理论+实操|一文掌握 RFM 模型在客户数据洞察平台内的落地实战
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理论+实操|一文掌握 RFM 模型在客户数据洞察平台内的落地实战相关的知识,希望对你有一定的参考价值。
确定用户价值是整个用户运营过程中极其重要的一环。传统的工作流程中,业务人员向数据部门提出数据需求,等待返回结果后再进行价值分析是主要的准备工作,但这个过程非常耗时。为了提高工作效率,业务人员经常会基于自己对用户的理解制定一系列的运营策略,但完成了运营活动后,比较难及时进行活动效果的跟进与评估,到了可以评估的时候又往往发现活动效果并不理想。
造成以上情况的主要原因就是业务人员认为的用户群体特征与用户实际的特征之间存在着一定的偏差,手动进行用户分析则耗时耗力,当有了客户数据洞察平台后,上述问题就全部迎刃而解了。
数据部门提前将基本的数据加工好,业务人员有需要的时候直接自主进行标签加工、群组分析等一系列操作,省去了很多沟通成本,将更多的精力放在了运营策略的制定上,最终成功落地效果突出的运营活动。
如何将用户从一个整体拆分成特征明显的群体决定了运营的成败。行业内有很多成熟的用户价值分析方法,而这其中最为经典的实现模型就是 RFM 模型。在资源有限的情况下,RFM 模型可以让企业聚焦于更有价值的用户,带来事半功倍的效果。
关于 RFM 模型,这个名字很多同学都知道,但深究到执行层面,相信很多同学都是一知半解,本文将为大家详细介绍 RFM 模型在「袋鼠云客户数据洞察平台」内的落地实战,帮助您快速判断用户价值等级,真正实现数据赋能业务发展。
RFM 模型核心维度
首先,让我们先来了解一下什么是 RFM 模型。RFM 模型是做用户精细化运营的常用分析方法,可以直观看出用户的价值贡献。RFM 模型包含三个重要指标:最近一次消费频率(Recency)、消费频率(Frequency)、消费金额(Monetary)。下面通过具体例子介绍如何生成 RFM 模型来指导运营工作的推进。
