开源数据仓库解决方案GreenPlum
Posted DevOps
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源数据仓库解决方案GreenPlum相关的知识,希望对你有一定的参考价值。
GreenPlum简介
Greenplum DB 号称是世界上第一个开源的大规模并行数据仓库,最初是基于 PostgreSQL,现在已经添加了大量数据库方面的创新。Greenplum 提供 PD 级别数据量的强大和快速分析能力,特别是面向大数据方面的分析能力,支持大数据的超高性能分析查询。
GreenPlum 主要特性:
大规模并行处理架构
高性能加载,使用 MPP 技术,提供 Petabyte 级别数据量的加载性能
大数据工作流查询优化
多态数据存储和执行
基于 Apache MADLib 的高级机器学习功能
Greenplum 采用 Apache 协议开源之后,加上之前的 HAWQ, PostgreSQL 以及 PostGIS,完全可以构建一体化的 PostgreSQL 企业数据架构。
什么是GreenPlum?
对于很多IT人来说GREENPLUM是个陌生的名字。简单的说它就是一个与ORACLE, DB2一样面向对象的关系型数据库。我们通过标准的SQL可以对GP中的数据进行访问存取。
GREENPLUM与其它普通的关系型数据库的区别?
本质上讲GREENPLUM是一个关系型 数据库集群. 它实际上是由数个独立的数据库服务组合成的逻辑数据库。与RAC不同,这种数据库集群采取的是MPP 架构。
它的组件分成三个部分MASTER/SEGMENT以及MASTER与SEGMENT之间的高效互联技术GNET。其中MASTER和SEGMENT本身就是独立的数据库SERVER。不同之处在于,MASTER只负责应用的连接,生成并拆分执行计划,把执行计划分配给SEGMENT节点,以及返回最终结果给应用,它只存储一些数据库的元数据,不负责运算,因此不会成为系统性能的瓶颈。这也是GREENPLUM与传统MPP架构数据库的一个重要区别。 SEGMENT节点存储用户的业务数据,并根据得到执行计划,负责处理业务数据。也就是用户关系表的数据会打散分布到每个SEGMENGT节点。当进行数据访问时,首先所有SEGMENT并行处理与自己有关的数据,如果需要segment可以通过进行innterconnect进行彼此的数据交互。 segment节点越多,数据就会打的越散,处理速度就越快。因此与SHARE ALL数据库集群不同,通过增加SEGMENT节点服务器的数量,GREENPLUM的性能会成线性增长。
GREENPLUM适用场景?
GREENPLUM虽然是关系型数据库产品,它的特点主要就是查询速度快,数据装载速度快,批量DML处理快。而且性能可以随着硬件的添加,呈线性增加,拥有非常良好的可扩展性。因此,它主要适用于面向分析的应用。比如构建企业级ODS/EDW,或者数据集市等等。
GREENPLUM运行的平台?
GREENPLUM运行在X86架构的硬件平台上,目前支持的操作系统包括32/64位的 LINUX(REDHAT/SUSE)/SOLARIS/MAC OS
GREENPLUM的前景?
GREENPLUM 诞生于2003年硅谷,2010/07 EMC收购了GREENPLUM,并把GREENPLUM作为EMC面向分析云的战略核心产品,加以大力发展。该产品不仅在国际市场发展很快,在国内市场发展也很快。最著名的案例就是阿里巴巴集团,经过多种产品的精心选型,最终选择GREENPLUM作为它们的数据仓库平台存放数百TB的业务数据去高效支持各种分析应用。
如何学习GREENPLUM?
