数据湖:Apache Iceberg在腾讯的探索和实践
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖:Apache Iceberg在腾讯的探索和实践相关的知识,希望对你有一定的参考价值。
摘要:今天分享的是Apache Iceberg在腾讯内部的探索和实践。本文结合腾讯大数据技术分享内容和2020全球软件开发大会分享内容进行整理,主要内容包括:
1、数据湖技术概述
2、Apache Iceberg的简介
3、腾讯为什么选择Apache Iceberg
4、腾讯看点万亿数据下的业务痛点
5、Apache Iceberg在看点实践
6、Apache Iceberg读写和删除

Apache Iceberg
新一代数据湖技术
Apache Iceberg是一种新的表格格式,用于存储移动缓慢的大型表格数据。它旨在改进Hive、Trino和Spark中内置的事实上的标准表布局。
一、数据湖技术概述
数据湖产生的背景:
随着大数据存储和处理需求越来越多样化,如何构建一个统一的存储,并在其上进行多种形式的数据分析,成了企业构建大数据生态的一个重要方向。如何快速、一致、原子性地在存储上构建起 Data Pipeline,成了亟待解决的问题。为此,Uber 开源了 Apache Hudi,Databricks 提出了 Delta Lake,而 Netflix 则发起了 Apache Iceberg 项目。一时间这种具备 ACID 能力的表格式中间件成为了大数据、数据湖领域炙手可热的方向。
腾讯在 2019 年开始投入研发 Apache Iceberg,阿里巴巴也联合 Apache Iceberg 社区积极推动 Flink 实时数据湖技术方案的落地。
那么Apache Iceberg有什么独到之处呢,受到国内两家互联网巨头的青睐?本文跟大家慢慢道来,感兴趣的读者可以关注、收藏哦。
计算引擎之下、存储之上:
数据库大牛、图灵奖获得者 Michael Stonebraker 曾在 MapReduce 诞生之初撰写过一篇文章,题为“MapReduce: A major step backwards”。Michael Stonebraker 在文章中直截了当地指出:MapReduce 忽视了数据库领域积累超过 40 年的技术经验。
虽然大数据技术的出现和迭代降低了用户处理海量数据的门槛,但另一方面,与数据库这样高度优化的技术相比,大数据技术的抽象和实现还是太原始和初级。因此大数据技术在后续十几年的发展中,一直以数据库为目标,将更多数据库的成熟技术和理念借鉴到大数据中。
如何定义这类新技术:
简单地说,这类新技术是介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”。
Iceberg 将其称之为“表格式”,也是表达类似的含义。它与底层的存储格式(比如 ORC、Parquet 之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。它构建在数据存储格式之上,其底层的数据存储仍然使用 Parquet、ORC 等进行存储。
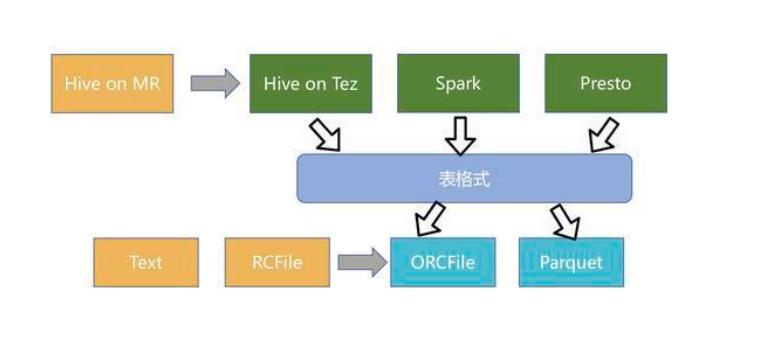
数据湖技术总结:
主要思想:对所有数据统一存储,通过计算能够生成符合要求的各种数据
物理实现:数据存储平台
实现方式:通常基于Hadoop生态,但不仅限于Hadoop
粗暴理解:数据仓库HIVE
数据湖技术的发展及问题:
计算引擎发展:
HIVE on MR → Spark、Presto、Impala
存储格式发展:
Text、RCFile → ORCFile、Parquet
存在问题:
数据读写没有ACID保证
数据没有版本控制
无法高效Update/Delete