在开始加工标签、生成模型之前,首先要完成业务场景的分析,根据业务场景对用户的行为进行分层后,再通过「客户数据洞察平台」创建相应的「最近一次消费频率」、「消费频率」、「消费金额」标签,随后根据这些标签生成想要的 RFM 模型。
下面我们以用户下单行为为例来看一下近30天有下单行为的用户价值。根据对业务场景的分析,我们需要完成以下这些标签的加工:
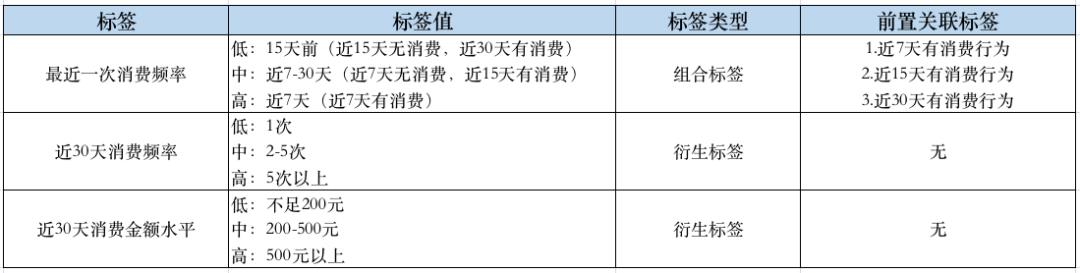
客户数据洞察平台中实现 RFM 模型
完成了业务场景的分析,接下来就可以在「客户数据洞察平台」完成标签的创建以及 RFM 模型的生成。
创建用户实体,并将订单表绑定至对应的用户实体下
下图展示了订单表绑定实体的过程,完成了绑定的实体则可以进行后续标签的加工。

根据订单表加工所需的衍生标签
通过前文的业务分析,我们需要以下5个衍生标签:近7天有消费行为、近15天有消费行为、近30天有消费行为、近30天消费频率、近30天消费金额水平。
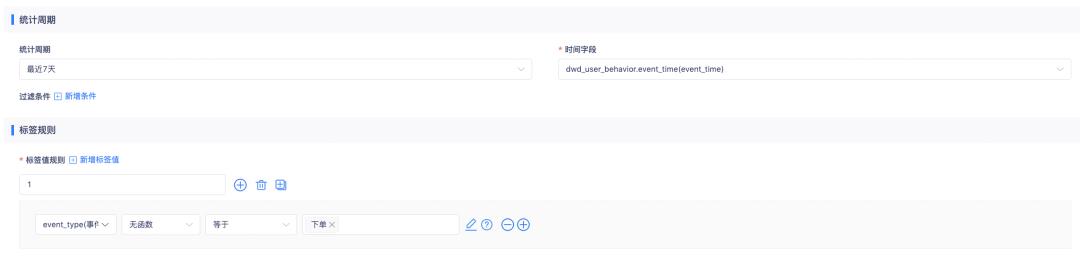
其中,「近7天有消费行为」、「近15天有消费行为」、「近30天有消费行为」标签的加工方法类似。下图仅展示「近7天有消费行为」标签的加工规则:
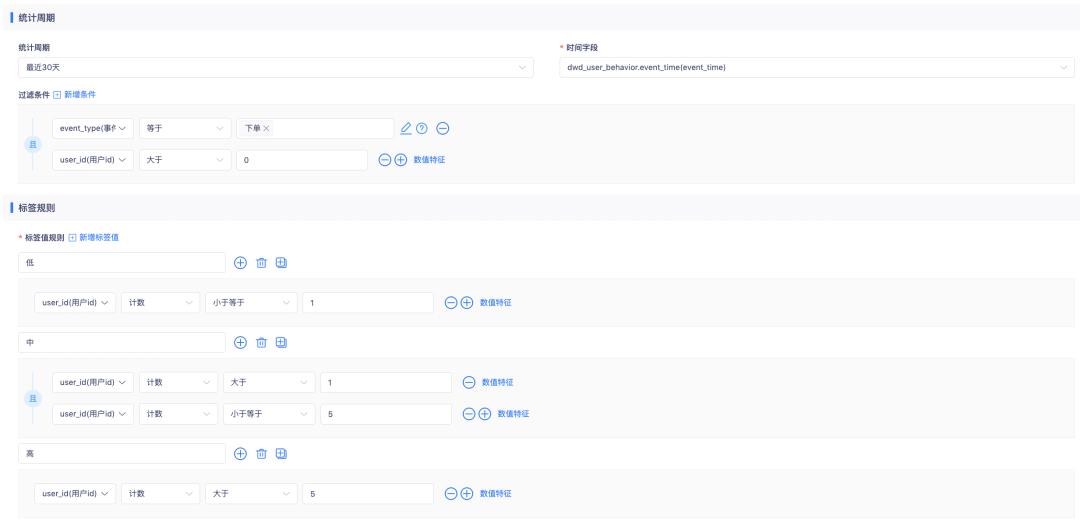
下图为「近30天消费频率」标签的加工规则:
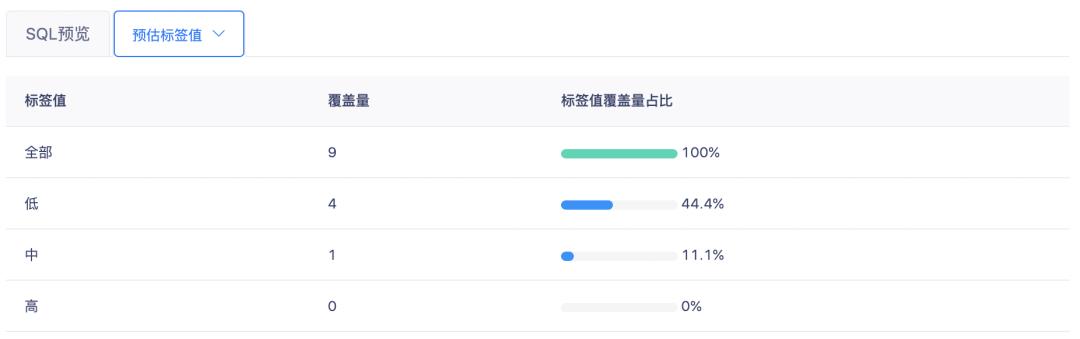
在加工标签的过程中,我们可以通过标签值分布功能来评估我们的分类标准是否合理,如出现了下图这种分布情况,则说明我们设置的「高」等级标签值的门槛过高,没有实例可以覆盖,此时我们需要整体调低分布区间,提高标签计算结果的利用率。