正是由于产品发展速度很快,但是在相关人才上存在很大缺口。因此,我个人认为对于各位有兴趣的技术人员来说,是一个很好的职业发展机会。以个人经验来说,只要有其它关系型数据库的基础,尤其是POSTGRESQL或者INFORMIX基础的(因为GREENPLUM是在POSTGRESQL基础上开发出来的),很容就可以上手学习并掌握GREENPLUM。
GREENPLUM的手册写的非常好,完全可以作为入门的教材使用。其软件本身也是软性LICENSE,用于学习研究完全免费,而且与生产环境并无不同,这与ORACLE完全一样。
Greenplum入门介绍
Greenplum数据库是在postgreSQL开发出来的,基于MPP(massively parallel processing)和shared-Nothing架构(Oracle RAC是shared everything架构)。
主要用在数据仓库中,做大规模数据和复杂的查询功能所涉及。
与现有的数据仓库解决方案(Oracle、IBM、Microsoft、Sybase和Teradata)相比有他自己的特点:
1.速度更快 2.支持数据量更大,扩展性较好 3.价格更低
缺点:
1、对局域网带宽要求很高,一般都是千兆交换机。
2、不支持在线扩容,扩容的话至少要增加2台以上的机器。后若不是成2倍扩展,需要重新平均分布所有数据。
(Greenplum的架构图)
Master节点主要作用:
接收客户端的连接、处理SQL命令、调配各segment节点间工作负载、协调各segment节点返回结果并把最终的结果返回给用户。
所有数据库的元数据都保存在Master节点,并不保存用户数据。各segment数据要做交换的是不经过master的。
Segment节点主要作用:
数据存储、 处理大多数的查询请求。
表和索引被分布在GP数据库的可用segment节点中,每个segment包含部分且唯一的数据。用户不能直接和segment节点做交互,都是要先通过master节点。
Interconnect网络连接层作用:
负责各segment节点进程通信,使用标准的千兆交换机。
数据传输缺省使用UDP协议。使用UPD时,GP会做额外数据包校验和对未执行的也会做检查。故在可靠性上,基本和TCP上是等价的,在性能和扩展性上,却优于TCP。
使用TCP的话,GP有1000个segment的限制,UDP则没有。
Greenplum技术浅析
说起Greenplum这个产品,最早是SUN来推他们的数据仓库产品DWA时接触到的,对这个由PgSQL堆叠出来的数据库产品还不是很了解,当时的焦点还在DWA本身的硬件上,当然不可否认,DWA还是有一些特点的。
后来,我们发现普通的PC+SAS磁盘具备非常好的吞吐能力,完全不逊于某些昂贵的存储设备。这样我们就尝试用PC+Greenplum搭建了一个 环境,效果完全超出了我们的预期,吞吐量完全超过了我们的大型存储。从那时开始,我们不再迷信那些昂贵的主机和存储,开始尝试一些新的东西,比如用 PC+SAS/SATA来堆叠廉价存储,用Greenplum来搭建数据仓库计算环境,搜索的hadoop集群,PC+SSD搭建OLTP数据库,用 Intel Nehalem来替代小型机等等。
昨天,去参加了数据仓库部门关于Greenplum的一个技术分享,期间大量列举了一些性能数据的对比,尤其是和当前的一套Oracle RAC的对比。结果不言而喻,在数据仓库的应用上,尤其是大数据量的处理,性能相差悬殊。这时问题就来了,很多人感觉这个产品太神奇了,可以解决数据仓库 的一切问题,好像它就是上帝赐予我们的礼物。最后好多人都在问:Oracle太烂了,用这么好的设备,性能还这么差,我们干嘛还要用?呜呼哀 哉,Greenplum是好,但并不“神奇”,我们不要被这些”神奇“的数据挡住了视线。
对于Greenplum,我其实也处于一知半解的状态,给大家讲原理未免有些力不从心,这里只简单给大家分析一下Greenplum为什么会快?他用了什么”神奇“的技术?
