开源分布式支持超大规模数据分析型数据仓库Apache Kylin实践-下
Posted IT小神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源分布式支持超大规模数据分析型数据仓库Apache Kylin实践-下相关的知识,希望对你有一定的参考价值。
文章目录
使用注意
连接条件限制
Kylin只能按照构建 Model 时使用的连接条件来使用,例如在前面创建 emp_model 时,对emp表和dept表选用的是 Inner Join 也即是内连接的方式,在使用 Kylin 查询的时候,也只能用 join 内连接,如果在使用 Kylin 查询时使用其他连接如左连接会报错。
select dept.dname,sum(emp.sal) from emp left join dept on emp.deptno = dept.deptno group by dept.dname;
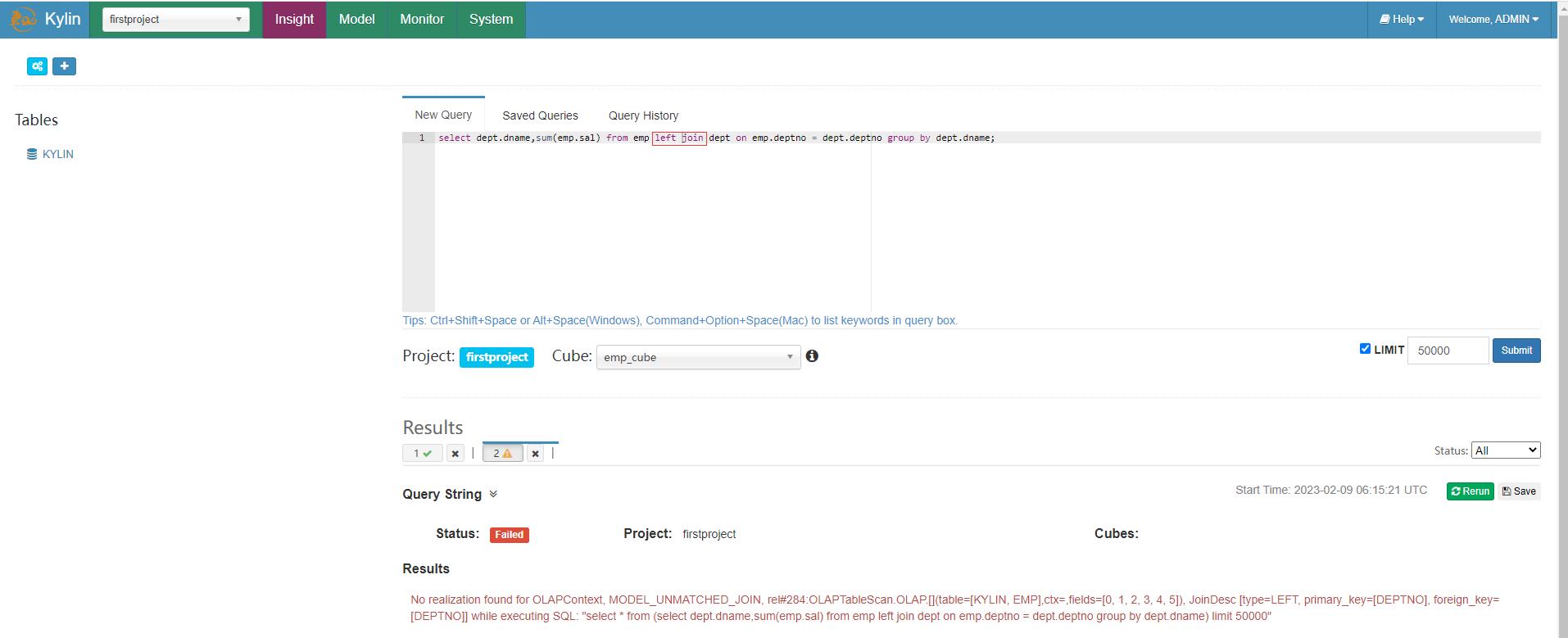
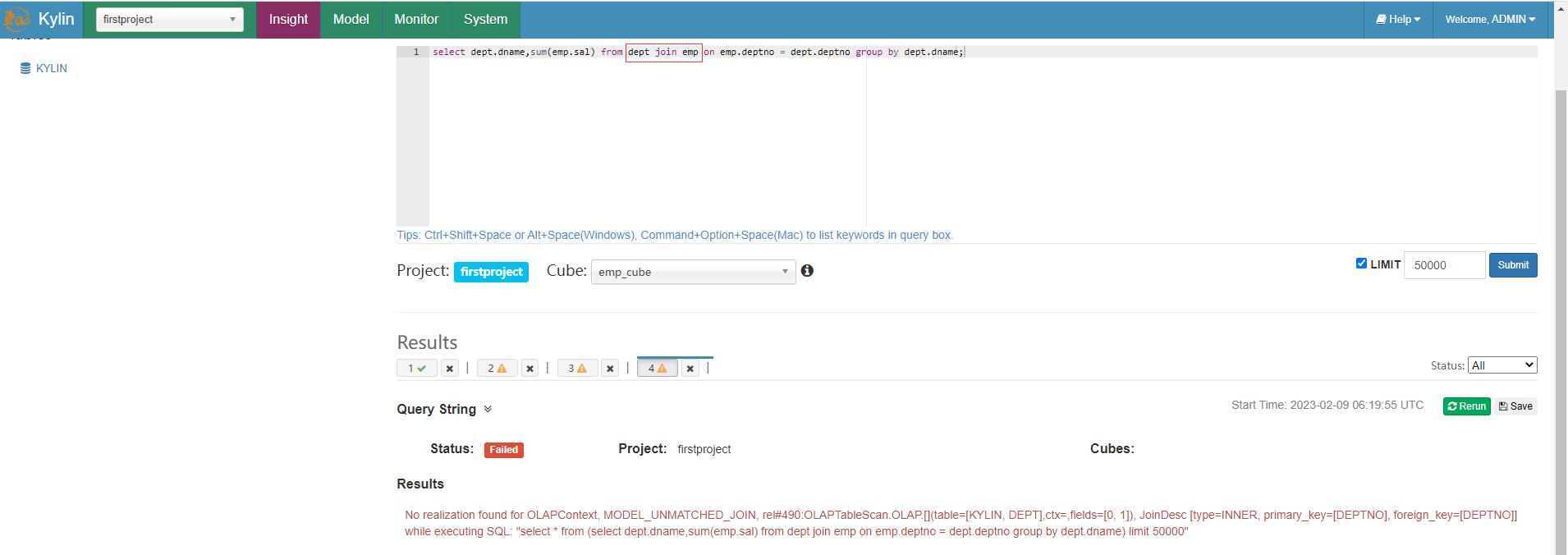
再查询语句中还要求事实表在前,维度表在后,否则也会报错,例如把dept部门维度表放在前面会报错。
select dept.dname,sum(emp.sal) from dept join emp on emp.deptno = dept.deptno group by dept.dname;
维度限制
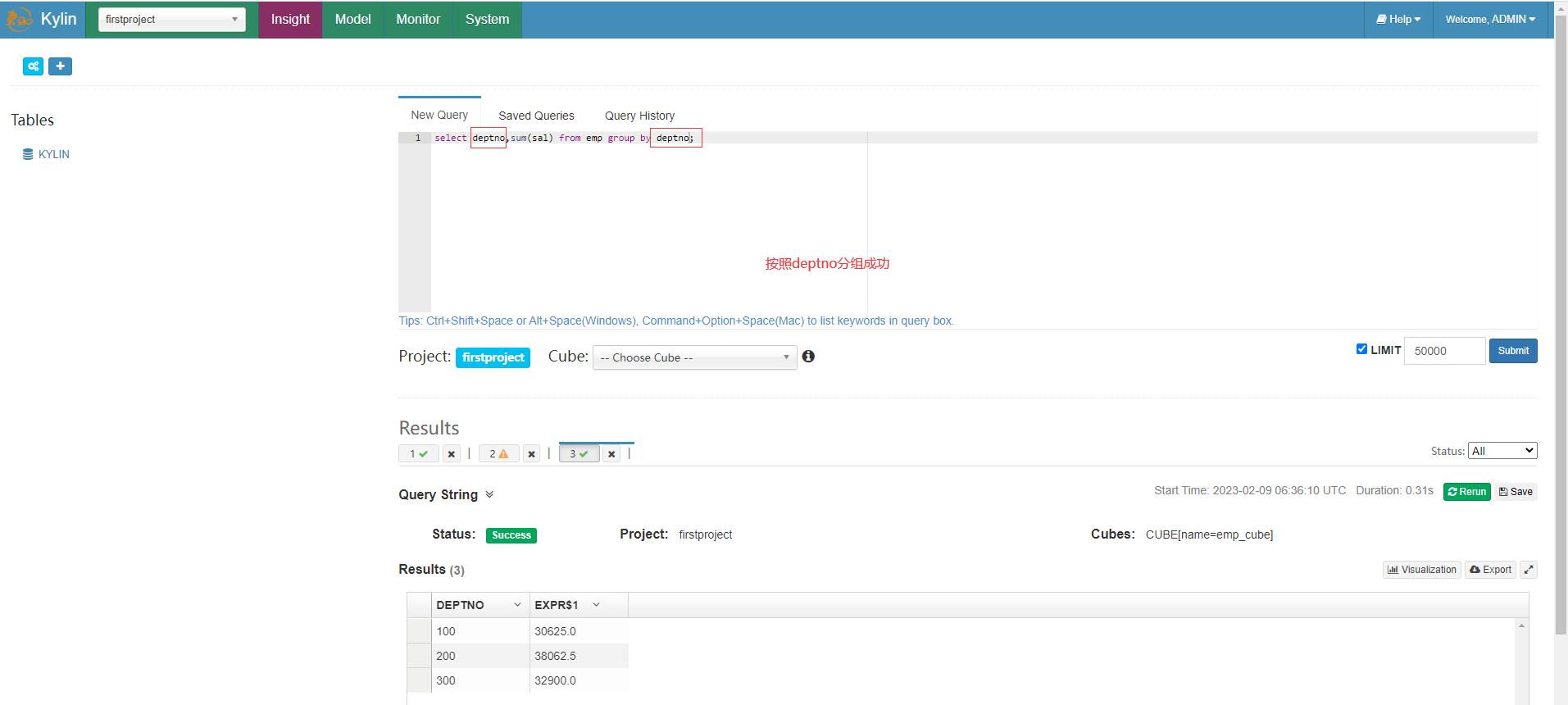
Kylin只能按照构建Cube时选择的维度字段分组统计,如果选择指定维度字段如deptno分组统计可以查询成功
select deptno,sum(sal) from emp group by deptno;
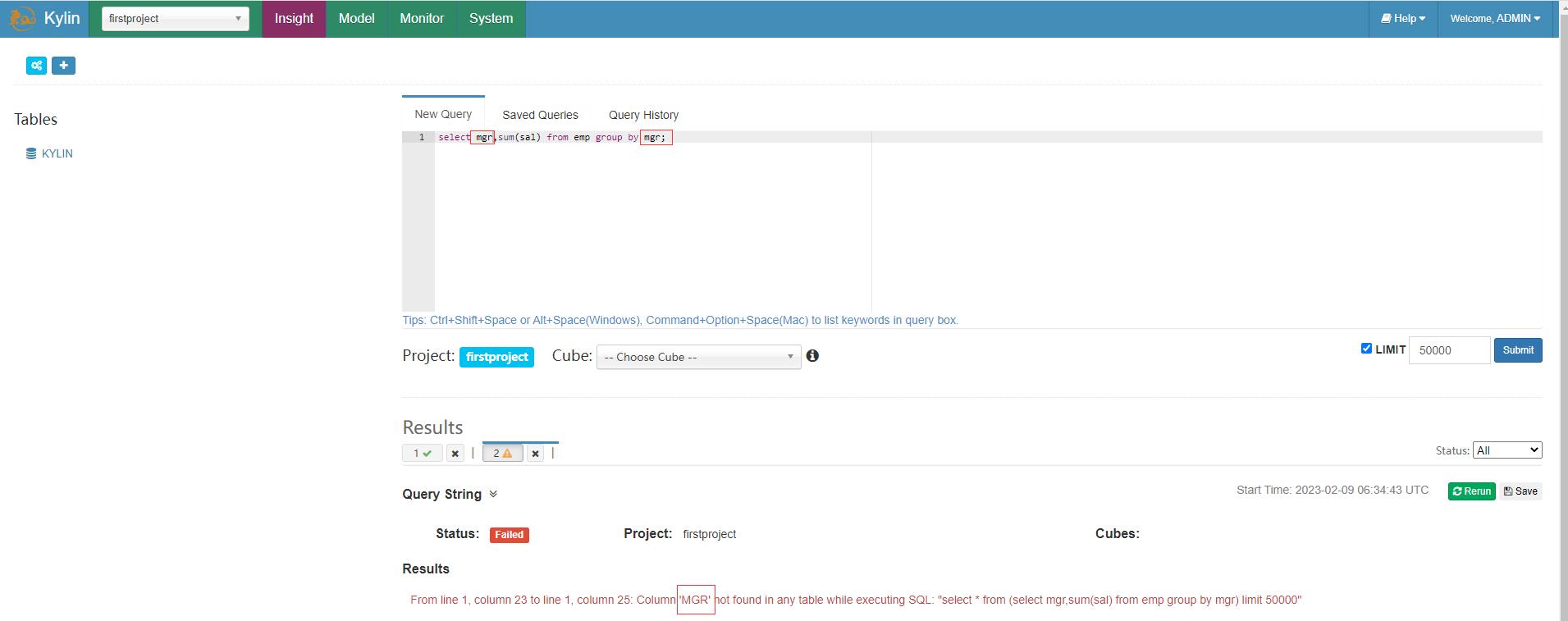
如果选择不在前面选择的mgr维度则查询会报错
select mgr,sum(sal) from emp group by mgr;
度量限制