下图为「近30天消费金额水平」标签的加工规则:
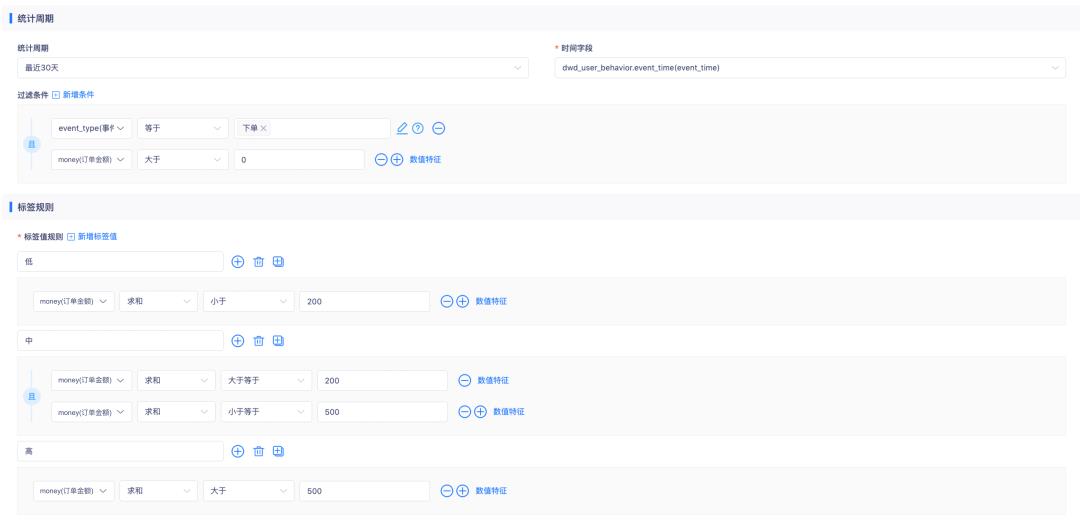
根据加工好的衍生标签加工组合标签
「最近一次消费频率」标签是根据近7天有消费行为、近15天有消费行为、近30天有消费行为三个衍生标签而来的组合标签,下图为「最近一次消费频率」标签的加工规则:
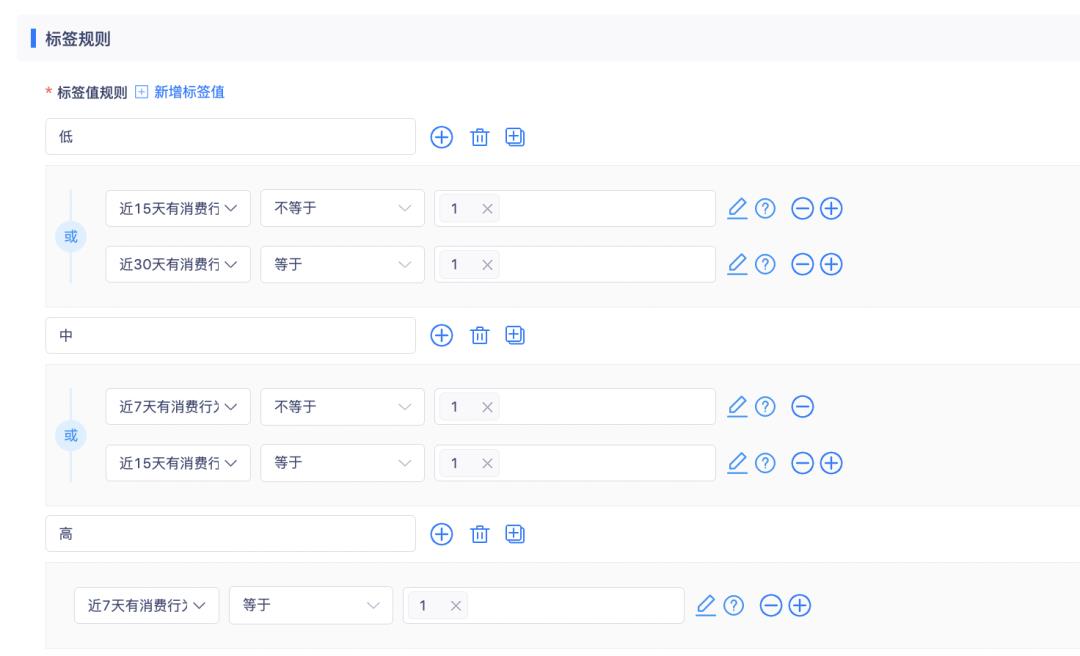
以上,我们就完成了实现 RFM 模型所必要的三个核心标签。
标签圈群,实现 RFM 模型
在创建 RFM 模型之前,让我们先对模型做一下拆解,看一下群体结果与业务是如何进行结合的。
在 RFM 模型中,我们需要的3个标签被分成了三个等级,对标签值进行自由组合,形成了27类人群,本文中选取其中的3类人群进行群组分析与洞察。
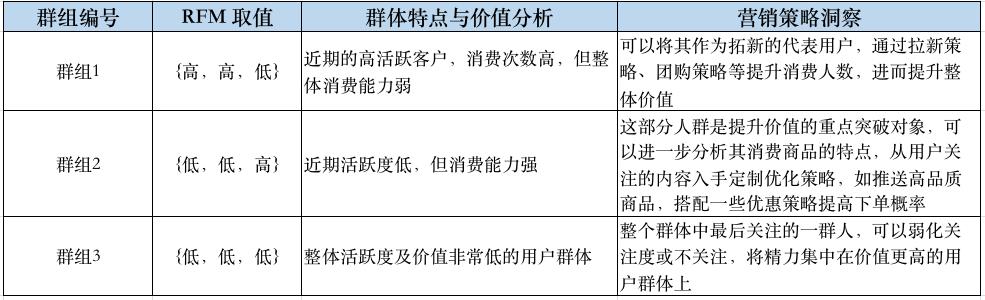
了解了 RFM 模型如何使用之后,我们就可以在「袋鼠云客户数据洞察平台」将需要进一步分析的各个群组的用户正式筛选出来,进而对各个群体进行定向的更加具体的营销策略制定与执行。
「袋鼠云客户数据洞察平台」提供了两种 RFM 模型落地的方式,一种是从27类人群中选取重点关注的群体分别建立群组;一种是使用平台提供的模型封装工具快速落地。
第一种方式将会节约更多的存储、计算资源,适合对模型、用户的理解与应用更加深刻的高级运营人员使用;第二种方式则可以更加方便快捷的查询各类不同价值等级的用户群体,更全面的洞察目标群体的突出特征,同时也需要花费更多的精力、更多的资源来关注一些低价值群体。
本文主要介绍第一种方式的配置方法,第二种方式感兴趣的同学可在「袋鼠云客户数据洞察平台」内自行探索。进入到群组分析内的标签圈群模块,设置好我们上方提到的群组1的圈群条件,如下图所示:
