Spring依赖注入和循环依赖问题分析
Posted 双子孤狼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring依赖注入和循环依赖问题分析相关的知识,希望对你有一定的参考价值。
Spring源码揭秘之依赖注入和循环依赖问题分析
- 前言
- 依赖注入的入口方法
- 依赖注入流程分析
- 总结
前言
在面试中,经常被问到 Spring 的 IOC 和 DI(依赖注入),很多人会觉得其实 IOC 就是 DI,但是严格上来说这两个其实并不等价,因为 IOC 注重的是存,而依赖注入注重的是取,实际上我们除了依赖注入还有另一种取的方式那就是依赖查找,可以把依赖注入和依赖查找都理解成 IOC 的实现方式。
依赖注入的入口方法
上一篇我们讲到了 IOC 的初始化流程,不过回想一下,是不是感觉少了点什么?IOC 的初始化只是将 Bean 的相关定义文件进行了存储,但是好像并没有进行初始化,而且假如一个类里面引用了另一个类,还需要进行赋值操作,这些我们都没有讲到,这些都属于我们今天讲解的依赖注入。
默认情况下依赖注入只有在调用 getBean() 的时候才会触发,因为 Spring 当中默认是懒加载,除非明确指定了配置 lazy-init=false,或者使用注解 @Lazy(value = false),才会主动触发依赖注入的过程。
依赖注入流程分析
在分析流程之前,我们还是看下面这个例子:
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
applicationContext.getBean("myBean");
applicationContext.getBean(MyBean.class);
我们的分析从 getBean() 方法开始。
AbstractBeanFactory#getBean
在前面我们讲到了一个顶层接口 BeanFactory 中定义了操作 Bean 的相关方法,而 ApplicationContext 就间接实现了 BeanFactory 接口,所以其调用 getBean() 方法会进入到 AbstractBeanFactory 类中的方法:

可以看到,这里调用之后直接就看到 doXXX 方法了,
AbstractBeanFactory#doGetBean
进入 doGetBean 这个方法进去之后呢,会有一系列判断,主要有以下几个方面:
- 当前类是不是单例,如果是的话而且单例已经被创建好,那么直接返回。
- 当前原型
bean是否正在创建,如果是的话就认为产生了循环依赖,抛出异常。 - 手动通过
@DependsOn注解或者xml配置中显式指定的依赖是否存在循环依赖问题,存在的话直接抛出异常。 - 当前的
BeanFactory中的beanDefinitionMap容器中是否存在当前bean对应的BeanDefinition,如果不存在则会去父类中继续获取,然后重新调用其父类对应的getBean()方法。
经过一系列的判断之后,会判断当前 Bean 是原型还是单例,然后走不同的处理逻辑,但是不论是原型还是单例对象,最终其都会调用 AbstractAutowireCapableBeanFactory 类中的 createBean 方法进行创建 bean 实例