如何提升数据仓库的处理能力,有以下两个主要因素:第一,吞吐能力,就是所谓的IO;第二,并行计算能力。
我们都知道Oracle RAC是shared everything架构,而Greenplum是shared nothing架构。整个集群由很多个segment host(数据节点)+master host(控制节点)组成,其中每个segment host上运行了很多个PgSQL数据库(segment)。
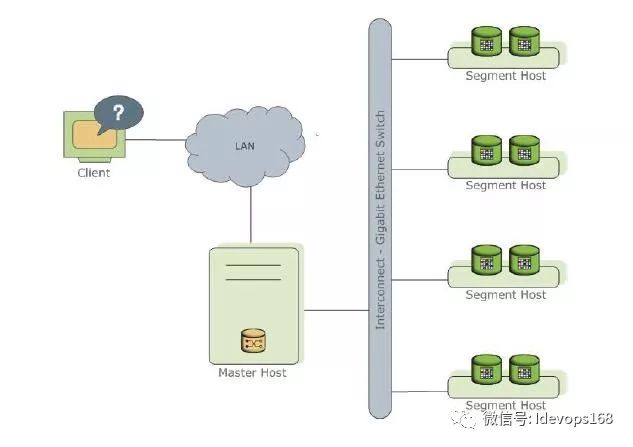
很多人在看到Greenplum架构的时候,第一个问题就是master机器承担了什么功能?它会不会成为系统的瓶颈?这也是Greenplum系 统的一个重要特点,master只承担非常少量的控制功能,以及和客户端的交互,完全不承担任何计算。如果存在一个中心节点的话,那意味着这个系统根本没 有办法线性扩展,因为master一定会成为系统的瓶颈。而Greenplum不存在这个问题,节点间的数据交互,不需要经过master,而是直接在节 点间就完成了。
现在,如果我们要查询某个表的数据,只要把工作分配给每个节点就行了,IO不再是问题,接下来要解决并行计算的问题,核心问题是多表做join。因 为表是通过DT列做分布的,所以每个节点通过DT列就知道数据在某个节点上,假设两个表用DT列做join,因为相同的数据都在相同的节点上,所以只需要 对应节点计算,然后合并结果就可以了。如果是非DT列做join,因为节点间不知道数据的分布,所以就会做一个数据重分布的过程 (redistribute)。我们看下面的例子,三个表都是用id列作为DT列,首先用id做join,因为设计到非DT列的join,这时 Greenplum会作redistribute的工作,作用就是重新按照hash做数据分布,这样做的目的就是要让节点知道数据在哪个节点上,以便完成 join的动作。我们看到后面的group by也做了redistribute,因为group by的也是非DT列,而hash aggregate动作也需要节点间交互数据,节点间也必须知道数据的分布。如果有redistribute动作,效率会高吗?因为 redistribute仅仅只针对需要的数据,而且全部在节点cache中完成,肯定要比DT列做join慢一些,但是效率还是非常高的。

