Hadoop集群配置
Posted AmwQqwWmg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群配置相关的知识,希望对你有一定的参考价值。
文章目录
- Hadoop是什么
- 开始搭建Hadoop集群
Hadoop是什么
1. 分布式系统基础架构
2. 解决海量数据的存储与分析计算
3. Hadoop广义是指Hadoop生态圈
Hadoop的优势
1. 高可靠性:底层维护多个数据副本,一个故障不会导致数据的丢失
2. 高扩展性:在集群间分配数据,可动态增加服务器
3. 高效性: 使用MapReduce思想,并行工作加快处理速度
4. 高容错性:能够自动将失败的任务重新分配
Hadoop组成
HDFS概述
| 名称 | 作用 |
|---|---|
| NameNode(NN) | 存储文件的元数据,如文件名,文件目录结构,文件属性,以及每个文件的块列表和块所在的块列表 |
| DataNode(DN) | 在本地文件系统存储文件块数据,以及块数据的校验和 |
| SecondaryNameNode(2NN) | 每一段时间对NameNode元数据备份 |
Yarn架构
| 名称 | 作用 |
|---|---|
| Resource Manager(RM) | 管理整个集群的资源 |
| Node Manager(NM) | 管理单个服务器资源 |
| ApplicationMaster(AM) | 管理单个任务 |
| Container | 相当于一个独立服务器,里面包含了任务运行所需的资源 |
MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce
1. Map阶段并行处理输入数据
2. Reduce阶段对Map结果进行汇总
开始搭建Hadoop集群
点击下载 CentOS-7
点击下载 VMware16 pro
点击跳转 XSHELL和XFTP教育版下载
点击跳转 ORACLE JDK8
点击下载 Hadoop-3.1.3
一、安装VMware
二、新建虚拟机,安装CentOS
三、配置主机
以下全文中的username均为代指你的用户名,在复制命令时注意替换
1、授予你的用户sudo权限,并且新建两个目录,所有权改为你的用户
鼠标右键桌面,找到在终端打开
# 输入密码后进入最高权限root角色
su
# 给自己新建的用户增加sudo权限'
vi /etc/sudoers
# ##Allows people in group wheel to run all commands
# %wheel ALL=(ALL) ALL'
# 在此处下面添加
username ALL=(ALL) NOPASSWD:ALL
# 切换新建用户
su username
# 前往/opt目录,新建module文件夹和software文件夹
cd /opt
sudo mkdir module
sudo mkdir software
# 将文件所有权交给新建用户
sudo chown username:username module software
2、修改网络配置
# 修改网络配置
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改主机名称
sudo vi /etc/hostname
# 配置IP对主机名的映射
sudo vi /etc/hosts
网络配置改为:IP的前三个网段要与自己Vnet8的网段保持一致(具体到windows上的查询方法为在CMD里面输入ipconfig即可找到)
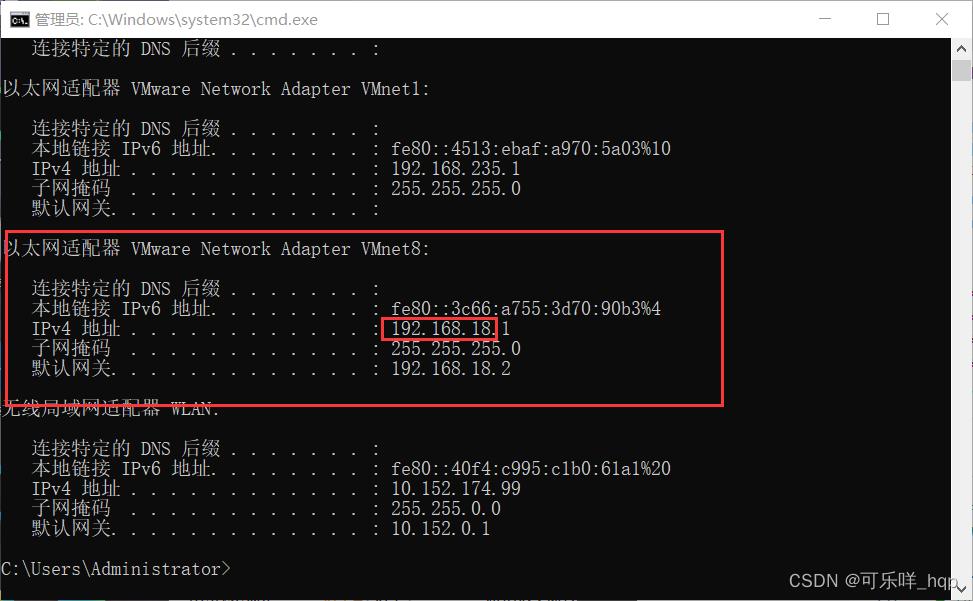
ifcfg-ens33
# 把BOOTPROTO的值由dhcp修改为static
BOOTPROTO="static"
# 后面加上四行
# 前三个网段 + 3~255任意数字,建议130开始,后续主机这个值递增即可
IPADDR=192.168.18.130
# 默认值,不更改
NETMASK=255.255.255.0
# 前三个网段 + 最后一段固定为2
GATEWAY=192.168.18.2
# 与上一行保持一致即可
DNS1=192.168.18.2
hostname
# 删除原内容,写入你的主机名称即可
hosts
IP对主机名映射样板如下:
# 自带的内容可以删除
# 前面是你的主机的ip地址,后面是你的主机名,后续可以直接ping主机名通过这个文件来找到对应ip
192.168.18.130 master
192.168.18.131 slave1
192.168.18.132 slave2
192.168.18.133 slave3
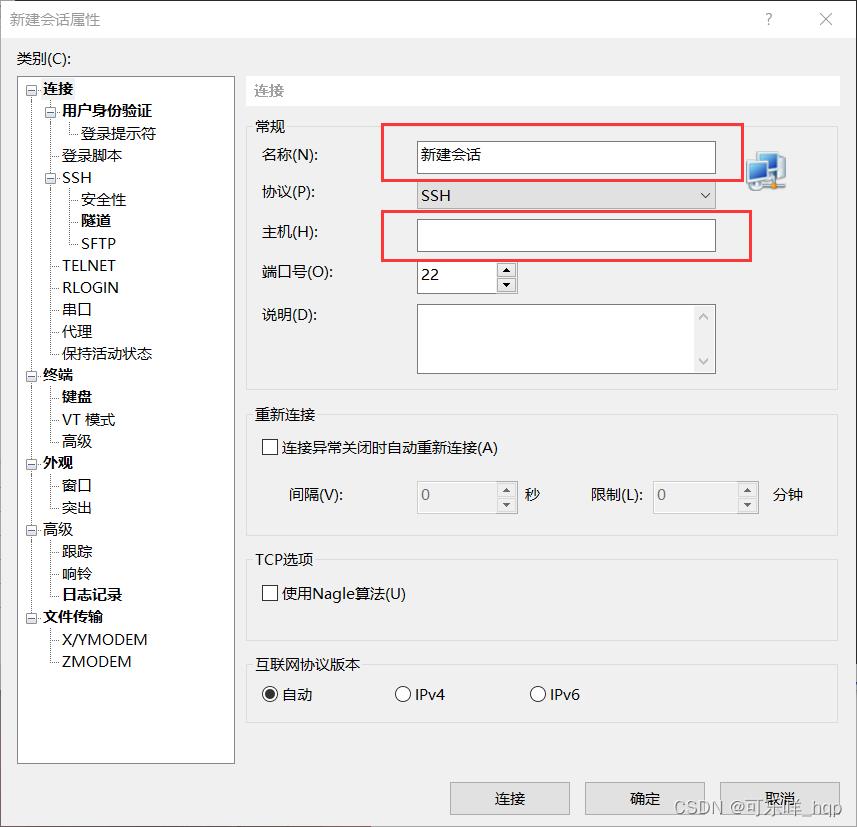
四、连接XShell
- 打开XShell,新建会话
- 名称随意填写,主机填写IP即可连接(连接不上可以重启虚拟机一下重试)
- 用户输入你新建的用户,密码即可(不建议root连接)
