强化学习Q-Learning算法及实现详解
Posted rayylee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习Q-Learning算法及实现详解相关的知识,希望对你有一定的参考价值。
本教程通过一个简单但全面的示例介绍Q-learning的概念。 该示例描述了一个使用无监督学习的过程。
假设我们在一个建筑物中有5个房间,这些房间由门相连,如下图所示。 我们将每个房间编号为0到4。建筑物的外部可以视为一个大房间(5)。 请注意,1号和4号门从5号房间(外部)通向建筑物。
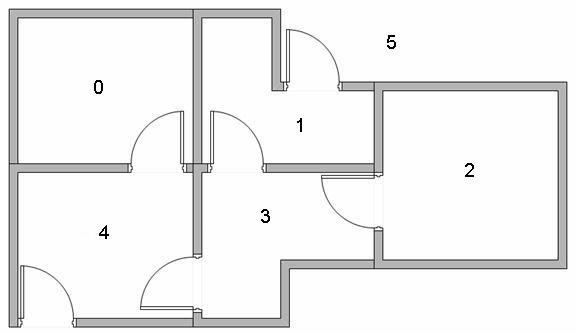
我们可以在图表上表示房间,每个房间作为节点,每个门作为链接。
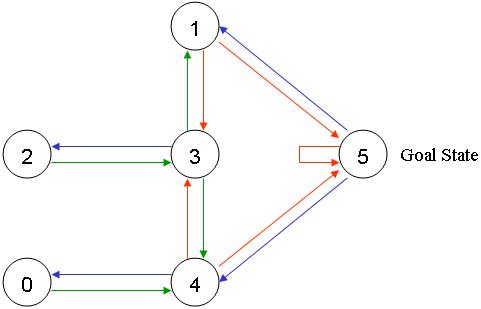
对于此示例,我们想在任何房间中放置一个门,然后从该房间进入建筑物外(这将是我们的目标房间)。换句话说,目标房间是5号。要将此房间设置为目标,我们会将奖励值关联到每个门(即节点之间的链接)。立即通向目标的门的即时奖励为100。未直接连接到目标房间的其他门的奖励为0。由于门是双向的,因此每个房间都有两个箭头。每个箭头都包含一个即时奖励值,如下所示:
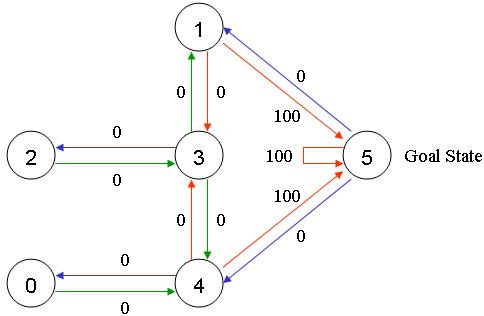
当然,房间5会以100的奖励返回自己,而与目标室的所有其他直接连接也会获得100的奖励。在Q-learning中,目标是达到最高奖励的状态,因此如果到达目标,它将停止。这种目标称为 “absorbing goal”。
想象一个可以从经验中学习的愚蠢的虚拟机器人。它可以从一个房间到另一个房间,但不了解环境,也不知道怎么走才能顺序通往外面。
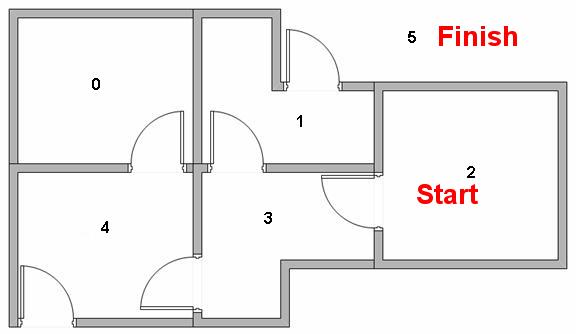
现在假设我们在2号房间有一个机器人,我们希望它能走到5(屋外)。
Q-learning中有两个术语"state" 、“action”。
我们将每个房间(包括外部房间)称为“state”,从一个房间到另一个房间的移动将称为“action”。在我们的图中,“action”被描述为一个节点,而“state”则由箭头表示。
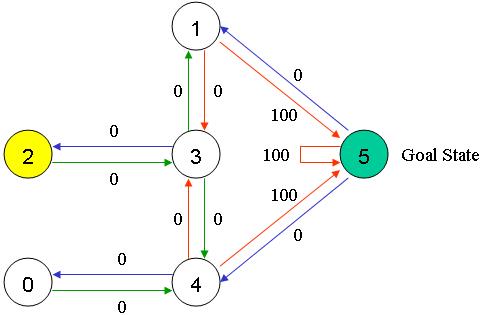
假设现在处于2,因为2已连接到3,所以它可以从2进入3。但是,由于没有直接的门连接房间1和2(因此,没有箭头)。从3开始,它可以进入1或4,也可以回到2(查看关于3的所有箭头)。如果处于4,则三个可能的动作是进入0、5或3。如果处于1,则它可以进入5或3。从0它只能进入4。
介绍两个概念:
- reward (当做出一个选择,环境给的回馈,这个是固定不变的,是先验信息)
- Q矩阵(和随机过程的Q矩阵稍有不同,相当于机器人的大脑,通过算法训练出来,再拿来做决策)
Q-learning算法:

根据算法初始化reward 矩阵R (根据上面的房间,-1表示不可以通过,0表示可以通过,100表示直接到达终点:
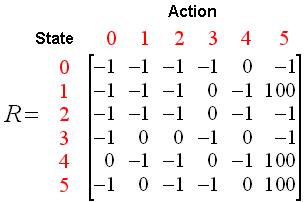
初始化一个与R同阶 的矩阵 Q(表示做出选择,可能在将来得到奖励的期望),初始化为0矩阵

Q阵的更新公式为:
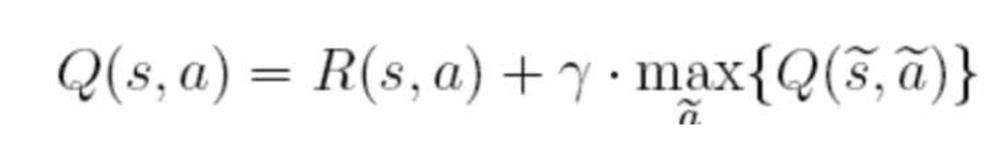
一般将贪婪因子\\gamma设置为0.8,Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作。
- 计算过程
