大数据架构变革进行时:为什么腾讯看好开源Apache Iceberg?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据架构变革进行时:为什么腾讯看好开源Apache Iceberg?相关的知识,希望对你有一定的参考价值。
虽然现阶段国内仍然缺乏数据湖概念上的优秀商业方案,但在基础软件开源化的趋势下,国内企业在数据湖技术点上的探索与跟进并不比国外企业落后太多。腾讯在 2018 年加入大数据存储开源项目 Apache Ozone,后又于 2019 年开始投入研发 Apache Iceberg;阿里巴巴也正联合 Apache Iceberg 社区积极推动 Flink 实时数据湖技术方案的落地。那么,Iceberg 和其他两个开源项目有何不同?为什么阿里和腾讯都在积极投入 Iceberg 的开源生态?Iceberg 有什么独到之处?
近期 InfoQ 采访了腾讯数据平台部数据湖内核技术负责人、资深大数据工程师邵赛赛,他与我们分享了腾讯选择 Iceberg 前后的一些思考和采用 Iceberg 之后所做的优化工作,本文基于采访整理而成。邵赛赛还将在 QCon 全球软件开发大会(北京站)2020 带来主题为 《Iceberg - 新一代的数据湖表格式》 的演讲分享,感兴趣的读者可以关注。
数据库大牛、图灵奖获得者 Michael Stonebraker 曾在 MapReduce 诞生之初撰写过一篇文章,题为 “MapReduce: A major step backwards”,Michael Stonebraker 在文章中直截了当地指出:MapReduce 忽视了数据库领域积累超过 40 年的技术经验。虽然大数据技术的出现和迭代降低了用户处理海量数据的门槛,但另一方面,与数据库这样高度优化的技术相比,大数据技术的抽象和实现还是太原始和初级。因此大数据技术在后续十几年的发展中,一直以数据库为目标,将更多数据库的成熟技术和理念借鉴到大数据中。
当前,大数据分析领域已经相当成熟,如何借鉴更多数据库的成熟技术和理念来提升大数据的能力呢?Apache Iceberg、Hudi 和 Delta Lake 这三个定位类似的开源项目正是从数据库方法论中汲取了灵感,将事务能力带到了大数据领域,并抽象成统一的中间格式供不同引擎适配对接。
如何定义这类新技术?
简单地说,这类新技术是介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”,Iceberg 将其称之为“表格式”也是表达类似的含义。它与底层的存储格式(比如 ORC、Parquet 之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。它构建在数据存储格式之上,其底层的数据存储仍然使用 Parquet、ORC 等进行存储。
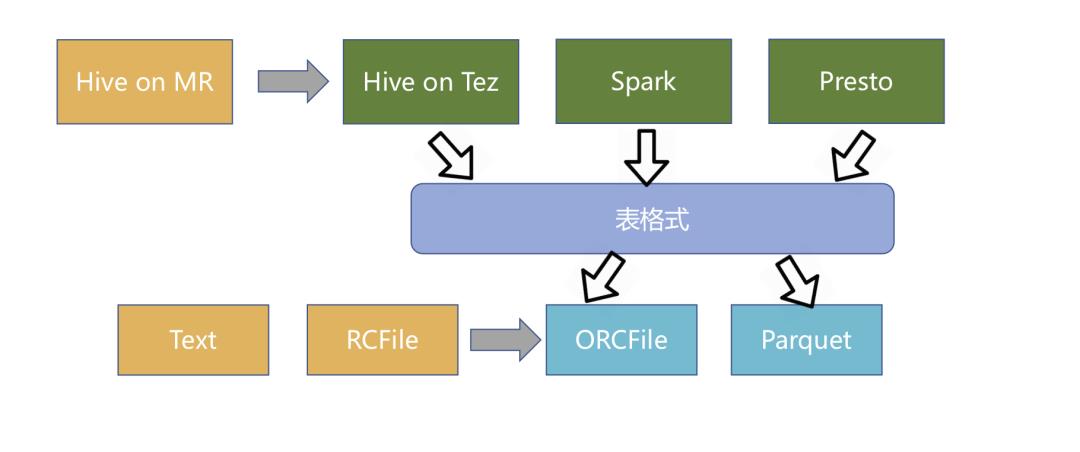
Apache Iceberg、Hudi 和 Delta Lake 诞生于不同公司,需要解决的问题存在差异,因此三者在设计初衷上稍有不同。
其中,Iceberg 的设计初衷更倾向于定义一个标准、开放且通用的数据组织格式,同时屏蔽底层数据存储格式上的差异,向上提供统一的操作 API,使得不同的引擎可以通过其提供的 API 接入;Hudi 的设计初衷更像是为了解决流式数据的快速落地,并能够通过 upsert 语义进行延迟数据修正;Delta Lake 作为 Databricks 开源的项目,更侧重于在 Spark 层面上解决 Parquet、ORC 等存储格式的固有问题,并带来更多的能力提升。
