架构大合集,轻松应对工作需求(上)
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构大合集,轻松应对工作需求(上)相关的知识,希望对你有一定的参考价值。
前言
本文讲述:
- 数据结构和算法,23种设计模式,
- OKhttp,Retrofit,
- Glide,
- Dagger2,
- MVP,MVC,MVVM,MVI,
- Jetpack Room,
今天星期一,星期一,星期一😑
关注公众号:初一十五a
解锁 《Android十大板块文档》,让学习更贴近未来实战。已形成PDF版
内容如下:
1.2022最新Android11位大厂面试专题,128道附答案
2.音视频大合集,从初中高到面试应有尽有
3.Android车载应用大合集,从零开始一起学
4.性能优化大合集,告别优化烦恼
5.Framework大合集,从里到外分析的明明白白
6.Flutter大合集,进阶Flutter高级工程师
7.compose大合集,拥抱新技术
8.Jetpack大合集,全家桶一次吃个够
9.架构大合集,轻松应对工作需求
10.Android基础篇大合集,根基稳固高楼平地起
整理不易,关注一下吧。开始进入正题,ღ( ´・ᴗ・` ) 🤔
一丶架构通用
1.1.常用数据结构
线性表之ArrayList
ArrayList 本质上是一个动态数组,第一次添加元素时,数组大小将变化为 DEFAULT_CAPACITY 10,不断添加元素后,会进行扩容。删除元素时,会按照位置关系把数组元素整体(复制)移动一遍。
ArrayList.java
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
···
// 增加元素
public boolean add(E e)
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
···
// 删除元素
public E remove(int index)
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
···
// 查找元素
public E get(int index)
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
···
1.2.二十三种设计模式
设计模式概念
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。 毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石脉络,如同大厦的结构一样。
即12字真言:设计模式是设计经验的总结
通俗的说,就是解决问题的方法,是前辈们归纳总结出来的便于人们理解使用,增加代码的可维护性、可复用性、可扩展性。
设计模式的几个分类
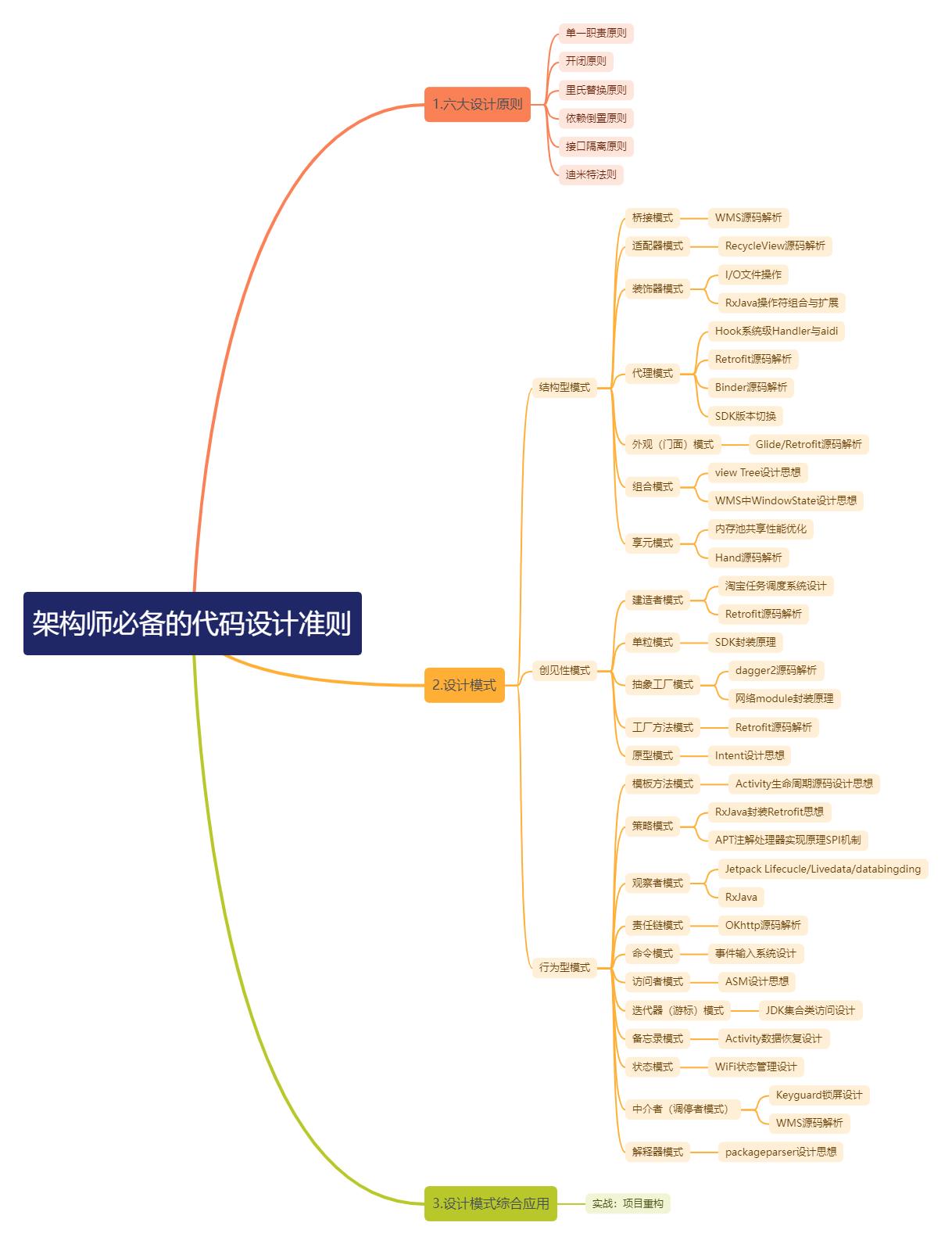
创建型模式:对象实例化的模式,创建型模式用于解耦对象的实例化过程。
结构型模式:把类或对象结合在一起形成一个更大的结构。
行为型模式:类和对象如何交互,及划分责任和算法。
如下图所示:
每个模式分类中有哪些关键点?
