; 139 } 140 /** 141 * 保证唯一性以及确定存储位置的方法1: 142 */ 143 @Override 144 public int hashCode() { 145 System.out.println("hashCode()方法被调用了..."); 146 final int prime = 31; 147 int result = 1; 148 result = prime * result + ((name == null) ? 0 : name.hashCode()); 149 result = prime * result + workOfYear; 150 return result; 151 } 152 /** 153 * 确保内容等同的对象只能存储一个的方法 154 */ 155 @Override 156 public boolean equals(Object obj) { 157 System.out.println("equals()方法被调用了..."); 158 if (this == obj) 159 return true; 160 if (obj == null) 161 return false; 162 if (getClass() != obj.getClass()) 163 return false; 164 Teacher other = (Teacher) obj; 165 if (name == null) { 166 if (other.name != null) 167 return false; 168 } else if (!name.equals(other.name)) 169 return false; 170 if (workOfYear != other.workOfYear) 171 return false; 172 return true; 173 } 174 } 175 ============================================ 176 package cn.zzsxt.collection_set_treeset; 177 178 import java.util.Iterator; 179 import java.util.TreeSet; 180 /** 181 *TreeSet类的构造方法: 182 * TreeSet(Comparator<super T> comparator);:按指定的比较器对TreeSet容器内的元素进行排序。 183 * ---->插入到该 set 的所有元素都必须能够由指定比较器进行相互比较: 184 * ---->对于 set 中的任意两个元素 e1 和 e2,执行 comparator.compare(e1, e2) 都不得抛出 ClassCastException。 185 */ 186 public class TestTreeSet3 { 187 public static void main(String[] args) { 188 // TreeSet<Teacher> treeSet = new TreeSet<Teacher>(); 189 TreeSet<Teacher> treeSet = new TreeSet<Teacher>(new TeacherComparator()); 190 Teacher t1 = new Teacher("teacher1",8); 191 Teacher t2 = new Teacher("teacher2",5); 192 Teacher t3 = new Teacher("teacher3",10); 193 treeSet.add(t1); 194 treeSet.add(t2); 195 treeSet.add(t3); 196 for(Iterator<Teacher> iterator = treeSet.iterator();iterator.hasNext();) { 197 Teacher teacher = iterator.next(); 198 System.out.println(teacher.getName()+"--"+teacher.getWorkOfYear()); 199 } 200 } 201 } 202 =======================END==================
========================================Collection实现类和子接口END===========================================
HashMap类似于HashSet:
应用1:
1 package cn.zzsxt.map_hashmap; 2 3 import java.util.HashMap; 4 /** 5 *Map接口:采用是键值对的方式存放数据。无序 6 *常见的实现类: 7 *--HashMap:基于哈希表的 Map 接口的实现。 8 *常用的构造方法: 9 * HashMap()构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。 10 * HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap 11 *常用方法: 12 * put(K key, V value)在此映射中关联指定值与指定键。 13 * get(Object key) 返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。 14 * size() 返回此映射中的键-值映射关系数。 15 * remove(Object key) 从此映射中移除指定键的映射关系(如果存在)。 16 * clear() 从此映射中移除所有映射关系。 17 * containsKey(Object key) 如果此映射包含对于指定键的映射关系,则返回 true。 18 * containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。 19 *----LinkedHashMap 20 *--Hashtable 21 *--TreeMap 22 * 23 */ 24 public class TestHashMap { 25 public static void main(String[] args) { 26 HashMap<String,String> map = new HashMap<String,String>(); 27 map.put("jack", "成龙");//向容器中添加键值对 28 map.put("jay", "周杰伦"); 29 map.put("eason", "陈奕迅"); 30 map.remove("jack");//移除容器中的键 31 System.out.println("容器中是否包含周杰伦:"+map.containsValue("周杰伦"));//查看容器是否包含某个值 32 System.out.println("容器中是否包含键:jay:"+map.containsKey("jay"));//查看容器是否包含某个键 33 System.out.println("容器中有"+map.size()+"个键值对元素");//查看容器的存储啦多少个键值对 34 String name = map.get("jack");//通过键获取容器中的值 35 String name2 = map.get("jay"); 36 String name3 = map.get("eason"); 37 System.out.println(name); 38 System.out.println(name2); 39 System.out.println(name3); 40 } 41 }