虽然这三个项目在设计初衷上稍有不同,但实现的思路和提供的能力却非常相似,他们都提供了 ACID 的能力,都基于乐观锁实现了冲突解决和提供线性一致性,同时相应地提供了 time travel 的功能。
但是因为设计初衷的不同,三个项目当前的能力象限各有不同,Iceberg 在其格式定义和核心能力上最为完善,但是上游引擎的适配上稍显不足;Hudi 基于 Spark 打造了完整的流式数据落地方案,但是其核心抽象较弱,与 Spark 耦合较紧;Delta Lake 同样高度依赖于 Spark 生态圈,与其他引擎的适配尚需时日。不过邵赛赛认为,这三个项目现有的差异会随着社区的推动和改进以及时间的累积慢慢磨平,最终可能会变得更趋于相同。
腾讯在 Iceberg 还未进入 Apache 孵化器时就已经开始关注,随着这几个技术的开源以及进入孵化器,这一领域开始逐渐升温,从 2019 年下半年开始,腾讯正式在该技术上进行探索和投入。
谈及引入 Iceberg 的原因,邵赛赛表示,当时团队在构建大数据生态的过程中遇到了几个痛点,而 Iceberg 恰好能解决这几个痛点:
T+0 的数据落地和处理。传统的数据处理流程从数据入库到数据处理通常需要一个较长的环节、涉及许多复杂的逻辑来保证数据的一致性,由于架构的复杂性使得整个流水线具有明显的延迟。Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟。
降低数据修正的成本。传统 Hive/Spark 在修正数据时需要将数据读取出来,修改后再写入,有极大的修正成本。Iceberg 所具有的修改、删除能力能够有效地降低开销,提升效率。
至于为何最终选择采用 Iceberg,而不是其他两个开源项目,技术方面的考量主要有以下几点:
Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如 Flink、Hive、Spark)对接,这对于腾讯内部落地是非常重要的,因为上下游数据管道的衔接往往涉及到不同的计算引擎;
良好的架构和开放的格式。相比于 Hudi、Delta Lake,Iceberg 的架构实现更为优雅,同时对于数据格式、类型系统有完备的定义和可进化的设计;
面向对象存储的优化。Iceberg 在数据组织方式上充分考虑了对象存储的特性,避免耗时的 listing 和 rename 操作,使其在基于对象存储的数据湖架构适配上更有优势。
除去技术上的考量,邵赛赛和团队也对代码质量、社区等方面做了详细的评估:
整体的代码质量以及未来的进化能力。整体架构代码上的抽象和优势,以及这些优势对于未来进行演化的能力是团队非常关注的。一门技术需要能够在架构上持续演化,而不会具体实现上需要大量的不兼容重构才能支持。
社区的潜力以及腾讯能够在社区发挥的价值。社区的活跃度是另一个考量,更重要的是在这个社区中腾讯能做些什么,能发挥什么样的价值。如果社区相对封闭或已经足够成熟,那么腾讯再加入后能发挥的价值就没有那么大了,在选择技术时这也是团队的一个重要考量点。
技术的中立性和开放性。社区能够以开放的态度去推动技术的演化,而不是有所保留地向社区贡献,同时社区各方相对中立而没有一个相对的强势方来完全控制社区的演进。
优化和改进
从正式投入研发到现在,腾讯在开源版本的基础上对 Iceberg 进行了一些优化和改进,主要包括:
实现了行级的删除和更新操作,极大地节省了数据修正和删除所带来的开销;
对 Spark 3.0 的 DataSource V2 进行了适配,使用 Spark 3.0 的 SQL 和 DataFrame 可以无缝对接 Iceberg 进行操作;