- 单例模式: 不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责
- 简单工厂:一个工厂类根据传入的参量决定创建出那一种产品类的实例。
- 工厂方法: 定义一个具体功能相关的接口,由子类来决定这么实现。
- 抽象工厂:创建相关或依赖对象的家族,而无需明确指定具体类。
- 建造者模式:封装一个复杂对象的构建过程,并可以按步骤构造。
- 原型模式: 将一个对象作为原型,通过复制的方式,克隆出多个和目标实例类似的新实例。
- 适配器模式:将一个类的方法接口转换成客户希望的另外一个接口。
- 组合模式:将对象组合成树形结构以表示“”部分-整体“”的层次结构。
- 装饰模式:动态的给对象添加新的功能。
- 代理模式:为其他对象提供一个代理以便控制这个对象的访问。
- 亨元模式:通过共享技术来有效的支持大量细粒度的对象。
- 外观模式:对外提供一个统一的方法,来访问子系统中的一群接口。
- 桥接模式:将抽象部分和它的实现部分分离,使它们都可以独立的变化。
- 模板模式:定义一个算法结构,而将一些步骤延迟到子类实现。
- 解释器模式:给定一个语言,定义它的文法的一种表示,并定义一个解释器。
- 策略模式:定义一系列算法,把他们封装起来,并且使它们可以相互替换。
- 状态模式:允许一个对象在其对象内部状态改变时改变它的行为。
- 观察者模式:对象间的一对多的依赖关系。
- 备忘录模式:在不破坏封装的前提下,保持对象的内部状态。
- 中介者模式:用一个中介对象来封装一系列的对象交互。
- 命令模式:将命令请求封装为一个对象,使得可以用不同的请求来进行参数化。
- 访问者模式:在不改变数据结构的前提下,增加作用于一组对象元素的新功能。
- 责任链模式:将请求的发送者和接收者解耦,使的多个对象都有处理这个请求的机会。
- 迭代器模式:一种遍历访问聚合对象中各个元素的方法,不暴露该对象的内部结构。
23种设计模式
1.单例模式
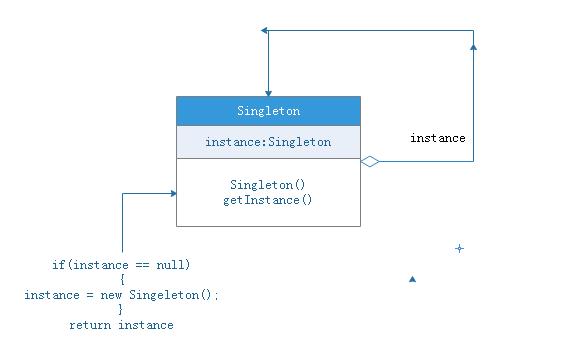
单例模式,它的定义就是确保某一个类只有一个实例,并且提供一个全局访问点。
单例模式具备典型的3个特点:
1、只有一个实例。
2、自我实例化。
3、提供全局访问点。
因此当系统中只需要一个实例对象或者系统中只允许一个公共访问点,除了这个公共访问点外,不能通过其他访问点访问该实例时,可以使用单例模式。
单例模式的主要优点就是节约系统资源、提高了系统效率,同时也能够严格控制客户对它的访问。也许就是因为系统中只有一个实例,这样就导致了单例类的职责过重,违背了“单一职责原则”,同时也没有抽象类,所以扩展起来有一定的困难。其UML结构图非常简单,就只有一个类,如下图:
2.工厂方法模式
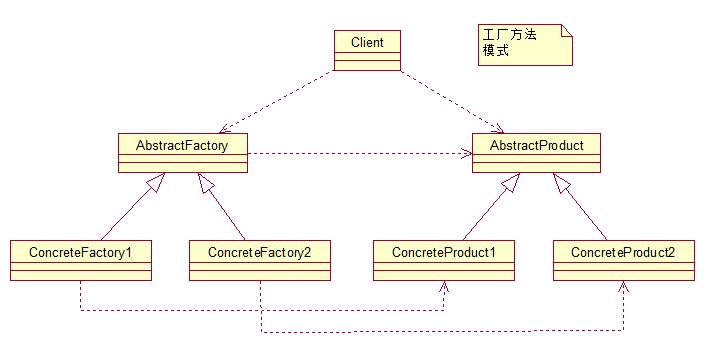
作为抽象工厂模式的孪生兄弟,工厂方法模式定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个,也就是说工厂方法模式让实例化推迟到子类。
工厂方法模式非常符合“开闭原则”,当需要增加一个新的产品时,我们只需要增加一个具体的产品类和与之对应的具体工厂即可,无须修改原有系统。同时在工厂方法模式中用户只需要知道生产产品的具体工厂即可,无须关系产品的创建过程,甚至连具体的产品类名称都不需要知道。虽然他很好的符合了“开闭原则”,但是由于每新增一个新产品时就需要增加两个类,这样势必会导致系统的复杂度增加。其UML结构图:
3.抽象工厂模式
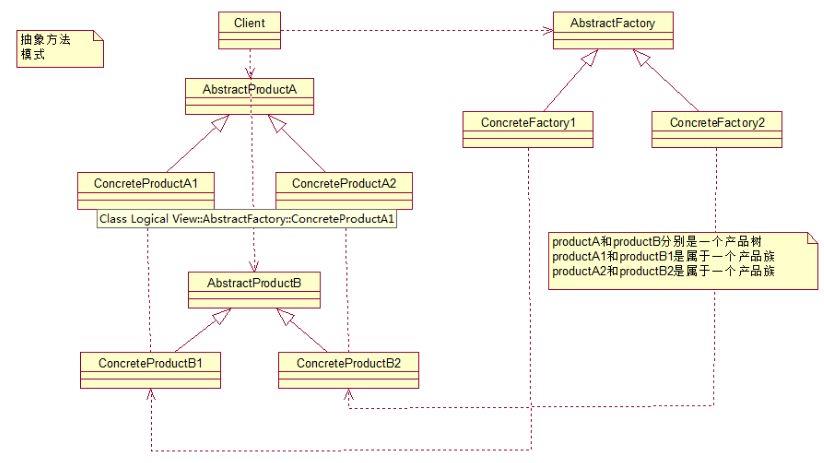
所谓抽象工厂模式就是提供一个接口,用于创建相关或者依赖对象的家族,而不需要明确指定具体类。他允许客户端使用抽象的接口来创建一组相关的产品,而不需要关系实际产出的具体产品是什么。这样一来,客户就可以从具体的产品中被解耦。它的优点是隔离了具体类的生成,使得客户端不需要知道什么被创建了,而缺点就在于新增新的行为会比较麻烦,因为当添加一个新的产品对象时,需要更加需要更改接口及其下所有子类。其UML结构图如下:
4.建造者模式
对于建造者模式而已,它主要是将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。适用于那些产品对象的内部结构比较复杂。