五、禁用防火墙和禁用selinux
# 关闭防火墙、禁止自启动防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld.service
# SELINUX的enforcing修改为disabled
sudo vi /etc/selinux/config
六、安装配置java
注意你下载的jdk的版本可能会不一致,注意更改文件名
# 如果机器已经自带了jdk,用如下命令卸载
su
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
# 进入software目录
cd /opt/software
# 在XSHELL上方有打开XFTP
# 利用XFTP将jdk8和Hadoop的压缩包放在/opt/software目录下
# 解压jdk输出到/opt/module/
tar -zxvf jdk-8u341-linux-x64.tar.gz -C /opt/module/
# 配置环境变量
su
echo '#JAVA_HOME' >> /etc/profile.d/my_env.sh
echo 'export JAVA_HOME=/opt/module/jdk1.8.0_341' >> /etc/profile.d/my_env.sh
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile.d/my_env.sh
# 载入新的配置文件
source /etc/profile
七、安装配置Hadoop
安装Hadoop并且配置环境变量
# 解压hadoop到输出/opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 配置环境变量
su
echo '#HADOOP_HOME' >> /etc/profile.d/my_env.sh
echo 'export HADOOP_HOME=/opt/module/hadoop-3.1.3' >> /etc/profile.d/my_env.sh
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile.d/my_env.sh
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile.d/my_env.sh
# 载入新的配置文件
source /etc/profile
配置Hadoop配置文件
cd /opt/module/hadoop-3.1.3/etc/hadoop
vi core-site.xml
vi hdfs-site.xml
vi yarn-site.xml
vi mapred-site.xml
vi workers
1. core-site.xml
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
2. hdfs-site.xml
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>username</value>
</property>
</configuration>
3. yarn-site.xml
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,PATH,LANG,TZ</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://slave1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
4. mapred-site.xml
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>slave2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>slave2:19888</value>
</property>
</configuration>
5. workers:
master
slave1
slave2
slave3
八、利用VMware复制四台服务器
- 关闭主机
- 复制机器
- 打开每一台机器,然后每台机器执行一遍的“三、配置主机”下的“2.修改网络配置”即可
九. 搭建全分布式
配置免密登录
以下命令注意使用xshell多开,减少重复工作
- 打开XShell多开
上方菜单栏工具 --> 发送输入到 --> 所有会话
# 创建当前主机rsa密钥
ssh-keygen -t rsa
# 拷贝hostname的密钥到本地,需要进行多次操作保证每一台主机拥有所有主机的密钥
ssh-copy-id -i master
ssh-copy-id -i slave1
·
·
·
ssh-copy-id -i slaven
# 尝试免密连接其他主机,建议多次尝试,避免问题发生
ssh master