增加了对 Flink 的支持,可以对接 Flink 以 Iceberg 的格式进行数据落地。
这些改进点提高了 Iceberg 在落地上的可用性,也为它在腾讯内部落地提供了更为吸引人的特性。同时腾讯也在积极拥抱社区,大部分的内部改进都已推往社区,一些内部定制化的需求也会以更为通用的方式贡献回社区。
目前团队正在积极尝试将 Iceberg 融入到腾讯的大数据生态中,其中最主要的挑战在于如何与腾讯现有系统以及自研系统适配,以及如何在一个成熟的大数据体系中寻找落地点并带来明显的收益。邵赛赛具体提到了以下几点:
Iceberg 的上下游配套能力的建设相对缺乏,需要较多的配套能力的建设,比如 Spark、Hive、Flink 等不同引擎的适配;
其次是 Iceberg 核心能力成熟度的验证,它是否能够支撑起腾讯大数据量级的考验,其所宣称的能力是否真正达到了企业级可用,都需要进一步验证和加强;
最后,腾讯内部大数据经过多年发展,已经形成了一整套完整的数据接入分析方案,Iceberg 如何能够在内部落地,优化现有的方案非常重要。
Iceberg 诞生的时间不长,虽然拥有高度抽象和非常优雅的设计,但功能上仍有不足,尤其在围绕生态系统的建立和周边能力的打造上还有很多工作需要做。邵赛赛认为,当前 Iceberg 最重要的缺失点是和上层引擎的对接。现在 Iceberg 和 Spark 的对接是最为完善的,但是由于 DataSource V2 API 仍在不断地改进中,对于一些语义的下推仍然缺失,因此能力上和内置的存储格式相比仍有欠缺(比如 bucket join 的支持)。而对于 Hive、Flink 的支持尚在开发中。因为 Iceberg 是一个统一的数据组织格式,想要全面使用的话必须使所有的上层引擎能够对接适配,因此这一块环节的补足是当前最为重要的。
其次,Iceberg 缺少行级更新、删除能力。腾讯内部已经为 Iceberg 增加了行级更新、删除的能力,但在 Iceberg 社区尚未有这样的能力,这些能力所需的格式定义仍在设计中。行级更新、删除能力是现有数据组织格式的最大卖点,因此该功能的补强对于 Iceberg 的推广和落地十分重要。
在腾讯内部,后续对于 Iceberg 的规划主要还是以适配不同的引擎以及优化核心能力为主,同时会围绕 Iceberg 和上下游的引擎提供端到端的面向终端用户的数据管道能力。
目前相比于 Hudi、Delta Lake,Iceberg 在国内的关注度较少,这主要是由于其主要开发团队在技术推广和运营上面的工作偏少,而且 Iceberg 的开发者多为海外开发者,但是现在已经有越来越多大公司加入到了 Iceberg 的贡献中,包括 Netflix、Apple、Adobe、Expedia 等国外大厂,也包括腾讯、阿里、网易等国内公司。邵赛赛非常看好 Iceberg 未来在国内发展的前景,在他看来,一个好的技术架构可能暂时不引人瞩目,但最终还是会得到更多人的认可。随着国内推广的增多,以及国内开发者在这个项目上的投入、运营,未来在国内 Iceberg 前景可期。
延伸阅读:
嘉宾介绍:
邵赛赛,腾讯数据平台部数据湖内核技术负责人,资深大数据工程师,Apache Spark PMC member & committer, Apache Livy PMC member,曾就职于 Hortonworks、Intel。
你也「在看」吗? 以上是关于大数据架构变革进行时:为什么腾讯看好开源Apache Iceberg?的主要内容,如果未能解决你的问题,请参考以下文章 对话腾讯云汽车业务副总经理李博:构建出行大版图,腾讯云迈向新征程