论文笔记All about Eve: Execute-Verify Replication for Multi-Core Servers
Posted 软件工程小施同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记All about Eve: Execute-Verify Replication for Multi-Core Servers相关的知识,希望对你有一定的参考价值。
本文理解来自论文All about Eve: Execute-Verify Replication for Multi-Core Servers
Eve是为了适应多核服务器而诞生的distributed replication方案。State machine replication旨在实现fault tolerance。
由于让所有的replicas执行一样顺序的请求很困难,Eve采取的措施是消除所有replicas必须执行一样顺序的请求的限制,但这并不是说不对请求的并行执行做准备,否则就会达不到一致性。
Eve采取的措施是将请求划分成一个一个batch,一个batch中的所有请求之间互不影响,这样就可以大胆并行执行一个batch中的所有请求。
传统上,要实现一致性,replicas需要在请求执行顺序上达成一致再去执行,而在Eve上,先并行执行请求,再验证它们是否达到一致性,如果出现divergence(分歧),Eve会进行roll back,然后重新串行执行请求序列。
为了减少divergence的出现,Eve使用了mixer,实际上是它使得组与组之间(还是组内?)的请求在并行执行时不会相互干扰,并且会让修复更有效。
Eve的execute-verify模型可以进行crash tolerant和Byzantine tolerant。
Eve的鲁棒性来自两个方面:首先,Eve的mixer会减少触发潜在concurrency bugs的可能性,因为在mixer的作用下,并行执行的是互不干扰的请求。
►Why not deterministic execution?
多线程一般情况下会出现不确定性,如何实现确定性的多线程(deterministic multithreading)是当前的关键。
其实解决方案不只限于让所有的replicas处理同样序列的输入,其实还有一种思路是:利用请求的语义(semantics)实现replica coordination。例如,对于读类型的请求,SMR系统不必要求replicas用同一种顺序来处理,因为读类型的请求不会修改replicated application的state。所以如果我们能判断出它是读请求,那么就可以放手去并行执行它,但对于一些类型的请求还是要达成一个统一的处理顺序。
让读请求只在首选的法定数目的replicas上执行,而不是在所有的replicas上执行,这是为什么呢?
►Synchronous primary-backup
Primary会接受请求并将请求划分成一个一个batch,如果一个batch B形成了,它就会发送信息 <EXECUTE-BATCH, n, B, ND> 给backup,
- n是这个batch的序号,
- ND是不确定性调用如random() 和 gettimeofday() 为了保证一致性执行的数据。
Backup就会根据这个信息去执行请求,并返回一个token给primary,primary会把它传来的token和自己的进行比较,
- 如果一致,说明没有发生divergence,primary会将这个batch的序号标记为稳定;
- 如果不一致,说明出现了divergence,此时primary就会roll back到上一个稳定的batch序号,并让backup也roll back到上一个稳定的batch序号,即放弃刚刚传来的batch。
►Evaluation
Eve的mixer会对性能有怎样的影响,Eve的吞吐率如何,相比于unreplicated multithreaded execution性能如何,Eve如何处理concurrency bugs?希望通过一个键值存储程序和H2 数据库引擎来告诉我们答案。
Eve现在的prototype存在的limitations有:
(i) not implementing extra protection mode optimization for our asynchronous configurations.
(ii) our current implementation does not handle applications that include objects for which Java’s finalize method modifies state that need to be consistent across replicas.
(iii) our current prototype only supports in-memory application state.
Eve的advantages是:在使用16个线程后,Eve会获得6.5倍于顺序执行的加速。
Eve还有一个limitation:As the workload gets lighter (the execution time per request reduces), the overhead of Eve becomes more pronounced(明显).
Eve为了有一个好的性能,需要一个好的mixer。
但是对Eve来说构造一个能检测所有的conflicts并允许较大量的并行存在的mixer是容易的。
►Failure and recovery
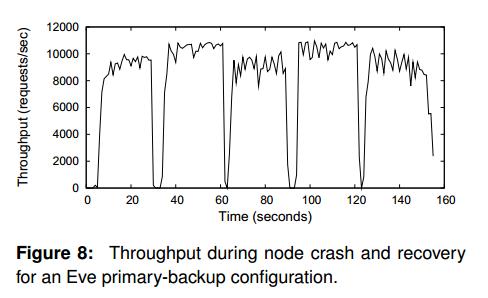
在30s出primary出错,60s时primary恢复,90s时secondary出错,120s时secondary恢复。
可见在出错时,很短的时间内就可以进行补救,Eve的容错能力还是不错的。
那Eve处理concurrency faults的能力如何呢?
如果bug在一个replica中,Eve可以检测到,然后通过roll back和重新顺序执行来修复这个bug;
但如果bug同时出现在两个replicas中,Eve就无法检测出它,所以这应该是Eve的一个limitation。
►Remus
Eve相比于Remus,要少使用两个数量级的网络带宽。
►Latency and batching
Eve在latency和throughput之间有tradeoff。
随着负载的增加,Eve的latency会开始增加,直至达到一个饱和点:每秒1225个请求的吞吐率。
这要少于unreplicated server的每秒1470个请求。
如何达到latency低,但却能有一个高的吞吐率?
Eve使用了一个dynamic batching scheme:batch的大小根据情况来变化,比如当系统开始饱和时,batch的大小会变大,以获得更多的并行性。
————————————————
版权声明:本文为CSDN博主「刘秋杉」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bluecloudmatrix/article/details/39121795
以上是关于论文笔记All about Eve: Execute-Verify Replication for Multi-Core Servers的主要内容,如果未能解决你的问题,请参考以下文章
[2016-06-17]OMG美语笔记-Do you believe that it's all about timing to find a good job?
周三九的论文笔记 -- Attention Is All You Need
《RAFT:Recurrent All-Pairs Field Transforms for Optical Flow》论文笔记