大数据计算能力 CPUGPU 和 DPU 有何不同
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据计算能力 CPUGPU 和 DPU 有何不同相关的知识,希望对你有一定的参考价值。
在这个大数据世界中,并行处理或并行计算是对传入系统的大数据进行更快处理和计算的解决方案。尽管在大多数情况下,多核 CPU 用于并行处理,但当涉及到大规模并行处理时,基于 CPU 的算法或基于多核 CPU 的算法速度不够快,无法在合理的时间内给出解决方案。这产生了最初用于游戏目的、图形和图像处理等的 GPU。此外,DPU(数据处理单元)的概念通过使用多个 CPU 和多个 GPU 在非常短的时间内进行大量大数据计算。

1. CPU(Central Processing Unit 中央处理器)
让我们从基础开始了解 CPU,让我们考虑一下个人计算机中的 CPU,当您升级 PC 进行游戏或视频编辑时,该 CPU 与内存 (RAM)、硬盘驱动器和 NIC(网络接口控制器)相连目的是您将获得额外的 GPU 连接到 CPU 和更快的内存访问 SSD 现在可以成为一种选择。所以下面是基本的CPU框图。
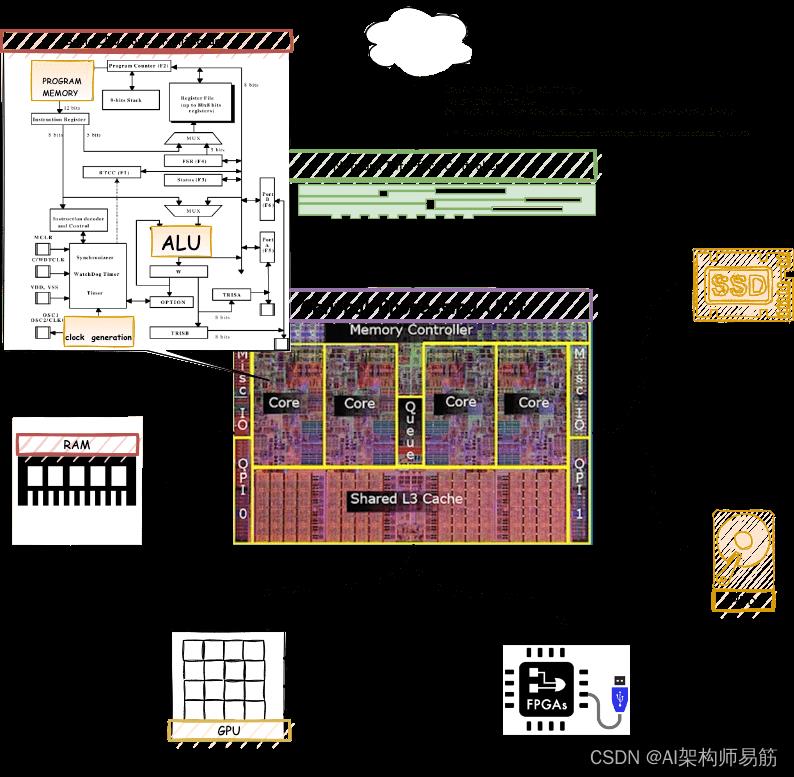
当我们专门谈论普通 PC 中的 CPU 时,它具有 4 到 8 个主频为 2 到 3 GHz 的灵活内核,数据中心的 CPU 可以拥有更多的内核和时钟速度。多核允许更轻松地同时进行并行数据处理或并行线程,高时钟速度意味着更快的处理速度。ALU (Arithmetic and logical unit 算术和逻辑单元)在CPU 内核中很重要,它负责算术和逻辑运算。CPU包含较少但功能强大的核心,而GPU可以拥有很多核心但在时钟速度方面的功率较低。


如果您与云提供商合作,您已经听说过 vCPU 这个词-centre 对于较小的实例而言价格非常高,因此对 CPU 及其内核的要求可能较低,因此我们可以使用内核较少的数据中心的物理 CPU 作为较小实例的虚拟 CPU。
给定一个物理 CPU,Intel Xeon Platinum R8282 处理器,CPU 规格核心数为 56,添加线程数 112 根据上述计算 vCPU 的公式使用 vCPU 的数量为:

= (112 *56) * 1 = 6272 个 vCPU
2. GPU( Graphics Processing Unit 图形处理单元):
从上面的基本 CPU 中,让我们通过比较两者来了解更多关于 CPU 和 GPU 的信息,以及为什么从游戏和图像/视频处理中,GPU 现在也用于计算深度学习神经网络和人工智能。当涉及算术运算和逻辑运算等常规计算时,CPU 速度更快,但在大型矩阵乘法和并行算法方面,GPU 排在第一位,那么为什么 GPU 和矩阵乘法呢?这是因为大多数机器学习深度学习算法都使用矩阵乘法,例如,在神经网络中,全连接层 l 中神经元 j的输出 y ( l ) ( j ) y^(l)(j) y(l)(j) 由下式给出
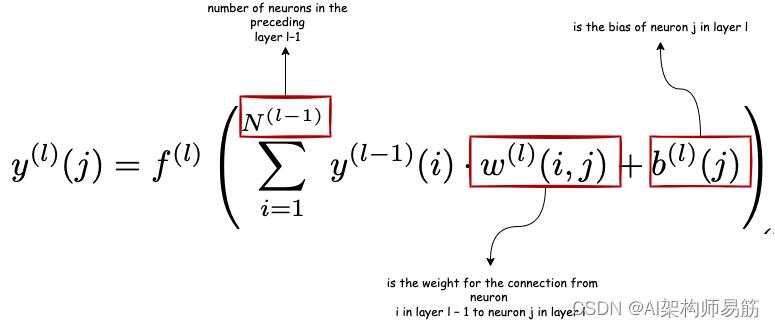
等式中的这些先前权重可以存储在与内核相关的缓存中,并且乘法可以使用 GPU 拥有的数千个内核并行发生,这些内核的时钟速度较低或内核较弱,但在并行计算中很有效,而且每个内核都有自己的 ALU。
CUDA(Compute Unified Device Architecture 计算统一设备架构)描述了 NVIDIA 的专有语言,它基于 C 并包含一些特殊的扩展,以实现高效的编程。扩展主要涵盖在 GPU 上启用多线程和访问 GPU 上不同类型内存的命令。
所有云提供商都提供:
- 计算优化实例——高性能处理器、大量内存 (RAM)。
- 加速计算(基于硬件的计算加速器,例如图形处理单元 (GPU)、现场可编程门阵列 (FPGA - Field Programmable Gate Arrays)
2.1 FPGA - Field Programmable Gate Arrays 现场可编程门阵列
FPGA代表Field Programmable Gate Array,本质上它是一个硬件,可以根据用户需要多次编程,它可以将任意方程转换或实现为布尔方程的形式,因此,将其实现为组合和顺序逻辑。简单地说,一个FPGA可以用来实现任何逻辑功能。与图形处理单元 (GPU) 或 ASIC 不同,FPGA 芯片内部的电路不是硬蚀刻的——它可以根据需要重新编程。这种能力使 FPGA 成为 ASIC 的绝佳替代品,后者需要较长的开发时间和大量的设计和制造投资。
基于 FPGA 的实例提供对具有数百万个并行系统逻辑单元的大型 FPGA 的访问。您可以使用基于 FPGA 的加速计算实例,通过利用自定义硬件加速来加速基因组学、财务分析、实时视频处理、大数据分析和安全工作负载等工作负载。设计人员可以从头开始构建神经网络,并构建最适合模型的 FPGA。当应用程序需要低延迟和低批量大小时,FPGA 可以提供优于 GPU 的性能优势。

与 GPU 相比,FPGA 可以在低延迟至关重要的深度学习应用中提供卓越的性能。可以对 FPGA 进行微调以平衡电源效率和性能要求。
3. DPU(Data Processing Unit 数据处理单元)
在计算机体系结构中,CPU 具有多种职责,例如运行您的应用程序、执行计算,同时它扮演着数据流量控制器的角色,在 GPU、存储、FPGA 等之间移动数据,因此 CPU 更加以计算机为中心以数据为中心的架构的要求。新的架构应该让资源直接访问网络,让他们最擅长的任务。
数据处理单元或 DPU 应该扮演数据流量控制器的角色,从这个 IO 密集型任务中卸载 CPU,但它的效率比 CPU 高几个数量级,特别是 DPU 应该从网络发送和接收数据包加密和压缩服务器周围的大量数据并运行防火墙以保护服务器免受滥用。DPU 应该使分布在服务器上的异构计算和存储资源能够集中起来,以最大限度地提高利用率,从而降低计算机和存储资源的总拥有成本。DPU 等数据引擎将使数据中心能够达到计算大量数据所需的效率和速度,许多云 ETL 产品以分布式方式提供 DPU 来执行数据处理,
AWS 提供名为 AWS 胶水的 ETL 无服务器服务,AWS 胶水使用 DPU,这些 DPU 成为工作节点并执行内存计算。AWS Glue 中有不同的工作线程类型。
- The standard worker 标准工作者:16 GB 内存、4 个 vCPU 的计算容量和 50 GB 附加的 EBS 存储和 2 个 Spark 执行器。
- G.1X worker:16 GB 内存、4 个 vCPU 和 64 GB 附加 EBS 存储。(1 个 Spark 执行器 = 1 个 DPU)
- G.2X worker :内存、磁盘空间和 vCPU 是 G.1X worker 类型的两倍。(1 个 Spark 执行器 =2 DPU)。
4. 关键概念:
- 算法可以是顺序的,也可以是并行的,有些算法在顺序上执行得很好,有些在并行计算中执行得特别快。
- CPU 内核越多,可用于并行计算/处理的线程就越多。
- 单个 CPU 可以有多个内核,因此单独的 CPU 可以处理并行处理,直到需要在同一时间点处理超过数千个线程的大规模并行处理。
- GPU 有数以千计的核心,并有像 CUDA 这样的 API 用于对它们进行编程以进行计算。
- 在分布式计算中,可以有多个实例具有 CPU/DPU 或 CPU-GPU 或 DPU-vCPU 或 DPU-vCPU-GPU。数据被分区,每个分区被分配给每个实例/DPU。每个实例都可以再次使用内核并行进行大规模计算。
- 如果内存涉及的是内存(RAM),则可以更快地完成分布式计算,Apache Spark 方式。许多云提供商提供了以内存中并行分布的方式计算海量数据的实例。
- 分布式计算可以使用大量内存(HDD/SSD)和更少的 RAM 来完成,创建大量分区数据的副本以实现容错并应用 MapReduce。
参考
https://statusneo.com/big-data-computing-power-cpu-vs-gpu-vs-dpu/
https://www.techtarget.com/searchdatacenter/tip/How-do-CPU-GPU-and-DPU-differ-from-one-another
以上是关于大数据计算能力 CPUGPU 和 DPU 有何不同的主要内容,如果未能解决你的问题,请参考以下文章