GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(CUDA-Aware MPI)
Posted 从善若水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(CUDA-Aware MPI)相关的知识,希望对你有一定的参考价值。
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
利用蒙特卡罗法求解 𝜋 的近似值(CUDA-Aware MPI)

CUDA-Aware MPI
MPI 帮助我们清理了在显式管理多个设备时使用的样板程序,但也牺牲了多个 GPU 之间直接对话的好处。MPI 是一种分布式内存并行编程模型,其中每个处理器都有自己的(虚拟)内存和地址空间,即使所有成员都在同一服务器上并因此共享相同的物理内存也不例外。(通常情况下,与之不同的是共享内存并行编程模型 ,其中每个处理线程都可以访问相同的内存空间,如 OpenMP。类似的还有传统的单 GPU CUDA 编程,其中所有线程都可以访问全局内存。) 因此我们将每个 GPU 的结果复制到 CPU,然后在 CPU 上求和。
但只要我们停留在单个服务器上,CUDA 通用地址空间的规则仍然有效,因此所有通过 CUDA 分配内存的结果都是虚拟地址,可以在进程之间有意义地共享(即使通常的 CPU 动态分配的内存不能实现这一点也无妨)。因此,MPI 可以在底层直接实现点对点内存拷贝。对于远程服务器之间的通信,这样是不行的,但还有其它技术允许 GPU 通过网络接口直接与远端 GPU 实现通信,尤其是 GPUDirect RDMA。由于认识到利用这些技术进行有效通信的价值,许多 MPI 的实现(包括我们使用的 OpenMPI)提供了CUDA-Aware MPI,程序员可以利用它向MPI通信函数提供设备内存的地址,然后 MPI 可以自由使用任何通信方案实现从一个 GPU 传输数据到另一个 GPU,包括使用 GPUDirect P2P 和 GPUDirect RDMA,只要合适就行。(请注意,尽管经常看到将 GPUDirect 和CUDA-Aware MPI 这两个术语错误的合并在一起,但前者指的是一系列技术,后者指的是可以在底层使用这些技术的 API。)
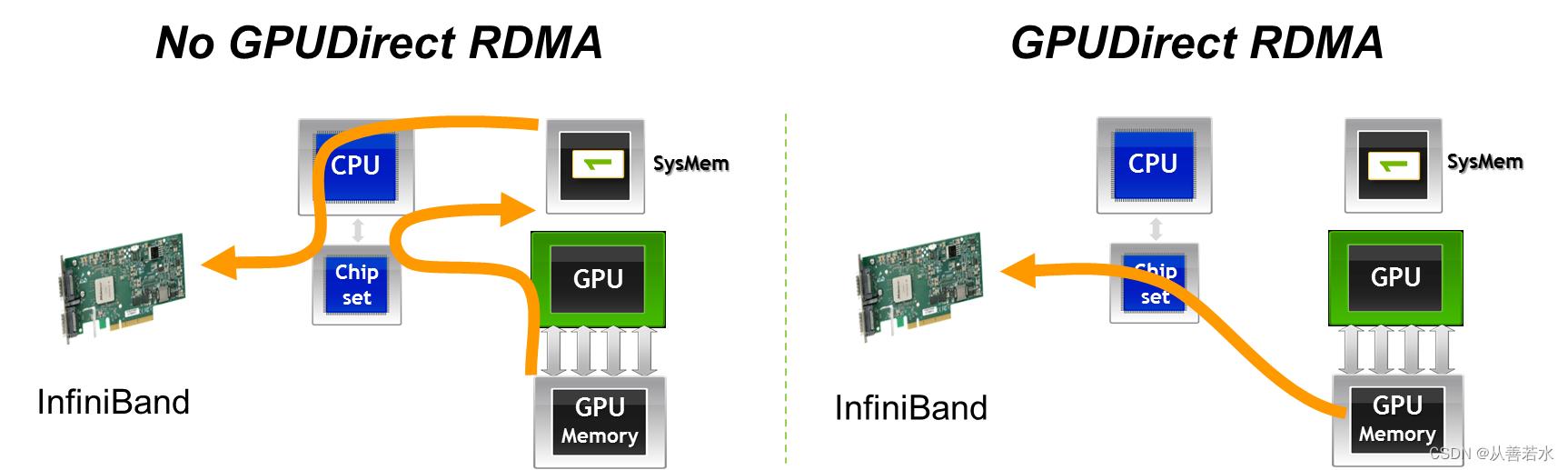
因此,CUDA-Aware MPI 提供了简化编程的好处,同时保留了避免不必要的将数据拷贝到 CPU 内存的性能优势。请谨记,撰写最终归约的方法之一是……
MPI_Reduce(d_hits, total_hits, 1, MPI_INT, MPI_SUM, root, MPI_COMM_WORLD);
……在此方法中,MPI 会自动发现发送缓冲区 d_hits 驻留在设备上,而接收缓冲区total_hits驻留在主机上,并会在幕后进行正确操作来启动数据拷贝。
一个例子
#include <iostream>
#include <curand_kernel.h>
#include <mpi.h>
#define N 1024*1024
__global__ void calculate_pi(int* hits, int device)
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// 初始化随机数状态(网格中的每个线程不得重复)