Kylin只能统计构建 Cube 时选择的度量值字段,由于count在前面的度量配置里因此可以查询成功
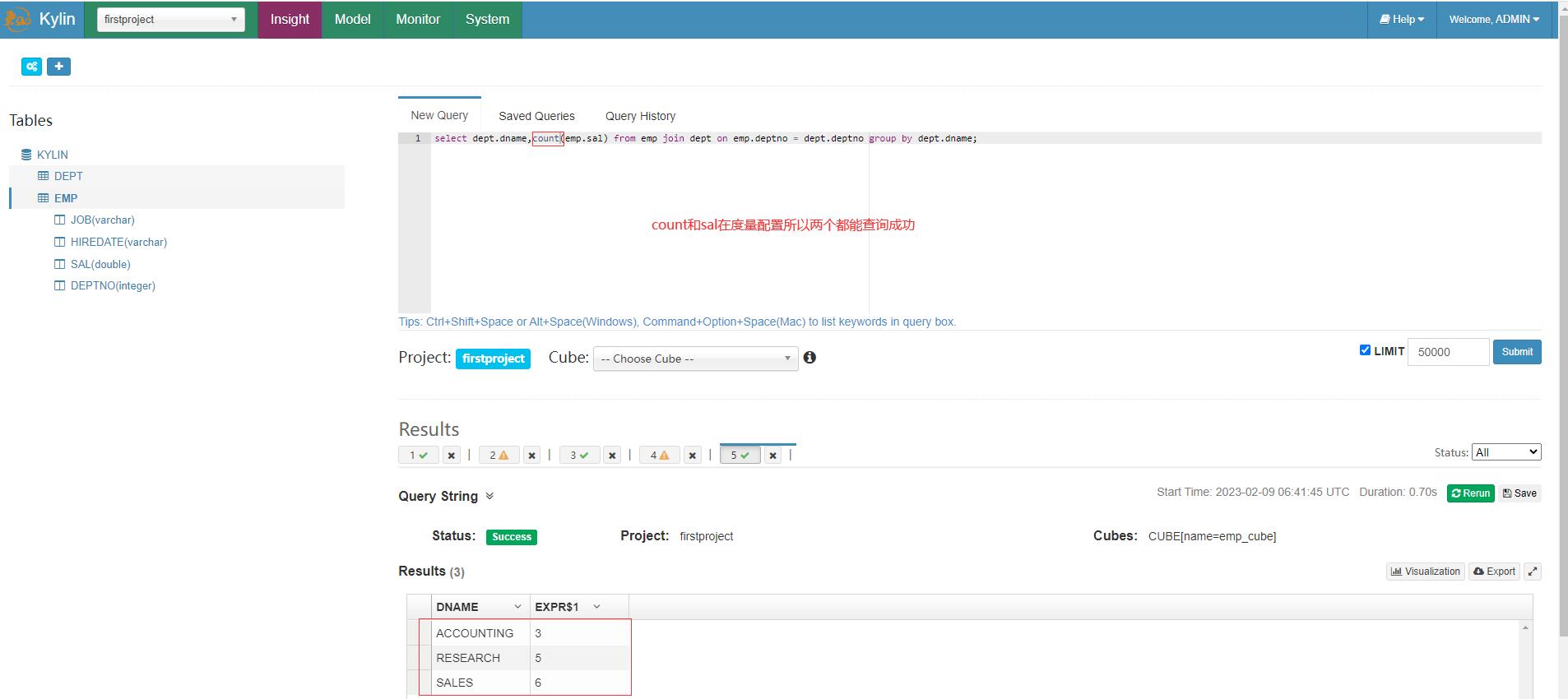
由于前面奖金comm字段没有放在度量里,因此查询报错
select dept.dname,sum(emp.comm) from emp join dept on emp.deptno = dept.deptno group by dept.dname;
查询引擎
Sparder
Sparder (SparderContext) 是由 Spark application 后端实现的新型分布式查询引擎,它是作为一个 Long-running 的 Spark application 存在的。Sparder 会根据 kylin.query.spark-conf 开头的配置项中配置的 Spark 参数来获取 Yarn 资源,如果配置的资源参数过大,可能会影响构建任务甚至无法成功启动 Sparder,如果 Sparder 没有成功启动,则所有查询任务都会失败,因此请在 Kylin 的 WebUI 中检查 Sparder 状态,不过默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
kylin.query.auto-sparder-context-enabled-enabled 参数用于控制是否在启动 kylin 的同时启动Sparder,默认值为 false,即默认情况下会在执行第一条 SQL 的时候才启动 Sparder,因此 Kylin 的第一条 SQL 查询速度一般比较慢,因为包含了 Sparder 任务的启动时间。
查看yarn可以看到有一个名称为sparder_on_xxxx的yarn应用

HDFS存储信息
根目录:/kylin/kylin_metadata
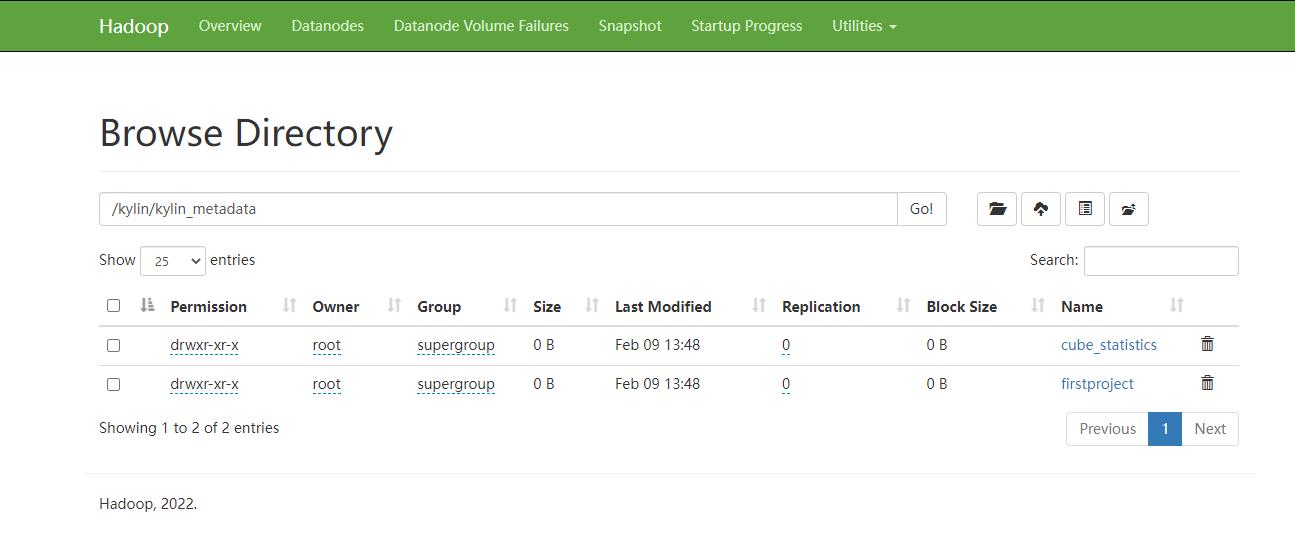
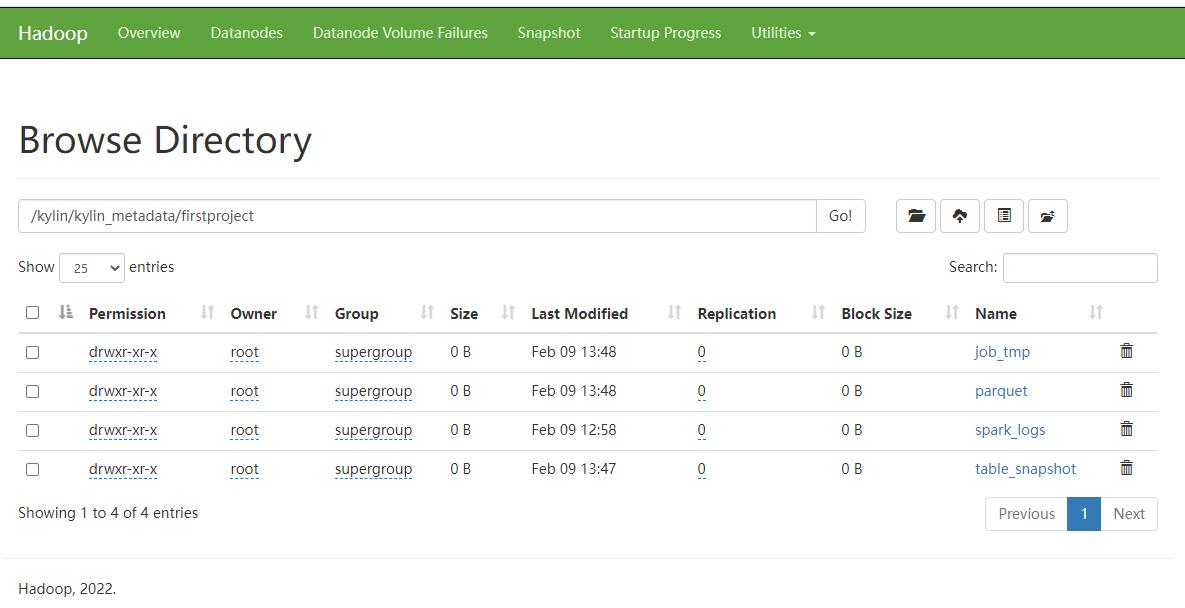
子目录:
- 临时文件存储目录:/project_name/job_tmp