建造者模式将复杂产品的构建过程封装分解在不同的方法中,使得创建过程非常清晰,能够让我们更加精确的控制复杂产品对象的创建过程,同时它隔离了复杂产品对象的创建和使用,使得相同的创建过程能够创建不同的产品。但是如果某个产品的内部结构过于复杂,将会导致整个系统变得非常庞大,不利于控制,同时若几个产品之间存在较大的差异,则不适用建造者模式,毕竟这个世界上存在相同点大的两个产品并不是很多,所以它的使用范围有限。其UML结构图:
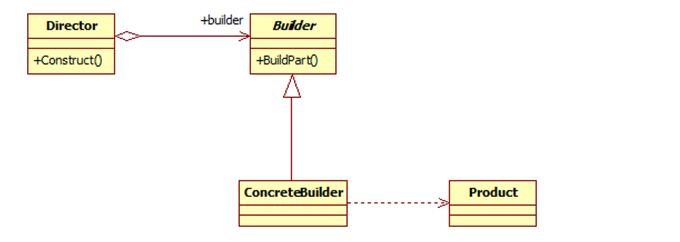
5.原型模式
在我们应用程序可能有某些对象的结构比较复杂,但是我们又需要频繁的使用它们,如果这个时候我们来不断的新建这个对象势必会大大损耗系统内存的,这个时候我们需要使用原型模式来对这个结构复杂又要频繁使用的对象进行克隆。所以原型模式就是用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。
它主要应用与那些创建新对象的成本过大时。它的主要优点就是简化了新对象的创建过程,提高了效率,同时原型模式提供了简化的创建结构。UML结构图:
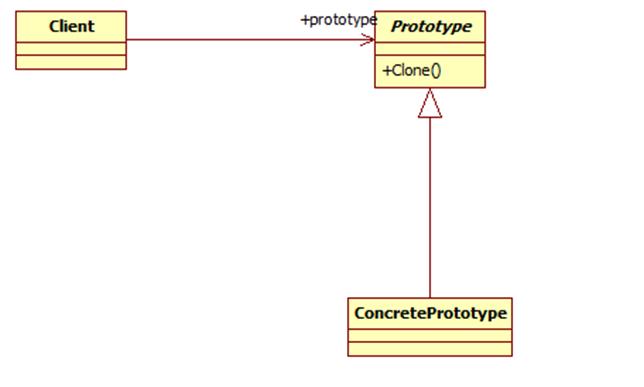
模式结构
原型模式包含如下角色:
Prototype:抽象原型类
ConcretePrototype:具体原型类
Client:客户类
6.适配器模式
在我们的应用程序中我们可能需要将两个不同接口的类来进行通信,在不修改这两个的前提下我们可能会需要某个中间件来完成这个衔接的过程。这个中间件就是适配器。所谓适配器模式就是将一个类的接口,转换成客户期望的另一个接口。它可以让原本两个不兼容的接口能够无缝完成对接。
作为中间件的适配器将目标类和适配者解耦,增加了类的透明性和可复用性。
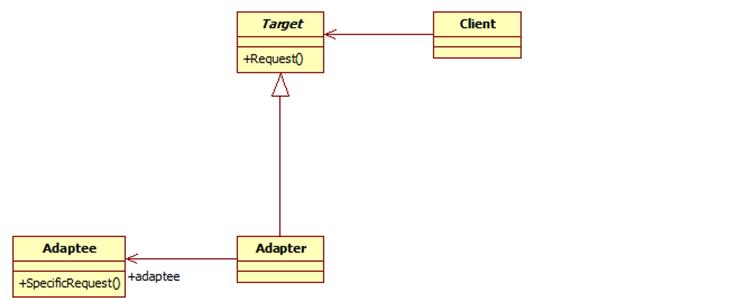
适配器模式包含如下角色:
Target:目标抽象类
Adapter:适配器类
Adaptee:适配者类
Client:客户类
7.桥接模式
如果说某个系统能够从多个角度来进行分类,且每一种分类都可能会变化,那么我们需要做的就是讲这多个角度分离出来,使得他们能独立变化,减少他们之间的耦合,这个分离过程就使用了桥接模式。所谓桥接模式就是讲抽象部分和实现部分隔离开来,使得他们能够独立变化。
桥接模式将继承关系转化成关联关系,封装了变化,完成了解耦,减少了系统中类的数量,也减少了代码量。
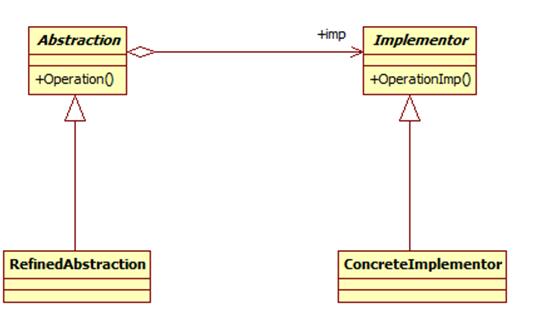
桥接模式包含如下角色:
Abstraction:抽象类
RefinedAbstraction:扩充抽象类
Implementor:实现类接口
ConcreteImplementor:具体实现类
8.组合模式
组合模式组合多个对象形成树形结构以表示“整体-部分”的结构层次。它定义了如何将容器对象和叶子对象进行递归组合,使得客户在使用的过程中无须进行区分,可以对他们进行一致的处理。在使用组合模式中需要注意一点也是组合模式最关键的地方:叶子对象和组合对象实现相同的接口。这就是组合模式能够将叶子节点和对象节点进行一致处理的原因。
虽然组合模式能够清晰地定义分层次的复杂对象,也使得增加新构件也更容易,但是这样就导致了系统的设计变得更加抽象,如果系统的业务规则比较复杂的话,使用组合模式就有一定的挑战了。
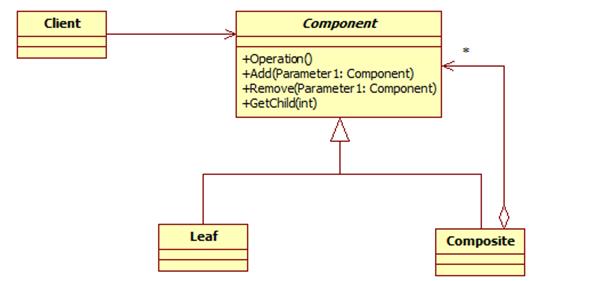
模式结构
组合模式包含如下角色:
Component: 抽象构件
Leaf: 叶子构件
Composite: 容器构件
Client: 客户类
9.装饰模式
我们可以通过继承和组合的方式来给一个对象添加行为,虽然使用继承能够很好拥有父类的行为,但是它存在几个缺陷:
一、对象之间的关系复杂的话,系统变得复杂不利于维护。
二、容易产生“类爆炸”现象。
三、是静态的。在这里我们可以通过使用装饰者模式来解决这个问题。
装饰者模式,动态地将责任附加到对象上。若要扩展功能,装饰者提供了比继承更加有弹性的替代方案。虽然装饰者模式能够动态将责任附加到对象上,但是他会产生许多的细小对象,增加了系统的复杂度.