AbstractAutowireCapableBeanFactory#createBean
这个方法里面会先确认当前 bean 是否可以被实例化,然后会有两个主要逻辑:
- 是否返回一个代理对象,是的话返回代理对象。
- 直接创建一个
bean对象实例。
这里面第一个逻辑我们不重点分析,在这里我们主要还是分析第二个逻辑,如何创建一个 bean 实例:
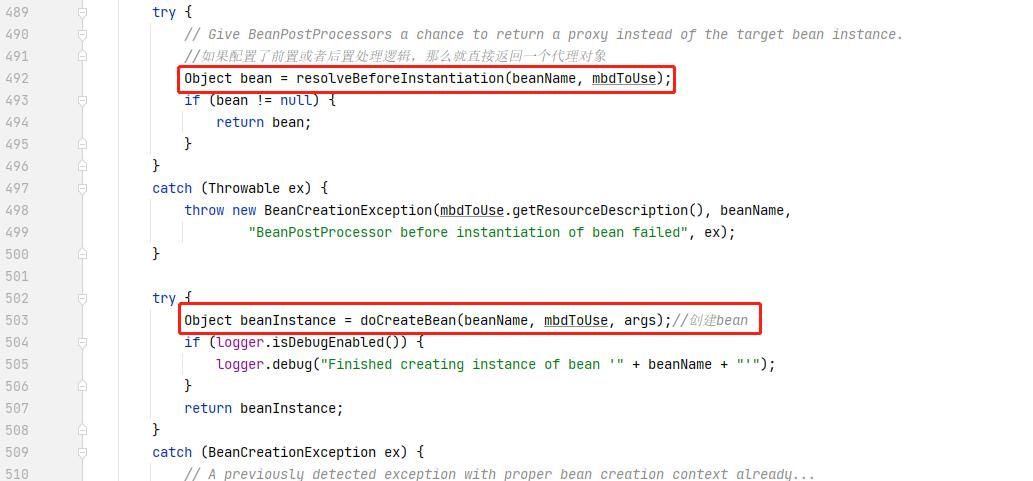
AbstractAutowireCapableBeanFactory#doCreateBean
这又是一个以 do 开头的方法,说明这里面会真正创建一个 bean 实例对象,在分析这个方法之前,我们先自己来设想一下,假如是我们自己来实现,在这个方法需要做什么操作?
在这个方法中,最核心的就是做两件事:
- 实例化一个
bean对象。 - 遍历当前对象的属性,如果需要则注入其他
bean,如果发现需要注入的bean还没有实例化,则需要先进行实例化。
创建 bean 实例(AbstractAutowireCapableBeanFactory#createBeanInstance)
在 doCreateBean 方法中,会调用 createBeanInstance 方法来实例化一个 bean。这里面也会有一系列逻辑去处理,比如判断这个类是不是具有 public 权限等等,但是最终还是会通过反射去调用当前 bean 的无参构造器或者有参构造器来初始化一个 bean 实例,然后再将其封装成一个 BeanWrapper 对象返回。
不过如果这里调用的是一个有参构造器,而这个参数也是一个 bean,那么也会触发先去初始化参数中的 bean,初始化 bean 实例除了有参构造器形式之外,相对还是比较容易理解,我们就不过多去分析细节,主要重点是分析依赖注入的处理方式。
依赖注入(AbstractAutowireCapableBeanFactory#populateBean)
在上面创建 Bean 实例完成的时候,我们的对象并不完整,因为还只是仅仅创建了一个实例,而实例中的注入的属性却并未进行填充,所以接下来就还需要完成依赖注入的动作,那么在依赖注入的时候,如果发现需要注入的对象尚未初始化,还需要触发注入对象的初始化动作,同时在注入的时候也会分为按名称注入和按类型注入(除此之外还有构造器注入等方式):

我们在依赖注入的时候最常用的是 @Autowired 和 @Resource 两个注解,而这连个注解的区别之一就是一个按照类型注入,另一个优先按照名称注入(没有找到名称就会按照类型注入),但是实际上这两个注解都不会走上面的按名称注入和按类型注入的逻辑,而是都是通过对应的 AutowiredAnnotationBeanPostProcessor 和 CommonAnnotationBeanPostProcessor 两个 Bean 的后置处理器来实现的,而且 @Resource 注解当无法通过名称找到 Bean 时也会根据类型去注入,在这里具体的处理细节我们就不过多展开分析,毕竟我们今天的目标是分析整个依赖注入的流程,如果过多纠结于这些分支细节,反而会使大家更加困惑。
上面通过根据名称或者根据属性解析出依赖的属性之后,会将其封装到对象 MutablePropertyValues(即:PropertyValues 接口的实现类) 中,最后会再调用 applyPropertyValues() 方法进行真正的属性注入:

循环依赖问题是怎么解决的
依赖注入成功之后,整个 DI 流水就算结束了,但是有一个问题我们没有提到,那就是循环依赖问题,循环依赖指的是当我们有两个类 A 和 B,其中 A 依赖 B,B 又依赖了 A,或者多个类也一样,只要形成了一个环状依赖那就属于循环依赖,比如下面的配置就是一个典型的循环依赖配置:
<bean id="classA" class="ClassA" p:beanB-ref="classB"/>
<bean id="classB" class="ClassB" p:beanA-ref="classA"/>
而我们前面讲解 Bean 的初始化时又讲到了当我们初始化 A 的时候,如果发现其依赖了 B,那么会触发 B 的初始化,可是 B 又依赖了 A,导致其无法完成初始化,这时候我们应该怎么解决这个问题呢?
在了解 Spring 中是如何解决这个问题之前,我们自己先想一下,如果换成我们来开发,我们会如何解决这个问题呢?其实方法也很简单,大家应该都能想到,那就是当我们把 Bean 初始化之后,在没有注入属性之前,就先缓存起来,这样,就相当于缓存了一个半成品 Bean 来提前暴露出来供注入时使用。
不过解决循环依赖也是有前提的,以下三种情形就无法解决循环依赖问题:
- 构造器注入产生的循环依赖。通过构造器注入产生的循环依赖会在第一步初始化就失败,所以也无法提前暴露出来。
- 非单例模式
Bean,因为只有在单例模式下才会对Bean进行缓存。 - 手动设置了
allowCircularReferences=false,则表示不允许循环依赖。
而在 Spring 当中处理循环依赖也是这个思路,只不过 Spring 中为了考虑设计问题,并非仅仅只采用了一个缓存,而是采用了三个缓存,这也就是面试中经常被问到的循环依赖相关的三级缓存问题(这里我个人意见是不太认同三级缓存这种叫法的,毕竟这三个缓存是在同一个类中的三个不同容器而已,并没有层级关系,这一点和 MyBatis 中使用到的两级缓存还是有区别的,不过既然大家都这么叫,咱一个凡人也就随波逐流了)。
Spring 中解决循环依赖的三级缓存
如下图所示,在 Spring 中通过以下三个容器(Map 集合)来缓存单例 Bean:

