深度学习基于卷积神经网络的验证码识别
Posted 林夕07
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基于卷积神经网络的验证码识别相关的知识,希望对你有一定的参考价值。
活动地址:CSDN21天学习挑战赛
目录
前言
关于环境这里不再赘述,与【深度学习】基于卷积神经网络的天气识别训练文中的环境一致,如还是配置不成功,请看该文章末尾的详细包配置。
了解captcha数据集
这里面包含了1070张手写验证码图片。并以正常的验证码作为图片的名称。所以后期需要手动进行拆分测试集和验证集,以及需要手动提取所有图片名称中的的验证码。
下载weather_photos数据集
可以私信我发你(因为该数据集已经被上传到csdn了,所以不能重复上传哦)
采用CPU训练还是GPU训练
一般来说有好的显卡(GPU)就使用GPU训练因为快,那么对应的你就要下载tensorflow-gpu包。如果你的显卡较差或者没有足够资金入手一款好的显卡就可以使用CUP训练。
区别
(1)CPU主要用于串行运算;而GPU则是大规模并行运算。由于深度学习中样本量巨大,参数量也很大,所以GPU的作用就是加速网络运算。
(2)CPU计算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。而目前GPU运算主要集中在矩阵乘法和卷积上,其他的逻辑运算速度并没有CPU快。
使用CPU训练
# 使用cpu训练
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
使用CPU训练时不会显示CPU型号。

使用GPU训练
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
使用GPU训练时会显示对应的GPU型号。

支持中文
使用import matplotlib.pyplot as plt 导入库,。plt是代表画图的库。库内的配置(configuration)是固定好的,但有时我们想要修改plt的配置参数来满足画图需求。
可用plt.rcParams['配置参数']=[修改值]进行修改,rcParams即(run configuration parameters)运行配置参数。
plt.rcParams['font.sans-serif'] = ['SimHei'] #运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['axes.unicode_minus'] = False #运行配置参数总的轴(axes)正常显示正负号(minus)
导入数据
这里我们见numpy的随机种子和tf的随机种子设为固定值,让训练的结果尽量稳定。这里将本地存放数据集的路径给到data_dir变量中。