int seed = device;
int offset = 0;
curandState_t curand_state;
curand_init(seed, idx, offset, &curand_state);
// 在 (0.0, 1.0] 内生成随机坐标
float x = curand_uniform(&curand_state);
float y = curand_uniform(&curand_state);
// 如果这一点在圈内,增加点击计数器
if (x * x + y * y <= 1.0f)
atomicAdd(hits, 1);
int main(int argc, char** argv)
// 初始化 MPI
MPI_Init(&argc, &argv);
// 获取我们的rank和rank总数
// MPI_COMM_WORLD 意味着我们想要包含所有进程
// (可以在 MPI 中创建仅
// 包含某些rank的“通信器”)。
int rank, num_ranks;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_ranks);
// 确保我们的rank个数不超过 GPU 数量
int device_count;
cudaGetDeviceCount(&device_count);
if (num_ranks > device_count)
std::cout << "Error: more MPI ranks than GPUs" << std::endl;
return -1;
// 每个rank(任意)选择与其rank对应的 GPU
int dev = rank;
cudaSetDevice(dev);
// 分配主机和设备值
int* hits;
hits = (int*) malloc(sizeof(int));
int* d_hits;
cudaMalloc((void**) &d_hits, sizeof(int));
// 初始化点击次数并复制到设备
*hits = 0;
cudaMemcpy(d_hits, hits, sizeof(int), cudaMemcpyHostToDevice);
// 启动核函数进行计算
int threads_per_block = 256;
int blocks = (N / device_count + threads_per_block - 1) / threads_per_block;
calculate_pi<<<blocks, threads_per_block>>>(d_hits, dev);
cudaDeviceSynchronize();
// 将所有rank的结果累加到第0号 rank 的结果中
int* d_total_hits;
cudaMalloc((void**) &d_total_hits, sizeof(int));
int root = 0;
MPI_Reduce(d_hits, d_total_hits, 1, MPI_INT, MPI_SUM, root, MPI_COMM_WORLD);
if (rank == root)
// 将结果复制回主机