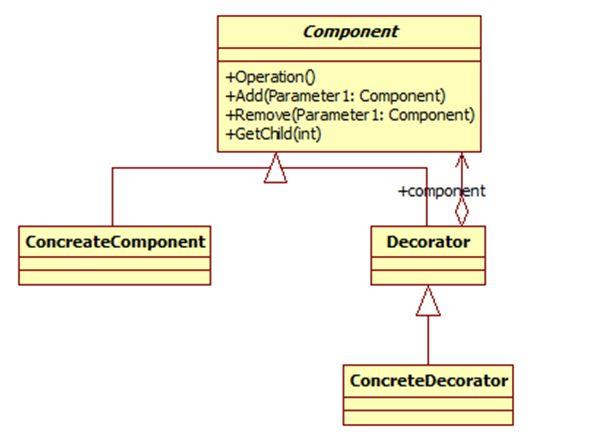
模式结构
装饰模式包含如下角色:
Component: 抽象构件
ConcreteComponent: 具体构件
Decorator: 抽象装饰类
ConcreteDecorator: 具体装饰类
10.外观模式
我们都知道类与类之间的耦合越低,那么可复用性就越好,如果两个类不必彼此通信,那么就不要让这两个类发生直接的相互关系,如果需要调用里面的方法,可以通过第三者来转发调用。外观模式非常好的诠释了这段话。外观模式提供了一个统一的接口,用来访问子系统中的一群接口。它让一个应用程序中子系统间的相互依赖关系减少到了最少,它给子系统提供了一个简单、单一的屏障,客户通过这个屏障来与子系统进行通信。通过使用外观模式,使得客户对子系统的引用变得简单了,实现了客户与子系统之间的松耦合。但是它违背了“开闭原则”,因为增加新的子系统可能需要修改外观类或客户端的源代码。
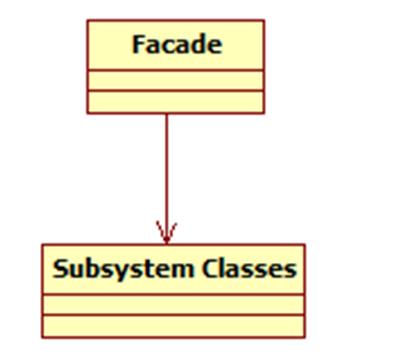
外观模式包含如下角色:
Facade: 外观角色
SubSystem:子系统角色
11.亨元模式
在一个系统中对象会使得内存占用过多,特别是那些大量重复的对象,这就是对系统资源的极大浪费。享元模式对对象的重用提供了一种解决方案,它使用共享技术对相同或者相似对象实现重用。享元模式就是运行共享技术有效地支持大量细粒度对象的复用。系统使用少量对象,而且这些都比较相似,状态变化小,可以实现对象的多次复用。这里有一点要注意:享元模式要求能够共享的对象必须是细粒度对象。享元模式通过共享技术使得系统中的对象个数大大减少了,同时享元模式使用了内部状态和外部状态,同时外部状态相对独立,不会影响到内部状态,所以享元模式能够使得享元对象在不同的环境下被共享。同时正是分为了内部状态和外部状态,享元模式会使得系统变得更加复杂,同时也会导致读取外部状态所消耗的时间过长。
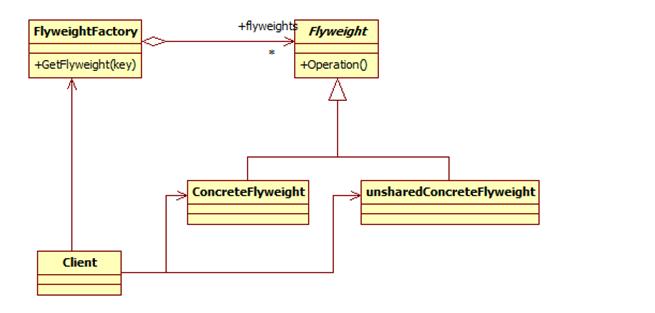
享元模式包含如下角色:
Flyweight: 抽象享元类
ConcreteFlyweight: 具体享元类
UnsharedConcreteFlyweight: 非共享具体享元类
FlyweightFactory: 享元工厂类
12.代理模式
代理模式就是给一个对象提供一个代理,并由代理对象控制对原对象的引用。它使得客户不能直接与真正的目标对象通信。代理对象是目标对象的代表,其他需要与这个目标对象打交道的操作都是和这个代理对象在交涉。
代理对象可以在客户端和目标对象之间起到中介的作用,这样起到了的作用和保护了目标对象的,同时也在一定程度上面减少了系统的耦合度。
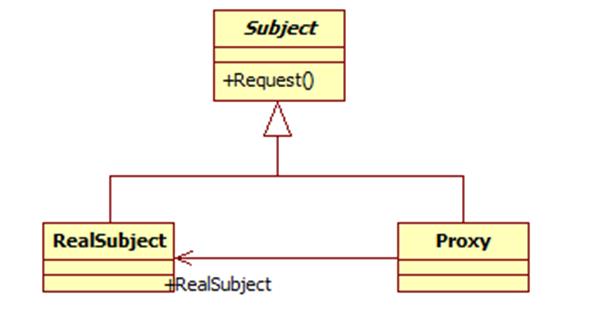
代理模式包含如下角色:
Subject: 抽象主题角色
Proxy: 代理主题角色
RealSubject:真实主题角色
13.访问者模式
访问者模式俗称23大设计模式中最难的一个。除了结构复杂外,理解也比较难。在我们软件开发中我们可能会对同一个对象有不同的处理,如果我们都做分别的处理,将会产生灾难性的错误。对于这种问题,访问者模式提供了比较好的解决方案。访问者模式即表示一个作用于某对象结构中的各元素的操作,它使我们可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
访问者模式的目的是封装一些施加于某种数据结构元素之上的操作,一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。为不同类型的元素提供多种访问操作方式,且可以在不修改原有系统的情况下增加新的操作方式。同时我们还需要明确一点那就是访问者模式是适用于那些数据结构比较稳定的,因为他是将数据的操作与数据结构进行分离了,如果某个系统的数据结构相对稳定,但是操作算法易于变化的话,就比较适用适用访问者模式,因为访问者模式使得算法操作的增加变得比较简单了。
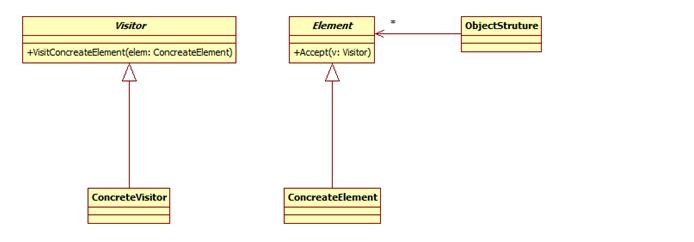
访问者模式包含如下角色:
Vistor: 抽象访问者
ConcreteVisitor: 具体访问者
Element: 抽象元素
ConcreteElement: 具体元素
ObjectStructure: 对象结构
14.模板模式
有些时候我们做某几件事情的步骤都差不多,仅有那么一小点的不同,在软件开发的世界里同样如此,如果我们都将这些步骤都一一做的话,费时费力不讨好。所以我们可以将这些步骤分解、封装起来,然后利用继承的方式来继承即可,当然不同的可以自己重写实现嘛!这就是模板方法模式提供的解决方案。
所谓模板方法模式就是在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。
模板方法模式就是基于继承的代码复用技术的。在模板方法模式中,我们可以将相同部分的代码放在父类中,而将不同的代码放入不同的子类中。也就是说我们需要声明一个抽象的父类,将部分逻辑以具体方法以及具体构造函数的形式实现,然后声明一些抽象方法让子类来实现剩余的逻辑,不同的子类可以以不同的方式来实现这些逻辑。所以模板方法的模板其实就是一个普通的方法,只不过这个方法是将算法实现的步骤封装起来的。
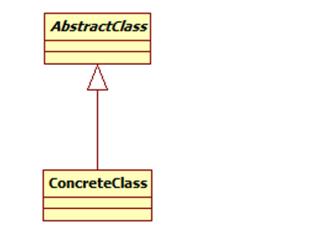
模板方法模式包含如下角色:
AbstractClass: 抽象类
ConcreteClass: 具体子类