- cuboid 文件存储目录: /project_name /parquet/cube_name/segment_name_XXX
- 维度表快照存储目录:/project_name /table_snapshot
- Spark 运行日志目录:/project_name/spark_logs
查询参数
Kylin 查询参数全部以 kylin.query.spark-conf 开头,默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
####spark 运行模式####
#kylin.query.spark-conf.spark.master=yarn
####spark driver 核心数####
#kylin.query.spark-conf.spark.driver.cores=1
####spark driver 运行内存####
#kylin.query.spark-conf.spark.driver.memory=4G
####spark driver 运行堆外内存####
#kylin.query.spark-conf.spark.driver.memoryOverhead=1G
####spark executor 核心数####
#kylin.query.spark-conf.spark.executor.cores=1
####spark executor 个数####
#kylin.query.spark-conf.spark.executor.instances=1
####spark executor 运行内存####
#kylin.query.spark-conf.spark.executor.memory=4G
####spark executor 运行堆外内存####
#kylin.query.spark-conf.spark.executor.memoryOverhead=1G
查询下压配置
对于没有cube能查到结果的,Kylin4.0版本支持这类查询下压到Spark SQL去查询hive源数据
- 将conf/kylin.properties配置文件中的注释放开
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.pushdown.PushDownRunnerSparkImpl
- 页面刷新配置
- 查询页面执行cube中没有的维度而报错的sql,可以看到这是已经将查询下压Spark去执行,结果也正确返回
select mgr,sum(sal) from emp group by mgr;
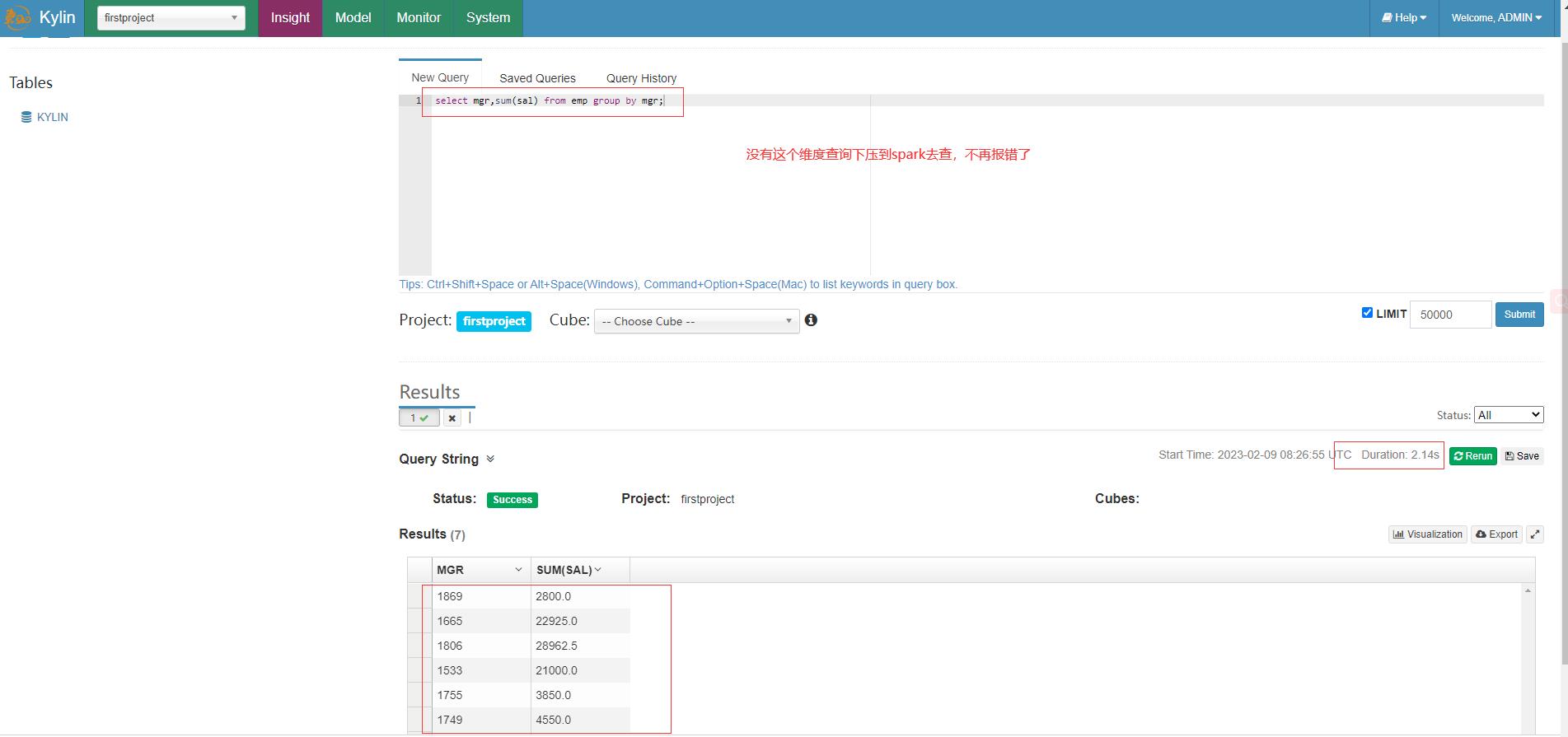
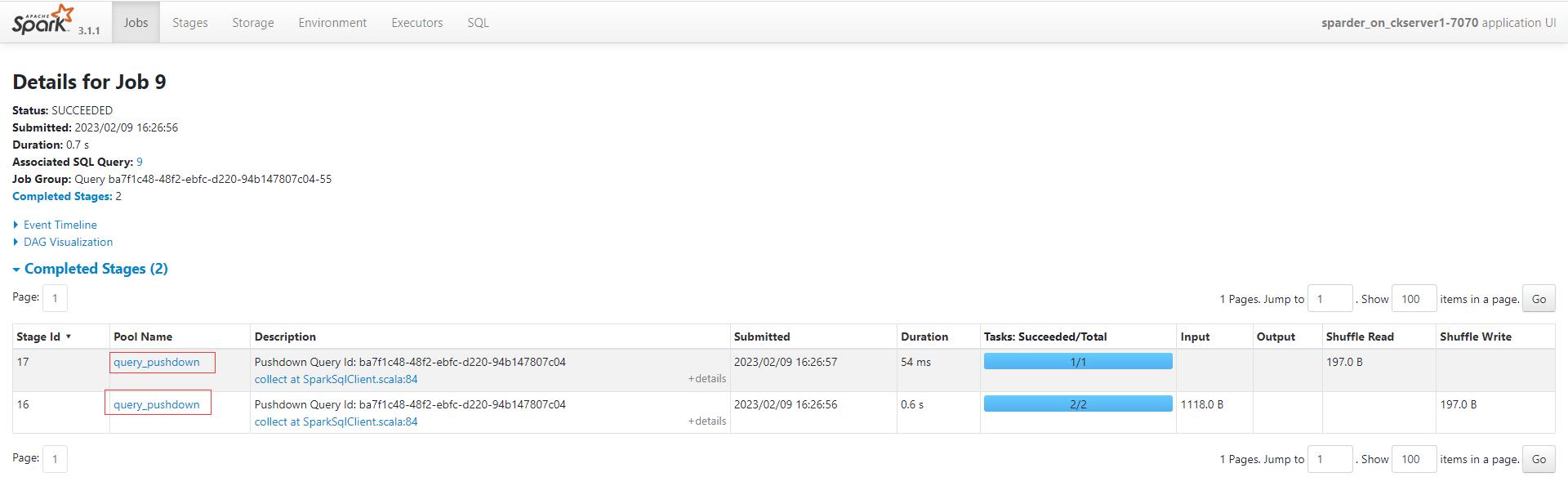
从spark WebUI也可以看到刚刚查询下压的Job和Stage的详细信息
Cube 构建优化
使用衍生维度(derived dimension)
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin 会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。

虽然衍生维度具有非常大的吸引力,但这也并不是说所有维度表上的维度都得变成衍生维度,如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,则不建议使用衍生维度。
使用聚合组(Aggregation group)
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个 Cube 的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube 所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的 Cuboid,所有分组贡献的 Cuboid 的并集就成为了当前 Cube 中所有需要物化的 Cuboid的集合。不同的分组有可能会贡献出相同的 Cuboid,构建引擎会察觉到这点,并且保证每一 个 Cuboid 无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下。