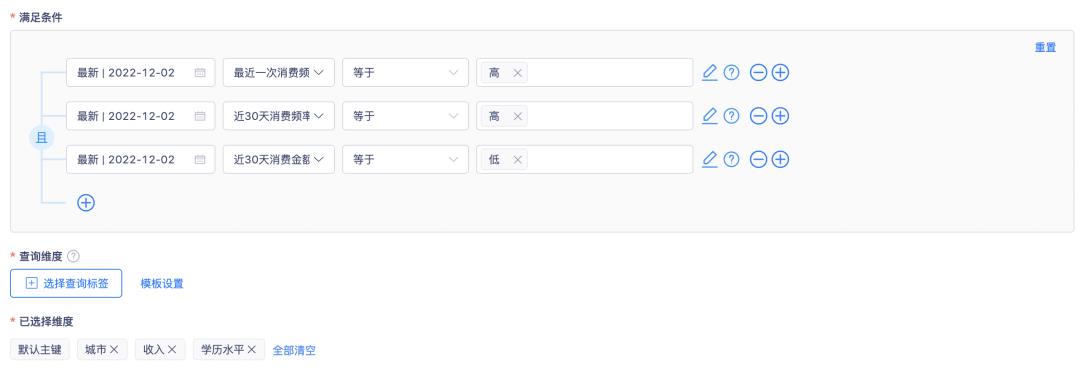
设置好群组规则后,开始进行圈群动作,平台会向你提供所有的群体实例信息,你可以将其保存为群组后后续实时关注群组变化,也可快速进行群组画像、显著性分析、群组对比等群组分析洞察。
总结
以上,就是 RFM 模型在「袋鼠云客户数据洞察平台」的实战演练。除了 RFM 模型,客户数据洞察平台也可以落地其他典型的用户分析模型,如 AARRR 模型、PLC 模型、AIPL 模型等。
在实际使用中,多模型组合分析也是重要的分析洞察内容,后续将陆续为大家呈现更多的模型加工与分析的实操内容,欢迎关注。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
数据挖掘应用案例:RFM模型分析与客户细分
正好刚帮某电信行业完成一个数据挖掘工作,其中的RFM模型还是有一定代表性,就再把数据挖掘RFM模型的建模思路细节与大家分享一下吧!手机充值业务是一项主要电信业务形式,客户的充值行为记录正好满足RFM模型的交易数据要求。
根据美国数据库营销研究所ArthurHughes的研究,客户数据库中有三个神奇的要素,这三个要素构成了数据分析最好的指标:最近一次消费(Recency)、消费频率(Frequency)、消费金额(Monetary)。
RFM模型:R(Recency)表示客户最近一次购买的时间有多远,F(Frequency)表示客户在最近一段时间内购买的次数,M(Monetary)表示客户在最近一段时间内购买的金额。一般原始数据为3个字段:客户ID、购买时间(日期格式)、购买金额,用数据挖掘软件处理,加权(考虑权重)得到RFM得分,进而可以进行客户细分,客户等级分类,CustomerLevelValue得分排序等,实现数据库营销!