15.策略模式
我们知道一件事可能会有很多种方式来实现它,但是其中总有一种最高效的方式,在软件开发的世界里面同样如此,我们也有很多中方法来实现一个功能,但是我们需要一种简单、高效的方式来实现它,使得系统能够非常灵活,这就是策略模式。
所以策略模式就是定义了算法族,分别封装起来,让他们之前可以互相转换,此模式然该算法的变化独立于使用算法的客户。
在策略模式中它将这些解决问题的方法定义成一个算法群,每一个方法都对应着一个具体的算法,这里的一个算法我就称之为一个策略。虽然策略模式定义了算法,但是它并不提供算法的选择,即什么算法对于什么问题最合适这是策略模式所不关心的,所以对于策略的选择还是要客户端来做。客户必须要清楚的知道每个算法之间的区别和在什么时候什么地方使用什么策略是最合适的,这样就增加客户端的负担。
同时策略模式也非常完美的符合了“开闭原则”,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。但是一个策略对应一个类将会是系统产生很多的策略类。
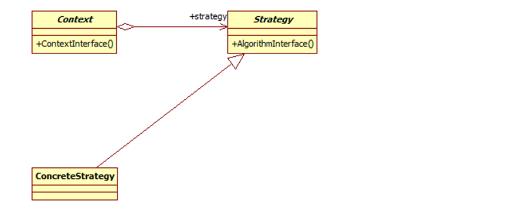
策略模式包含如下角色:
Context: 环境类
Strategy: 抽象策略类
ConcreteStrategy: 具体策略类
16.状态模式
在很多情况下我们对象的行为依赖于它的一个或者多个变化的属性,这些可变的属性我们称之为状态,也就是说行为依赖状态,即当该对象因为在外部的互动而导致他的状态发生变化,从而它的行为也会做出相应的变化。对于这种情况,我们是不能用行为来控制状态的变化,而应该站在状态的角度来思考行为,即是什么状态就要做出什么样的行为。这个就是状态模式。
所以状态模式就是允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
在状态模式中我们可以减少大块的if…else语句,它是允许态转换逻辑与状态对象合成一体,但是减少if…else语句的代价就是会换来大量的类,所以状态模式势必会增加系统中类或者对象的个数。
同时状态模式是将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。但是这样就会导致系统的结构和实现都会比较复杂,如果使用不当就会导致程序的结构和代码混乱,不利于维护。
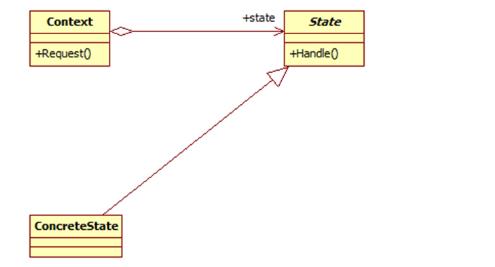
状态模式包含如下角色:
Context: 环境类
State: 抽象状态类
ConcreteState: 具体状态类
17.观察者模式
何谓观察者模式?观察者模式定义了对象之间的一对多依赖关系,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并且自动更新。
在这里,发生改变的对象称之为观察目标,而被通知的对象称之为观察者。一个观察目标可以对应多个观察者,而且这些观察者之间没有相互联系,所以么可以根据需要增加和删除观察者,使得系统更易于扩展。所以观察者提供了一种对象设计,让主题和观察者之间以松耦合的方式结合。
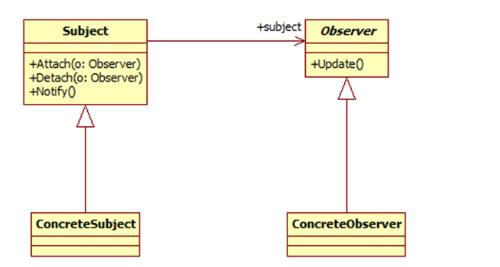
观察者模式包含如下角色:
Subject: 目标
ConcreteSubject: 具体目标
Observer: 观察者
ConcreteObserver: 具体观察者
18.备忘录模式
后悔药人人都想要,但是事实却是残酷的,根本就没有后悔药可买,但是也不仅如此,在软件的世界里就有后悔药!备忘录模式就是一种后悔药,它给我们的软件提供后悔药的机制,通过它可以使系统恢复到某一特定的历史状态。
所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。它实现了对信息的封装,使得客户不需要关心状态保存的细节。保存就要消耗资源,所以备忘录模式的缺点就在于消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。

备忘录模式包含如下角色:
Originator: 原发器
Memento: 备忘录
Caretaker: 负责人
19.中介者模式
租房各位都有过的经历吧!在这个过程中中介结构扮演着很重要的角色,它在这里起到一个中间者的作用,给我们和房主互相传递信息。在外面软件的世界里同样需要这样一个中间者。在我们的系统中有时候会存在着对象与对象之间存在着很强、复杂的关联关系,如果让他们之间有直接的联系的话,必定会导致整个系统变得非常复杂,而且可扩展性很差!在前面我们就知道如果两个类之间没有不必彼此通信,我们就不应该让他们有直接的关联关系,如果实在是需要通信的话,我们可以通过第三者来转发他们的请求。同样,这里我们利用中介者来解决这个问题。
所谓中介者模式就是用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。在中介者模式中,中介对象用来封装对象之间的关系,各个对象可以不需要知道具体的信息通过中介者对象就可以实现相互通信。它减少了对象之间的互相关系,提供了系统可复用性,简化了系统的结构。
在中介者模式中,各个对象不需要互相知道了解,他们只需要知道中介者对象即可,但是中介者对象就必须要知道所有的对象和他们之间的关联关系,正是因为这样就导致了中介者对象的结构过于复杂,承担了过多的职责,同时它也是整个系统的核心所在,它有问题将会导致整个系统的问题。所以如果在系统的设计过程中如果出现“多对多”的复杂关系群时,千万别急着使用中介者模式,而是要仔细思考是不是您设计的系统存在问题。
