Flink基础原理
Posted miller.zc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink基础原理相关的知识,希望对你有一定的参考价值。
一、Flink的概述
我感觉就是一个实时的流处理程序,可以实时的从数据源读取数据,然后根据设置好的一系列算法,
对数据进行处理,最终输出到目的存储介质(数据库、缓存等)中去,和jdk1.8里面的数据流处理很像,
也有并行流、map、fifter等处理。
二、Flink的基础架构
(1)、流程
flink client(客户端)提交job到jobManager上,这一步实际上就会对我们提交的程序进行一次解析,
解析成StreamGraph ,然后优化成JobGraph。
也就是最基本的数据流程图,从数据源—中间一系列的算法——存储。
jobManager里面包含两个组件,一个是JobMaster 一个是ResourceManager(资源管理器)。
JobMaster 负责处理单独的作业(Job),负责将JobGraph转换成一个物理层面的数据流图(ExecutionGraph)。
ExecutionGraph相对于JobGraph来说,就是具体到了每个算子在哪些taskManager上的slot上执行。
同时JobMaster还要向ResourceManager去请求资源,ResourceManager按照配置生成多个taskManager,
每个taskManager向ResourceManager上注册slot。
也就是告诉ResourceManager每个taskManager有多少个插槽。
JobMaster 请求到资源之后,就会将job分解成subtask提交到每个taskManager的多个slot上执行,
slot实际上就是对taskManager进行了内存划分,taskManager就是一个jvm进程。

(2)、数据流图的优化和解析过程
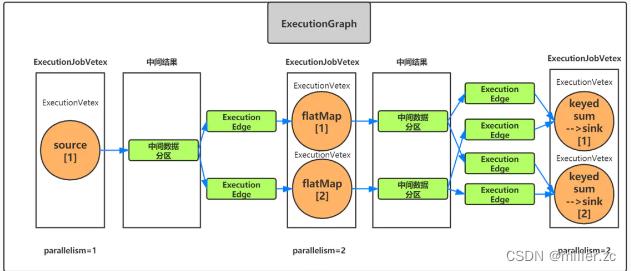
第一步在flink client上会按照程序里面的逻辑解析成StreamGraph (数据流图),对整个task任务做一个总体的描述。

第二步,由flinkClient依据StreamGraph 进行优化,将数据不需要跨taskmanager进行分组聚合等操作的(One-to-One关系),比较简单的直接流向后一个算子的这种,合并成一个subtask。也就是优化过后的JobGraph。

第三步,由JobMaster 将JobGraph进行并行化解析,也就是根据每个算子的并行度进行描述。
(3)、Task slot
flink的TM就是运行在不同节点上的JVM进程,每个进程会拥有一定量的资源。
比如内存,cpu,网络,磁盘等。flink将进程的内存进行了划分到多个slot中.比如2个TaskManager,每个TM有3个slot的,每个slot占有1/3的内存。