- 强制维度(Mandatory),如果一个维度被定义为强制维度,那么这个分组产生的所有 Cuboid 中每一个 Cuboid 都会包含该维度。每个分组中都可以有 0 个、1 个或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度。(强制维度自己也不能单独出现)
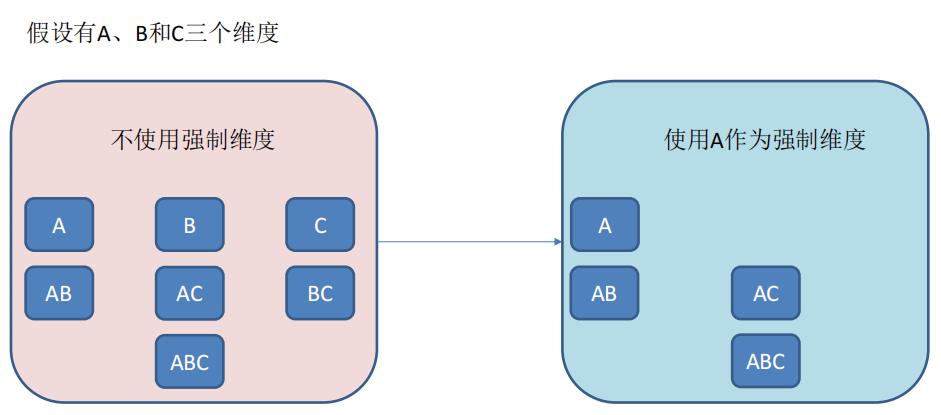
- 层级维度(Hierarchy),每个层级包含两个或更多个维度。假设一个层级中包含 D1,D2…Dn 这 n 个维度,那么在该分组产生的任何 Cuboid 中,这 n 个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这 n+1 种形式中的一种出现。每个分组中可以有 0 个、1 个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。
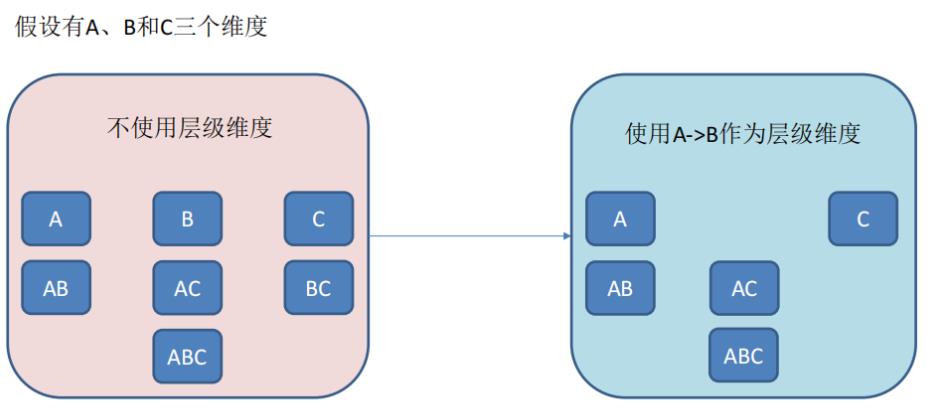
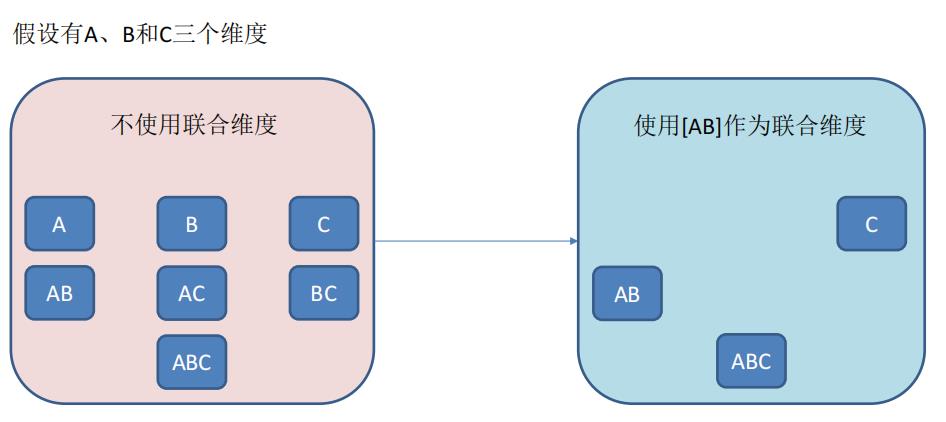
- 联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何 Cuboid 中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有 0 个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。
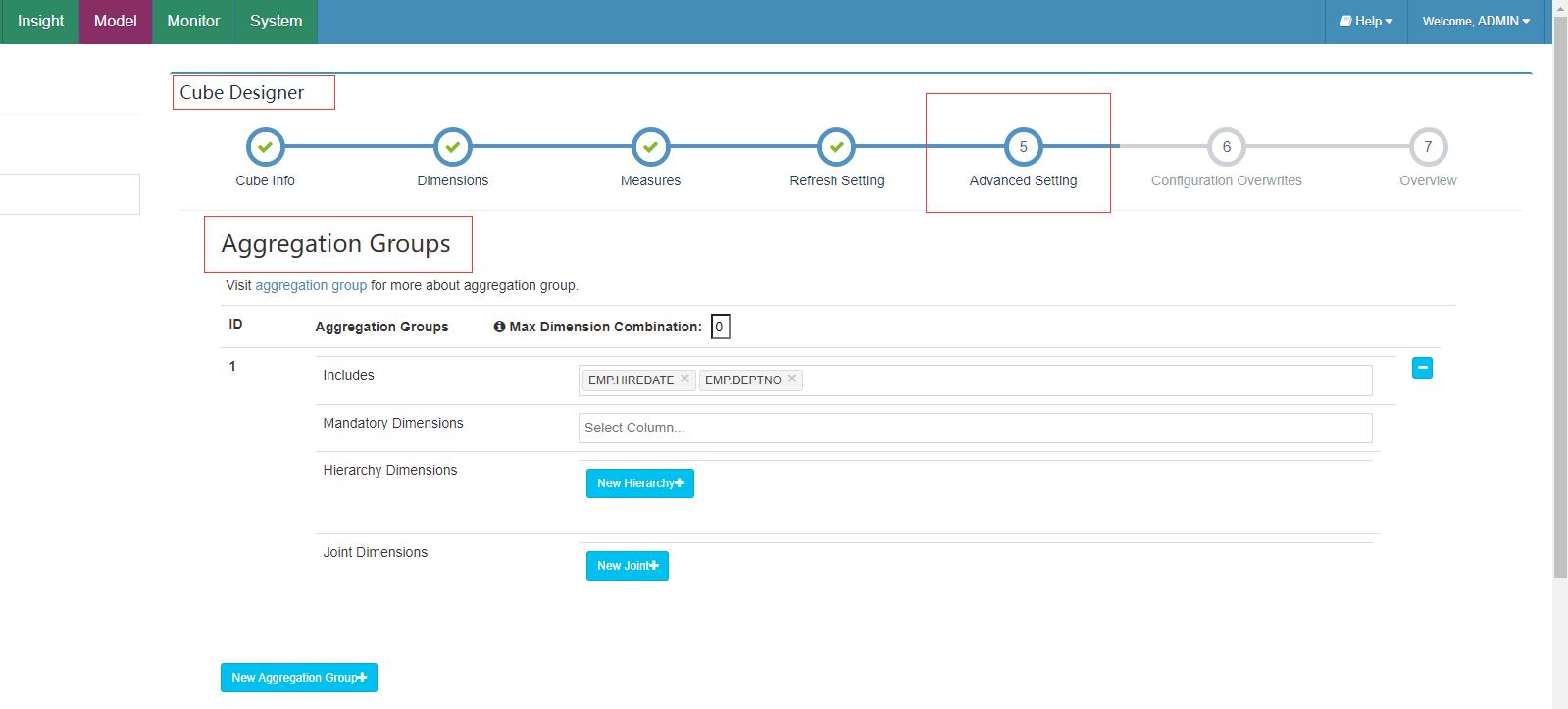
上述的聚合组可以在新建cube中Cube Designer 的 Advanced Setting 中的 Aggregation Groups 区域配置。
- 聚合组的设计非常灵活,甚至可以用来描述一些极端的设计。假设我们的业务需求非常单一,只需要某些特定的 Cuboid,那么可以创建多个聚合组,每个聚合组代表一个 Cuboid。