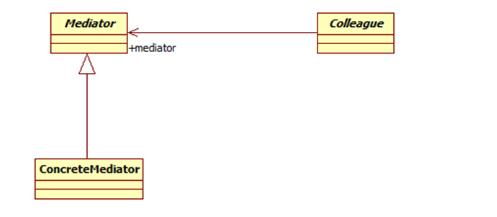
Mediator: 抽象中介者
ConcreteMediator: 具体中介者
Colleague: 抽象同事类
ConcreteColleague: 具体同事类
20.迭代器模式
对于迭代在编程过程中我们经常用到,能够游走于聚合内的每一个元素,同时还可以提供多种不同的遍历方式,这就是迭代器模式的设计动机。在我们实际的开发过程中,我们可能会需要根据不同的需求以不同的方式来遍历整个对象,但是我们又不希望在聚合对象的抽象接口中充斥着各种不同的遍历操作,于是我们就希望有某个东西能够以多种不同的方式来遍历一个聚合对象,这时迭代器模式出现了。
何为迭代器模式?所谓迭代器模式就是提供一种方法顺序访问一个聚合对象中的各个元素,而不是暴露其内部的表示。迭代器模式是将迭代元素的责任交给迭代器,而不是聚合对象,我们甚至在不需要知道该聚合对象的内部结构就可以实现该聚合对象的迭代。
通过迭代器模式,使得聚合对象的结构更加简单,它不需要关注它元素的遍历,只需要专注它应该专注的事情,这样就更加符合单一职责原则了。
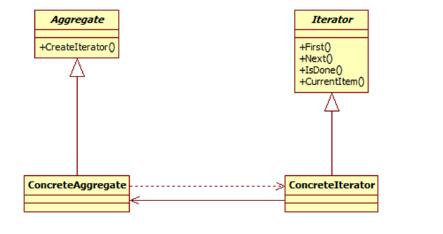
迭代器模式包含如下角色:
Iterator: 抽象迭代器
ConcreteIterator: 具体迭代器
Aggregate: 抽象聚合类
ConcreteAggregate: 具体聚合类
21.解释器模式
所谓解释器模式就是定义语言的文法,并且建立一个解释器来解释该语言中的句子。解释器模式描述了如何构成一个简单的语言解释器,主要应用在使用面向对象语言开发的编译器中。它描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。
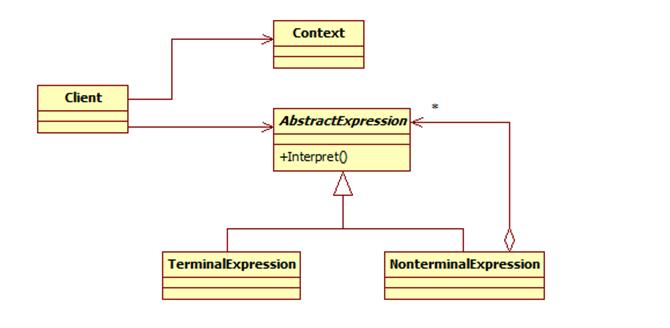
解释器模式包含如下角色:
AbstractExpression: 抽象表达式
TerminalExpression: 终结符表达式
NonterminalExpression: 非终结符表达式
Context: 环境类
Client: 客户类
22.命令模式
有些时候我们想某个对象发送一个请求,但是我们并不知道该请求的具体接收者是谁,具体的处理过程是如何的,们只知道在程序运行中指定具体的请求接收者即可,对于这样将请求封装成对象的我们称之为命令模式。所以命令模式将请求封装成对象,以便使用不同的请求、队列或者日志来参数化其他对象。同时命令模式支持可撤销的操作。
命令模式可以将请求的发送者和接收者之间实现完全的解耦,发送者和接收者之间没有直接的联系,发送者只需要知道如何发送请求命令即可,其余的可以一概不管,甚至命令是否成功都无需关心。同时我们可以非常方便的增加新的命令,但是可能就是因为方便和对请求的封装就会导致系统中会存在过多的具体命令类。
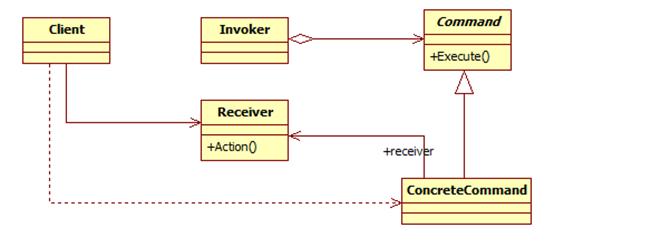
命令模式包含如下角色:
Command: 抽象命令类
ConcreteCommand: 具体命令类
Invoker: 调用者
Receiver: 接收者
Client:客户类
23.责任链模式
职责链模式描述的请求如何沿着对象所组成的链来传递的。它将对象组成一条链,发送者将请求发给链的第一个接收者,并且沿着这条链传递,直到有一个对象来处理它或者直到最后也没有对象处理而留在链末尾端。
避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止,这就是职责链模式。在职责链模式中,使得每一个对象都有可能来处理请求,从而实现了请求的发送者和接收者之间的解耦。同时职责链模式简化了对象的结构,它使得每个对象都只需要引用它的后继者即可,而不必了解整条链,这样既提高了系统的灵活性也使得增加新的请求处理类也比较方便。但是在职责链中我们不能保证所有的请求都能够被处理,而且不利于观察运行时特征。
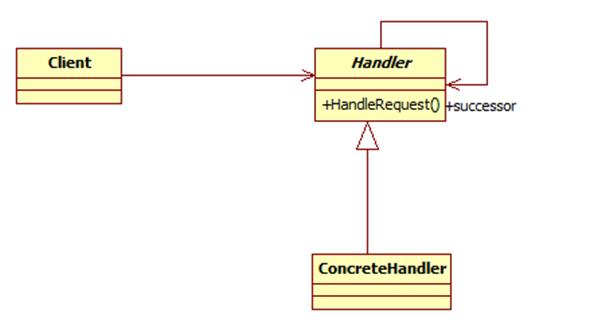
职责链模式包含如下角色:
Handler: 抽象处理者
ConcreteHandler: 具体处理者
Client: 客户类
二丶网络访问
1.OKhttp网络架构
OKHttp请求流程
OKHttp内部的大致请求流程图如下所示:
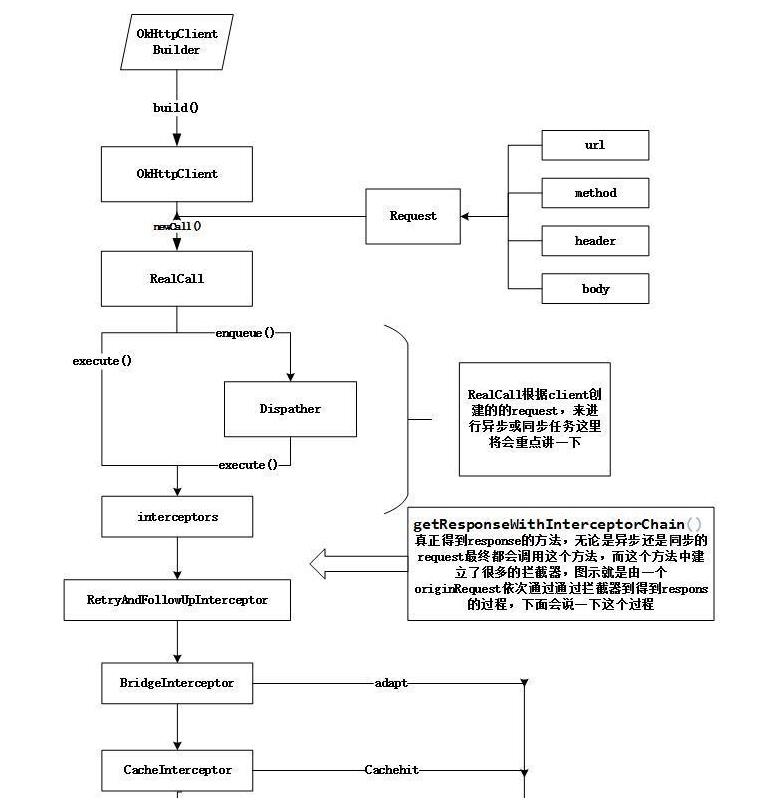
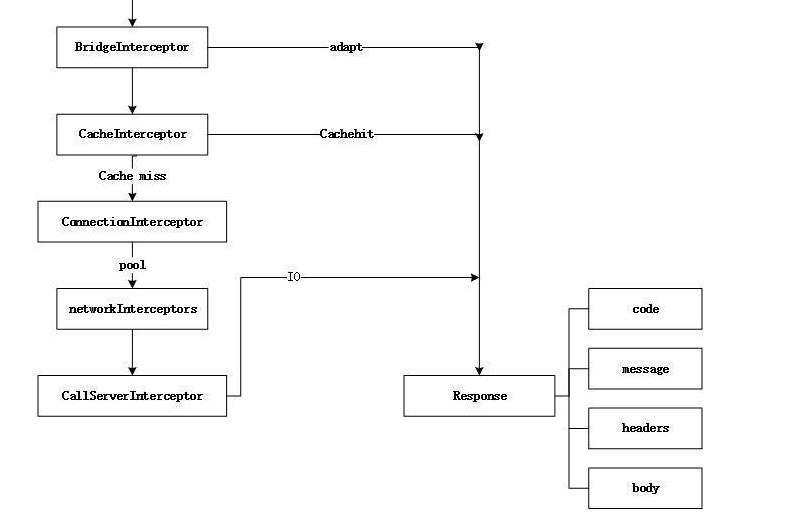
如下为使用OKHttp进行Get请求的步骤:
//1.新建OKHttpClient客户端
OkHttpClient client = new OkHttpClient();
//新建一个Request对象
Request request = new Request.Builder()
.url(url)
.build();
//2.Response为OKHttp中的响应
Response response = client.newCall(request).execute();
新建OKHttpClient客户端
OkHttpClient client = new OkHttpClient();
public OkHttpClient()
this(new Builder());
OkHttpClient(Builder builder)
....