这里借用@数据挖掘与数据分析 的RFM客户RFM分类图。
本次分析用的的软件工具:IBMSPSSStatistics19,IBMSPSSModeler14.1,Tableau7.0,EXCEL和PPT
因为RFM分析仅是项目的一个小部分分析,但也面临海量数据的处理能力,这一点对计算机的内存和硬盘容量都有要求。
先说说对海量数据挖掘和数据处理的几点体会:(仅指个人电脑操作平台而言)
1、一般我们拿到的数据都是压缩格式的文本文件,需要解压缩,都在G字节以上存储单位,一般最好在外置电源移动硬盘存储;如果客户不告知,你大概是不知道有多少记录和字段的;
2、Modeler挖掘软件默认安装一般都需要与C盘进行数据交换,至少需要100G空间预留,否则读取数据过程中将造成空间不足
3、海量数据处理要有耐心,等待30分钟以上运行出结果是常有的现象,特别是在进行抽样、合并数据、数据重构、神经网络建模过程中,要有韧性,否则差一分钟中断就悲剧了,呵呵;
4、数据挖掘的准备阶段和数据预处理时间占整个项目的70%,我这里说如果是超大数据集可能时间要占到90%以上。一方面是处理费时,一方面可能就只能这台电脑处理,不能几台电脑同时操作;
5、多带来不同,这是我一直强调的体验。所以海量数据需要用到抽样技术,用来查看数据和预操作,记住:有时候即使样本数据正常,也可能全部数据有问题。建议数据分隔符采用“|”存储;
6、如何强调一个数据挖掘项目和挖掘工程师对行业的理解和业务的洞察都不为过,好的数据挖掘一定是市场导向的,当然也需要IT人员与市场人员有好的沟通机制;
数据挖掘会面临数据字典和语义层含义理解,在MetaData元数据管理和理解上7、下功夫会事半功倍,否则等数据重构完成发现问题又要推倒重来,悲剧;
8、每次海量大数据挖掘工作时都是我上微博最多的时侯,它真的没我算的快,只好上微博等它,哈哈!
传统RFM分析转换为电信业务RFM分析主要思考:

这里的RFM模型和进而细分客户仅是数据挖掘项目的一个小部分,假定我们拿到一个月的客户充值行为数据集(实际上有六个月的数据),我们们先用IBMModeler软件构建一个分析流:
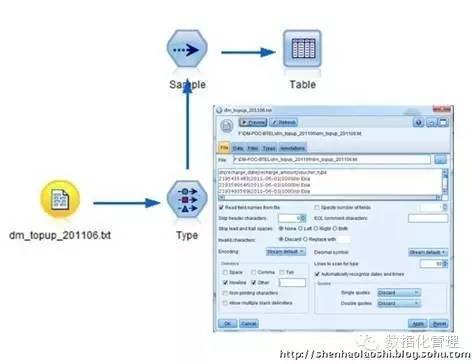
数据结构完全满足RFM分析要求,一个月的数据就有3千万条交易记录!
