I/O模型演变
Posted EileenChang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了I/O模型演变相关的知识,希望对你有一定的参考价值。
文章目录
1 BIO
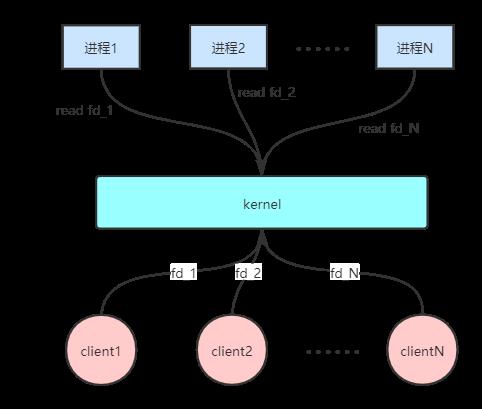
在Linux系统早期,由于socket是阻塞的,用户进程需要阻塞等待请求到达,所以需要为每个socket开启一个进程。这时缺点显而易见,开启越多的进程则需要越多的内存,同时CPU的调度成本也会上升。
2 NIO
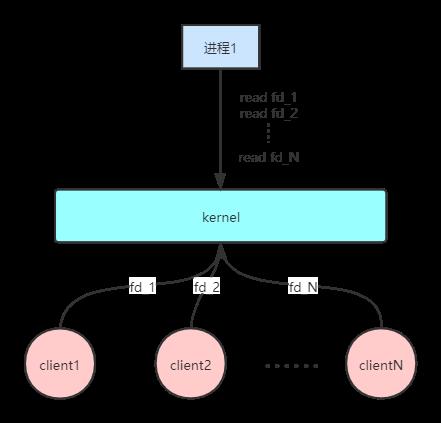
随着Linux系统的不断完善,socket可以是非阻塞了。这时,用户空间只需要开启一个进程,轮询所有的socket,解决了BIO时期需要开启多个进程的问题。但是,这个方案依然有问题,如果有很多个socket,意味着用户进程需要访问多次内核调用,这依然需要很高的成本。
3 select
当Linux有了select之后,用户进程可以一次把所有的socket文件描述通过select调用传递给内核,由内核遍历并筛选出就绪的socket文件描述符返回给用户进程,这样用户进程只需要遍历少量的文件描述符。
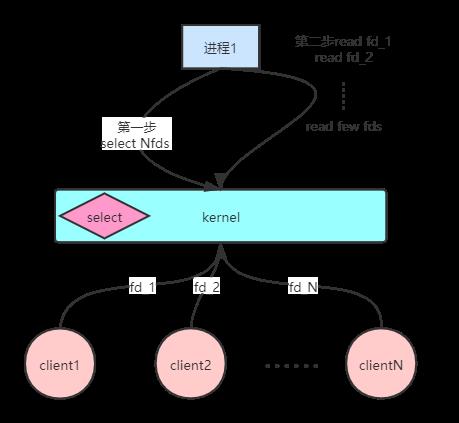
但是,这个方案也有缺点,那就是用户空间和内核空间是通过select进行数据传输,而且select每次最多只能传输1024个文件描述符,这种用户空间和内核空间的来回拷贝数据也是需要很高的成本。
4 epoll
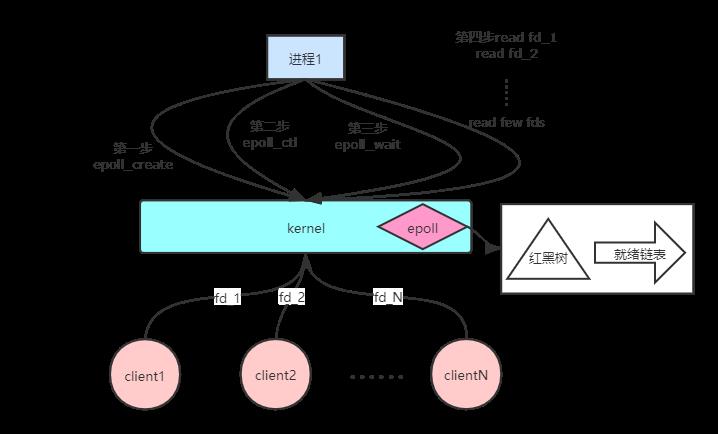
epoll提供了三个系统调用:
- epoll_create:创建一个epoll实例并返回其文件描述符。
- epoll_ctl:往epoll中注册指定的文件描述符。
- epoll_wait:阻塞等待注册的事件发生,返回事件的数目,并将触发的事件写入events数组中。
epoll相比于select,其优越之处在于,因为select每次调用时都要传递需要监控的所有socket给内核,这意味着需要将用户态的socket列表拷贝到内核空间,如果数以万计的句柄会导致每次都要拷贝几十几百KB的内存到内核态,非常低效。而我们调用epoll_wait时就相当于调用select,但是这时却不用传递socket句柄给内核,因为内核已经通过epoll_ctl拿到了要监控的句柄列表。
epoll在初始化时,会开辟出epoll自己的内核高速缓冲区,用于存放每一个我们想监控的socket,这些socket会以红黑树的结构存储,以支持快速的查找、插入、删除。
epoll的高效就在于,当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以快速返回,并有效地将发生事件的句柄给用户进程。这是由于我们在调用epoll_create时,内核除了建立一个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件。当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已。
以上是关于I/O模型演变的主要内容,如果未能解决你的问题,请参考以下文章