import matplotlib.pyplot as plt
import PIL
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
tf.random.set_seed(1)
from tensorflow import keras
from tensorflow.keras import layers, models
import pathlib
data_dir = "E:\\\\PythonProject\\\\day6\\\\data\\\\captcha\\\\"
data_dir = pathlib.Path(data_dir)
# 提取所有照片的路径
all_image_paths = list(data_dir.glob('*'))
all_image_paths = [str(path) for path in all_image_paths]
# 打乱数据 因为文件默认按照文件名的字母排序,所以需要打乱顺序
random.shuffle(all_image_paths)
# 获取数据标签 通过拆分图片名称的后缀见所有的验证码字符串提取出来
# 验证码长度是5位,且都已.png结尾 然后进行拆分
all_label_names = [path.split("\\\\")[5].split(".")[0] for path in all_image_paths]
查看数据量
image_count = len(all_image_paths)
print("图片总数为:", image_count)
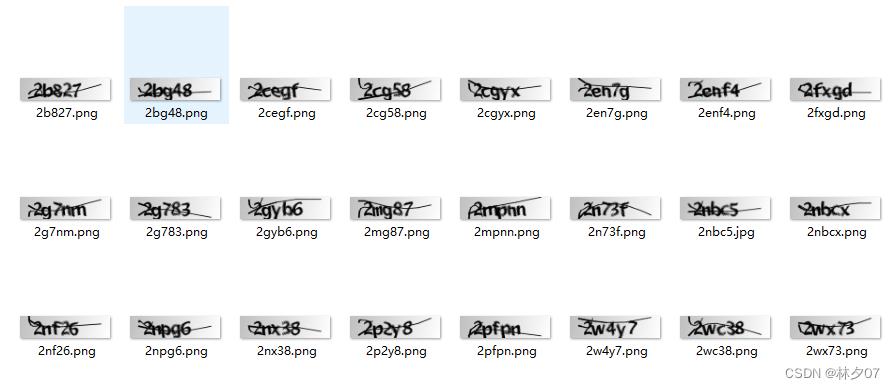
显示部分图片
绘制前20张,每行5个共四行。
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
images = plt.imread(all_image_paths[i])
plt.imshow(images)
# 显示标签
plt.xlabel(all_label_names[i])
plt.show()
绘制结果:
预处理
手动设置标签
设计一个数组用来存放验证码中出现所有的数字+字符。
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in all_label_names]
直接看代码可能有点迷糊,下面这个图就是最后的效果,相当于是个三维数组,第一维度表示每张图片,第二维度表示多个字符集,第三维度表示每位的验证码应该是什么字符,有在对应的位置上是0,无则0。

灰度化处理
