Yolov5部署训练及代码解读
Posted 南栀北辰SDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolov5部署训练及代码解读相关的知识,希望对你有一定的参考价值。
5.Yolov5实操训练(重点)
一、前言
1.集成的资源,包括我自己做成的成品,可以直接train与detect。需要加qq群:938162384

2.本文目的主要是能够让读者复现,直接使用,而且少讲原理。如果想深入了解yolov5的原理,可以去看热度比较高的博主做的
3.如果是制作自己的数据集,那么有一个自己给训练集打标签的过程,那么需要看第五、六部分;如果用公开的数据集,那么可跳过第五部分
4.本次大更新,采用2022.06.28版本,应该是v6.1,
二、学习内容
2020年6月25日,Ultralytics发布了YOLOV5 的第一个正式版本,其性能与YOLO V4不相伯仲,同样也是现今最先进的对象检测技术,并在推理速度上是目前最强,yolov5按大小分为四个模型yolov5s、yolov5m、yolov5l、yolov5x。
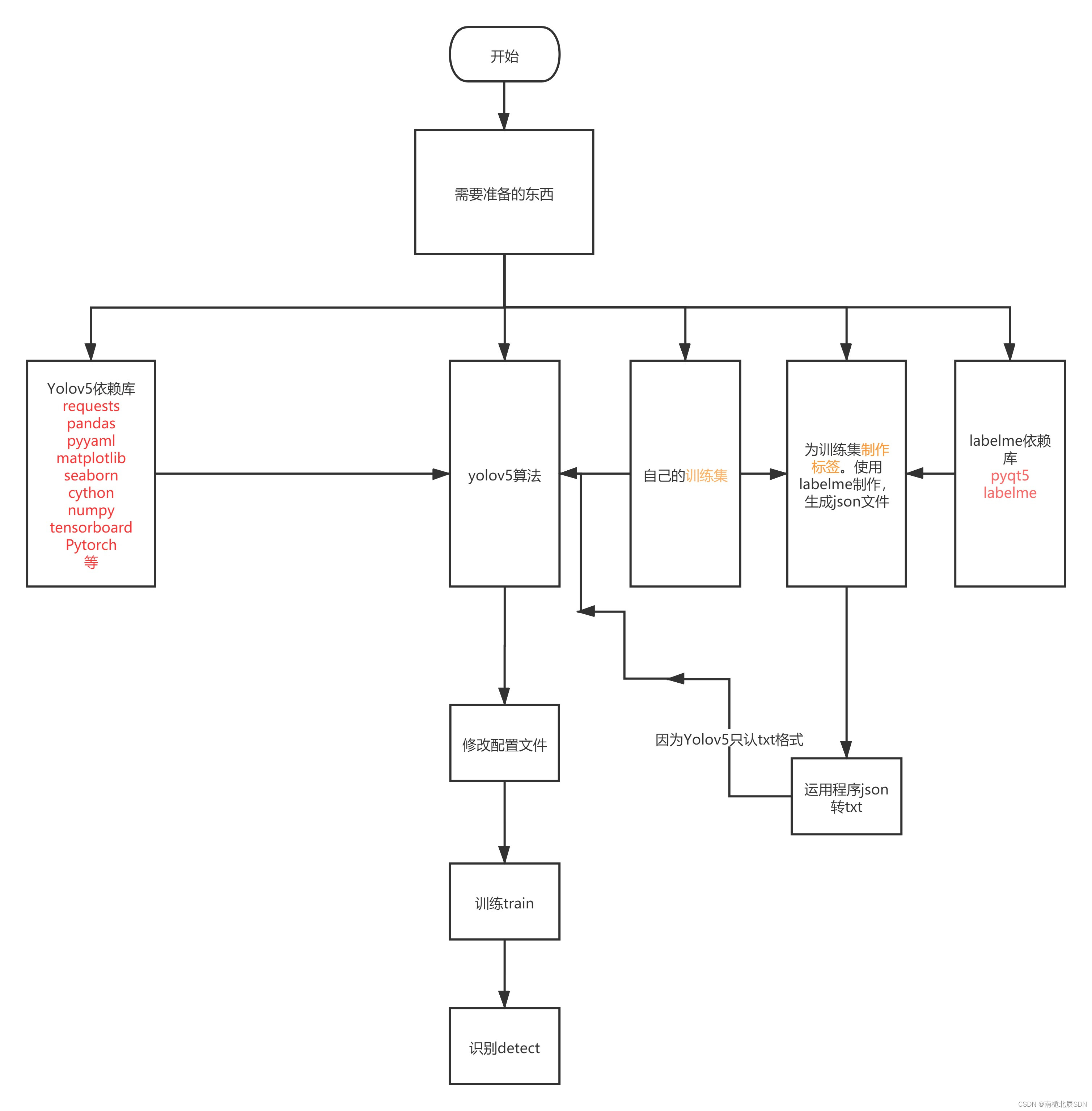
操作的流程图
三、版本与配置声明
# YOLOv5 requirements
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1 # Google Colab version
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
protobuf<4.21.3 # https://github.com/ultralytics/yolov5/issues/8012
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop # FLOPs computation
# albumentations>=1.0.3
# pycocotools>=2.0 # COCO mAP
# roboflow
四、Yolov5的准备
1.基本的Python环境配置
