https://www.cnblogs.com/chy2055/p/5220793.html
一、关于I/O模型的引出
我们都知道,为了OS的安全性等的考虑,进程是无法直接操作I/O设备的,其必须通过系统调用请求内核来协助完成I/O动作,而内核会为每个I/O设备维护一个buffer。如下图所示:
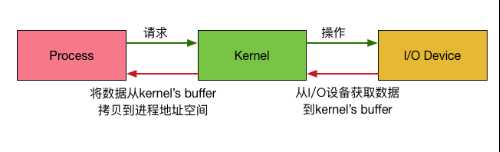
整个请求过程为: 用户进程发起请求,内核接受到请求后,从I/O设备中获取数据到buffer中,再将buffer中的数据copy到用户进程的地址空间,该用户进程获取到数据后再响应客户端。
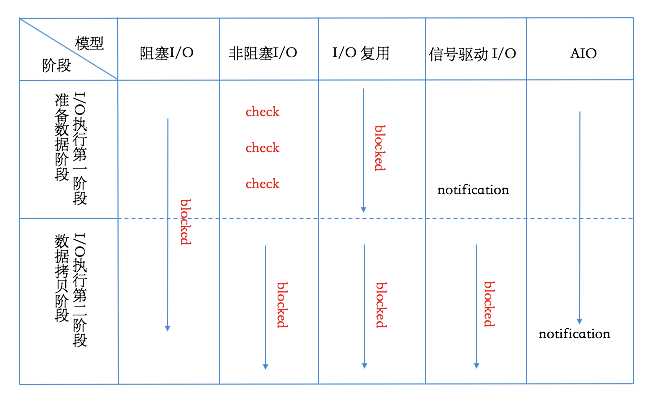
在整个请求过程中,数据输入至buffer需要时间,而从buffer复制数据至进程也需要时间。因此根据在这两段时间内等待方式的不同,I/O动作可以分为以下五种模式:
(1) 阻塞I/O (Blocking I/O)
(2) 非阻塞I/O (Non-Blocking I/O)
(3) I/O复用(I/O Multiplexing)
(4) 信号驱动的I/O (Signal Driven I/O)
(5) 异步I/O (Asynchrnous I/O)
二、关于I/O模型的划分
阻塞:调用的进程一直处于等待状态,直到操作完成。
非阻塞:在内核的数据还未准备好时,会立即返回,进程可以去干其他事情。
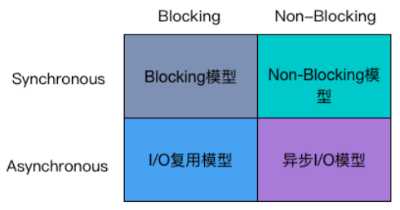
从同步异步,以及阻塞、非阻塞两个维度来划分来看:
三、I/O模型分述
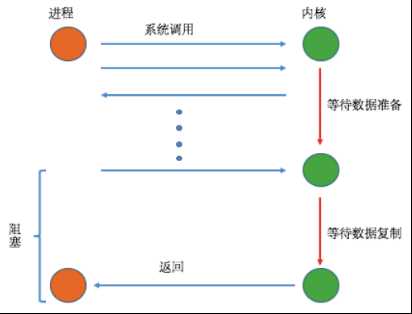
1、阻塞I/O
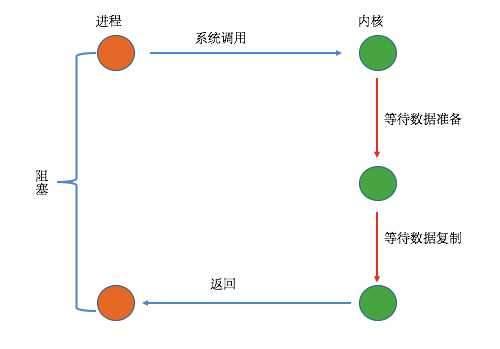
从上图可以看到在整个过程中,当用户进程进行系统调用时,内核就开始了I/O的第一个阶段,准备数据到缓冲区中,当数据都准备完成后,则将数据从内核缓冲区中拷贝到用户进程的内存中,这时用户进程才解除block的状态重新运行。
所以,Blocking I/O的特点就是在I/O执行的两个阶段都被block了。
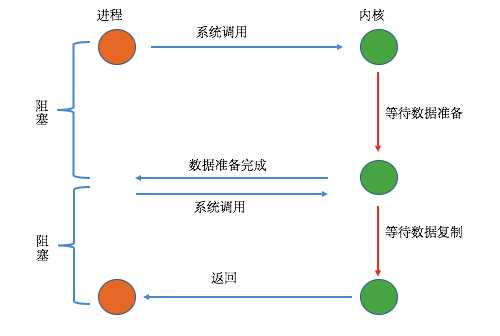
2、非阻塞I/O
从上图可以看到在I/O执行的两个阶段中,用户进程只有在第二个阶段被阻塞了,而第一个阶段没有阻塞,但是在第一个阶段中,用户进程需要盲等,不停的去轮询内核,看数据是否准备好了,因此该模型是比较消耗CPU的。
3、I/O复用
从上图可以看到在I/O复用模型中,I/O执行的两个阶段都是用户进程都是阻塞的,但是两个阶段是独立的,在一次完整的I/O操作中,该用户进程是发起了两次系统调用。
4、信号驱动的I/O
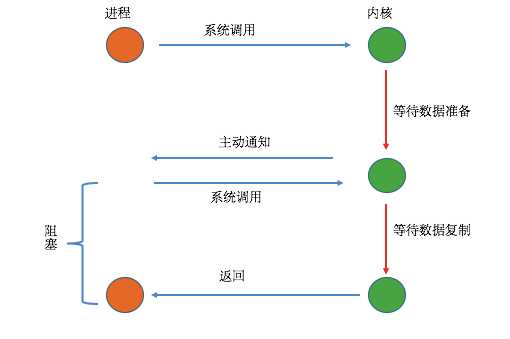
该模型也叫作基于事件驱动的I/O模型,可以看到该模型中,只有在I/O执行的第二阶段阻塞了用户进程,而在第一阶段是没有阻塞的。
乍看起来感觉和非阻塞模型很相似,其实不同之处就在于,该模型在I/O执行的第一阶段,当数据准备完成之后,会主动的通知用户进程数据已经准备完成,即对用户进程做一个回调。该通知分为两种,一为水平触发,即如果用户进程不响应则会一直发送通知,二为边缘触发,即只通知一次。
5、异步I/O
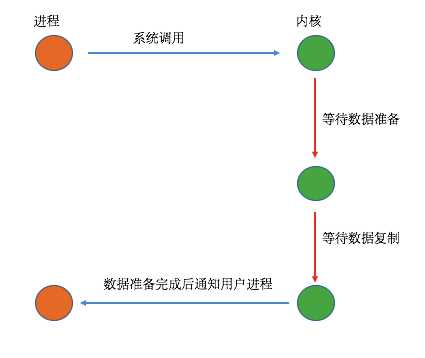
在该模型中,当用户进程发起系统调用后,立刻就可以开始去做其它的事情,然后直到I/O执行的两个阶段都完成之后,内核会给用户进程发送通知,告诉用户进程操作已经完成了。
四、五种模型总结