内存被划分到不同的slot之后的好处:
<1>、TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量。
<2>、slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
<3>、slot之间可以共享JVM资源, 可以共享Dataset和数据结构,也可以通过多路复用
槽slot共享:
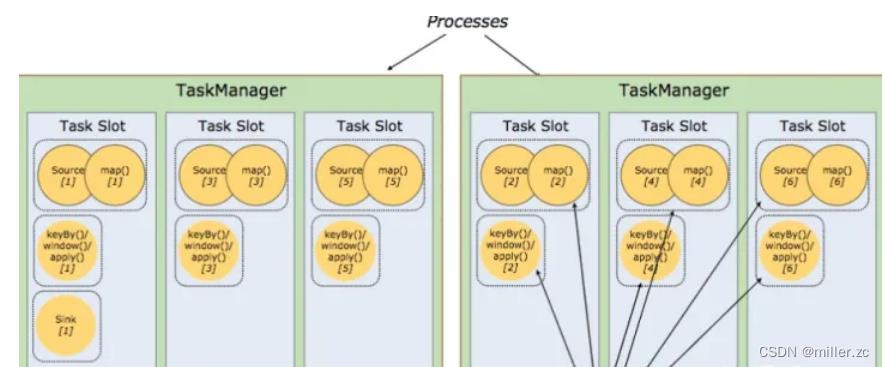
允许同一个job下的subtask(子任务,也就是分解出来的各个算子)可以共享slot,这样可以使得同一个slot运行整个job(每个task)的流水线(pipleline)
好处有点和java里面的fork-join多线程框架有点像,都是可以最大程度的利用空闲资源进行任务执行。
上面图片中有两个 Task Manager,每个 Task Manager 有三个 slot,这样算子最大并行度那么就是 6 个,在同一个 slot 里面可以执行多个子任务(subtask,并且有些算子进行了优化,合并为了一个subtask)。
source/map/keyby/window/apply 最大可以有 6 个并行度,sink 只用了 1 个并行度。
一般 slot 数是每个 TaskManager 的 cpu 的核数。
三、Flink如何保证数据精确一次性
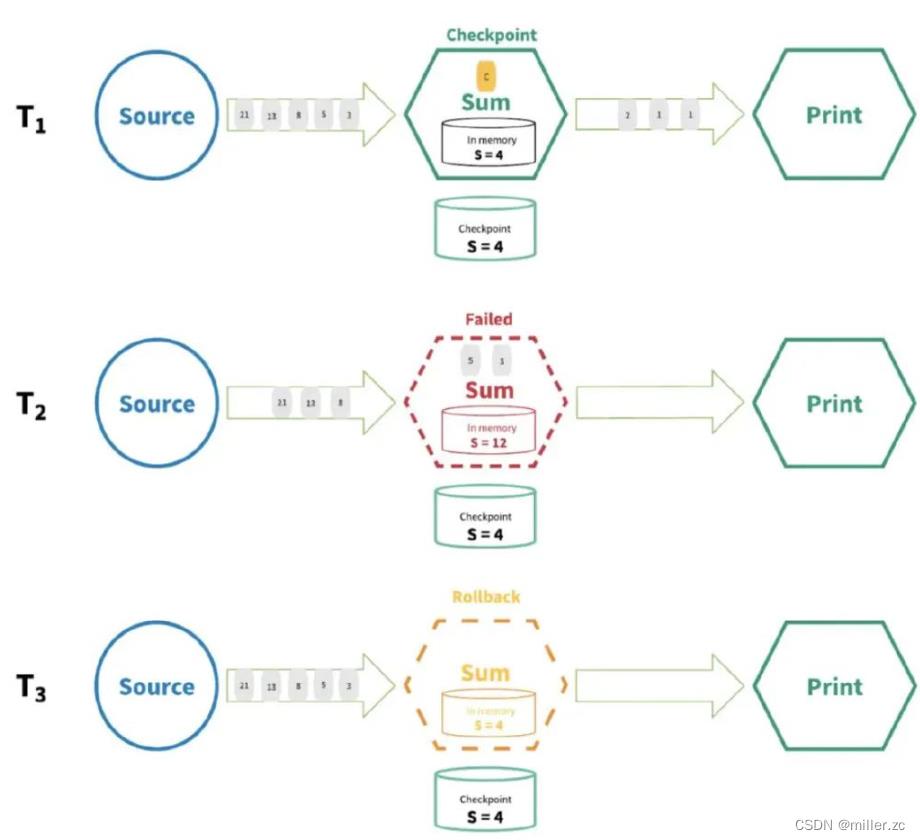
状态只持久化一次到最终的存储介质中,实现原理实际上和kafka的消费者保持最终一致性很像。
也就是每次计算之后,存储到最终的介质上才算计算成功,才会把当前的数据更新到checkponit。
如果中途出了问题,重试的时候会从checkponit(类似于kafka的offest)重新开始。
一个完整的流计算,在每个阶段的算子都会上报barrier,更新checkponit的依据是:sink都上报了barrier
四、Flink背压
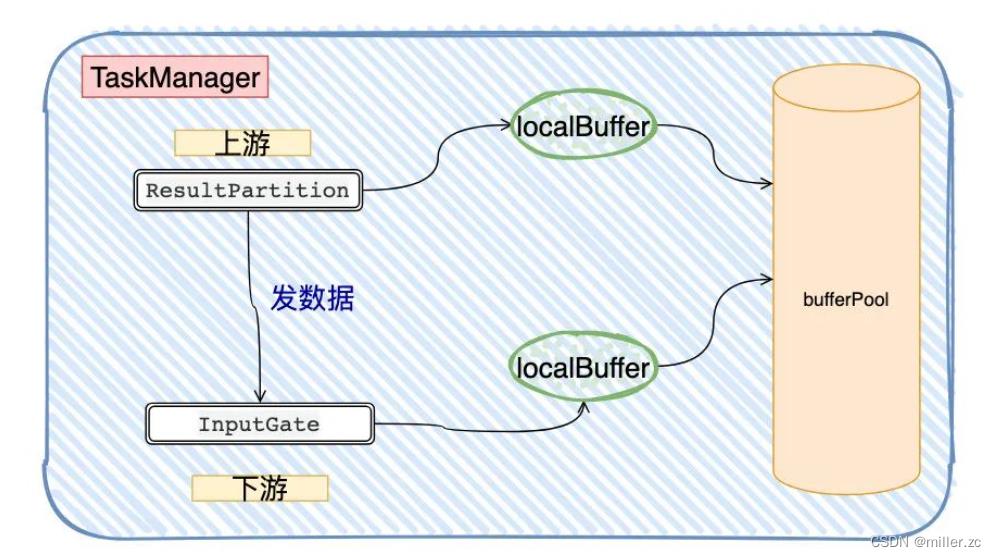
实际上就是每个算子的读写操作都有自己的有界阻塞队列,满了就堵住呗,形成连锁反应一直堵到源头。

远程通信用的Netty,底层是TCP Socket来实现的,从宏观的角度看,多个TaskManager只不过多了两个Buffer(缓冲区)
只要InputGate的LocalBuffer被打满,Netty Buffer也迟早被打满,而Socket Buffer同样迟早也会被打满(TCP 本身就带有流量控制),再反馈到ResultPartition上,数据又又又发不出去了…导致整条数据链路都存在反压的现象。
一个TaskManager的task有多个,共用一个TCP Buffer/Buffer Pool,那只要其中一个task的链路有问题,会导致整个TaskManager跟着挂。
所以在实际的处理中用了credit机制,简单理解为以「更细粒度」去做流量控制,通过InputGate和ResultPartition来做阻塞队列。
以上是关于Flink基础原理的主要内容,如果未能解决你的问题,请参考以下文章