机器学习笔记
Posted hhh江月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记相关的知识,希望对你有一定的参考价值。
机器学习笔记(四)
文章目录
线性判别分析
线性判别分析(Linear Discriminant Analysis,简称LDA),其基本思想是:将训练样本投影到一条直线上,使得同类的样例尽可能近,不同类的样例尽可能远。如图所示:


想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
类内散度矩阵(within-class scatter matrix)

类间散度矩阵(between-class scaltter matrix)
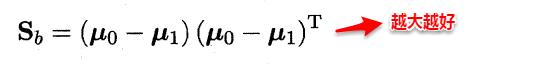
因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。

从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。

若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),因此LDA也常被视为一种经典的监督降维技术。
多分类学习
现实生活中的问题可能是由多种种类构成的,因此分类问题也并不局限于两种类型的回归的分析了,对于多余两种种类的多分类学习的回归分析问题,有三种思路,分别是:一对一,一对多(一对其余),多对多。其核心思想图如下所示:

以及:
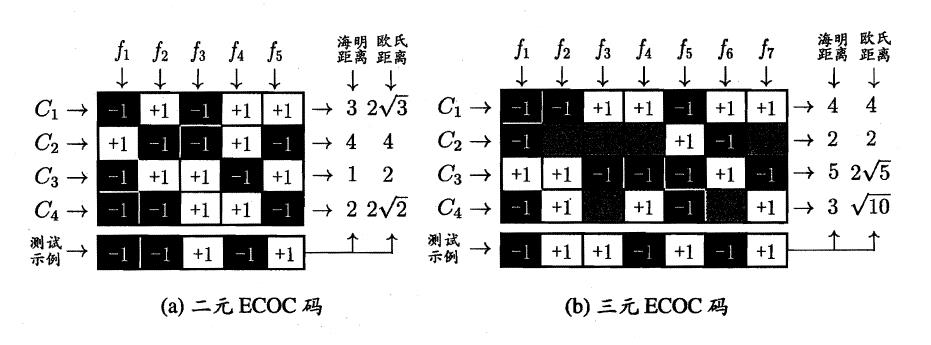
类别不平衡问题
类别不平衡的问题是指在一个分类问题中,不同的类别对应的数据集的大小是不一样的,甚至相差很大,譬如:以二元分类为例,其中一个类别的数据集中总共有900条数据,但是另一个类别的数据集中只有100条数据,那么这两个类别的数据集训练样本就是相差比较悬殊的,因此就需要进行相应的处理来平衡有关的问题。处理这个不平衡的问题大致有三种方法:
- 在训练样本较多的类别中进行欠采样,常见的算法有EasyEnsemble
- 在训练样本较少的类别中进行过采样,常见的算法有SMOTE
- 直接对原数据集进行训练,但是对预测值需要进行再缩放的处理,其中再缩放也是代价敏感学习 的基础,如下图所示:

小总结
以上我们就学习完毕了所有的有关于线性回归的问题,接下来我们要开始学习决策树部分的有关知识。
决策树
决策树是一种广泛被使用的分类算法,英文名为:Decision Tree。
决策树的基本概念
首先我们举一个例子:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个例子可以用决策树来进行描述:
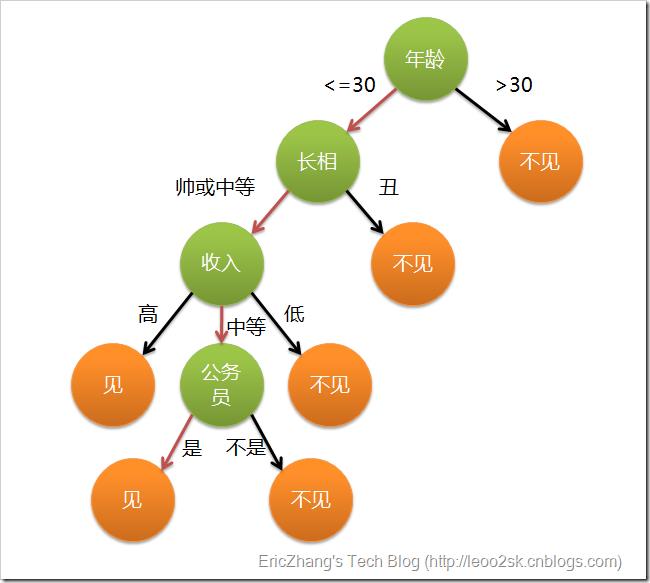
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。一般一颗决策树包含:一个根节点、若干个内部节点和若干个叶子节点,易知:
* 每个非叶节点表示一个特征属性测试。
* 每个分支代表这个特征属性在某个值域上的输出。
* 每个叶子节点存放一个类别。
* 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。
决策树的构造
ID3算法
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:

假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。
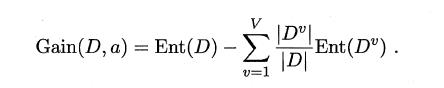
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
C4.5算法
ID3算法存在一个问题,就是偏向于取值数目较多的属性,例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。因此C4.5算法使用了“增益率”(gain ratio)来选择划分属性,来避免这个问题带来的困扰。首先使用ID3算法计算出信息增益高于平均水平的候选属性,接着C4.5计算这些候选属性的增益率,增益率定义为:
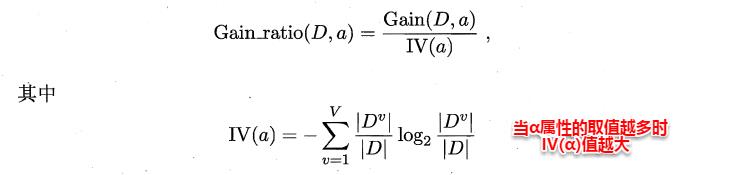
CART算法
CART决策树使用“基尼指数”(Gini index)来选择划分属性,基尼指数反映的是从样本集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小越好,基尼指数定义如下:
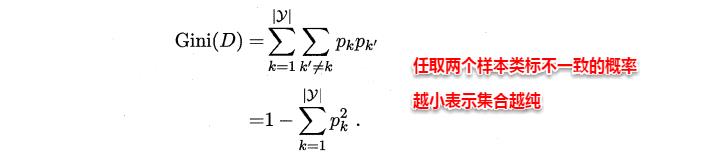
进而,使用属性α划分后的基尼指数为:

以上是关于机器学习笔记的主要内容,如果未能解决你的问题,请参考以下文章