Spring框架进阶Spring V2.0 循环依赖
Posted 烟锁迷城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring框架进阶Spring V2.0 循环依赖相关的知识,希望对你有一定的参考价值。
1、循环依赖的本质
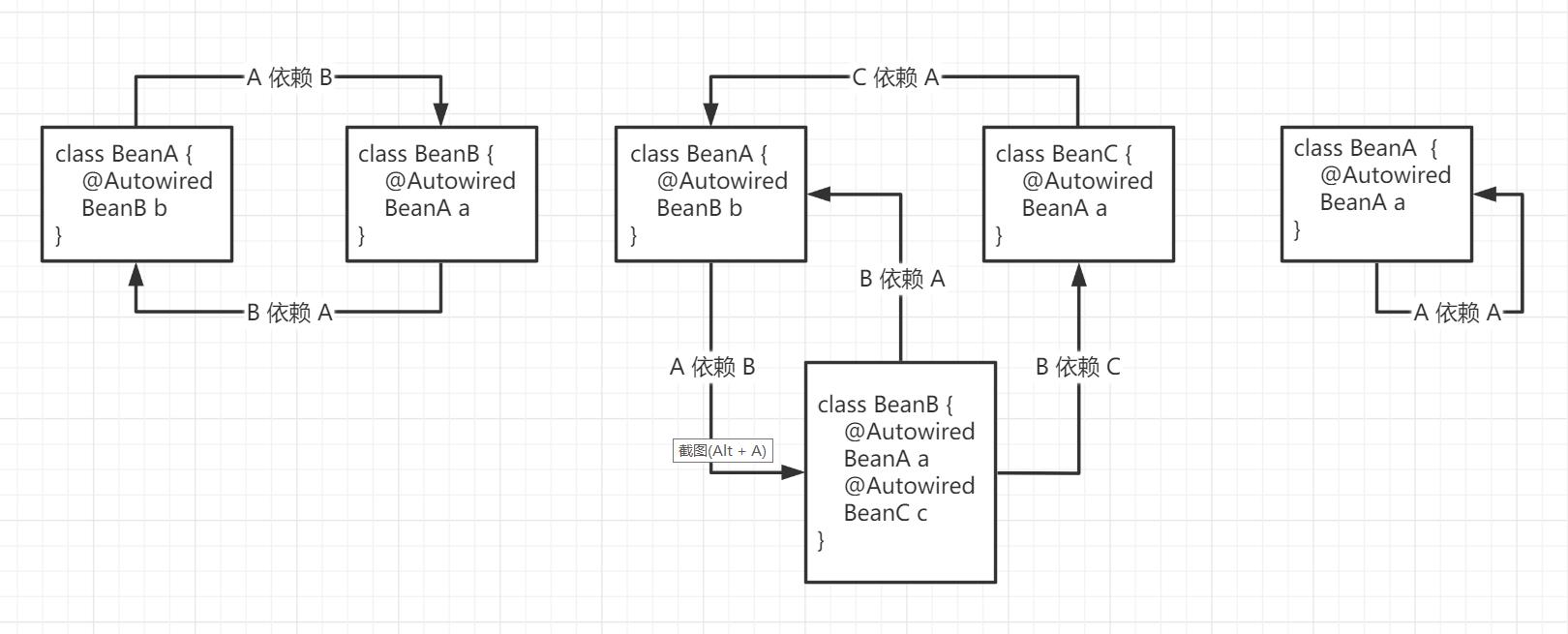
循环依赖,即在创建一个BeanA的时候,发现依赖注入所使用的BeanB尚未创建,进一步创建BeanB时,发现它又依赖注入BeanA,这样两个Bean都无法完成依赖注入,只能注入Null,这种情况可能发生于一个或数个Bean的创建过程。
从源码层面上分析,执行IOC的初始化及装载的动作本质是对getBean()方法的循环执行,循环依据是从BeanDefinitionReader中获取到的BeanDefinition列表,list本身是有顺序的,所以在执行getBean方法执行Bean实例化和依赖注入的时候会有先后顺序,循环依赖一旦发生,很有可能会因为BeanA所依赖的BeanB还没有完成创建而注入Null
2、解决思路
如何解决循环依赖问题,需要理顺思路。
第一步,需要对产生循环依赖的对象进行记录,或者说是标记,可以创建一个容器,专门用来存储可能产生循环依赖的Bean
第二步,在进行依赖注入的时候,不再从factoryBeanInstanceCache中拿取bean,依赖注入的bean可能还没来得及放入这个缓存中,因此,最好采用递归调用的方式,获取到需要依赖注入的Bean,也就是再执行一次getBean()方法
第三步,如果在递归调用getBean()方法时需要的Bean已经被创建过了,自然不需要继续创建,那么就可以先检测容器中是否存在一个已经创建好的Bean,直接取出,无需再创建。
有了这样的思路,就已经基本解决了循环依赖的问题。
3、源码实现
Spring为了解决循环依赖的问题,提出了一个方案:三级缓存
- 一级缓存:已经完成依赖注入,可以直接使用的完整Bean
- 二级缓存:没有完成依赖注入,早期的Bean
- 三级缓存:为AOP动态代理做准备的Bean
三级缓存的概念就是这样的,可能不明白,但是不要紧,实际上在源码中,参与到循环依赖问题解决的容器有四个
- singletonsCurrentlyInCreation:正在创建的bean
- singletonObjects:一级缓存
- earlySingletonObjects:二级缓存
- singletonFactories:三级缓存
在这段解决循环依赖的源码中可以看到,获取到一个单例Bean时,会先从一级缓存中拿到bean,如果没有,且拥有创建标记,证明这个bean可能已经被创建过了,从二级缓存中拿取,如果二级缓存中也没有,就会尝试从三级缓存中拿取,如果三级缓存中不为空,就会尝试从三级缓存的单例工厂中获取到一个,拿到之后,会放入到二级缓存中,并且从三级缓存中移除。
protected Object getSingleton(String beanName, boolean allowEarlyReference)
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName))
synchronized (this.singletonObjects)
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference)
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null)
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
return singletonObject;
public boolean isSingletonCurrentlyInCreation(String beanName)
return this.singletonsCurrentlyInCreation.contains(beanName);
singletonObject = singletonFactory.getObject();会根据lambda表达式映射到getSingleton( beanName, singletonFactory)方法中,可以非常清楚地看到,lambda表达式锁执行的,是creatBean方法,即创建一个Bean
sharedInstance = getSingleton(beanName, () ->
try
//创建一个指定Bean实例对象,如果有父级继承,则合并子类和父类的定义
return createBean(beanName, mbd, args);
catch (BeansException ex)
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
//显式地从容器单例模式Bean缓存中清除实例对象