- singletonObjects
这个容器用来存储成品的单例 Bean,也就是所谓的第一级缓存。
- earlySingletonObjects
这个用来存储半成品的单例 Bean,也就是初始化之后还没有注入属性的 Bean,也就是所谓的第二级缓存。
- singletonFactories
存储的是 Bean 工厂对象,可以用来生成半成品的 Bean,这也就是所谓的三级缓存。
为什么需要三级缓存才能解决循环依赖问题
看了上面的三级缓存,不知道大家有没有疑问,因为第一级缓存和第二级缓存都比较好理解,一个成品一个半成品,这个都没什么好说的,那么为什么又需要第三级缓存呢,这又是出于什么考虑呢?
回答这个问题之前,我梳理了有循环依赖和没有循环依赖两种场景的流程图来进行对比分析:
没有循环依赖的创建 Bean A 流程:

有循环依赖的创建 Bean A 流程(A 依赖 B,B 依赖 A):

对比这两个流程其实有一个比较大的区别,我在下面这个有循环依赖的注入流程标出来了,那就是在没有循环依赖的情况下一个类是会先完成属性的注入,才会调用 BeanPostProcessor 处理器来完成一些后置处理,这也比较符合常理也符合 Bean 的生命周期,而一旦有循环依赖之后,就不得不把 BeanPostProcessor 提前进行处理,这样在一定程度上就破坏了 Bean 的生命周期。
但是到这里估计大家还是有疑问,因为这并不能说明一定要使用三级缓存的理由,那么这里就涉及到了 Spring Aop 了,当我们使用了 Spring Aop 之后,那么就不能使用原生对象而应该换成用代理对象,那么代理对象是什么时候创建的呢?
实际上 Spring Aop 的代理对象也是通过 BeanPostProcessor 来完成的,下图就是一个使用了 Spring Aop 的实例对象所拥有的所有 BeanPostProcessor:

在这里有一个 AnnotationAwareAspectJAutoProxyCreator 后置处理器,也就是 Spring Aop 是通过后置处理器来实现的。
知道了这个问题,我们再来确认另一个问题,Spring 中为了解决循环依赖问题,在初始化 Bean 之后,还未注入属性之前就会将单例 Bean 先放入缓存,但是这时候也不能直接将原生对象放入二级缓存,因为这样的话如果使用了 Spring Aop 就会出问题,其他类可能会直接注入原生对象而非代理对象。
那么这里我们能不能直接就创建代理对象存入二级缓存呢?答案是可以,但是直接创建代理对象就必须要调用 BeanPostProcessor 后置处理器,这样就使得调用后置处理器在属性注入之前了,违背了 Bean 声明周期。
在提前暴露单例之前,Spring 并不知道当前 Bean 是否有循环依赖,所以为了尽可能的延缓 BeanPostProcessor 的调用,Spring 才采用了三级缓存,存入一个 Objectactory 对象,并不创建,而是当发生了循环依赖的时候,采取三级缓存获取到三级缓存来创建对象,因为发生了循环依赖的时候,不得不提前调用 BeanPostProcessor 来完成实例的初始化。
我们看下加入三级缓存的逻辑:

加入三级缓存是将一个 lambda 表达式存进去,目的就是延缓创建,最后发生循环依赖的时候,从一二级缓存都无法获取到 Bean 的时候,会获取三级缓存,也就是调用 ObjectFactory 的 getObject() 方法,而这个方法实际上就是调用下面的 getEarlyBeanReference ,这里就会提前调用 BeanPostProcessor 来完成实例的创建。

总结
本文主要分析了 Spinrg 依赖注入的主要流程,而依赖注入中产生的循环依赖问题又是其中比较复杂的处理方式,在本文分析过程中略去了详细的逻辑,只关注了主流程。本文主要是结合了网上一些资料然后自己 debug 调试过程得到的自己对 Spring 依赖注入的一个主要流程,如果有理解错误的地方,欢迎留言交流。
以上是关于Spring依赖注入和循环依赖问题分析的主要内容,如果未能解决你的问题,请参考以下文章