int* total_hits = (int*) malloc(sizeof(int));
cudaMemcpy(total_hits, d_total_hits, sizeof(int), cudaMemcpyDeviceToHost);
// 计算 pi 的最终值
float pi_est = (float) *total_hits / (float) (N) * 4.0f;
// 打印结果
std::cout << "Estimated value of pi = " << pi_est << std::endl;
std::cout << "Error = " << std::abs((M_PI - pi_est) / pi_est) << std::endl;
// 清理
free(hits);
cudaFree(d_hits);
// 最终确定 MPI
MPI_Finalize();
return 0;
编译命令(只做参考)
nvcc -ccbin=mpicxx -x cu -arch=sm_70 -o monte_carlo_mgpu_cuda_mpi_cuda_aware exercises/monte_carlo_mgpu_cuda_mpi_cuda_aware.cpp
mpirun -np $NUM_DEVICES ./monte_carlo_mgpu_cuda_mpi_cuda_aware
运行结果(只做参考)
Estimated value of pi = 3.14072
Error = 0.000277734
总结
您现在已经掌握了管理多个 GPU 以分配并行工作负载的多种方法,其中包括在设备上显式地循环,以及使用 MPI 隐式地使用多台设备的做法。您还了解了处理 GPU 之间数据传输的多种方法,包括直接点对点内存访问、点对点 CUDA 内存拷贝和通过 CPU 内存的数据拷贝。
希望您已借此更好地了解了每种方法的优缺点。值得一提的是,CUDA-Aware MPI 的方法十分出众,可实现超高性能。
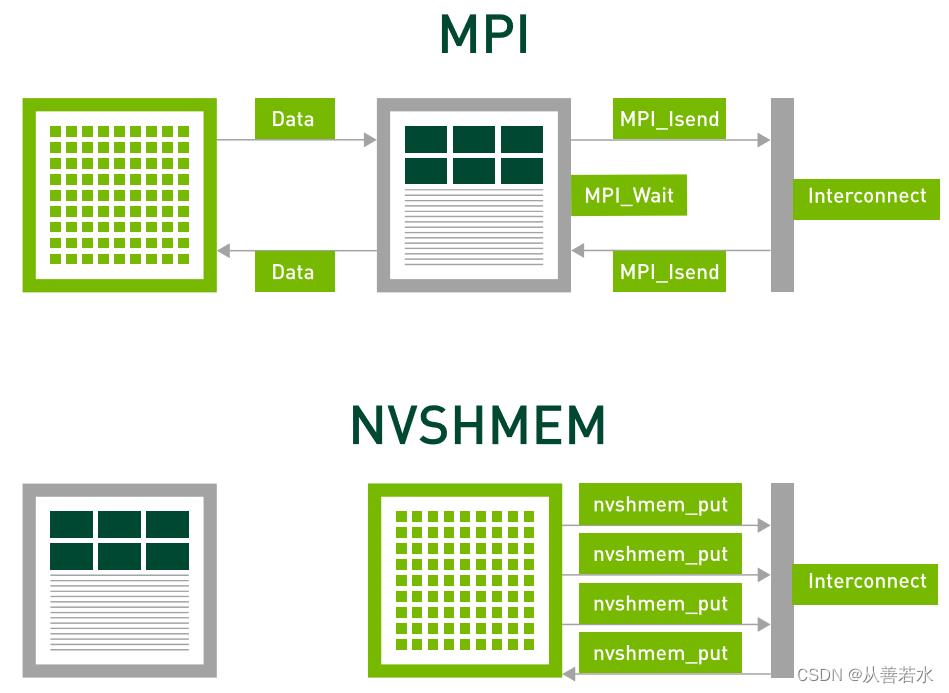
但即使是CUDA-Aware MPI,我们也必须返回到 CPU 来启动传输。对于许多应用而言,尤其是那些由于 GPU 在传统计算中的高效率而遭遇扩展性限制的应用,返回 CPU 的延迟可能会造成严重的性能损失。如果我们能够拥有类似 MPI 的 SPMD 的特性,从而实现高度可理解的编程,同时保留直接从核函数启动传输的潜在性能优势,岂不是两全其美? 接下来,我们将介绍 NVSHMEM,并演示其正好提供了上述好处。

以上是关于GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(CUDA-Aware MPI)的主要内容,如果未能解决你的问题,请参考以下文章
GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(CUDA-Aware MPI)
GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(CUDA-Aware MPI)
GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(NVSHMEM)
GPUNvidia CUDA 编程高级教程——利用蒙特卡罗法求解近似值(NVSHMEM)