- 具体的方法是在聚合组中先包含某个 Cuboid 所需的所有维度,然后把这些维度都设置为强制维度。这样当前的聚合组就只能产生我们想要的那一个 Cuboid 了。
- 再比如,有的时候我们的 Cube 中有一些基数非常大的维度,如果不做特殊处理,它就会和其他的维度进行各种组合,从而产生一大堆包含它的 Cuboid。包含高基数维度的 Cuboid在行数和体积上往往非常庞大,这会导致整个 Cube 的膨胀率变大。如果根据业务需求知道这个高基数的维度只会与若干个维度(而不是所有维度)同时被查询到,那么就可以通过聚合组对这个高基数维度做一定的“隔离”。我们把这个高基数的维度放入一个单独的聚合组,
再把所有可能会与这个高基数维度一起被查询到的其他维度也放进来。这样,这个高基数的维度就被“隔离”在一个聚合组中了,所有不会与它一起被查询到的维度都没有和它一起出现在任何一个分组中,因此也就不会有多余的 Cuboid 产生。这点也大大减少了包含该高基数维度的 Cuboid 的数量,可以有效地控制 Cube 的膨胀率。
Row Key 优化
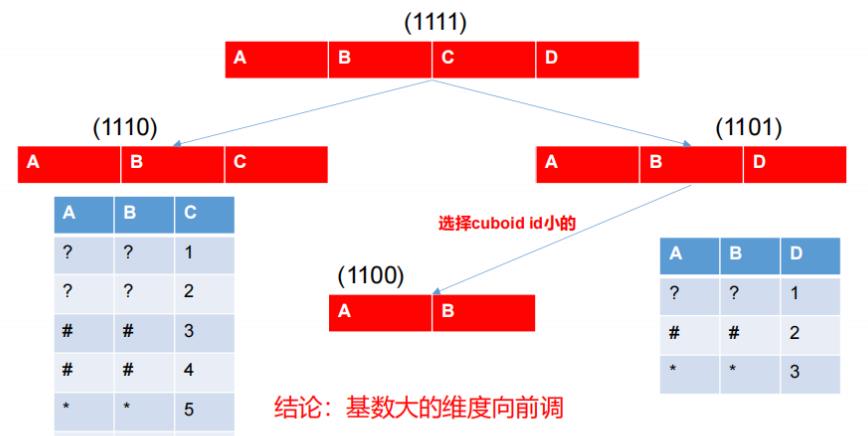
Kylin 会把所有的维度按照顺序组合成一个完整的 Rowkey,并且按照这个 Rowkey 升序排列 Cuboid 中所有的行。维度的位置(Rowkey)对查询性能有影响,可以调整顺序。将过滤维放在非过滤维之前,将高基数维放在低基数维之前。
-
设计良好的 Rowkey 将更有效地完成数据的查询过滤和定位,减少 IO 次数,提高查询速度,维度在 rowkey 中的次序,对查询性能有显著的影响。
Row key 的设计原则如下:- 被用作过滤的维度放在前边。

- 基数大的维度放在基数小的维度前边。
RestAPI使用
身份认证
官方RestAPI使用 https://kylin.apache.org/docs/howto/howto_use_restapi.html
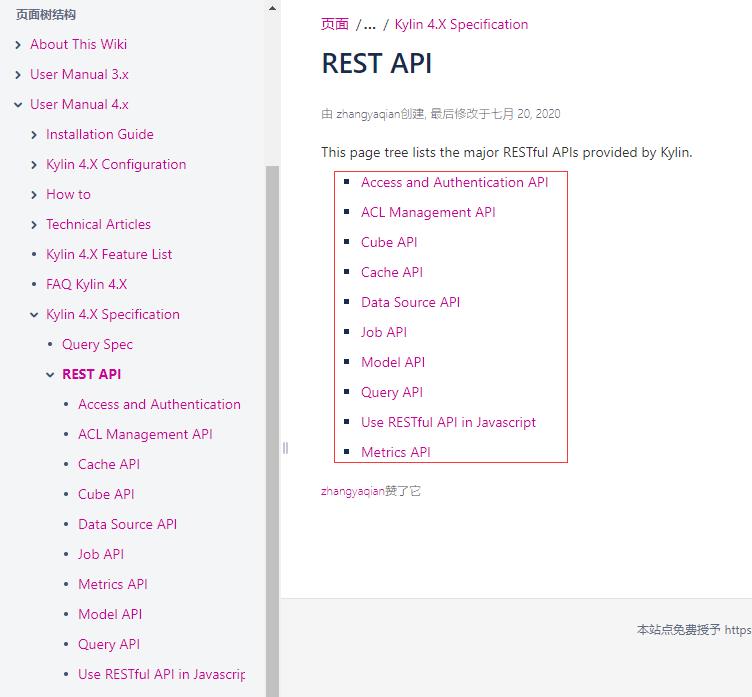
