语音识别系列︱利用达摩院ModelScope进行语音识别+标点修复
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音识别系列︱利用达摩院ModelScope进行语音识别+标点修复相关的知识,希望对你有一定的参考价值。
终于有时间更新语音识别系列了,之前的几篇:
语音识别系列︱用python进行音频解析(一)
语音识别系列︱paddlehub的开源语音识别模型测试(二)
语音识别系列︱paddlespeech的开源语音识别模型测试(三)
文章目录
1 达摩院ModelScope

官方地址:https://www.modelscope.cn/home
github地址:https://github.com/modelscope/modelscope
在 2022 云栖大会杭州现场,阿里达摩院与 CCF 开源发展委员会共同推出 AI 模型社区“魔搭”ModelScope。同时,达摩院向魔搭社区贡献 300 多个 AI 模型,超过 1/3 为中文模型,全面开源开放。
魔搭社区首批开源模型超过 300 个,包括视觉、语音、自然语言处理、多模态等 AI 主要方向,并向 AI for Science 等新领域探索,覆盖的主流任务超过 60 个。模型均经过筛选和效果验证,包括 150 多个 SOTA 模型和 10 多个大模型,全面开源且开放使用。
据介绍,魔搭社区 ModelScope 践行模型即服务的新理念(Model as a Service),提供众多预训练基础模型,只需针对具体场景再稍作调优,就能快速投入使用。
此外,社区目前已上架的中文模型超过 100 个,占比超过 1/3,包括一批中文大模型,如阿里通义大模型系列、澜舟科技的孟子系列模型、智谱 AI 的中英双语千亿大模型等。
2 基本库 + docker安装
笔者是魔搭上线没几天就开始测试,但是一开始没有放docker链接,所以自己搞了半天,发现tf1.15 + py3.7 +pytorch1.11 挺麻烦。
最近开放了cpu/gpu的docker,不多说:良心!
CPU环境镜像(版本号:1.0.2):
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-py37-torch1.11.0-tf1.15.5-1.0.2
GPU环境镜像(版本号:1.0.2):
registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py37-torch1.11.0-tf1.15.5-1.0.2
其他基本库:
语音领域中一部分模型使用了三方库SoundFile进行wav文件处理,在Linux系统上用户需要手动安装SoundFile的底层依赖库libsndfile,在Windows和MacOS上会自动安装不需要用户操作。详细信息可参考SoundFile官网。以Ubuntu系统为例,用户需要执行如下命令:
sudo apt-get update
sudo apt-get install libsndfile1
如仅需体验语音领域模型,请执行如下命令:
pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
3 语音识别模型
语音识别模型挺多的,看下载量就大概知道大众的选择了
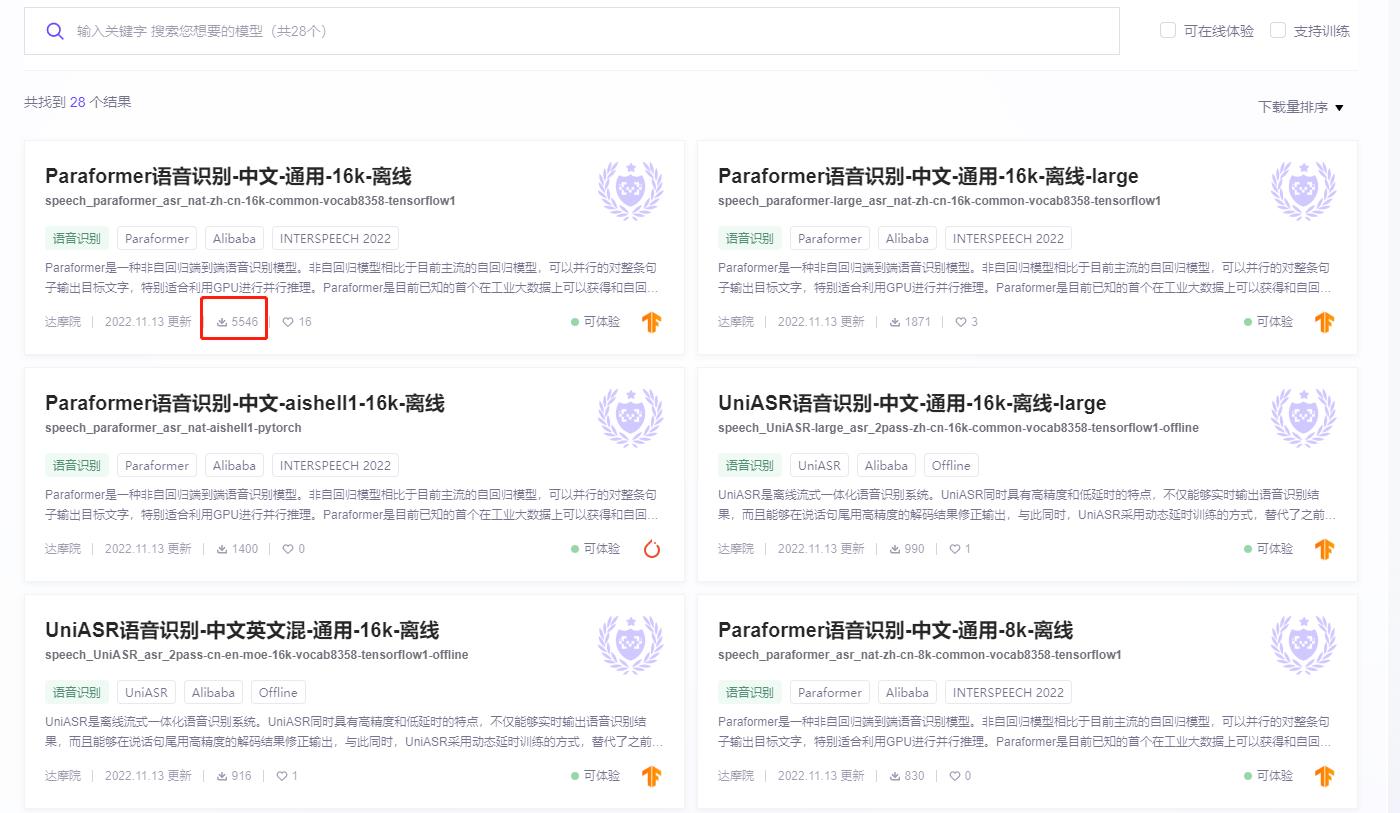
从精度来看,笔者测试下来最好的是:
3.1 Paraformer语音识别-中文-通用-16k-离线-large
针对Transoformer模型自回归生成文字的低计算效率缺陷,学术界提出了非自回归模型来并行的输出目标文字。根据生成目标文字时,迭代轮数,非自回归模型分为:多轮迭代式与单轮迭代非自回归模型。
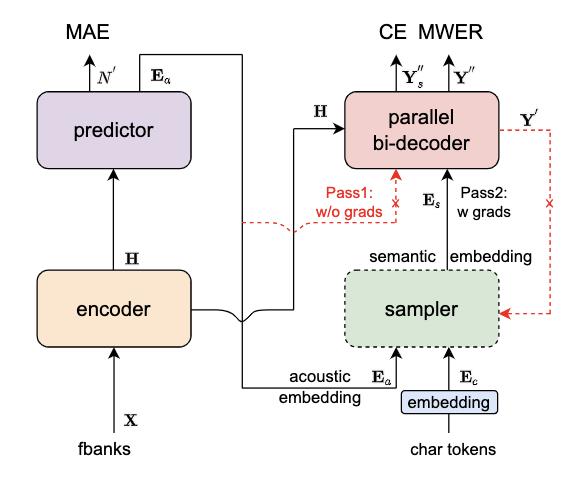
其核心点主要有:
Predictor 模块:基于 CIF 的 Predictor 来预测语音中目标文字个数以及抽取目标文字对应的声学特征向量
Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力
基于负样本采样的 MWER 训练准则
运行范围
现阶段只能在Linux-x86_64运行,不支持Mac和Windows。
使用方式
直接推理:可以直接对输入音频进行解码,输出目标文字。
微调:加载训练好的模型,采用私有或者开源数据进行模型训练。
使用范围与目标场景
适合与离线语音识别场景,如录音文件转写,配合GPU推理效果更加,推荐输入语音时长在20s以下。
模型效果:

api调用:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_16k_pipline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1')
rec_result = inference_16k_pipline(audio_in='https://modelscope.oss-cn-beijing.aliyuncs.com/test/audios/asr_example.wav')
print(rec_result)