HashMap三种遍历键值对方式的应用2:
1 package cn.zzsxt.map_hashmap; 2 3 import java.util.HashMap; 4 import java.util.Iterator; 5 import java.util.Map; 6 import java.util.Map.Entry; 7 import java.util.Set; 8 /** 9 *Map的遍历 10 * Set<K> keySet() 返回此映射中所包含的键的 Set 视图。 11 * Set<Map.Entry<K,V>> entrySet() 返回此映射所包含的映射关系的 Set 视图。 12 * public static interface Map.Entry<K,V>映射项(键-值对)。Map.entrySet 方法返回映射的 collection 视图,其中的元素属于此类 13 */ 14 public class TestHashMap2 { 15 public static void main(String[] args) { 16 HashMap<String,String> map = new HashMap<String,String>(); 17 map.put("jack", "成龙");//向容器中添加键值对 18 map.put("jay", "周杰伦"); 19 map.put("eason", "陈奕迅"); 20 map.put("jack", "杰克");//如果键重复就会发生覆盖 21 System.out.println(map); 22 System.out.println("********************************"); 23 //从Map中取键值对的方式1:从Map中取出keySet[键的集合] 24 Set<String> keySet = map.keySet(); 25 for (String key : keySet) { 26 String name = map.get(key); 27 System.out.println(key+"---"+name); 28 } 29 System.out.println("******************************"); 30 //方式2:从Map中取出Set[存放Entry<String,String>键值对的集合的集合] 31 //注释:Entry<String,String>:是对Map.Entry元素键、值的泛型;Set<Map.Entry<String,String>>:是对Set集合元素Map.Entry的泛型 32 Set<Map.Entry<String,String>> entrySet = map.entrySet(); 33 for (Entry<String, String> entry : entrySet) { 34 String key = entry.getKey(); 35 String value = entry.getValue(); 36 System.out.println(key+"===="+value); 37 } 38 System.out.println("***********************************"); 39 //方式3: 40 for(Iterator<Map.Entry<String,String>> iterator = map.entrySet().iterator();iterator.hasNext();) { 41 Entry<String,String> entry = iterator.next(); 42 System.out.println(entry.getKey()+"******"+entry.getValue()); 43 } 44 } 45 }
Hashtable的应用:
1 package cn.zzsxt.map_hashmap; 2 3 import java.util.HashMap; 4 import java.util.Hashtable; 5 /** 6 * 位于java.util.Hashtable包中 7 *Hashtable: 8 * 与HashMap的区别: 9 * 1.HashMap是非线程安全的、Hashtable是线程安全的; 10 * 2.HashMap允许键和值都为null,如果出现重复的key值,将会发生覆盖。 11 * 而Hashtable中的key和value都不能为null否则会出现NullPointerException(空指针异常) 12 * 13 */ 14 public class TestHashtable { 15 public static void main(String[] args) { 16 HashMap<String,String> map = new HashMap<String,String>(); 17 map.put(null, "成龙");//向容器中添加键值对 18 map.put("jay", null); 19 map.put("eason", "陈奕迅"); 20 map.put(null, "杰克");//如果键重复就会发生覆盖 21 System.out.println(map); 22 System.out.println("**************************"); 23 Hashtable<String,String> table = new Hashtable<String,String>(); 24 table.put(null, "成龙");//向容器中添加键值对 25 table.put("jay", null); 26 table.put("eason", "陈奕迅"); 27 table.put(null, "杰克");//如果键重复就会发生覆盖 28 System.out.println(table); 29 } 30 }
LinkedHashMap类似于LinkedHashSet:
应用:
1 package cn.zzsxt.map_hashmap; 2 3 import java.util.Iterator; 4 import java.util.LinkedHashMap; 5 import java.util.Map; 6 import java.util.Map.Entry; 7 import java.util.Set; 8 /** 9 *LinkedHashMap:是用哈希表+链表实现的 10 *常用的方法同HashMap相同。 区别是有序(添加顺序) 11 * 常用的构造方法: 12 * LinkedHashMap()构造一个带默认初始容量 (16) 和加载因子 (0.75) 的空插入顺序 LinkedHashMap 实例 13 * LinkedHashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空插入顺序 LinkedHashMap 实例。 14 * 常用的方法: 15 * put(K key, V value)在此映射中关联指定值与指定键。 16 * get(Object key) 返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。 17 * size() 返回此映射中的键-值映射关系数。 18 * remove(Object key) 从此映射中移除指定键的映射关系(如果存在)。 19 * clear() 从此映射中移除所有映射关系。 20 * containsKey(Object key) 如果此映射包含对于指定键的映射关系,则返回 true。 21 * containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。 22 * Set<K> keySet() 返回此映射中所包含的键的 Set 视图。 23 * Set<Map.Entry<K,V>> entrySet() 返回此映射所包含的映射关系的 Set 视图。 24 * 25 */ 26 public class TestLinkedHashMap { 27 public static void main(String[] args) { 28 LinkedHashMap<String,String> map = new LinkedHashMap<String,String>(); 29 map.put("jack", "成龙");//向容器中添加键值对 30 map.put("jay", "周杰伦"); 31 map.put("eason", "陈奕迅"); 32 //遍历的方式1:获取键的集合、 33 Set<String> keySet = map.keySet(); 34 for (String key : keySet) { 35 String value = map.get(key); 36 System.out.println(key+"---"+value); 37 } 38 System.out.println("****************************************"); 39 //获取键值对的集合EntrySet 40 Set<Map.Entry<String, String>> entrySet = map.entrySet(); 41 for (Entry<String, String> entry : entrySet) { 42 String key = entry.getKey(); 43 String value = entry.getValue(); 44 System.out.println(key+"==="+value); 45 } 46 System.out.println("****************************************"); 47 //方式3.通过取得键值对集合的迭代器迭代键值对对象 48 for(Iterator<Map.Entry<String,String>> iterator = map.entrySet().iterator();iterator.hasNext();) { 49 Entry<String,String> entryset = iterator.next(); 50 System.out.println(entryset.getKey()+"*****"+entryset.getValue()); 51 } 52 } 53 }
TreeMap类似于TreeSet:
应用1:
1 package cn.zzsxt.map_treemap; 2 3 public class Student implements Comparable<Student>{ 4 private String name; 5 private int age; 6 public Student() { 7 super(); 8 // TODO Auto-generated constructor stub 9 } 10 public Student(String name, int age) { 11 super(); 12 this.name = name; 13 this.age = age; 14 } 15 public String getName() { 16 return name; 17 } 18 public void setName(String name) { 19 this.name = name; 20 } 21 public int getAge() { 22 return age; 23 } 24 public void setAge(int age) { 25 this.age = age; 26 } 27 @Override 28 public String toString() { 29 return "[name=" + name + ", age=" + age + "]"; 30 } 31 @Override 32 public int compareTo(Student o) { 33 return name.length()-o.name.length(); 34 } 35 36 37 } 38 39 ============================================ 40 package cn.zzsxt.map_treemap; 41 42 import java.util.TreeMap; 43 44 public class TestTreeMap { 45 public static void main(String[] args) { 46 TreeMap<String,String> map = new TreeMap<String,String>(); 47 map.put("a", "aaa"); 48 map.put("b", "bbb"); 49 map.put("c", "ccc"); 50 