pytorch模型保存加载与续训练
Posted 秃头小苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch模型保存加载与续训练相关的知识,希望对你有一定的参考价值。
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:对抗生成网络GAN系列——GAN原理及手写数字生成小案例 对抗生成网络GAN系列——DCGAN简介及人脸图像生成案例
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
文章目录
pytorch保存与加载模型详解篇
写在前面
最近,看到不少小伙伴问pytorch如何保存和加载模型,其实这部分pytorch官网介绍的也是很清楚的,感兴趣的点击☞☞☞了解详情🥁🥁🥁
但是肯定有很多人是不愿意看官网的,所以我还是花一篇文章来为大家介绍介绍。当然了,在介绍中我会加入自己的一些理解,让大家有一个更深的认识。如果准备好了的话,就让我们开始吧。⏳⏳⏳
模型保存与加载
pytorch中介绍了几种不同的模型保存和加载方式,我会在下文一一为大家介绍。首先先让我们来随便定义一个模型,如下:【用的是pytorch官网的例子】
# 模型定义
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
定义好模型结构后,我们可以实例化这个模型:
#模型初始化
model = TheModelClass()
模型初始化过后,我们就一起来看看模型保存和加载的方式吧。🍄🍄🍄
方式1
方式1是官方推荐的一种方式,我们直接来看代码好了,如下:
# 保存模型
torch.save(model.state_dict(), './model/model_state_dict.pth')
该方法后面的参数'./model/model_state_dict.pth'为模型的保存路径,模型后缀名官方推荐使用.pth和.pt,当然了,你取别的后缀名也是完全可行的。☘☘☘
介绍了模型的保存,下面就来看看方式1是如何加载模型的。【这里我说明一点,模型保存往往是在训练中进行的,而模型加载多数用在模型推理中,它们存在两个文件中,故我们在推理过程中要先实列化模型】
# 加载模型
model_test1 = TheModelClass() # 加载模型时应先实例化模型
# load_state_dict()函数接收一个字典,所以不能直接将'./model/model_state_dict.pth'传入,而是先使用load函数将保存的模型参数反序列化
model_test1.load_state_dict(torch.load('./model/model_state_dict.pth'))
model_test1.eval() # 模型推理时设置
在上述的代码注释中我有写到,我们使用load_state_dict()加载模型时先需要使用load方法将保存的模型参数反序列化,load后的结果是一个字典,这时就可以通过load_state_dict()方法来加载了。
这里我来简单说一下我理解的反序列化,其和序列化是相对应的一个概念。序列化就是把内存中的数据保存到磁盘中,像我们使用torch.save()方法保存模型就是序列化;而反序列化则是将硬盘中的数据加载到内存当中,显然我们加载模型的过程就是反序列化过程。【大致的意思如下图所示,偶然在水群的时候看到一个画图软件,是不是还挺好看的🍧🍧🍧】

方式2
方式2非常简单,直接上代码:
# 保存模型
torch.save(model, './model/model.pt') #这里我们保存模型的后缀名取.pt
# 加载模型
model_test2 = torch.load('./model/model.pt')
model_test2.eval() # 模型推理时设置
但是这种方式是不推荐使用的,因为你使用这种方式保存模型,然后再加载时会遇到各种各样的错误。为了加深大家理解,我们来看这样的一个例子。文件的结构如下图所示:

models.py文件中存储的是模型的定义,其位于文件夹models下。save_model.py文件中写的是保存模型的代码,如下:
from models.models import TheModelClass
from torch import optim
import torch
#模型初始化
model = TheModelClass()
# 初始化优化器
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# ## 保存加载方式2——save/load
# # 保存模型
# torch.save(models, './models/models.pt')
执行此文件后,会生成models.pt文件,我们在执行load_mode.py文件即可实现加载,load_mode.py内容如下:
from models.models import TheModelClass
import torch
## 加载方式2
# 加载模型
model_test2 = TheModelClass()
model_test2 = torch.load('./models/models.pt')
model_test2.eval() # 模型推理时设置
print(model_test2)
此时我们可以正常加载。但如果我们将models文件夹修改为model,如下:

