零基础学Flink:Join两个流
Posted 麒思妙想
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零基础学Flink:Join两个流相关的知识,希望对你有一定的参考价值。
《零基础学Flink》这个系列已经做了不少篇了,接下来几章会更加贴近案例来说明一些功能,今天我们先来说说如何将两个流join起来。这次我们以实时汇率和订单流合并为最后牌价为案例,进行说明。
案例代码存放在 https://github.com/dafei1288/flink_casestudy
原理介绍
首先流和流的Join的基本原理和表之间join是一样的,但是由于窗口本身性质的原因,流和流Join还是分为以下几个类型。
下图是滚动窗口合并,每个窗口内,数据独立合并,没有重叠。
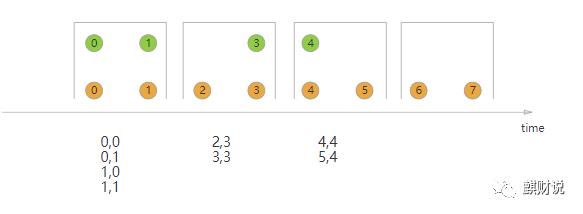
下图是滑动窗口合并,每个窗口内,数据独立合并,由于滑动窗口,有数据重叠。

下图是Session窗口合并,在会话间隙为一个窗口,窗口内数据独立计算。

下图是间隔关联合并,在时间流上下界,数据合并,有部分数据重叠。
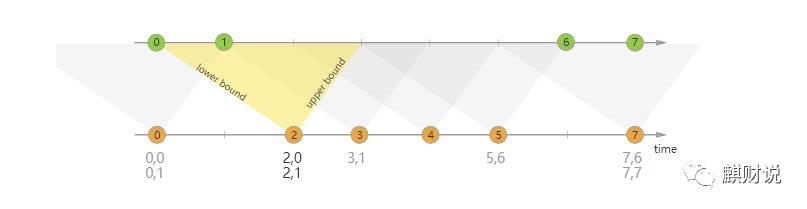
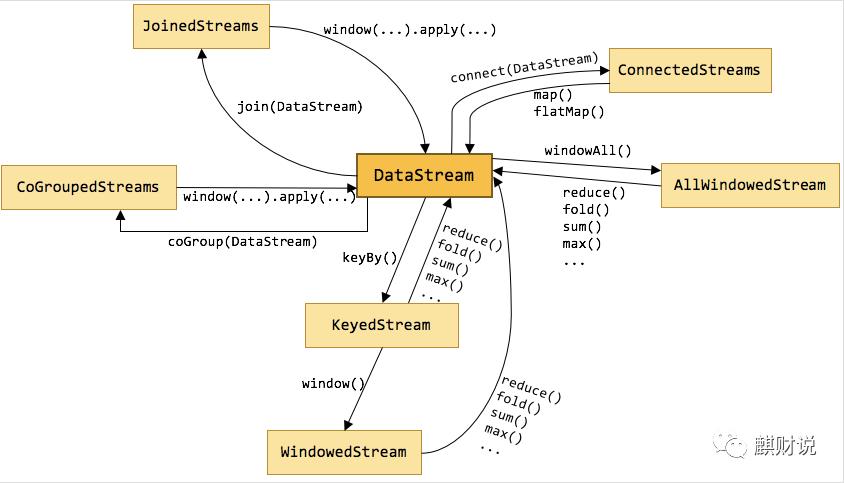
官方文档的这几张图,还是很清晰的说明的这几个连接的情况的。另外对datastream的转换对应关系,下图还是讲述的比较清晰的。
案例
我们构建来2个数据流,一条为实时汇率,一条为订单流,两条流合并,订单价格*汇率计算出最终价格。
本次案例,我们还是先用flink sink到kafka(有兴趣的同学,可以翻阅之前的文章,有详细说明),然后再消费kafka的数据。
下面为订单流,订单包括字段
时间戳(Long)
商品大类(String)
商品细目(Integer)
货币类型(String)
价格(Integer)
package dummy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
public class OrderWriter
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Map prop = new HashMap();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("topic", "order");
ParameterTool parameterTool = ParameterTool.fromMap(prop);
DataStream<String> messageStream = env.addSource(new SourceFunction<String>()
private Random r = new Random();
private static final long serialVersionUID = 1L;
boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception
while(running)
Thread.sleep(r.nextInt(1500));
char catlog = (char) (65 + r.nextInt(5));
ctx.collect(String.format("%d,%s,%d,%s,%d", System.currentTimeMillis(), String.valueOf(catlog), r.nextInt(5), RateWriter.HBDM[r.nextInt(RateWriter.HBDM.length)], r.nextInt(1000)));
@Override
public void cancel()
running = false;
);
DataStreamSink<String> airQualityVODataStreamSink = messageStream.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("bootstrap.servers"),
parameterTool.getRequired("topic"),
new SimpleStringSchema()));
messageStream.print();
env.execute("write order to kafka !!!");
下面为汇率,订单包括字段,这里为了简单,我们将汇率定义为整形了
时间戳(Long)
货币类型(String)
汇率(Integer)
汇率定义为以下几个类型
"BEF","CNY","DEM","EUR","HKD","USD","ITL";
package dummy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
public class RateWriter
public static final String[] HBDM = "BEF","CNY","DEM","EUR","HKD","USD","ITL";
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Map prop = new HashMap();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("topic", "rate");
ParameterTool parameterTool = ParameterTool.fromMap(prop);
DataStream<String> messageStream = env.addSource(new SourceFunction<String>()
private Random r = new Random();
private static final long serialVersionUID = 1L;
boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception
while(running)
Thread.sleep(r.nextInt(3) * 1000);
ctx.collect(String.format("%d,%s,%d", System.currentTimeMillis(), HBDM[r.nextInt(HBDM.length)], r.nextInt(20)));
@Override
public void cancel()
running = false;
);
DataStreamSink<String> airQualityVODataStreamSink = messageStream.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("bootstrap.servers"),
parameterTool.getRequired("topic"),
new SimpleStringSchema()));
messageStream.print();
env.execute("write rate to kafka !!!");
下面为合并的具体代码:
package cn.flinkhub.ratedemo;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.*;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class App