可以看到,OkHttpClient使用了建造者模式,Builder里面的可配置参数如下:
public static final class Builder
Dispatcher dispatcher;// 分发器
@Nullable Proxy proxy;
List<Protocol> protocols;
List<ConnectionSpec> connectionSpecs;// 传输层版本和连接协议
final List<Interceptor> interceptors = new ArrayList<>();// 拦截器
final List<Interceptor> networkInterceptors = new ArrayList<>();
EventListener.Factory eventListenerFactory;
ProxySelector proxySelector;
CookieJar cookieJar;
@Nullable Cache cache;
@Nullable InternalCache internalCache;// 内部缓存
SocketFactory socketFactory;
@Nullable SSLSocketFactory sslSocketFactory;// 安全套接层socket 工厂,用于HTTPS
@Nullable CertificateChainCleaner certificateChainCleaner;// 验证确认响应证书 适用 HTTPS 请求连接的主机名。
HostnameVerifier hostnameVerifier;// 验证确认响应证书 适用 HTTPS 请求连接的主机名。
CertificatePinner certificatePinner;// 证书锁定,使用CertificatePinner来约束哪些认证机构被信任。
Authenticator proxyAuthenticator;// 代理身份验证
Authenticator authenticator;// 身份验证
ConnectionPool connectionPool;// 连接池
Dns dns;
boolean followSslRedirects; // 安全套接层重定向
boolean followRedirects;// 本地重定向
boolean retryOnConnectionFailure;// 重试连接失败
int callTimeout;
int connectTimeout;
int readTimeout;
int writeTimeout;
int pingInterval;
// 这里是默认配置的构建参数
public Builder()
dispatcher = new Dispatcher();
protocols = DEFAULT_PROTOCOLS;
connectionSpecs = DEFAULT_CONNECTION_SPECS;
...
// 这里传入自己配置的构建参数
Builder(OkHttpClient okHttpClient)
this.dispatcher = okHttpClient.dispatcher;
this.proxy = okHttpClient.proxy;
this.protocols = okHttpClient.protocols;
this.connectionSpecs = okHttpClient.connectionSpecs;
this.interceptors.addAll(okHttpClient.interceptors);
this.networkInterceptors.addAll(okHttpClient.networkInterceptors);
...
同步请求流程
Response response = client.newCall(request).execute();
/**
* Prepares the @code request to be executed at some point in the future.
*/
@Override public Call newCall(Request request)
return RealCall.newRealCall(this, request, false /* for web socket */);
// RealCall为真正的请求执行者
static RealCall newRealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket)
// Safely publish the Call instance to the EventListener.
RealCall call = new RealCall(client, originalRequest, forWebSocket);
call.eventListener = client.eventListenerFactory().create(call);
return call;
@Override public Response execute() throws IOException
synchronized (this)
// 每个Call只能执行一次
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
captureCallStackTrace();
timeout.enter();
eventListener.callStart(this);
try
// 通知dispatcher已经进入执行状态
client.dispatcher().executed(this);
// 通过一系列的拦截器请求处理和响应处理得到最终的返回结果
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
catch (IOException e)
e = timeoutExit(e);
eventListener.callFailed(this, e);
throw e;
finally
// 通知 dispatcher 自己已经执行完毕
client.dispatcher().finished(this);
Response getResponseWithInterceptorChain() throws IOException
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
// 在配置 OkHttpClient 时设置的 interceptors;
interceptors.addAll(client.interceptors());
// 负责失败重试以及重定向
interceptors.add(retryAndFollowUpInterceptor);
// 请求时,对必要的Header进行一些添加,接收响应时,移除必要的Header
interceptors.add(new BridgeInterceptor(client.cookieJar()));
// 负责读取缓存直接返回、更新缓存
interceptors.add(new CacheInterceptor(client.internalCache()));
// 负责和服务器建立连接
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket)
// 配置 OkHttpClient 时设置的 networkInterceptors
interceptors.addAll(client.networkInterceptors());
// 负责向服务器发送请求数据、从服务器读取响应数据
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
// 使用责任链模式开启链式调用
return chain.proceed(originalRequest);
// StreamAllocation 对象,它相当于一个管理类,维护了服务器连接、并发流
// 和请求之间的关系,该类还会初始化一个 Socket 连接对象,获取输入/输出流对象。
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException
...
// Call the next interceptor in the chain.