我采用的是Anaconda+Pycharm的配置,大家要了解一些关于pip的指令,方便管理包,这里就不赘述了。
2.下载Yolov5
https://github.com/ultralytics/yolov5,放在合理的位置,如果这个下的慢的话,通过qq群下载。
3.安装依赖库
当我们下好yolov5后,可以发现有一个requirements.txt文件,我们可以使用Anaconda Prompt(或者cmd或者pycharm的终端),执行下面一行代码(要requirements.txt所在文件夹下使用cmd等),即可一步到位全部下完。
pip install -r requirements.txt
这个过程下载很慢,可以进行pip加速,参考如下博客:
https://blog.csdn.net/zhengyuehai/article/details/124081661?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167807035016800188592370%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167807035016800188592370&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-124081661-null-null.142^v73^insert_down1,201^v4^add_ask,239^v2^insert_chatgpt&utm_term=pycharm%E7%BB%88%E7%AB%AF%E5%AE%89%E8%A3%85pip%E5%A4%AA%E6%85%A2&spm=1018.2226.3001.4187
大部分都能pip install 。重点说两个
(1)对于Pytorch,如果文件较大没有办法下完的话,可以用我下面的网址单独下载whl文件,
https://download.pytorch.org/whl/torch_stable.html
torch>=1.7.0
torchvision>=0.8.1