灰度化,在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。公式如下:

平均值法
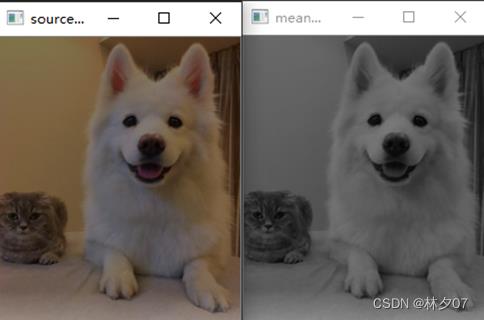
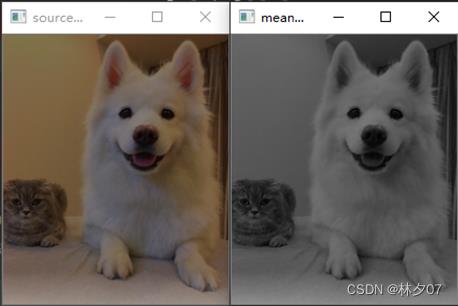
将彩色图像中的三分量亮度求平均得到一个灰度图。本文就采用的是平均值法处理的的照片。

下图就是以平均法进行灰度化。左边是原图,右边是灰度化后的图片。
加权平均法
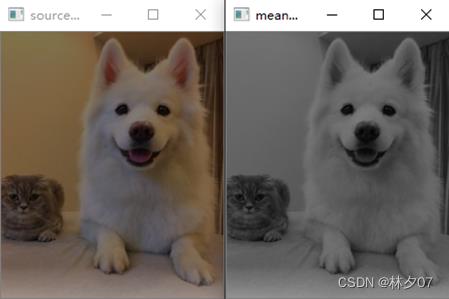
此方法是根据之前某段时间内的观测值作为基础,用它来预算将来此值可能的走向的一种方法。
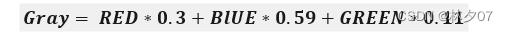
下图就是以平均法进行灰度化。左边是原图,右边是灰度化后的图片。
cvtColor
OpenCV的API cvtColor函数也可以实现灰度化处理。下图就是以平均法进行灰度化。左边是原图,右边是灰度化后的图片。
加载数据
这里使用的是from_tensor_slices 方法。该函数是dataset核心函数之一,它的作用是把给定的元组、列表和张量等数据进行特征切片。切片的范围是从最外层维度开始的。如果有多个特征进行组合,那么一次切片是把每个组合的最外维度的数据切开,分成一组一组的。
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
# 拆分数据集 将前1000个作为训练集 剩余的作为测试集
train_ds = image_label_ds.take(1000)
val_ds = image_label_ds.skip(1000)
配置数据集(加快速度)
shuffle():该函数是将列表的所有元素随机排序。 有时候我们的任务中会使用到随机sample一个数据集的某些数,比如一个文本中,有10行,我们需要随机选取前5个。
prefetch():prefetch是预取内存的内容,程序员告诉CPU哪些内容可能马上用到,CPU预取,用于优化。
BATCH_SIZE = 16
train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
建立CNN模型
这里的模型与前几篇的大致相同,就不做过多介绍了。
from tensorflow.keras import datasets, layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(label_name_len * char_set_len),
layers.Reshape([label_name_len, char_set_len]),
layers.Softmax()
])
