数据挖掘基于RFM的精细化用户管理
Posted Sciengineer-Mike
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘基于RFM的精细化用户管理相关的知识,希望对你有一定的参考价值。
1.摘要
用户价值细分是了解用户价值度的重要途径,而销售型公司中对于订单交易尤为关注,因此基于订单交易的价值度模型将更适合运营需求。针对交易数据分析的常用模型是RFM模型,该模型不仅简单、容易理解,且业务落地能力非常强。因此,本节将基于该模型做数据分析和应用。在RFM的结果中,业务部门希望不仅能对用户做分组,还希望能将每个组的用户特征概括和总结出来,这样便于后续精细化运营不同的客户群体,且根据不同群体做定制化或差异性的营销和关怀。
本文的案例数据是某企业2018年的用户订单抽样数据,数据来源于销售系统。数据在Excel中包含2个sheet,第一个sheet为用户的下单数据,后一个sheet为用户的等级表。具体内容如图:
2.案例实战
会员价值度,作为评价用户的价值情况,是区分用户价值的重要模型和参考依据,也是衡量不同营销效果的关键指标之一。价值度模型一般基于交易行为产生,衡量的是有实体转化价值的行为。常用的价值度模型是RFM模型。
RFM模型是根据会员最近一次购买时间R(Recency)、购买频率F(Frequency)、购买金额M(Monetary)计算出RFM得分,通过这3个维度来评估客户的订单活跃价值,常用来做客户分群或价值区分。该模型常用于电子商务(即交易类)企业的会员分析。
RFM模型基于一个固定时间点来做模型分析,因此今天做的RFM得分与7天前做的结果可能不一样,原因是每个客户在不同的时间节点所得到的数据不同。以下是RFM模型的基本实现过程。
(1)设置要做计算时的时间节点,用来做基于该时间的数据选取和计算。
(2)在会员数据库中,得到包含每个会员的会员ID、订单时间、订单金额的原始数据集。一个会员可能会产生多条订单记录。
(3)数据预处理。从订单时间中找到各个会员距离截止时间节点最近的订单时间作为最近购买时间;以会员ID为维度统计每个用户的订单数量作为购买频率;将用户多个订单的订单金额求和得到总订单金额。由此得到的R、F、M三个原始数据。
(4)R、F、M分区。对于F和M变量来讲,值越大代表购买频率越高、订单金额越高;但对于R来讲,值越小代表离截止时间节点越近,因此值越好。对R、F、M分别使用五分位(三分位也可以,分位数越多划分的越详细)法做数据分区。需要注意的是,对于R来讲需要倒过来划分,离截止时间越近的值,划分越大。这样得到每个用户的R、F、M三个变量的分位数值。
(5)将三个值组合或相加得到总的RFM得分。对于RFM总得分的计算,有两种方式,一种是直接将三个值拼接在一起,例如RFM得分为312、333、132等。另一种是直接将三个值相加,求得一个新的汇总值,例如RFM得分为6、9、6。 在得到不同的会员的R、F、M后,根据步骤5产生的两种结果,有两种应用思路。
接下来,开启我们的代码之路:
首先,导入相应的包。
import numpy as np
import pandas as pd
import time
from sklearn.ensemble import RandomForestClassifier
读取提供的数据
sheet_names = ["2018","会员等级"]
datas= [pd.read_excel("./sales1.xlsx",sheet_name=i) for i in sheet_names]
对订单数据进行预处理,删除缺失值,对订单金额小于1的判断为无效数据。
data = datas[0]
data.dropna(inplace=True)
data = data[data["订单金额"]>1]
data["max_year_date"] = data["提交日期"].max()
# 计算时间间隔
data["interval"] = (data["max_year_date"] - data["提交日期"]).apply(lambda x:x.days)
data.head()

计算客户最近一次的订单时间Recency、订单的频率Frequency、订单的总金额Monetary
rfm = data.groupby(["会员ID"],as_index=False).agg("interval":"min","提交日期":"count","订单金额":"sum")
rfm = rfm.rename(columns="interval":"r","提交日期":"f","订单金额":"m")