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Map properties= new HashMap();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "test");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
// properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("topicOrder", "order");
properties.put("topicRate", "rate");
ParameterTool parameterTool = ParameterTool.fromMap(properties);
FlinkKafkaConsumer010 consumer010Rate = new FlinkKafkaConsumer010(
parameterTool.getRequired("topicRate"), new DeserializationSchema()
@Override
public TypeInformation getProducedType()
return TypeInformation.of(new TypeHint<Tuple3<Long,String,Integer>>());
//return TypeInformation.of(new TypeHint<Tuple>());
@Override
public Tuple3<Long,String,Integer> deserialize(byte[] message) throws IOException
String[] res = new String(message).split(",");
Long timestamp = Long.valueOf(res[0]);
String dm = res[1];
Integer value = Integer.valueOf(res[2]);
return Tuple3.of(timestamp,dm,value);
@Override
public boolean isEndOfStream(Object nextElement)
return false;
, parameterTool.getProperties());
FlinkKafkaConsumer010 consumer010Order = new FlinkKafkaConsumer010(
parameterTool.getRequired("topicOrder"), new DeserializationSchema()
@Override
public TypeInformation getProducedType()
return TypeInformation.of(new TypeHint<Tuple5<Long,String,Integer,String,Integer>>());
@Override
public Tuple5<Long,String,Integer,String,Integer> deserialize(byte[] message) throws IOException
//%d,%s,%d,%s,%d
String[] res = new String(message).split(",");
Long timestamp = Long.valueOf(res[0]);
String catlog = res[1];
Integer subcat = Integer.valueOf(res[2]);
String dm = res[3];
Integer value = Integer.valueOf(res[4]);
return Tuple5.of(timestamp,catlog,subcat,dm,value);
@Override
public boolean isEndOfStream(Object nextElement)
return false;
, parameterTool.getProperties());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
DataStream<Tuple3<Long,String,Integer>> rateStream = env.addSource(consumer010Rate);
DataStream<Tuple5<Long,String,Integer,String,Integer>> oraderStream = env.addSource(consumer010Order);
long delay = 1000;
DataStream<Tuple3<Long,String,Integer>> rateTimedStream = rateStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple3<Long,String,Integer>>(Time.milliseconds(delay))
@Override
public long extractTimestamp(Tuple3<Long, String, Integer> element)
return (Long)element.getField(0);
);
DataStream<Tuple5<Long,String,Integer,String,Integer>> oraderTimedStream = oraderStream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple5<Long,String,Integer,String,Integer>>()
@Override
public long extractAscendingTimestamp(Tuple5 value)
return (Long)value.getField(0);
);
DataStream<Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer>> joinedStream = oraderTimedStream.join(rateTimedStream).where(new KeySelector<Tuple5<Long,String,Integer,String,Integer>,String>()
@Override
public String getKey(Tuple5<Long,String,Integer,String,Integer> value) throws Exception
// System.out.println(value.getField(3).toString());
return value.getField(3).toString();
).equalTo(new KeySelector<Tuple3<Long,String,Integer>,String>()
@Override
public String getKey(Tuple3<Long,String,Integer> value) throws Exception
// System.out.println(value.getField(1).toString());
return value.getField(1).toString();