进入Access and Authentication API 访问和身份验证API,头文件中需要使用基本认证编码的授权数据,例如可以使用下面的python脚本生成data
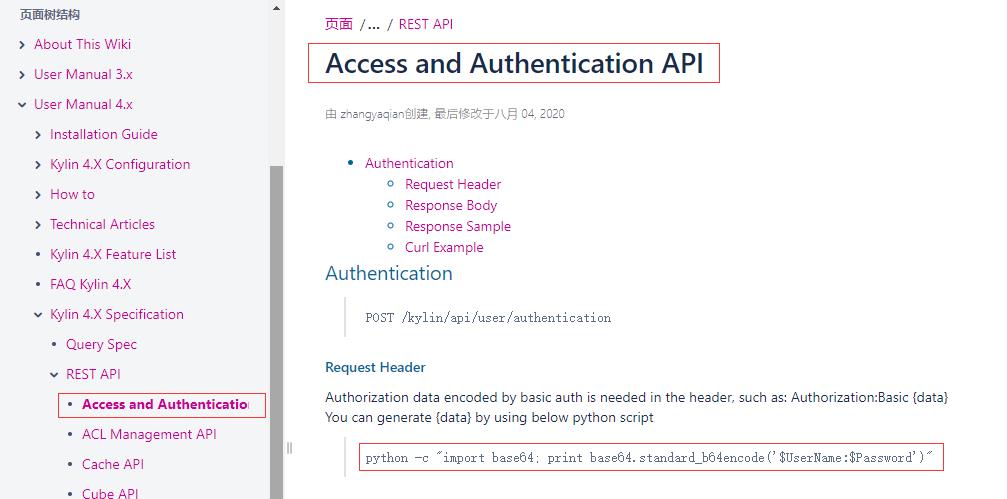
python -c "import base64; print base64.standard_b64encode('ADMIN:KYLIN')"

查询
进入Query API后找到Curl Example的实例代码
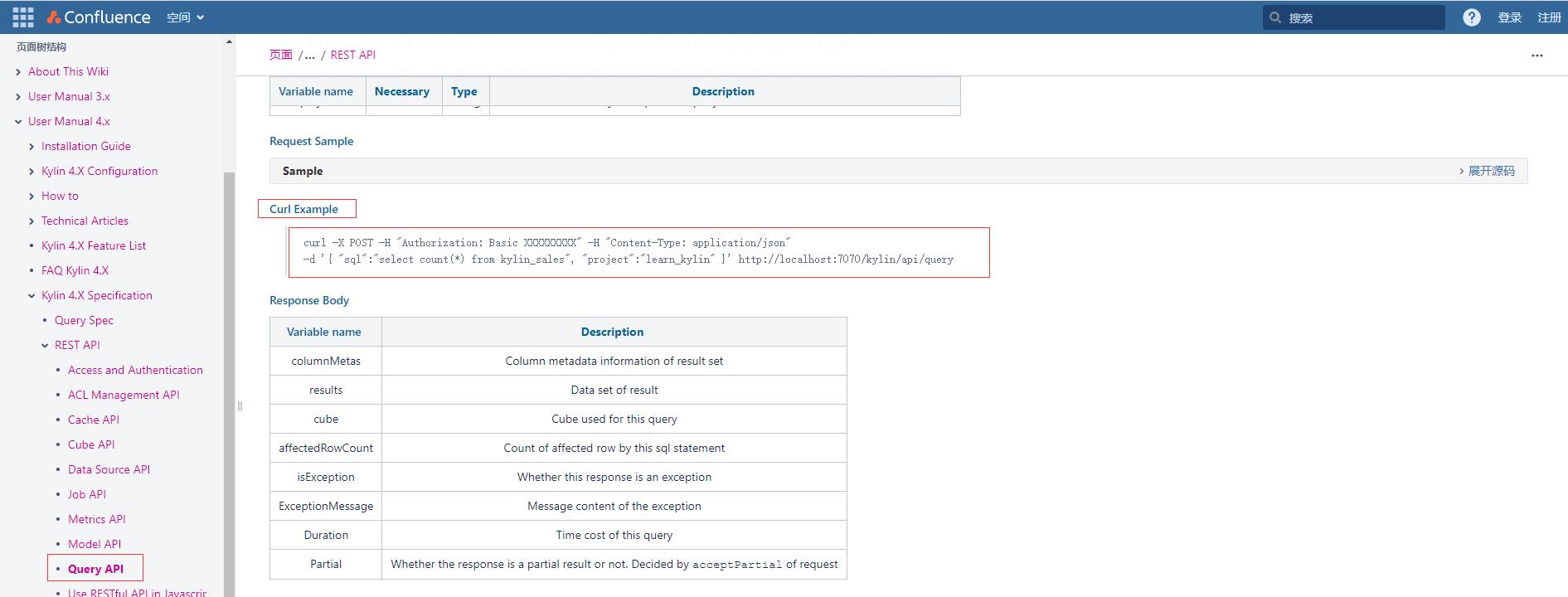
复制上面脚本得到的授权码并修改成如下:
curl -X POST -H "Authorization: Basic QURNSU46S1lMSU4=" -H "Content-Type: application/json" -d ' "sql":"select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname;", "project":"firstproject" ' http://hadoop1:7070/kylin/api/query
可以看到返回成功结果数据

cube定时构建
通过Cube API中找到Build Cube,查看地址,路径变量和请求体的参数说明
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lukQbqYf-1676045281339)(image-20230209154440123.png)]
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '"startTime":'1423526400000', "endTime":'1423612800000', "buildType":"BUILD"' http://hadoop1:7070/kylin/api/cubes/emp_cube/build
如果需要每日构建则可以通过Kylin 提供了 Restful API,将构建 cube 的命令写到脚本中,将脚本交给DolphinScheduler、Azkaban之类的调度工具,以实现定时调度的功能。