(2)对于wandb,wandb安装方法,这个好像不是必须的,但我还是下了,版本为0.12.19,刚好能兼容,作用就是对训练分析,如图所示
wandb安装方法:如果使用pip加速,直接安装就行不需要注册
pip install wandb
否则参考如下:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/116124285?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162791597216780265438950%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162791597216780265438950&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-8-116124285.first_rank_v2_pc_rank_v29&utm_term=wandb&spm=1018.2226.3001.4187
wandb实际上是非必须的,如果影响到了使用,那么在程序中可以把它禁止使用,不影响任何效果。在yolov5/utils/loggers/wandb/wandb_utils.py前面几行,加入如下图所示的第28行输入wandb=None


四、初步测试:detect.py
下载完yolov5后,什么都不用改,运行detect.py
这个是帮你检测能不能正常运行的
若正常:
在runs/detect/exp中能发现被处理过的标签,说明成功了!若程序报错,大概率是因为有的库版本不正确或者还未安装,这个自己调试一下即可,应该没有太大难度
五、训练集要求及路径要求
训练集至少100张起步才有效果。要想效果好,用公开的数据集,几千张才会有较好的效果。
训练集就是你需要train并用于detect的东西,我以玉米作为例子,你可以跟着我来一遍,资源在qq群。要做自己的训练集的话再看第五步。跟着我的话可以不用做标签,因为资源中已经做好了
如下图所示创建文件夹,让操作更清晰方便


images是图片,labels是标签,train的话是用于训练的,test就是用于测试的,这里一定一定要照着我的格式去建文件夹(seed_detection_model指训练的数据文件夹,这个可以改成你们的数据集的名字,但是其余的一定要一样),不然后面训练会出现找不到文件的报错
六、制作自己的数据集之制作标签
可采用labelme和labelimg,前者需要json标注格式转txt,后者需要xml标注格式转txt。我只用过前者,只给出前者的用法。
1.下载labelme
https://github.com/wkentaro/labelme,如果下载得慢的话见文末资源
2.安装依赖库
在pycharm终端里pip install pyqt5和pip install labelme
3.labelme操作
然后在pycharm终端里输入labelme,打开界面如下
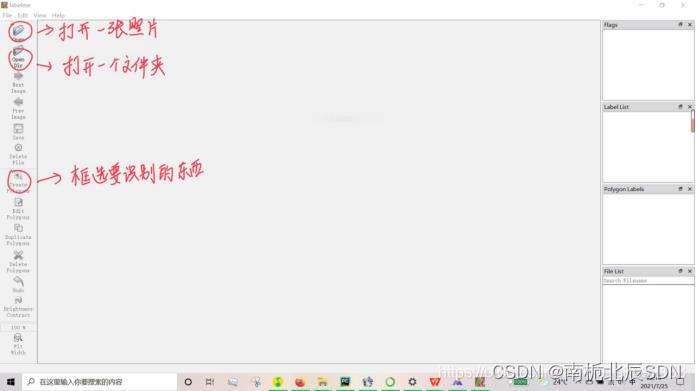
可以选择打开一个文件或者文件夹,如果是打开文件夹的话就会是下面那样子
右击,点击rectangle,即画矩形框,框选你要识别训练的东西,举种子识别的例子

框选之后输入标签的名字,注意,必须选择矩形框,否则json转txt会出错,可以框选多个作为标签。框选完一张图后保存,然后接着下一张图。保存的文件格式是.json
4.json转txt
由于yolov5只认txt而不认json,因此还要有一个转换的过程
在yolov5-master中创建一个.py文件,代码如下
import json
import os
name2id = 'corn': 0, 'soybean': 1 # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'C:\\\\Users\\\\17616\\\\Desktop\\\\txt\\\\' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\\n')
if __name__ == "__main__":
json_floder_path = 'C:\\\\Users\\\\17616\\\\Desktop\\\\json\\\\'
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)
建两个文件夹

转化完后大概会是这样子,如果一张图有多个标签的话,这个数据就会变多,
转换完的txt文件务必放在datasets/labels/train文件夹中

简单说明一下,第一个数字是数据集中第0个种类,其余均是与坐标相关的值,软件生成,可不用管。
5.xml转txt
如果使用别的打标签文件或者是原先已经打好的xml文件标签,那么我也给出相关的转换代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
# continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['People', 'Car', 'Bus', 'Motorcycle', 'Lamp', 'Truck']
# 2、voc格式的xml标签文件路径
xml_files1 = r'D:\\Technology\\Python_File\\yolov5\\M3FD\\Annotation_xml'
# xml_files1 = r'C:/Users/GuoQiang/Desktop/数据集/标签1'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'D:\\Technology\\Python_File\\yolov5\\M3FD\\Annotation_txt'
convert_annotation(xml_files1, save_txt_files1, classes)
七、修改配置文件
1.coco128.yaml->seed_detection_parameter.yaml
在yolov5/data/coco128.yaml中先复制一份,粘贴到Seed_detection_model文件夹中,改名为Seed_detection_model_parameter.yaml(意义为Seed_detection_model的参数配置)
Seed_detection_model_parameter.yaml(文件需要修改的参数是nc与names。nc是标签名个数,names就是标签的名字,检测目标例子中有2个标签[玉米,大豆],标签名字都如下。