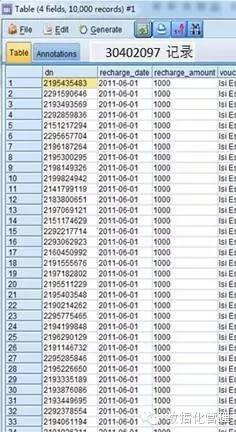
我们先用挖掘工具的RFM模型的RFM汇总节点和RFM分析节点产生R(Recency)、F(Frequency)、M(Monetary);
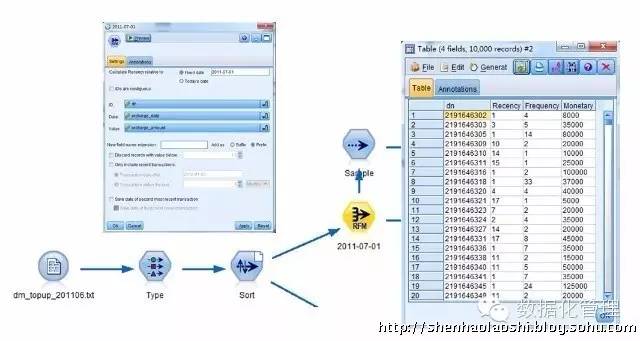
接着我们采用RFM分析节点就完成了RFM模型基础数据重构和整理;
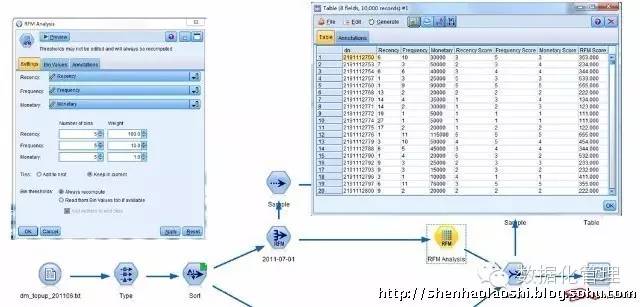
现在我们得到了RFM模型的Recency_Score、Frequency_Score、Monetary_Score和RFM_Score;这里对RFM得分进行了五等分切割,采用100、10、1加权得到RFM得分表明了125个RFM魔方块。
传统的RFM模型到此也就完成了,但125个细分市场太多啦无法针对性营销也需要识别客户特征和行为,有必要进一步细分客户群;
另外:RFM模型其实仅仅是一种数据处理方法,采用数据重构技术同样可以完成,只是这里固化了RFM模块更简单直接,但我们可以采用RFM构建数据的方式不为RFM也可用该模块进行数据重构。
我们可以将得到的数据导入到Tableau软件进行描述性分析:(数据挖掘软件在描述性和制表输出方面非常弱智,哈哈)
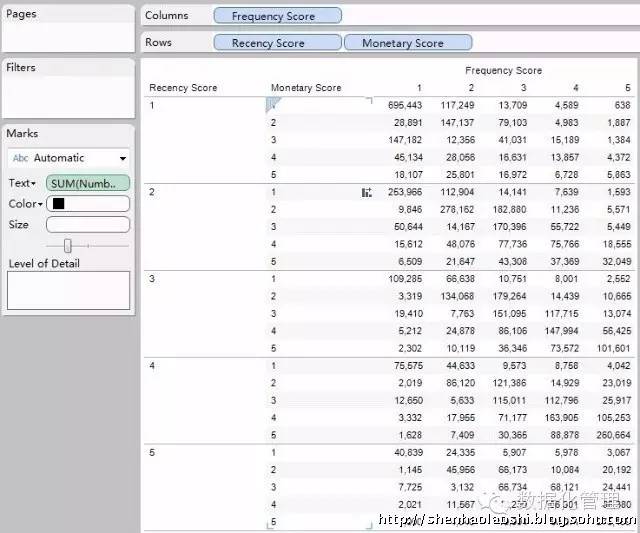
我们也可以进行不同块的对比分析:均值分析、块类别分析等等