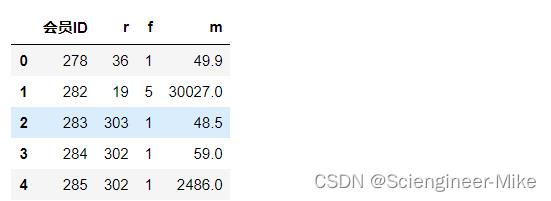
rfm.head()
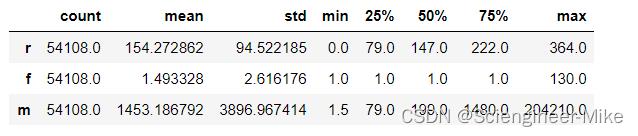
查看rfm的数据分布情况,进行分箱
rfm[["r","f","m"]].describe().T
箱子分布区间设置如下:
# 箱子不要太多,如下设置
r_bins = [-1,79,222,365]
f_bins = [0,2,5,132]
m_bins = [0,79,1480,204211]
在这里,我们先使用随机森林查看下R,F,M特征的重要性
#合并rfm数据和会员等级数据
rfm_merge = pd.merge(rfm,datas[-1],on="会员ID",how="inner")
以会员等级为标签,R,F,M为特征,进行模型训练
Model = RandomForestClassifier().fit(rfm_merge[["r","f","m"]],rfm_merge["会员等级"])
print(Model.score(rfm_merge[["r","f","m"]],rfm_merge["会员等级"]),Model.feature_importances_)
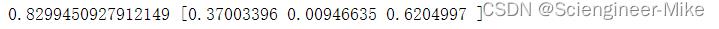
准确度达到0.8299,R和M的具有更大的重要性。
每个rfm的过程使用了pd.cut方法,基于自定义的边界区间进行划分,labels用来显示每个离散化后的具体值。F和M的规则是值越大,等级越高;而R的规则是值越小,等级越高。因此关于R的labels的规则与F和M相反。
# 开始分箱
rfm_merge["r_score"] = pd.cut(rfm_merge["r"],r_bins,labels=[i for i in range(4,1,-1)])
rfm_merge["f_score"] = pd.cut(rfm_merge["f"],f_bins,labels=[i for i in range(1,4,1)])
rfm_merge["m_score"] = pd.cut(rfm_merge["m"],m_bins,labels=[i for i in range(1,4,1)])
rfm_merge.head()
第一种分析方法:加权得分
然后将rfm三列分别乘以权重,得到新的rfm加权得分。通过加权得分来评估客户的重要程度。
importance_ = Model.feature_importances_
rfm_merge_RFC = rfm_merge.apply(np.int32)
rfm_merge_RFC["score"] = rfm_merge_RFC["r_score"] * importance_[0] + rfm_merge_RFC["f_score"] * importance_[1] + rfm_merge_RFC["m_score"] * importance_[2]
rfm_merge_RFC
第二种分析方法:RFM组合
rfm_merge_fenxiang = rfm_merge
rfm_merge_fenxiang["r_score"] = rfm_merge_fenxiang["r_score"].astype(np.str)
rfm_merge_fenxiang["f_score"] = rfm_merge_fenxiang["f_score"].astype(np.str)
rfm_merge_fenxiang["m_score"] = rfm_merge_fenxiang["m_score"].astype(np.str)
rfm_merge_fenxiang["rfm_group"] = rfm_merge_fenxiang["r_score"].str.cat(rfm_merge_fenxiang["f_score"]).str.cat(rfm_merge_fenxiang["m_score"])
rfm_merge_fenxiang.head()
统计各类客户的分布情况。
rfm_ = rfm_merge_fenxiang
pd.DataFrame(rfm_["rfm_group"].value_counts()/len(rfm_)*100)

这里,我们得到了我们关注的客户群体,对此进行相应的营销策略。
以上是关于数据挖掘基于RFM的精细化用户管理的主要内容,如果未能解决你的问题,请参考以下文章