pipeline推理:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('auto-speech-recognition', 'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1')
p('http://www.modelscope.cn/api/v1/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1/repo?Revision=master&FilePath=example/asr_example.wav')
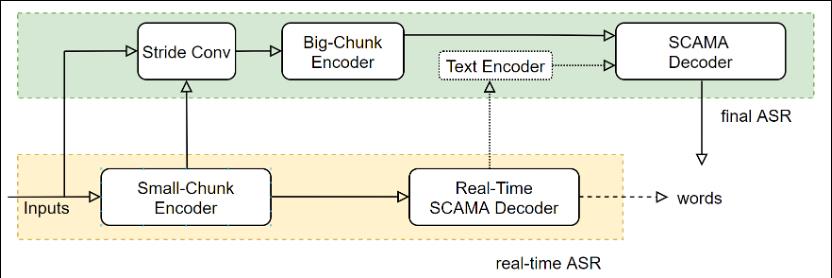
3.2 UniASR语音识别-中文-通用-16k-离线-large
UniASR 模型是一种2遍刷新模型(Two pass)端到端语音识别模型。日益丰富的业务需求,不仅要求识别效果精度高,而且要求能够实时地进行语音识别。一方面,离线语音识别系统具有较高的识别准确率,但其无法实时的返回解码文字结果,并且,在处理长语音时,容易发生解码重复的问题,以及高并发解码超时的问题等;另一方面,流式系统能够低延时的实时进行语音识别,但由于缺少下文信息,流式语音识别系统的准确率不如离线系统,在流式业务场景中,为了更好的折中实时性与准确率,往往采用多个不同时延的模型系统。为了满足差异化业务场景对计算复杂度、实时性和准确率的要求,常用的做法是维护多种语音识别系统,例如,CTC系统、E2E离线系统、SCAMA流式系统等。
运行范围
现阶段只能在Linux-x86_64运行,不支持Mac和Windows。
使用方式
直接推理:可以直接对输入音频进行解码,输出目标文字。
微调:加载训练好的模型,采用私有或者开源数据进行模型训练。
使用范围与目标场景
建议输入语音时长在20s以下。
模型效果:

api调用:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_16k_pipline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline')
rec_result = inference_16k_pipline(audio_in='https://modelscope.oss-cn-beijing.aliyuncs.com/test/audios/asr_example.wav')
print(rec_result)
pipeline推理:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('auto-speech-recognition', 'damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline')
p('http://www.modelscope.cn/api/v1/models/damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline/repo?Revision=master&FilePath=example/asr_example.wav')
4 标点修复、纠错
标点修复模型,阿里没有开源只看到paddle有,当然笔者自己测试的时候,发现魔搭开源的文本纠错也有一定的标点修复功能 + 文本纠错,刚好把两个任务合在一起,有奇效,看客可以自行做选择。
可以结合paddle的标点修复,也可以使用魔搭的文本纠错
语音识别系列︱paddlespeech的开源语音识别模型测试(三)
另外一种可以借助
4.1 解法一:BART文本纠错-中文-通用领域-large
这里的任务变成:
语音识别 + 文本修复->语音识别 + 文本纠错
输入一句中文文本,文本纠错技术对句子中存在拼写、语法、语义等错误进行自动纠正,输出纠正后的文本。
如图所示,我们采用基于transformer的seq2seq方法建模文本纠错任务。模型训练上,我们使用中文BART作为预训练模型,然后在Lang8和HSK训练数据上进行finetune。不引入额外资源的情况下,本模型在NLPCC18测试集上达到了SOTA。
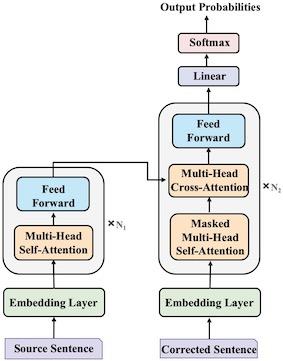
模型效果如下:
输入:这洋的话,下一年的福气来到自己身上。
输出:这样的话,下一年的福气就会来到自己身上。
api调用:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_id = 'damo/nlp_bart_text-error-correction_chinese'
input = '这洋的话,下一年的福气来到自己身上。'
pipeline = pipeline(Tasks.text_error_correction, model=model_id)
result = pipeline(input)
print(result['output'])
pipeline调用:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('text-error-correction', 'damo/nlp_bart_text-error-correction_chinese')
p('这洋的话,下一年的福气来到自己身上。')
4.2 解法二: 智能音频切分:auditok