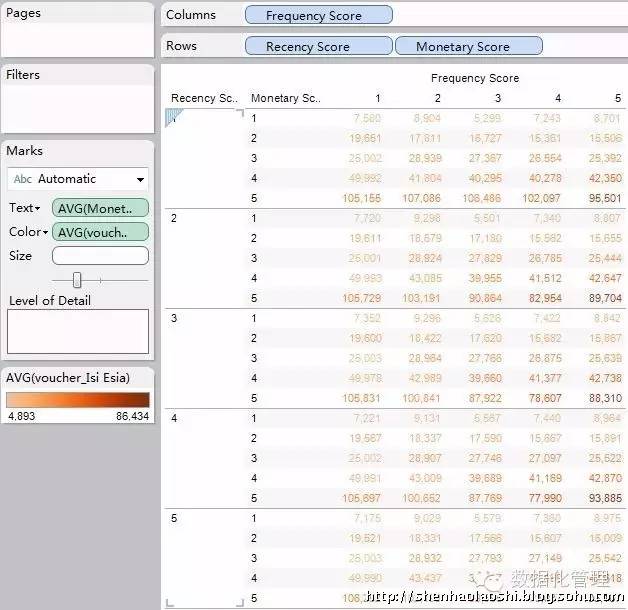
这时候我们就可以看出Tableau可视化工具的方便性
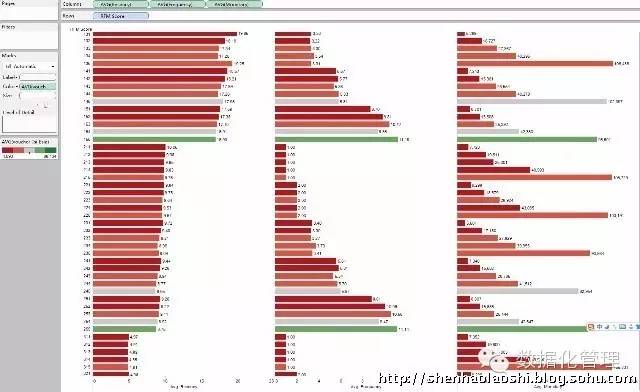
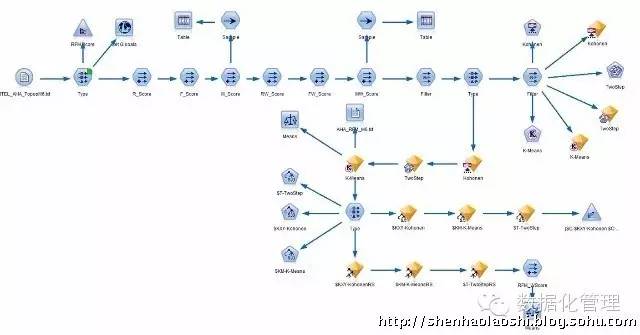
接下来,我们继续采用挖掘工具对R、F、M三个字段进行聚类分析,聚类分析主要采用:Kohonen、K-means和Two-step算法:
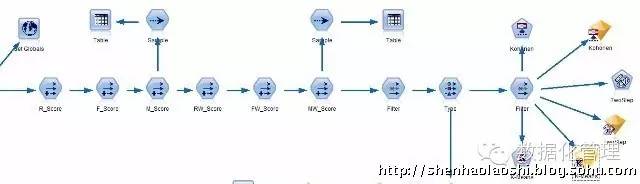
这时候我们要考虑是直接用R(Recency)、F(Frequency)、M(Monetary)三个变量还是要进行变换,因为R、F、M三个字段的测量尺度不同最好对三个变量进行标准化,例如:Z得分(实际情况可以选择线性插值法,比较法,对标法等标准化)!另外一个考虑:就是R、F、M三个指标的权重该如何考虑,在现实营销中这三个指标重要性显然不同!
有资料研究表明:对RFM各变量的指标权重问题,Hughes,Arthur认为RFM在衡量一个问题上的权重是一致的,因而并没有给予不同的划分。而Stone,Bob通过对信用卡的实证分析,认为各个指标的权重并不相同,应该给予频度最高,近度次之,值度最低的权重;
这里我们采用加权方法:WR=2WF=3WM=5的简单加权法(实际情况需要专家或营销人员测定);具体选择哪种聚类方法和聚类数需要反复测试和评估,同时也要比较三种方法哪种方式更理想!