destroySingleton(beanName);
throw ex;
);
//获取给定Bean的实例对象
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);这是一个复杂的创建流程,如果成功的话,就会执行addSingleton(beanName, singletonObject)方法,这个方法很直观,会直接将创建好的Bean放入一级缓存中。
protected void addSingleton(String beanName, Object singletonObject)
synchronized (this.singletonObjects)
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
可实际上我们不用关心singletonObject = singletonFactory.getObject();这个方法是怎么拿到实例对象的,也无需直到为什么需要从三级缓存中将其移除,为什么源码的三级缓存和实际的三级缓存不相同,因为这并非重点,重点在于,整个执行流程就是先从一级缓存中得到完成的具有依赖注入的bean,如果没有,就去获取二级缓存中已经创建完成但是没有依赖注入的bean,如果还是没有,就从三级缓存中拿到一个已经创建完成但是没有依赖注入的bean。
因为java是引用,所以就算依赖注入的是早期的bean,也可以通过后来的依赖注入补充完其内部没有依赖注入的数值。
四、代码实现
明白整个流程之后,编写代码就非常简单了
首先增加容器
public class MyDefaultListableBeanFactory implements MyBeanFactory
//保存所有的配置信息
public Map<String, MyBeanDefinition> beanDefinitionMap = new HashMap<String, MyBeanDefinition>();
//循环依赖标识,当前正在创建的bean
private Set<String> singletonsCurrentlyInCreation = new HashSet<String>();
//一级缓存,存放完成注入的bean
private Map<String, Object> singletonObjects = new HashMap<String, Object>();
//二级缓存,存放早期bean
private Map<String, Object> earlySingletonObjects = new HashMap<String, Object>();
//三级缓存,也是终极缓存
private Map<String, MyBeanWrapper> factoryBeanInstanceCache = new HashMap<String, MyBeanWrapper>();
然后在getBean方法中增加getSingleton方法
@Override
public Object getBean(String beanName)
//1、先拿到对应的beanDefinition配置信息
MyBeanDefinition beanDefinition = this.beanDefinitionMap.get(beanName);
//从一级缓存中拿取对象,如果对象存在,就直接返回
Object singleton = getSingleton(beanName, beanDefinition);
if (singleton != null)
return singleton;
具体如何实现,先不去探究,至少这个方法其内部应该是和spring源码中的是类似的。
如果能够成功从一级缓存中拿到一个完备的bean,肯定最好,但如果没有,就需要继续创建,因此这个beanName需要被添加到标记正在创建的容器singletonsCurrentlyInCreation中
@Override
public Object getBean(String beanName)
//1、先拿到对应的beanDefinition配置信息
MyBeanDefinition beanDefinition = this.beanDefinitionMap.get(beanName);
//从一级缓存中拿取对象,如果对象存在,就直接返回
Object singleton = getSingleton(beanName, beanDefinition);
if (singleton != null)
return singleton;
//标记bean正在被创建
if (!singletonsCurrentlyInCreation.contains(beanName))
singletonsCurrentlyInCreation.add(beanName);
标记完成后,正常执行创建,但是在实例化完成后,需要加入到一级缓存中.