System.out.println(map); 51 System.out.println("********************"); 52 TreeMap<String,Student> map2 = new TreeMap<String,Student>(); 53 Student stu1 = new Student("zhangsan",28); 54 Student stu2 = new Student("lisi",23); 55 Student stu3 = new Student("wangwu",20); 56 map2.put("zhangsan", stu1); 57 map2.put("lisi", stu2); 58 map2.put("wangwu", stu3); 59 System.out.println(map2); 60 System.out.println("*********************"); 61 TreeMap<Student,String> map3 = new TreeMap<Student,String>(); 62 Student stu4 = new Student("zhangsan",28); 63 Student stu5 = new Student("lisi",23); 64 Student stu6 = new Student("wangwu",20); 65 map3.put(stu2,"lisi"); 66 map3.put(stu1,"zhangsan"); 67 map3.put(stu3,"wangwu"); 68 System.out.println(map3); 69 } 70 }
TreeMap的应用2:
1 package cn.zzsxt.map_treemap; 2 3 import java.util.Comparator; 4 5 public class AgeComparator implements Comparator<Student> { 6 7 @Override 8 public int compare(Student o1, Student o2) { 9 return -(o1.getAge()-o2.getAge()); 10 } 11 12 } 13 14 ============================================ 15 package cn.zzsxt.map_treemap; 16 17 public class Student implements Comparable<Student>{ 18 private String name; 19 private int age; 20 public Student() { 21 super(); 22 // TODO Auto-generated constructor stub 23 } 24 public Student(String name, int age) { 25 super(); 26 this.name = name; 27 this.age = age; 28 } 29 public String getName() { 30 return name; 31 } 32 public void setName(String name) { 33 this.name = name; 34 } 35 public int getAge() { 36 return age; 37 } 38 public void setAge(int age) { 39 this.age = age; 40 } 41 @Override 42 public String toString() { 43 return "[name=" + name + ", age=" + age + "]"; 44 } 45 @Override 46 public int compareTo(Student o) { 47 return name.length()-o.name.length(); 48 } 49 50 51 } 52 53 ============================================ 54 package cn.zzsxt.map_treemap; 55 56 import java.util.TreeMap; 57 /** 58 *TreeMap:类似于TreeSet,采用二叉树的方式存储数据,有序(大小顺序)。 59 *常用的构造函数: 60 *TreeMap() 使用键的自然顺序构造一个新的、空的树映射。 插入该映射的所有键都必须实现 Comparable 接口. 61 *TreeMap(Comparator<? super K> comparator) 构造一个新的、空的树映射,该映射根据给定比较器进行排序。 62 */ 63 public class TestTreeMap2 { 64 public static void main(String[] args) { 65 /** 66 * 按照key的自然顺序进行摆放的 67 */ 68 TreeMap<String,Student> map2 = new TreeMap<String,Student>(); 69 Student stu1 = new Student("zhangsan",28); 70 Student stu2 = new Student("lisi",23); 71 Student stu3 = new Student("wangwu",20); 72 map2.put("zhangsan", stu1); 73 map2.put("lisi", stu2); 74 map2.put("wangwu", stu3); 75 System.out.println(map2); 76 System.out.println("************************************************************"); 77 /** 78 * 按照指定的比较器规定的规则进行摆放的 79 */ 80 TreeMap<Student,String> map3 = new TreeMap<Student,String>(new AgeComparator()); 81 Student stu4 = new Student("zhangsan",28); 82 Student stu5 = new Student("lisi",23); 83 Student stu6 = new Student("wangwu",20); 84 map3.put(stu2,"lisi"); 85 map3.put(stu1,"zhangsan"); 86 map3.put(stu3,"wangwu"); 87 System.out.println(map3); 88 } 89 }
以上是关于java之容器(集合)的主要内容,如果未能解决你的问题,请参考以下文章