随机选择一个状态,比如1,查看状态1所对应的R表,也就是1可以到达3或5,随机地,我们选择5,根据转移方程:
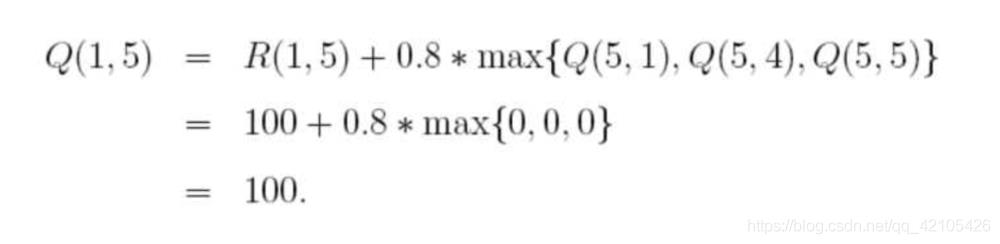
又随机选中了3状态 ,3对应的下一个状态有(1,2,4都是状态3对应的非负状态),随机地,我们选择1,这样根据算法更新:
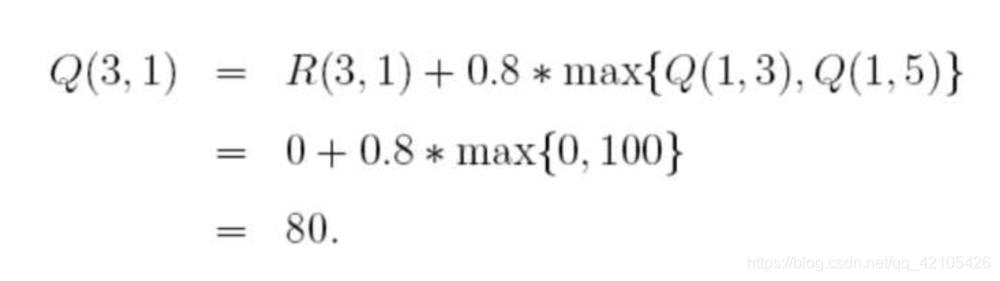
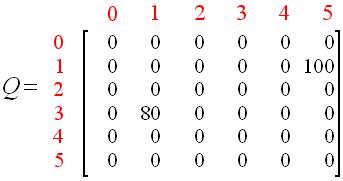
经过两次更新,Q阵变成了 :
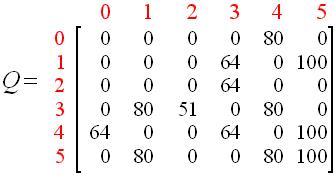
经过多次更新以后,然后进行归一化,Q阵变成了;
将Q阵转移到房间的抽象图上
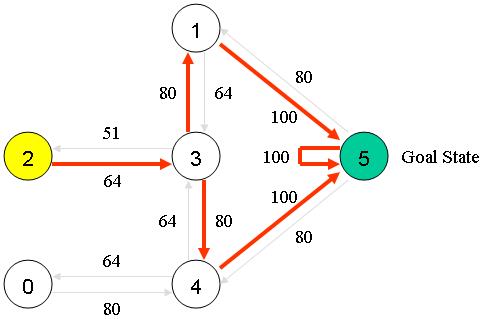
下面就可以使用Q矩阵来做出最优解了

在入口进入(2是入口),选择权值最大的路径,3 -> 1 -> 5
代码实现:
import numpy as np
# R matrix
R = np.matrix([ [-1,-1,-1,-1,0,-1],
[-1,-1,-1,0,-1,100],
[-1,-1,-1,0,-1,-1],
[-1,0,0,-1,0,-1],
[-1,0,0,-1,-1,100],
[-1,0,-1,-1,0,100] ])
# Q matrix
Q = np.matrix(np.zeros([6,6]))
# Gamma (learning parameter).
gamma = 0.8
# Initial state. (Usually to be chosen at random)
initial_state = 1
# This function returns all available actions in the state given as an argument
def available_actions(state):
current_state_row = R[state,]
av_act = np.where(current_state_row >= 0)[1]
return av_act
# Get available actions in the current state
available_act = available_actions(initial_state)
# This function chooses at random which action to be performed within the range
# of all the available actions.
def sample_next_action(available_actions_range):
next_action = int(np.random.choice(available_act,1))
return next_action
# Sample next action to be performed
action = sample_next_action(available_act)
# This function updates the Q matrix according to the path selected and the Q
# learning algorithm
def update(current_state, action, gamma):
max_index = np.where(Q[action,] == np.max(Q[action,]))[1]