现在来看Greenplum并不神奇,其实Oracle RAC也是数据仓库非常好的解决方案,类似的技术Oracle全部都有。我们可以这样来做一个假设,如果针对某个固定的SQL,我可以同样用Oracle RAC来做Greenplum做的事情,根据SQL,我们可以把表做 Hash+Range分区(事实上Greenplum也是hash+range分区,用hash将数据分布到不同的数据库上,然后再用range将每个数 据库上的表做分区),再利用RAC的并行处理能力。Oracle也有partition-wise join这种类似功能,但是没有数据redistribute的操作。Oracle最大的问题还是在于shared everything的架构,导致IO的处理能力有限,我们的大型存储吞吐量也就1.4GB/S,而且扩展能力也有限。以前曾经介绍过的Oracle database machine,就是Oracle专门为数据仓库的提供的解决方案。
其实并存在什么神奇的技术,Greenplum之所以神奇是因为我们的场景发挥了他的特点,其实我们也可以设计一个场景来得到Greenplum很烂的结论,所以不要相信厂商的数据,不要相信什么可以解决一切问题的技术,那根本不存在。
”不要迷恋哥,哥只是传说。“
greenplum数据库引擎探究
Greenplum做为新一代的数据库引擎,有着良好的发展与应用前景。强大的工作效率,低成本的硬件平台对数据仓库与商业智能建设有很大的吸引力。要清楚的了解其特点最好从架构着手。 
架构分析
Greenplum的高性能得益于其良好的体系结构。Greenplum的架构采用了MPP(大规模并行处理)。在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配 (Data Redistribution) 。与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。而MPP系统在决策支持和数据挖掘方面显示了优势,可以这样说,如果操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好,相反就不合适了。