@Override
public Object getBean(String beanName)
//1、先拿到对应的beanDefinition配置信息
MyBeanDefinition beanDefinition = this.beanDefinitionMap.get(beanName);
//从一级缓存中拿取对象,如果对象存在,就直接返回
Object singleton = getSingleton(beanName, beanDefinition);
if (singleton != null)
return singleton;
//标记bean正在被创建
if (!singletonsCurrentlyInCreation.contains(beanName))
singletonsCurrentlyInCreation.add(beanName);
//2、反射实例化对象
Object instance = instantiateBean(beanName, beanDefinition);
//实例化完成后保存到一级缓存中
this.singletonObjects.put(beanName, instance);
完成后,在依赖注入时改为递归调用
private void populateBean(String beanName, MyBeanDefinition beanDefinition, MyBeanWrapper beanWrapper)
Object instance = beanWrapper.getWrappedInstance();
Class<?> clazz = instance.getClass();
if (!(clazz.isAnnotationPresent(MyController.class) || clazz.isAnnotationPresent(MyService.class)))
return;
for (Field field : clazz.getDeclaredFields())
if (!field.isAnnotationPresent(MyAutowired.class))
continue;
MyAutowired autowired = field.getAnnotation(MyAutowired.class);
String autowiredBeanName = field.getType().getName();
if (!"".equals(autowired.value()))
autowiredBeanName = autowired.value().trim();
field.setAccessible(true);
try
/*if (this.factoryBeanInstanceCache.get(autowiredBeanName) == null)
continue;
field.set(instance, this.factoryBeanInstanceCache.get(autowiredBeanName).getWrappedInstance());*/
//此处不再从三级缓存中获取到实例对象,而是直接递归调用获取
field.set(instance,getBean(autowiredBeanName));
catch (IllegalAccessException e)
e.printStackTrace();
这些步骤都处理完成后,就可以处理最关键的步骤,getSingleton方法了
private Object getSingleton(String beanName, MyBeanDefinition beanDefinition)
//一级缓存中进行获取
Object bean = this.singletonObjects.get(beanName);
//如果一级缓存中没有,又有创建标识,就证明是循环依赖
if (bean == null && singletonsCurrentlyInCreation.contains(beanName))
//二级缓存中获取
bean = this.earlySingletonObjects.get(beanName);
//如果二级缓存中也没有,就去创建实例化,同时放入三级缓存
if (bean == null)
bean = instantiateBean(beanName, beanDefinition);
//同时放入二级缓存中
earlySingletonObjects.put(beanName, bean);
return bean;
到此可以看出,其实解决循环依赖并不需要三级缓存,只需要到二级缓存就可以完成循环依赖的解决,因为在实例化完成后就可以直接放入二级缓存,整个过程都不需要三级缓存参与。
那么三极缓存到底是做什么的呢?
是AOP,这将在下一章节谈到。
五、特殊情况
有几种情况,循环依赖时无法被解决的
- 通过构造器注入的不能支持循环依赖
- 非单例的,不支持循环依赖
非单例不支持循环依赖,这比较容易理解,因为原型Bean每次都会重新创建,不会交给IOC托管,自然也就无法从缓存中获取。
通过构造器互相依赖的不支持循环依赖,同样可以理解,因为构造方法是反射实现对象实例化的基础,没有构造函数就不能用反射实例化,所有的java类在不自定义构造方法时都有默认的无参构造,而一旦通过构造方法进行依赖注入导致的循环依赖,就会导致BeanA实例化时就要依赖BeanB,BeanB开始实例化时还需要依赖BeanA,但实际上BeanA根本还没有被创建,这样就会进入死循环,根本无法被成功创建。
那么,如果一个使用构造器注入,另一个使用非构造器注入,是否还会导致无法解决循环依赖的问题呢?
这就和Bean的创建顺序有关了,加入BeanA构造依赖BeanB,BeanB注解依赖BeanA,如果BeanA先创建,又会陷入死循环中。但如果是BeanB先创建,然后依赖注入BeanA,BeanA实例化时就可以找到BeanB,完成自己的创建过程。
在Spring中,创建Bean的顺序是依据自然排序,所以Bean的创建顺序决定这种特殊循环依赖方式的成功与否。
以上是关于Spring框架进阶Spring V2.0 循环依赖的主要内容,如果未能解决你的问题,请参考以下文章