这里auditok可以按照一定规则进行音频智能切分,那么之前的任务:
语音识别 + 文本修复->智能音频切割 + 语音识别
在paddlehttps://zhuanlan.zhihu.com/p/548494500看到一个有趣的音频切分模块
安装:
!pip install auditok
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting auditok
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/49/3a/8b5579063cfb7ae3e89d40d495f4eff6e9cdefa14096ec0654d6aac52617/auditok-0.2.0-py3-none-any.whl (1.5 MB)
l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.5 MB ? eta -:--:--━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.4/1.5 MB 14.2 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━ 1.3/1.5 MB 19.7 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.5/1.5 MB 15.4 MB/s eta 0:00:00
[?25hInstalling collected packages: auditok
Successfully installed auditok-0.2.0
[notice] A new release of pip available: 22.1.2 -> 22.2
[notice] To update, run: pip install --upgrade pip
然后就是切割代码:
from paddlespeech.cli.asr.infer import ASRExecutor
import csv
import moviepy.editor as mp
import auditok
import os
import paddle
from paddlespeech.cli import ASRExecutor, TextExecutor
import soundfile
import librosa
import warnings
warnings.filterwarnings('ignore')
# 引入auditok库
import auditok
# 输入类别为audio
def qiefen(path, ty='audio', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55):
audio_file = path
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
audio_regions = auditok.split(
audio_file,
min_dur=mmin_dur, # minimum duration of a valid audio event in seconds
max_dur=mmax_dur, # maximum duration of an event
# maximum duration of tolerated continuous silence within an event
max_silence=mmax_silence,
energy_threshold=menergy_threshold # threshold of detection
)
for i, r in enumerate(audio_regions):
# Regions returned by `split` have 'start' and 'end' metadata fields
print(
"Region i: r.meta.start:.3fs -- r.meta.end:.3fs".format(i=i, r=r))
epath = ''
file_pre = str(epath.join(audio_file.split('.')[0].split('/')[-1]))
mk = 'change'
if (os.path.exists(mk) == False):
os.mkdir(mk)
if (os.path.exists(mk + '/' + ty) == False):
os.mkdir(mk + '/' + ty)
if (os.path.exists(mk + '/' + ty + '/' + file_pre) == False):
os.mkdir(mk + '/' + ty + '/' + file_pre)
num = i
# 为了取前三位数字排序
s = '000000' + str(num)
file_save = mk + '/' + ty + '/' + file_pre + '/' + \\
s[-3:] + '-' + 'meta.start:.3f-meta.end:.3f' + '.wav'