Shared nothing架构
常见的OLTP数据库系统常常采用shared everything架构来做集群,例如oracle RAC架构,数据存储共享,节点间内存可以相互访问。
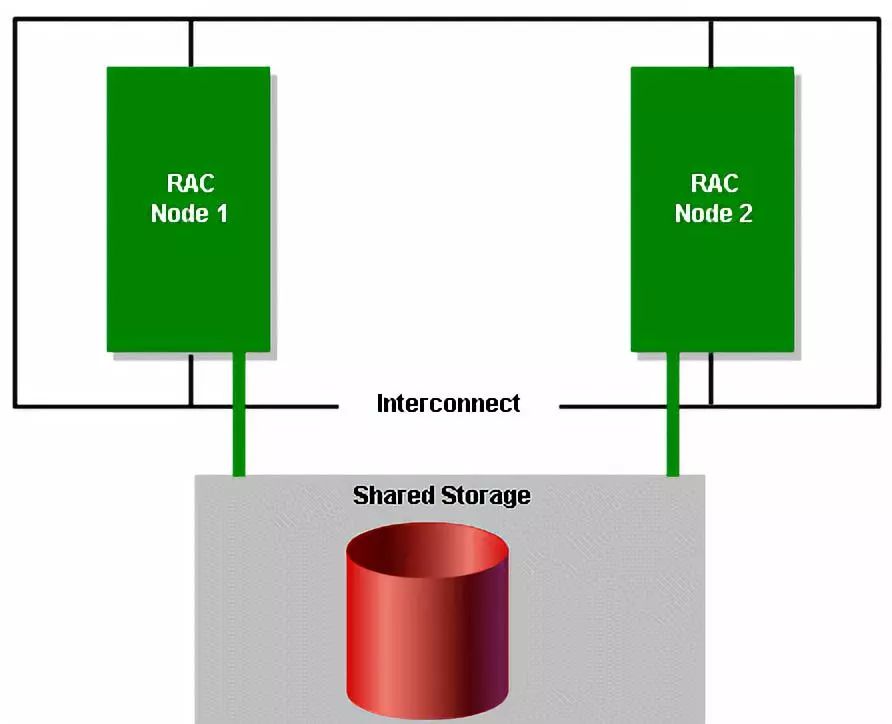
Oracle RAC架构
Greenplum是一种基于postgresql(开源数据库)的分布式数据库。其采用shared nothing架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。主要由master host,segment host,interconnect三大部分组成。
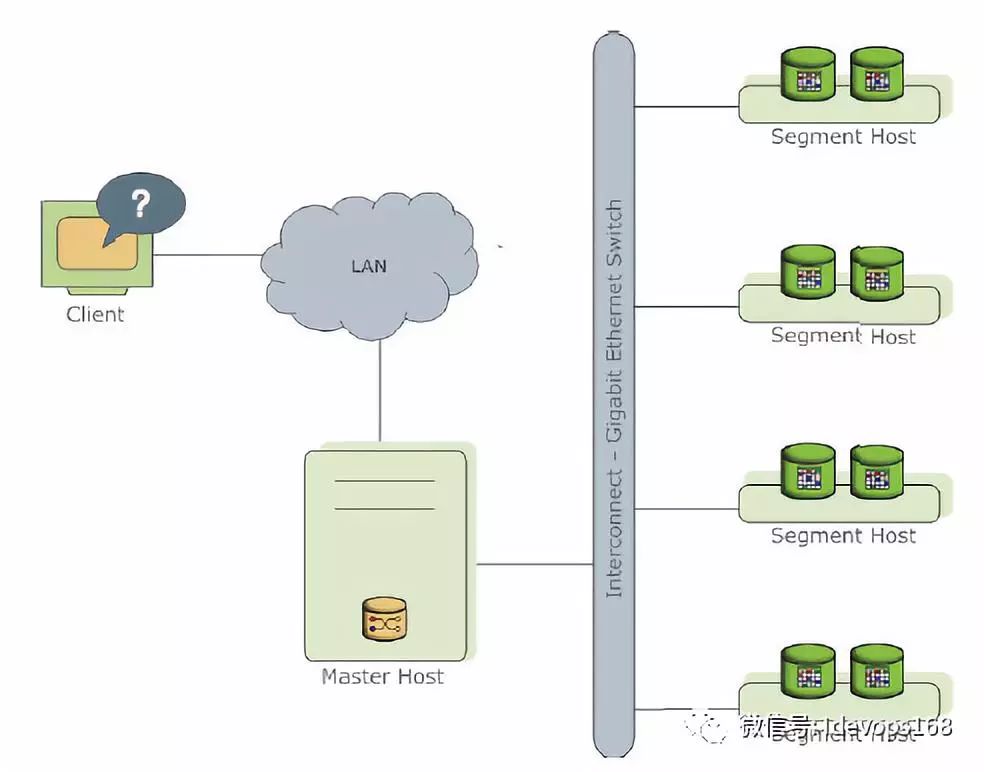
Greenplum架构图
了解完Greenplum的架构后,对其工作流程也就相对简单了。因greenplum采用了MPP架构,其主要的优点是大规模的并行处理能力,应该把精力主要放在大规模存储与并行处理两个方面。
大规模存储
Greenplum数据库通过将数据分布到多个节点上来实现规模数据的存储。数据库的瓶颈经常发生在I/O方面,数据库的诸多性能问题最终总能归罪到I/O身上,久而久之,IO瓶颈成为了数据库性能的永恒的话题。
Greenplum采用分而治之的办法,将数据规律的分布到节点上,充分利用segment主机的IO能力,以此让系统达到最大的IO能力(主要是带宽)。
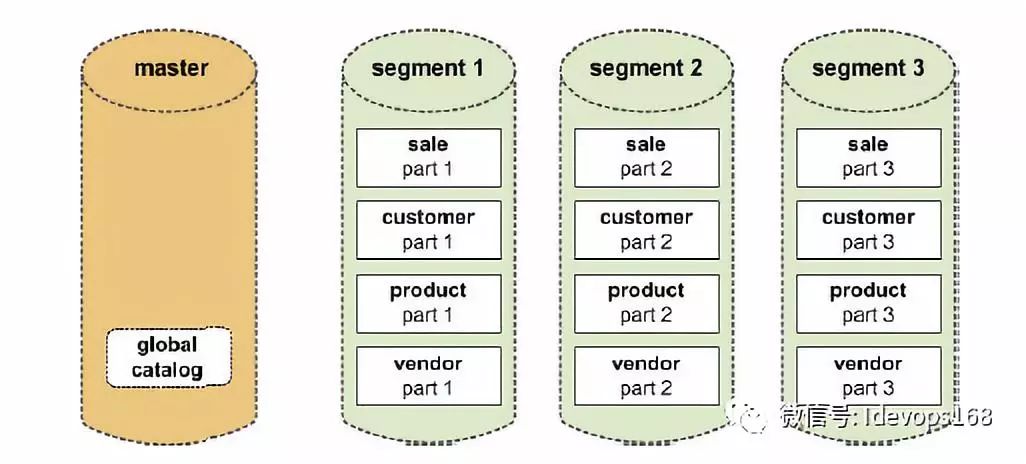
在greenplum中每个表都是分布在所有节点上的。Master host首先通过对表的某个或多个列进行hash运算,然后根据hash结果将表的数据分布到segment host中。整个过程中master host不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
并行处理
Greenplum的并行处理主要体现在外部表并行装载,并行备份恢复与并行查询处理三个方面。
数据仓库的主要精力一般集中在数据的装载和查询,数据的并行装载主要是在采用外部表或者web表方式,通常情况下通过gpfdist来实现。