说明:
path是绝对路径
train是在path绝对路径条件下的训练集路径,即:Seed_detection_model\\datasets\\images\\train
val同上,但是是验证集,这里我为了方便,让训练集和验证集是一个,也没啥大问题。
test可不填
关于训练集、验证集、测试集三者关系:
https://blog.csdn.net/nkwshuyi/article/details/94593053
nc是训练集中种类的个数,names是他们对应的名字,这个顺序不要混了,尤其是自己打标签时,会有对应的顺序的。
2.yolov5x.yaml->seed_detection_model.yaml
yolov5有4种配置,不同配置的特性如下,我这里选择yolov5x,效果较好,但是训练时间长,也比较吃显存
yolov5有4种配置,不同配置的特性如下,我这里选择yolov5x,效果较好,但是训练时间长,也比较吃显存
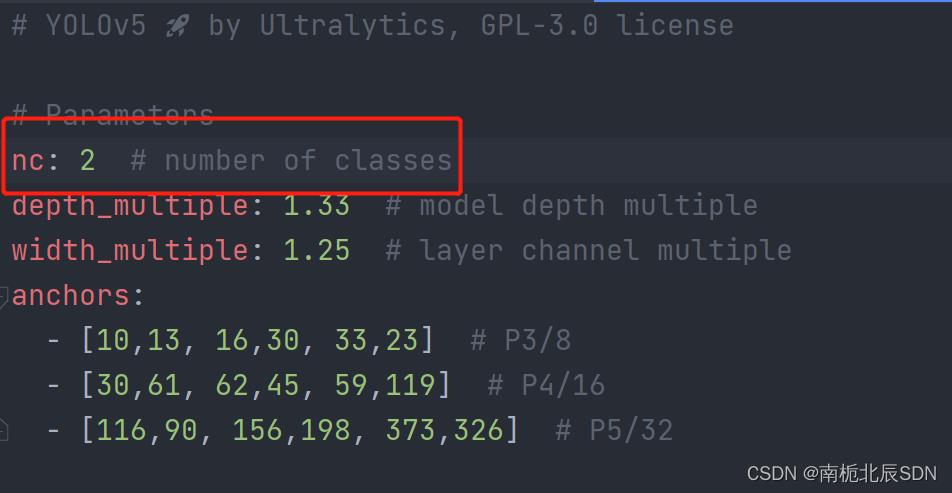
在yolov5/models先复制一份yolov5x.yaml至Seed_detection_model文件夹中,更名为seed_detection_model.yaml(意为模型),只将如下的nc修改为训练集种类即可
八、开始训练train
1.调参
在train.py,找到def parse_opt(known=False)这行,这下面是我们要修改的程序部分
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5x.pt', help='initial weights path') # 修改处 初始权重
parser.add_argument('--cfg', type=str, default=ROOT /'Seed_detection_model/Seed_detection_model.yaml', help='model.yaml path') # 修改处 训练模型文件
parser.add_argument('--data', type=str, default=ROOT /'Seed_detection_model/Seed_detection_parameter.yaml', help='dataset.yaml path') # 修改处 数据集参数文件
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') # 超参数设置
parser.add_argument('--epochs', type=int, default=100) # 修改处 训练轮数
parser.add_argument('--batch-size', type=int, default=10, help='total batch size for all GPUs, -1 for autobatch') # 修改处 batch size
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=300, help='train, val image size (pixels)')# 修改处 图片大小
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')#修改处,选择
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=4, help='max dataloader workers (per RANK in DDP mode)')#修改处
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
YOLOv5源码逐行超详细注释与解读——训练部分train.py