model.summary() # 打印网络结构
网络结构
包含输入层的话总共10层
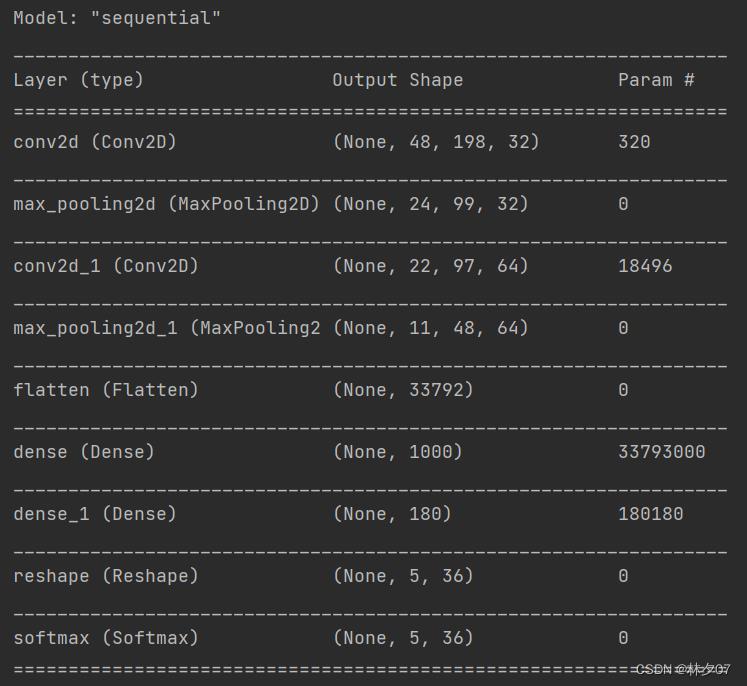
参数量
总共参数为33M,参数量更加庞大但是数据集不是很多问题不大。建议采用GPU训练。
Total params: 33,991,996
Trainable params: 33,991,996
Non-trainable params: 0
训练模型
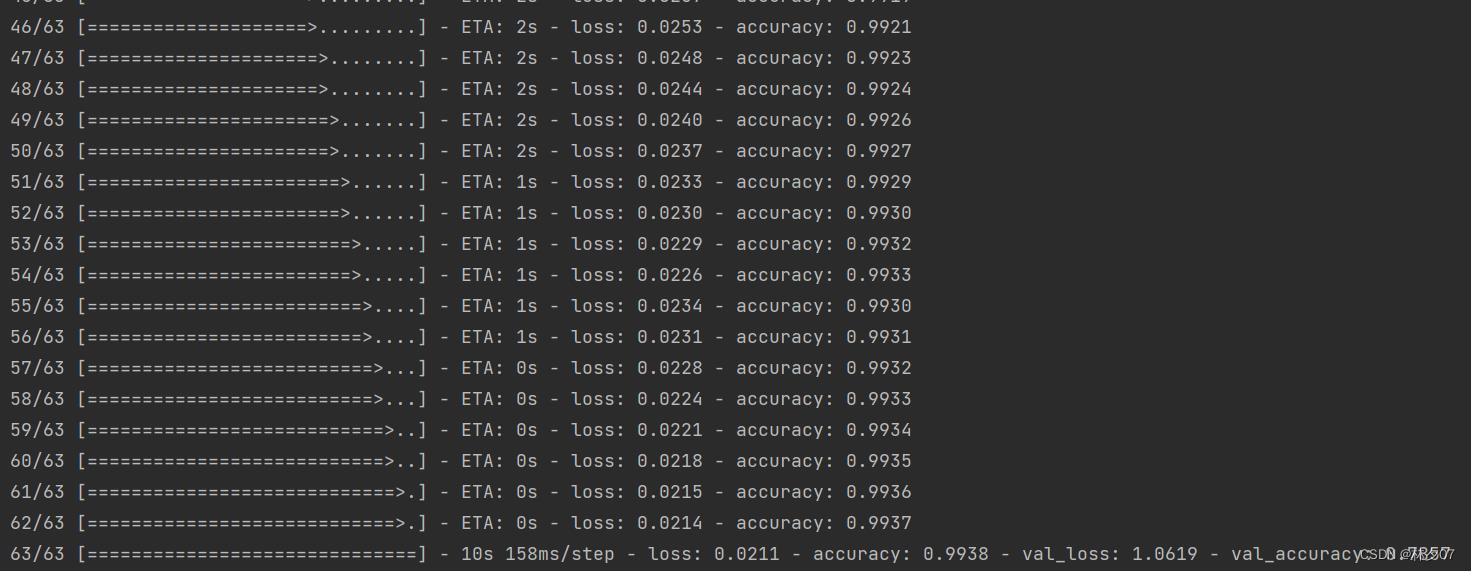
训练模型,进行10轮。
# 设置优化器
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
训练结果:10轮下来测试集的正确率仅有78.57%,可见还有很大的优化空间。
模型评估
对训练完模型的数据制作成曲线表,方便之后对模型的优化,看是过拟合还是欠拟合还是需要扩充数据等等。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
运行结果:

预测
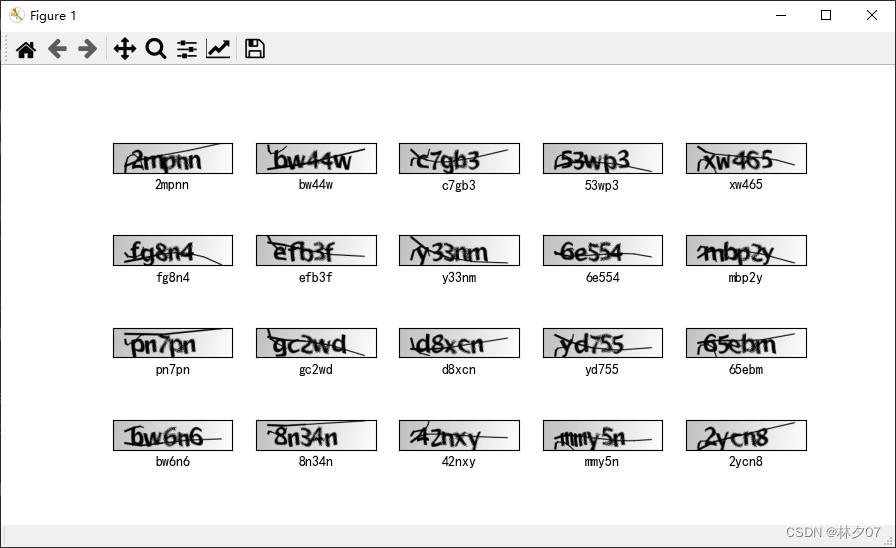
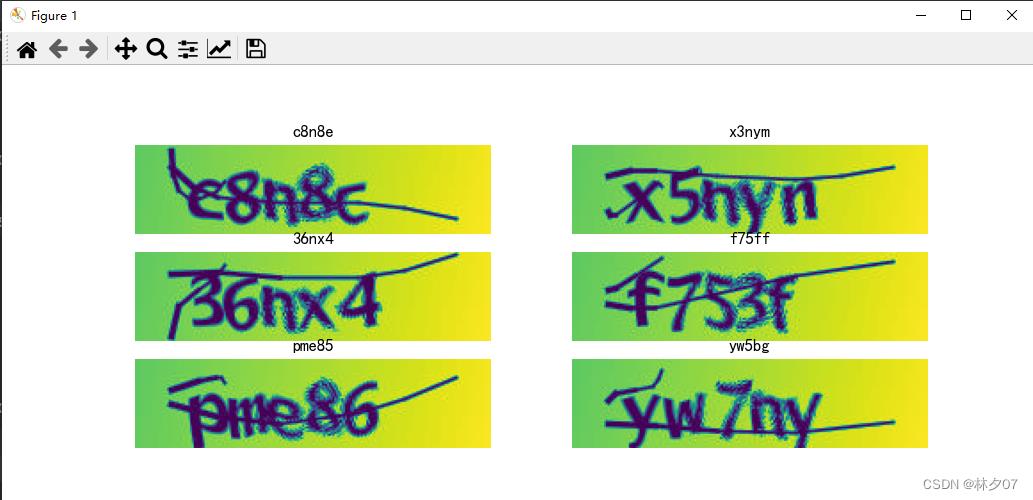
这里我们对训练好的模型进行一个预处效果,下面以6张图片为例,进行测试。
def vec2text(vec):
text = []
for i, c in enumerate(vec):
text.append(char_set[c])
return "".join(text)
plt.figure(figsize=(8, 8))
for images, labels in val_ds.take(1):
for i in range(6):
ax = plt.subplot(5, 2, i + 1)
# 显示图片
image = tf.reshape(images, [16, 50, 200])
plt.imshow(image[i])
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测验证码
predictions = model.predict(img_array)
plt.title(vec2text(np.argmax(predictions, axis=2)[0]))
plt.axis("off")
plt.show()
可以看到错误率还是挺高的,还需进一步改善模型。
以上是关于深度学习基于卷积神经网络的验证码识别的主要内容,如果未能解决你的问题,请参考以下文章
深度学习100例-卷积神经网络(CNN)识别验证码 | 第12天
爱科研 | 基于卷积神经网络的验证码识别 (人工智能项目,十一科研实训)