此时我们在使用如下代码加载模型的话就会出现错误:
from models.models import TheModelClass
import torch
## 加载方式2
# 加载模型
model_test2 = TheModelClass()
model_test2 = torch.load('./model/models.pt') #这里需要修改一下文件路径
model_test2.eval() # 模型推理时设置
print(model_test2)

出现这种错误的原因是使用方式2进行模型保存的时候会把模型结构定义文件路径记录下来,加载的时候就会根据路径解析它然后装载参数;当把模型定义文件路径修改以后,使用torch.load(path)就会报错。
其实使用方式2进行模型的保存和加载还会存在各种问题,感兴趣的可以看看这篇博文。总之,在我们今后的使用中,尽量不要用方式2来加载模型。🌱🌱🌱
方式3
pytorch还为我们提供了一种模型保存与加载的方式——checkpoint。这种方式保存的是一个字典,如果我们程序在运行中由于某种原因异常中止,那么这种方式可以很方便的让我们接着上次训练,正因为这样,我非常推荐大家使用这种方式进行模型的保存与加载。下面就让我们一起来看看方式3是如何使用的吧!!!🍥🍥🍥
首先,我们同样使用torch.save来保存模型,但是这里保存的是一个字典,里面可以填入你需要保存的参数,如下:
# 保存checkpoint
torch.save(
'epoch':epoch,
'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':loss
, './model/model_checkpoint.tar' #这里的后缀名官方推荐使用.tar
)
接着我们来看看如何加载checkpoint,代码如下:
# 加载checkpoint
model_checkpoint = TheModelClass()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load('./model/model_checkpoint.tar') # 先反序列化模型
model_checkpoint.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
看了我上文的介绍,大家是否知道如何使用checkpoint了呢,我想大家都会觉得这个不是很难,但要自己写可能还是不好把握,那么第一次就让我来带领大家看看如何在代码中使用checkpoint吧!!!🍵🍵🍵
这节我采用cifar10数据集实现物体分类的例子,我的这篇博文对其进行了详细介绍,那么这里介绍checkpoint我将利用这个demo来为大家讲解。首先我们直接来看模型保存的完整代码,如下:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#1、准备数据集
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download= True)
test_dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download= True)
#2、加载数据集
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=100)
test_dataset_loader = DataLoader(dataset=test_dataset, batch_size=100)
#3、搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, input):
input = self.model1(input)
return input
#4、创建网络模型
net = Net()
#5、设置损失函数、优化器
#损失函数
loss_fun = nn.CrossEntropyLoss() #交叉熵
loss_fun = loss_fun.to(device)
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(net.parameters(), learning_rate) #SGD:梯度下降算法
#6、设置网络训练中的一些参数
total_train_step = 0 #记录总计训练次数
total_test_step = 0 #记录总计测试次数
Max_epoch = 10 #设计训练轮数
#7、开始进行训练
for epoch in range(Max_epoch):
print("---第轮训练开始---".format(epoch))
net.train() #开始训练,不是必须的,在网络中有BN,dropout时需要
#由于训练集数据较多,这里我没用训练集训练,而是采用测试集(test_dataset_loader)当训练集,但思想是一致的
for data in test_dataset_loader:
imgs, targets = data
targets = targets.to(device)
outputs = net(imgs)
#比较输出与真实值,计算Loss
loss = loss_fun(outputs, targets)
#反向传播,调整参数
optimizer.zero_grad() #每次让梯度重置
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 50 == 0:
print("---第次训练结束, Loss:)".format(total_train_step, loss.item()))
if (epoch+1) % 2 == 0:
# 保存checkpoint
torch.save(
'epoch': epoch,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss
, './model/model_checkpoint_epoch_.tar'.format(epoch) # 这里的后缀名官方推荐使用.tar
)
if epoch > 5:
print("---意外中断---")
break
整个流程和这篇文章基本一致,不清楚的建议先花几分钟阅读一下哈。🍍🍍🍍主要区别就是在最后保存模型的时候我使用了checkpoint进行保存,且两个epoch保存一次。当epoch=6时,我设置了一个break模拟程序意外中断,中断后可以来看一下终端的输出信息,如下图所示:

我们可以看到在进行第6轮循环时,程序中断了,此时最新的保存的模型是第五次训练结果,如下:
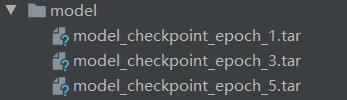
同时注意到第5次训练结束的loss在2.0左右,如果我们下次接着训练,损失应该是在2.0附近。🍊🍊🍊
好了,上面由于一些糟糕的原因导致程序中断了,现在我想接着上次训练的结果继续训练,我该怎么办呢?代码如下:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#1、准备数据集
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download= True)
test_dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download= True)
#2、加载数据集
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=100)
test_dataset_loader = DataLoader(dataset=test_dataset, batch_size=100)
#3、搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, input):
input = self.model1(input)
return input
#4、创建网络模型
net = Net()
#5、设置损失函数、优化器
#损失函数
loss_fun = nn.CrossEntropyLoss() #交叉熵
loss_fun = loss_fun.to(device)
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(net.parameters(), learning_rate) #SGD:梯度下降算法
#6、设置网络训练中的一些参数
total_train_step = 0 #记录总计训练次数
total_test_step = 0 #记录总计测试次数
Max_epoch = 10 #设计训练轮数
##########################################################################################
# 加载checkpoint
checkpoint = torch.load('./model/model_checkpoint_epoch_5.tar') # 先反序列化模型
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
loss = checkpoint['loss']
##########################################################################################
#7、开始进行训练
for epoch in range(start_epoch+1, Max_epoch):
print("---第轮训练开始---".format(epoch))
net.train() #开始训练,不是必须的,在网络中有BN,dropout时需要
for data in test_dataset_loader:
imgs, targets = data
targets = targets.to(device)
outputs = net(imgs)
#比较输出与真实值,计算Loss
loss = loss_fun(outputs, targets)
#反向传播,调整参数
optimizer.zero_grad() #每次让梯度重置
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 50 == 0:
print("---第次训练结束, Loss:)".format(total_train_step, loss.item()))
if (epoch+1) % 2 == 0:
# 保存checkpoint
torch.save(
'epoch': epoch,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss
, './model/model_checkpoint_epoch_.tar'.format(epoch) # 这里的后缀名官方推荐使用.tar
)
这里的代码相较之前的多了一个加载checkpoint的过程,我将其截取出来,如下图所示:

通过加载checkpoint我们就保存了之前训练的参数,进而实现断点续训练,我们直接来看执行此代码的结果,如下图所示:

从上图可以看出我们的训练是从第6轮开始的,并且初始的loss为1.99,和2.0接近。这就说明了我们已经实现了中断后恢复训练的操作。
🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸
这里我简单的说两句,上文介绍checkpoint的用法时,训练中断和训练恢复我是放在两个文件中的进行的,但是在实际中我们肯定是在一个文件中运行,那这该怎么办呢?其实方法很简单啦,我们只需要设置一个if条件将加载checkpoint的部分放在训练文件中,然后设置一个参数来控制if条件的执行即可。具体细节我就不给大家介绍了,如果有不明白的评论区见吧!!!🌿🌿🌿🌿
🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸🌸
总结
这部分还是蛮简单的,但一些细节还是需要大家自行考量,我就为大家介绍到这里啦,希望大家都能够有所收获吧。🥂🥂🥂
如若文章对你有所帮助,那就🛴🛴🛴

以上是关于pytorch模型保存加载与续训练的主要内容,如果未能解决你的问题,请参考以下文章