集成
集成JDBC示例
添加kylin的依赖
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>4.0.3</version>
</dependency>
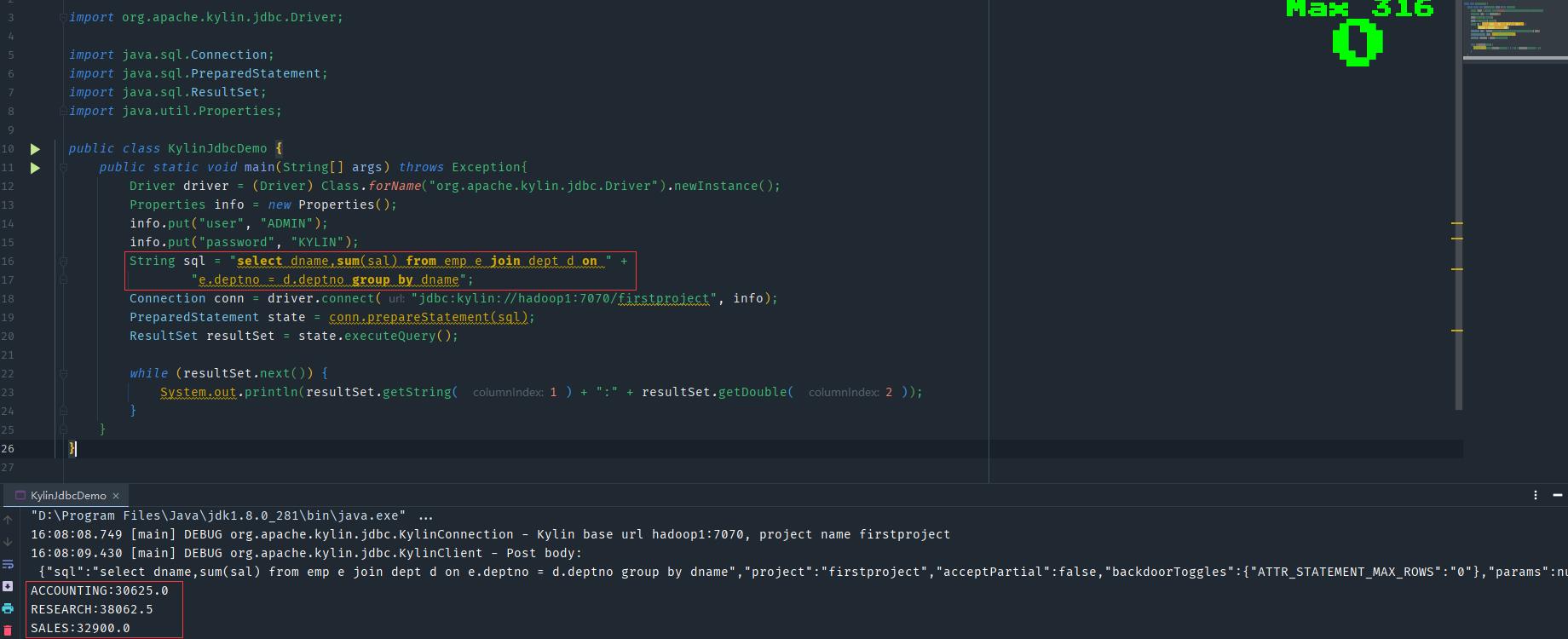
创建KylinJdbcDemo.java测试类
import org.apache.kylin.jdbc.Driver;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
public class KylinJdbcDemo
public static void main(String[] args) throws Exception
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
String sql = "select dname,sum(sal) from emp e join dept d on " +
"e.deptno = d.deptno group by dname";
Connection conn = driver.connect("jdbc:kylin://hadoop1:7070/firstproject", info);
PreparedStatement state = conn.prepareStatement(sql);
ResultSet resultSet = state.executeQuery();
while (resultSet.next())
System.out.println(resultSet.getString( 1 ) + ":" + resultSet.getDouble( 2 ));
运行查看结果是正确的
- 本人博客网站IT小神 www.itxiaoshen.com
以上是关于开源分布式支持超大规模数据分析型数据仓库Apache Kylin实践-下的主要内容,如果未能解决你的问题,请参考以下文章