// 实例化下一个拦截器对应的RealIterceptorChain对象
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
// 得到当前的拦截器
Interceptor interceptor = interceptors.get(index);
// 调用当前拦截器的intercept()方法,并将下一个拦截器的RealIterceptorChain对象传递下去,最后得到响应
Response response = interceptor.intercept(next);
...
return response;
异步请求流程
Request request = new Request.Builder()
.url("http://publicobject.com/helloworld.txt")
.build();
client.newCall(request).enqueue(new Callback()
@Override
public void onFailure(Call call, IOException e)
e.printStackTrace();
@Override
public void onResponse(Call call, Response response) throws IOException
...
void enqueue(AsyncCall call)
synchronized (this)
readyAsyncCalls.add(call);
promoteAndExecute();
// 正在准备中的异步请求队列
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
// 运行中的异步请求
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
// 同步请求
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
// Promotes eligible calls from @link #readyAsyncCalls to @link #runningAsyncCalls and runs
// them on the executor service. Must not be called with synchronization because executing calls
// can call into user code.
private boolean promoteAndExecute()
assert (!Thread.holdsLock(this));
List<AsyncCall> executableCalls = new ArrayList<>();
boolean isRunning;
synchronized (this)
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); )
AsyncCall asyncCall = i.next();
// 如果其中的runningAsynCalls不满,且call占用的host小于最大数量,则将call加入到runningAsyncCalls中执行,
// 同时利用线程池执行call;否者将call加入到readyAsyncCalls中。
if (runningAsyncCalls.size() >= maxRequests) break; // Max capacity.
if (runningCallsForHost(asyncCall) >= maxRequestsPerHost) continue; // Host max capacity.
i.remove();
executableCalls.add(asyncCall);
runningAsyncCalls.add(asyncCall);
isRunning = runningCallsCount() > 0;
for (int i = 0, size = executableCalls.size(); i < size; i++)
AsyncCall asyncCall = executableCalls.get(i);
asyncCall.executeOn(executorService());
return isRunning;
最后,我们在看看AsynCall的代码。
final class AsyncCall extends NamedRunnable
private final Callback responseCallback;
AsyncCall(Callback responseCallback)
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
String host()
return originalRequest.url().host();
Request request()
return originalRequest;
RealCall get()
return RealCall.this;
/**
* Attempt to enqueue this async call on @code executorService. This will attempt to clean up
* if the executor has been shut down by reporting the call as failed.
*/
void executeOn(ExecutorService executorService)
assert (!Thread.holdsLock(client.dispatcher()));
boolean success = false;
try
executorService.execute(this);
success = true;
catch (RejectedExecutionException e)
InterruptedIOException ioException = new InterruptedIOException("executor rejected");
ioException.initCause(e);
eventListener.callFailed(RealCall.this, ioException);
responseCallback.onFailure(RealCall.this, ioException);
finally
if (!success)
client.dispatcher().finished(this); // This call is no longer running!
@Override protected void execute()
boolean signalledCallback = false;
timeout.enter();
try
// 跟同步执行一样,最后都会调用到这里
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled())
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
else
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
catch (IOException e)
e = timeoutExit(e);
if (signalledCallback)
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
else
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
finally
client.dispatcher().finished(this);
从上面的源码可以知道,拦截链的处理OKHttp帮我们默认做了五步拦截处理,其中RetryAndFollowUpInterceptor、BridgeInterceptor、CallServerInterceptor内部的源码很简洁易懂,此处不再多说。
网络请求缓存处理之CacheInterceptor
@Override public Response intercept(Chain chain) throws IOException
// 根据request得到cache中缓存的response
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
// request判断缓存的策略,是否要使用了网络,缓存或两者都使用
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
if (cache != null)
cache.trackResponse(strategy);
if (cacheCandidate != null && cacheResponse == null)
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
// If we're forbidden from using the network and the cache is insufficient, fail.
if (networkRequest == null && cacheResponse == null)
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
// If we don't need the network, we're done.
if (networkRequest == null)
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
Response networkResponse = null;
try
// 调用下一个拦截器,决定从网络上来得到response
networkResponse = chain.proceed(networkRequest);
finally
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null)
closeQuietly(cacheCandidate.body());
// If we have a cache response too, then we're doing a conditional get.
// 如果本地已经存在cacheResponse,那么让它和网络得到的networkResponse做比较,决定是否来更新缓存的cacheResponse
if (cacheResponse != null)
if (networkResponse.code() == HTTP_NOT_MODIFIED)
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
else
closeQuietly(cacheResponse.body());
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null)
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest))
// Offer this request to the cache.
// 缓存未经缓存过的response
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
if (HttpMethod.invalidatesCache(networkRequest.method()))
try
cache.remove(networkRequest);
catch (IOException ignored)
// The cache cannot be written.
return response;
缓存拦截器会根据请求的信息和缓存的响应的信息来判断是否存在缓存可用,如果有可以使用的缓存,那么就返回该缓存给用户,否则就继续使用责任链模式来从服务器中获取响应。当获取到响应的时候,又会把响应缓存到磁盘上面。
ConnectInterceptor之连接池
@Override public Response intercept(Chain chain) throws IOException
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
// HttpCodec是对 HTTP 协议操作的抽象,有两个实现:Http1Codec和Http2Codec,顾名思义,它们分别对应 HTTP/1.1 和 HTTP/2 版本的实现。在这个方法的内部实现连接池的复用处理
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
// Returns a connection to host a new stream. This // prefers the existing connection if it exists,
// then the pool, finally building a new connection.
// 调用 streamAllocation 的 newStream() 方法的时候,最终会经过一系列
// 的判断到达 StreamAllocation 中的 findConnection() 方法
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException
...
// Attempt to use an already-allocated connection. We need to be careful here because our
// already-allocated connection may have been restricted from creating new streams.
// 尝试使用已分配的连接,已经分配的连接可能已经被限制创建新的流
releasedConnection = this.connection;
// 释放当前连接的资源,如果该连接已经被限制创建新的流,就返回一个Socket以关闭连接
toClose = releaseIfNoNewStreams();
if (this.connection != null)
// We had an already-allocated connection and it's good.
result = this.connection;
releasedConnection = null;
if (!reportedAcquired)
// If the connection was never reported acquired, don't report it as released!
// 如果该连接从未被标记为获得,不要标记为发布状态,reportedAcquired 通过 acquire() 方法修改
releasedConnection = null;
if (result == null)
// Attempt to get a connection from the pool.
// 尝试供连接池中获取一个连接
Internal.instance.get(connectionPool, address, this, null);
if (connection != null)
foundPooledConnection = true;
result = connection;
else
selectedRoute = route;
// 关闭连接
closeQuietly(toClose);
if (releasedConnection != null)
eventListener.connectionReleased(call, releasedConnection);
if (foundPooledConnection)
eventListener.connectionAcquired(call, result);
if (result != null)
// If we found an already-allocated or pooled connection, we're done.
// 如果已经从连接池中获取到了一个连接,就将其返回
return result;
// If we need a route selection, make one. This is a blocking operation.
boolean newRouteSelection = false;
if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext()))
newRouteSelection = true;
routeSelection = routeSelector.next();
synchronized (connectionPool)
if (canceled) throw new IOException("Canceled");
if (newRouteSelection)
// Now that we have a set of IP addresses, make another attempt at getting a connection from
// the pool. This could match due to connection coalescing.
// 根据一系列的 IP地址从连接池中获取一个链接
List<Route> routes = routeSelection.getAll();
for (int i = 0, size = routes.size(); i < size;i++)
Route route = routes.get(i);
// 从连接池中获取一个连接
Internal.instance.get(connectionPool, address, this, route);
if (connection != null)
foundPooledConnection = true;
result = connection;
this.route = route;
break;
if (!foundPooledConnection)
if (selectedRoute == null)
selectedRoute = routeSelection.next();
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
以上是关于架构大合集,轻松应对工作需求(上)的主要内容,如果未能解决你的问题,请参考以下文章