filename = r.save(file_save)
print("region saved as: ".format(filename))
return mk + '/' + ty + '/' + file_pre
5 实践
那么最后笔者在第四章节的都用上,那么就是:
语音识别 + 文本修复->智能音频切割 + 语音识别 + 文本纠错
5.1 预装
这里就是结合以上的代码,就不细说,直接贴代码
在docker之中预装一些依赖:
- 语音识别两个模型
- 文本纠错模型
- auditok 依赖
!pip install auditok -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install librosa -i https://mirror.baidu.com/pypi/simple
!pip install soundfile -i https://mirror.baidu.com/pypi/simple
'''
语音识别模型
https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1/quickstart
'''
!pip install auditok -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install librosa -i https://mirror.baidu.com/pypi/simple
!pip install soundfile -i https://mirror.baidu.com/pypi/simple
'''
语音识别模型
https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1/quickstart
'''
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('auto-speech-recognition', 'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1')
p = pipeline('auto-speech-recognition', 'damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline')
#p('http://www.modelscope.cn/api/v1/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1/repo?Revision=master&FilePath=example/asr_example.wav')
'''
文本纠错
https://www.modelscope.cn/models/damo/nlp_bart_text-error-correction_chinese/quickstart
'''
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('text-error-correction', 'damo/nlp_bart_text-error-correction_chinese')
5.2 执行代码
# 引入auditok库
import auditok
import soundfile
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 输入类别为audio
def qiefen(path, ty='audio', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55):
'''
mmin_dur:有效音频事件的最短持续时间(以秒为单位)
mmax_dur:事件最大持续时间
mmax_silence:事件中可容忍的连续静默的最长持续时间
'''
audio_file = path
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
audio_regions = auditok.split(
audio_file,
min_dur=mmin_dur, # minimum duration of a valid audio event in seconds
max_dur=mmax_dur, # maximum duration of an event
# maximum duration of tolerated continuous silence within an event
max_silence=mmax_silence,
energy_threshold=menergy_threshold # threshold of detection
)
for i, r in enumerate(audio_regions):
# Regions returned by `split` have 'start' and 'end' metadata fields
print(
"Region i: r.meta.start:.3fs -- r.meta.end:.3fs".format(i=i, r=r))
epath = ''