if max_index.shape[0] > 1:
max_index = int(np.random.choice(max_index, size = 1))
else:
max_index = int(max_index)
max_value = Q[action, max_index]
# Q learning formula
Q[current_state, action] = R[current_state, action] + gamma * max_value
# Update Q matrix
update(initial_state,action,gamma)
#-------------------------------------------------------------------------------
# Training
# Train over 10 000 iterations. (Re-iterate the process above).
for i in range(10000):
current_state = np.random.randint(0, int(Q.shape[0]))
available_act = available_actions(current_state)
action = sample_next_action(available_act)
update(current_state,action,gamma)
# Normalize the "trained" Q matrix
print("Trained Q matrix:")
print(Q/np.max(Q)*100)
#-------------------------------------------------------------------------------
# Testing
# Goal state = 5
# Best sequence path starting from 2 -> 2, 3, 1, 5
current_state = 2
steps = [current_state]
while current_state != 5:
next_step_index = np.where(Q[current_state,] == np.max(Q[current_state,]))[1]
if next_step_index.shape[0] > 1:
next_step_index = int(np.random.choice(next_step_index, size = 1))
else:
next_step_index = int(next_step_index)
steps.append(next_step_index)
current_state = next_step_index
# Print selected sequence of steps
print("Selected path:")
print(steps)
参考:
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
https://blog.csdn.net/qq_42105426/article/details/88679907
https://zhuanlan.zhihu.com/p/36669905
以上是关于强化学习Q-Learning算法及实现详解的主要内容,如果未能解决你的问题,请参考以下文章
强化学习 5 —— SARSA 和 Q-Learning算法代码实现