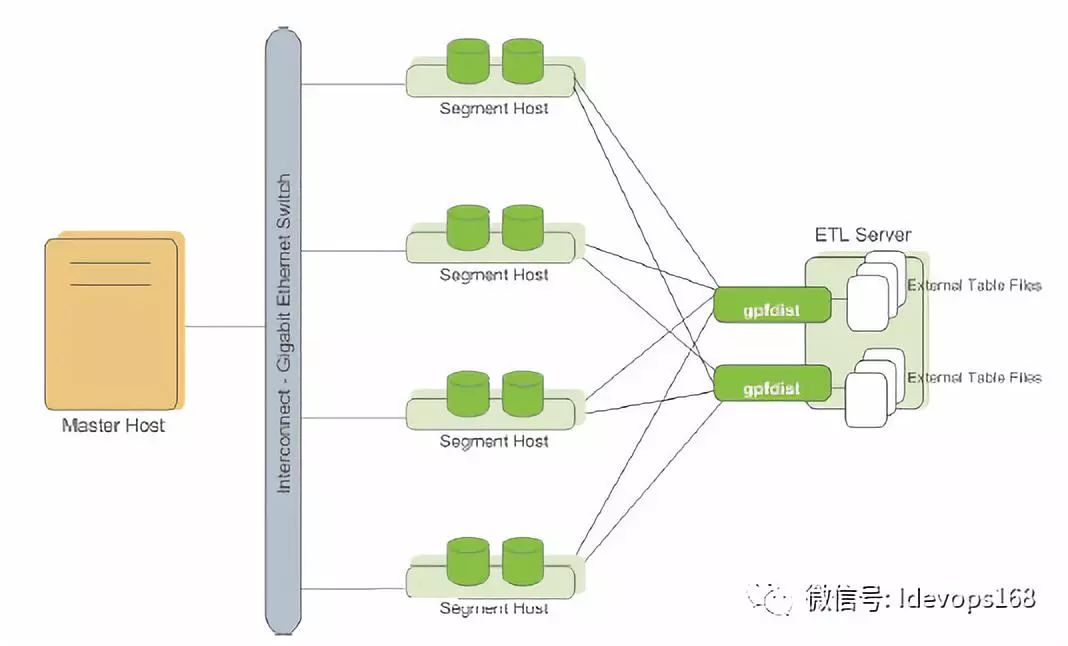
Gpfidist架构
Gpfdist程序能够以370MB/s装载text格式的文件和200MB/s装载CSV格式文件,ETL带宽为1GB的情况下,我们可以运行3个gpfdist程序装载text文件,或者运行5个gpfdist程序装载CSV格式文件。例如图例中采用了2个gpfdist程序进行数据装载。可以根据实际的环境通过配置postgresql.conf参数文件来优化装载性能。
查询性能的强弱往往由查询优化器的水平来决定,greenplum主节点负责解析SQL与生成执行计划。Greenplum的执行计划生成同样采用基于成本的方式,基于数据库是由诸多segment实例组成,在选择执行计划时主节点还要综合考虑节点间传送数据的代价。
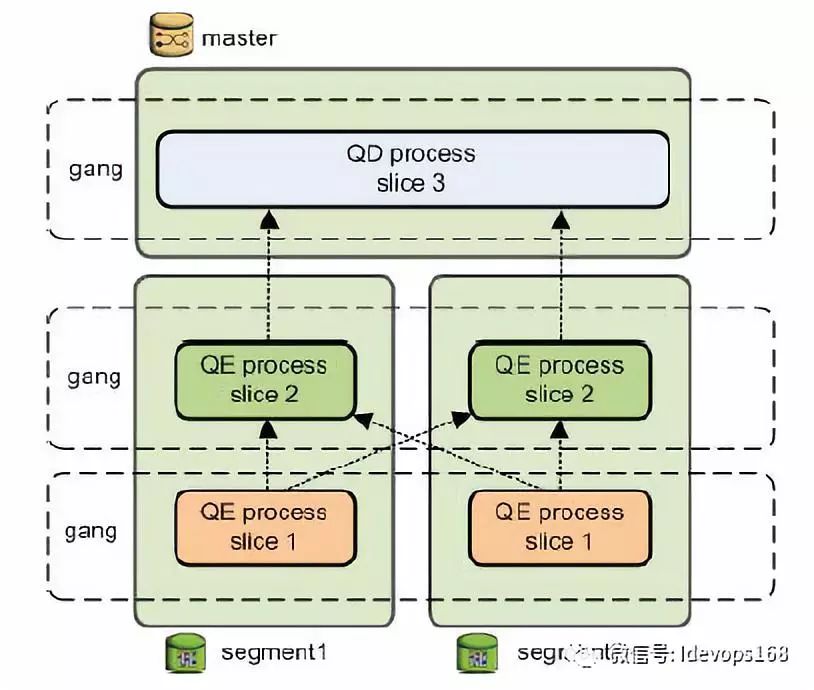
工作原理:
在主节点上存在query dispatcher (QD)进程,该进程前期负责查询计划的创建和调度,segment instance返回结果后,该进程再进行聚合与向用户展示;segment host存在query executor (QE)进程,该进程负责其它节点相互通信与执行QD调度的执行计划。
Greenplum最为一个严格的数据库系统,同样支持线性扩展,高可用性架构,数据与主机的容错机制,还有数据的分区与压缩功能。
想要充分的发挥出greenplum的性能,还要对greenplum的运行机制有更加深入的了解。
GreenPlum官网:http://pivotal.io/big-data/pivotal-greenplum
欢迎关注运维自研堂订阅号,运维自研堂是一个技术分享平台,主要是运维自动化开发:linux、python、django、saltstack、tornado、bootstrap、redis、golang、docker、etcd等经验分享。
开源 创新 共享
投稿&商务合作
Mail:idevops168@163.com QQ:785249378
牛人并不可怕,可怕的是牛人比我们还努力!
以上是关于开源数据仓库解决方案GreenPlum的主要内容,如果未能解决你的问题,请参考以下文章