分区管理不灵活
二、Apache Iceberg简介
简介:
Apache Iceberg 由Netflix 发起,现已开源到Apache,作为新一代的存储正在飞速的发展中,目前最新版本为V1.0。
Apache Iceberg是一种新的表格格式,用于存储移动缓慢的大型表格数据。它旨在改进Hive、Trino和Spark中内置的事实上的标准表布局。
可靠性、性能:
Iceberg 是为Bigtable而建的。Iceberg 用于生产中,其中单个表可以包含数十 PB 的数据,甚至可以在没有分布式 SQL 引擎的情况下读取这些巨大的表。特点:
扫描计划很快 - 读取表或查找文件不需要分布式 SQL 引擎
高级过滤 - 使用表元数据,使用分区和列级统计信息修剪数据文件
Iceberg 旨在解决最终一致的云对象存储中的正确性问题。
适用于任何云存储,并通过避免列出和重命名来减少HDFS中的NN拥塞
可序列化隔离 - 表更改是原子的,读者永远看不到部分或未提交的更改
多个并发写入程序使用乐观并发,并将重试以确保兼容的更新成功,即使写入发生冲突
Iceberg的优势:
更开放的框架,既独立于上层计算引擎又独立于下层存储
接口抽象程度高,兼容性好,迁移成本低
对各种引擎提供针对性的优化化
Iceberg的劣势:
Iceberg 诞生的时间不长,功能上仍有不足
Iceberg 最重要的缺失点是和上层引擎的对接
Iceberg 缺少行级更新、删除能力
三、腾讯选择Iceberg
Iceberg解决的痛点:
T+0 的数据落地和处理:
传统的数据处理流程从数据入库到数据处理通常需要一个较长的环节、涉及许多复杂的逻辑来保证数据的一致性,由于架构的复杂性使得整个流水线具有明显的延迟。Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟。
降低数据修正的成本:
传统 Hive/Spark 在修正数据时需要将数据读取出来,修改后再写入,有极大的修正成本。Iceberg 所具有的修改、删除能力能够有效地降低开销,提升效率。
技术方面的考量:
Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如 Flink、Hive、Spark)对接
良好的架构和开放的格式。相比于 Hudi、Delta Lake,Iceberg 的架构实现更为优雅,同时对于数据格式、类型系统有完备的定义和可进化的设计
面向对象存储的优化。Iceberg 在数据组织方式上充分考虑了对象存储的特性,避免耗时的 listing 和 rename 操作,使其在基于对象存储的数据湖架构适配上更有优势
四、腾讯看点业务痛点
腾讯看点业务数据已经发展到万亿级别,在这种超大数据量的场景下,会有哪些痛点呢?腾讯技术大牛又是如何解决的呢?
腾讯看点主要内容:

数据来源:

产生的问题:


五、Iceberg在看点实践
通过前期充分调研,结合目前技术、社区等现状,Iceberg当仁不让被选中了。在解决看点业务中Iceberg发挥着怎样的作用呢,一起来看看。
在框架中Iceberg的作用1:

带来的收益1:

在框架中Iceberg的作用2:

带来的收益2:

六、Iceberg读写和删除
Iceberg读写文件:

分区查找优化:

行级删除设计:

写在最后
数据湖技术可谓是时代发展的必然趋势,通过数据湖,用户能够以自己的方式访问和探索数据,无需将数据移入其他系统。不同于定期从其他平台或数据库提取分析报告,数据湖的分析和报告通常可以临时获取。
今天分享的内容先到这里了,欢迎感兴趣的小伙伴关注、交流。让我们站在巨人的肩膀上,不断砥砺前行。
往期回顾

以上是关于数据湖:Apache Iceberg在腾讯的探索和实践的主要内容,如果未能解决你的问题,请参考以下文章