file_pre = str(epath.join(audio_file.split('.')[0].split('/')[-1]))
mk = 'change'
if (os.path.exists(mk) == False):
os.mkdir(mk)
if (os.path.exists(mk + '/' + ty) == False):
os.mkdir(mk + '/' + ty)
if (os.path.exists(mk + '/' + ty + '/' + file_pre) == False):
os.mkdir(mk + '/' + ty + '/' + file_pre)
num = i
# 为了取前三位数字排序
s = '000000' + str(num)
file_save = mk + '/' + ty + '/' + file_pre + '/' + \\
s[-3:] + '-' + 'meta.start:.3f-meta.end:.3f' + '.wav'
filename = r.save(file_save)
print("region saved as: ".format(filename))
return mk + '/' + ty + '/' + file_pre
def audio2txt(path,model = 'uniasr'):
# 初始化
if model == 'uniasr':
inference_16k_pipline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline')
elif model == 'paraformer':
inference_16k_pipline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1')
else:
print('no other model...')
# 返回path下所有文件构成的一个list列表
print(f"path: path")
filelist = os.listdir(path)
# 保证读取按照文件的顺序
filelist.sort(key=lambda x: int(os.path.splitext(x)[0][:3]))
# 遍历输出每一个文件的名字和类型
words = []
for file in filelist:
print(path + '/' + file)
# baidu
text = inference_16k_pipline(audio_in=path + '/' + file)
#text = asr_executor(
# audio_file=path + '/' + file,
# device=paddle.get_device(), force_yes=True) # force_yes参数需要注意
words.append(text)
return words
def cut_text(text,cut_len = 200):
'''文本按照每200字进行拆分'''
cut_level = list(range(0,len(text_a) ,cut_len ))
if len(cut_level) == 1:
interval = [[0,len(text_a)]]
else:
cut_level_2 = cut_level + [len(text)]
interval = [[cut_level_2[n] , cut_level_2[n+1] ] for n in range(len(cut_level_2)-1)]
return [ text[x[0]:x[1]] for x in interval]
# 可替换成自身的录音文件
source_path = 'xxxx.wav' # 写成你自己的语音
# 划分音频
path = qiefen(path=source_path, ty='audio',
mmin_dur=1, mmax_dur=100000, mmax_silence=0.5, menergy_threshold=55)
# 识别
text = audio2txt(path,model = 'uniasr')
text_uniasr = ','.join([t['text'] for t in text if t!= ])
text = audio2txt(path,model = 'paraformer')
text_paraformer = ','.join([t['text'] for t in text if t!= ])
# BART文本纠错-中文-通用领域-large
p1 = pipeline('text-error-correction', 'damo/nlp_bart_text-error-correction_chinese')
text_refine = [p1(p) for p in cut_text(text_uniasr,cut_len = 200)]
最终你可以自己观察一下效果,还可以的~
以上是关于语音识别系列︱利用达摩院ModelScope进行语音识别+标点修复的主要内容,如果未能解决你的问题,请参考以下文章
语音识别系列︱利用达摩院ModelScope进行语音识别+标点修复
视频处理系列︱利用达摩院ModelScope进行视频人物分割+背景切换