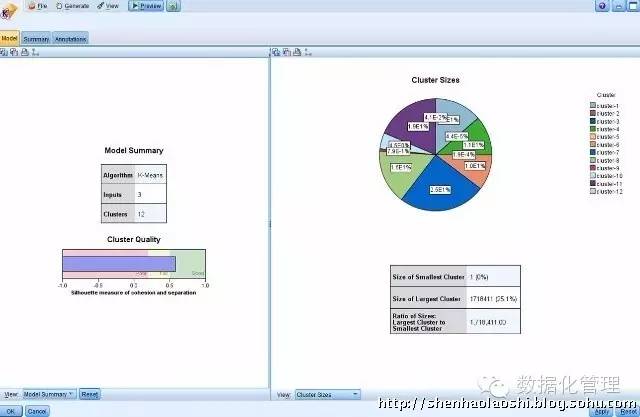
下图是采用快速聚类的结果:
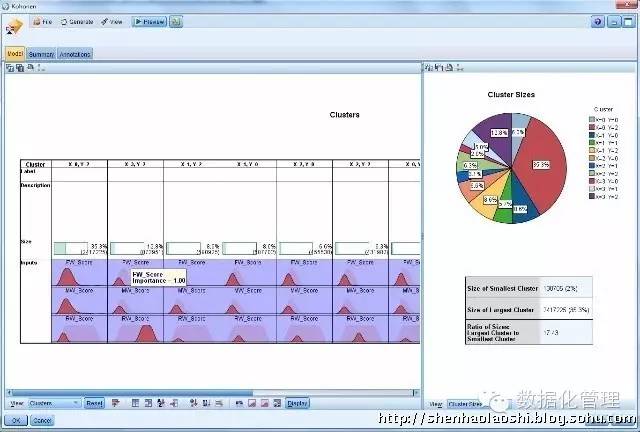
以及kohonen神经算法的聚类结果:
接下来我们要识别聚类结果的意义和类分析:这里我们可以采用C5.0规则来识别不同聚类的特征:
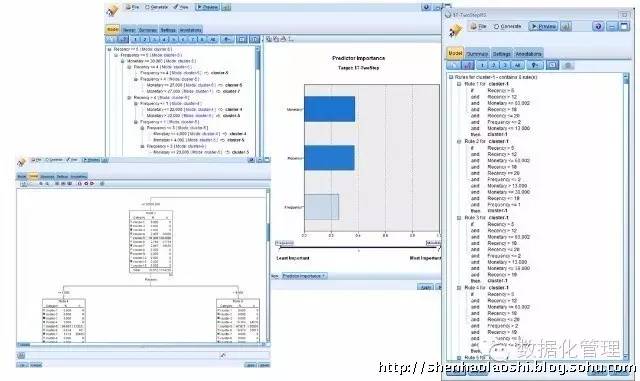
其中Two-step两阶段聚类特征图:
采用评估分析节点对C5.0规则的模型识别能力进行判断:
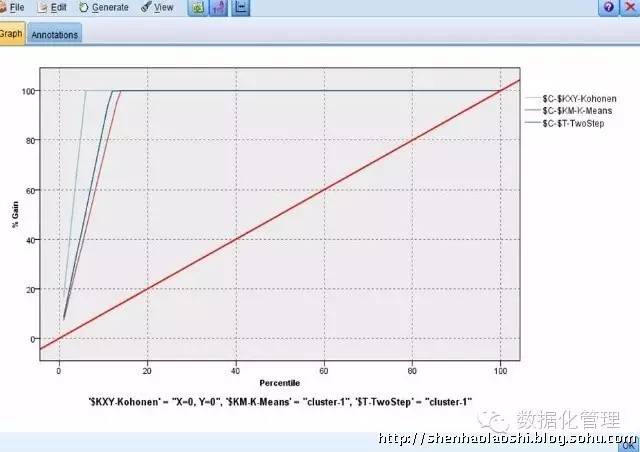
结果还不错,我们可以分别选择三种聚类方法,或者选择一种更易解释的聚类结果,这里选择Kohonen的聚类结果将聚类字段写入数据集后,为方便我们将数据导入SPSS软件进行均值分析和输出到Excel软件!
输出结果后将数据导入Excel,将R、F、M三个字段分类与该字段的均值进行比较,利用Excel软件的条件格式给出与均值比较的趋势!结合RFM模型魔方块的分类识别客户类型:通过RFM分析将客户群体划分成重要保持客户、重要发展客户、重要挽留客户、一般重要客户、一般客户、无价值客户等六个级别;(有可能某个级别不存在);
另外一个考虑是针对R、F、M三个指标的标准化得分按聚类结果进行加权计算,然后进行综合得分排名,识别各个类别的客户价值水平;
至此如果我们通过对RFM模型分析和进行的客户细分满意的话,可能分析就此结束!如果我们还有客户背景资料信息库,可以将聚类结果和RFM得分作为自变量进行其他数据挖掘建模工作!
以上是关于理论+实操|一文掌握 RFM 模型在客户数据洞察平台内的落地实战的主要内容,如果未能解决你的问题,请参考以下文章