).window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new JoinFunction<Tuple5<Long,String,Integer,String,Integer>, Tuple3<Long,String,Integer>,Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer>>()
@Override
public Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer> join( Tuple5<Long,String,Integer,String,Integer> first, Tuple3<Long,String,Integer>second) throws Exception
Integer res = (Integer)second.getField(2)*(Integer)first.getField(4);
return Tuple9.of(first.f0,first.f1,first.f2,first.f3,first.f4,second.f0,second.f1,second.f2,res);
);
joinedStream.print();
env.execute("done!");
首先,我们再消费kafka数据流的时候,定义个一个匿名类来规定如何消费数据,这里我们将数据切分成元组。
new DeserializationSchema()
@Override
public TypeInformation getProducedType()
return TypeInformation.of(new TypeHint<Tuple3<Long,String,Integer>>());
//return TypeInformation.of(new TypeHint<Tuple>());
@Override
public Tuple3<Long,String,Integer> deserialize(byte[] message) throws IOException
String[] res = new String(message).split(",");
Long timestamp = Long.valueOf(res[0]);
String dm = res[1];
Integer value = Integer.valueOf(res[2]);
return Tuple3.of(timestamp,dm,value);
@Override
public boolean isEndOfStream(Object nextElement)
return false;
然后为两个流添加事件时间。
DataStream<Tuple3<Long,String,Integer>> rateTimedStream = rateStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple3<Long,String,Integer>>(Time.milliseconds(delay))
@Override
public long extractTimestamp(Tuple3<Long, String, Integer> element)
return (Long)element.getField(0);
);
DataStream<Tuple5<Long,String,Integer,String,Integer>> oraderTimedStream = oraderStream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple5<Long,String,Integer,String,Integer>>()
@Override
public long extractAscendingTimestamp(Tuple5 value)
return (Long)value.getField(0);
);
接下来,就是将两条流合并起来,要再where和equalTo的两个方法里,设置连接条件,然后通过window设置时间窗口,通过apply方法将join的数据最后结果拼装起来。
DataStream<Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer>> joinedStream = oraderTimedStream.join(rateTimedStream).where(new KeySelector<Tuple5<Long,String,Integer,String,Integer>,String>()
@Override
public String getKey(Tuple5<Long,String,Integer,String,Integer> value) throws Exception
// System.out.println(value.getField(3).toString());
return value.getField(3).toString();
).equalTo(new KeySelector<Tuple3<Long,String,Integer>,String>()
@Override
public String getKey(Tuple3<Long,String,Integer> value) throws Exception
// System.out.println(value.getField(1).toString());
return value.getField(1).toString();
).window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new JoinFunction<Tuple5<Long,String,Integer,String,Integer>, Tuple3<Long,String,Integer>,Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer>>()
@Override
public Tuple9<Long,String,Integer,String,Integer,Long,String,Integer,Integer> join( Tuple5<Long,String,Integer,String,Integer> first, Tuple3<Long,String,Integer>second) throws Exception
Integer res = (Integer)second.getField(2)*(Integer)first.getField(4);
return Tuple9.of(first.f0,first.f1,first.f2,first.f3,first.f4,second.f0,second.f1,second.f2,res);
);
下面来看看执行效果
生成订单流数据:
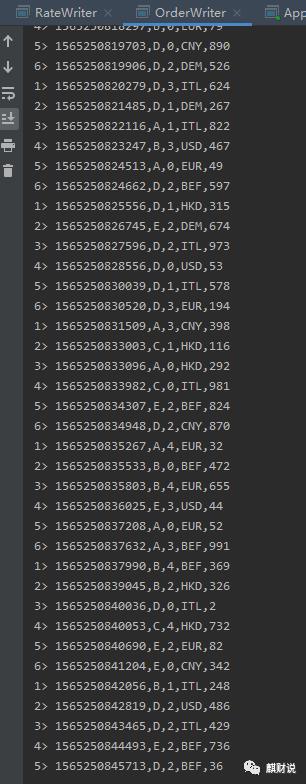
生成汇率流数据:
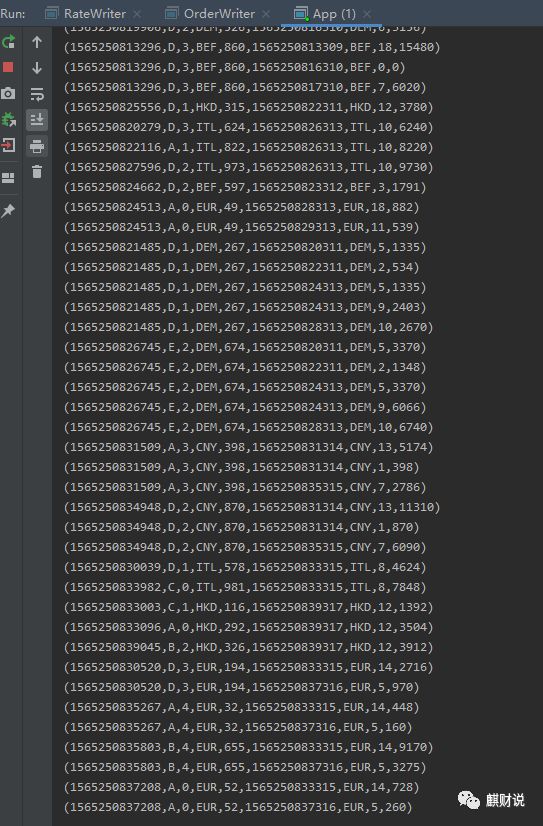
合并后的结果数据流
好了,今天的案例就讲解到这里,下次我计划来说一说,如何统计计算实时热门Top5
参考连接:
https://ci.apache.org/projects/flink/flink-docs-master/dev/stream/operators/joining.html
http://wuchong.me/blog/2018/11/07/use-flink-calculate-hot-items/
以上是关于零基础学Flink:Join两个流的主要内容,如果未能解决你的问题,请参考以下文章