数仓4.0笔记——数仓环境搭建—— DataGrip准备和数据准备
Posted 丝丝呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数仓4.0笔记——数仓环境搭建—— DataGrip准备和数据准备相关的知识,希望对你有一定的参考价值。
1 DataGrip准备
1.1 启动HiveServer2
[zhang@hadoop102 hive]$ hiveserver2
1.2 配置DataGrip连接
启动DataGrip,创建连接

配置连接属性
所有属性配置,和Hive的beeline客户端配置一致即可。初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。

测试时,根据提示下载驱动。

测试使用
创建数据库gmall,并观察是否创建成功。

注意当前使用的数据库是谁,默认default

修改连接,指明连接数据库,这样以后打开默认数据库就是gmall
在文件中查看

重命名操作

2 数据准备
回顾:数据仓库的数据来源
(1)用户行为日志:采集通道,Flume+Kafak+Flume
(2)业务数据:采集通道,sqoop
一般企业在搭建数仓时,业务系统中会存在一定的历史数据,此处为模拟真实场景,需准备若干历史数据。假定数仓上线的日期为2020-06-14,具体说明如下。
2.1 用户行为日志
用户行为日志,一般是没有历史数据的,故日志只需要准备2020-06-14一天的数据。具体操作如下:
1)启动日志采集通道,包括Flume、Kafak等
2)修改两个日志服务器(hadoop102、hadoop103)中的/opt/module/applog/application.yml配置文件,将mock.date参数改为2020-06-14。
3)执行日志生成脚本lg.sh。
4)观察HDFS是否出现相应文件。
启动日志采集通道:
[zhang@hadoop102 hadoop]$ zk.sh start
[zhang@hadoop102 hadoop]$ kf.sh start
[zhang@hadoop102 hadoop]$ f1.sh start
[zhang@hadoop102 hadoop]$ f2.sh start
(前一个老师配置了集群脚本,老师应该是忘了,所以只需要cluster.sh start,即可)

[zhang@hadoop102 hadoop]$ cd /opt/module/applog/
[zhang@hadoop102 applog]$ ll

[zhang@hadoop102 applog]$ vim application.yml
对hadoop103做同样的修改

先进去web端,把之前的origin_data文件删除
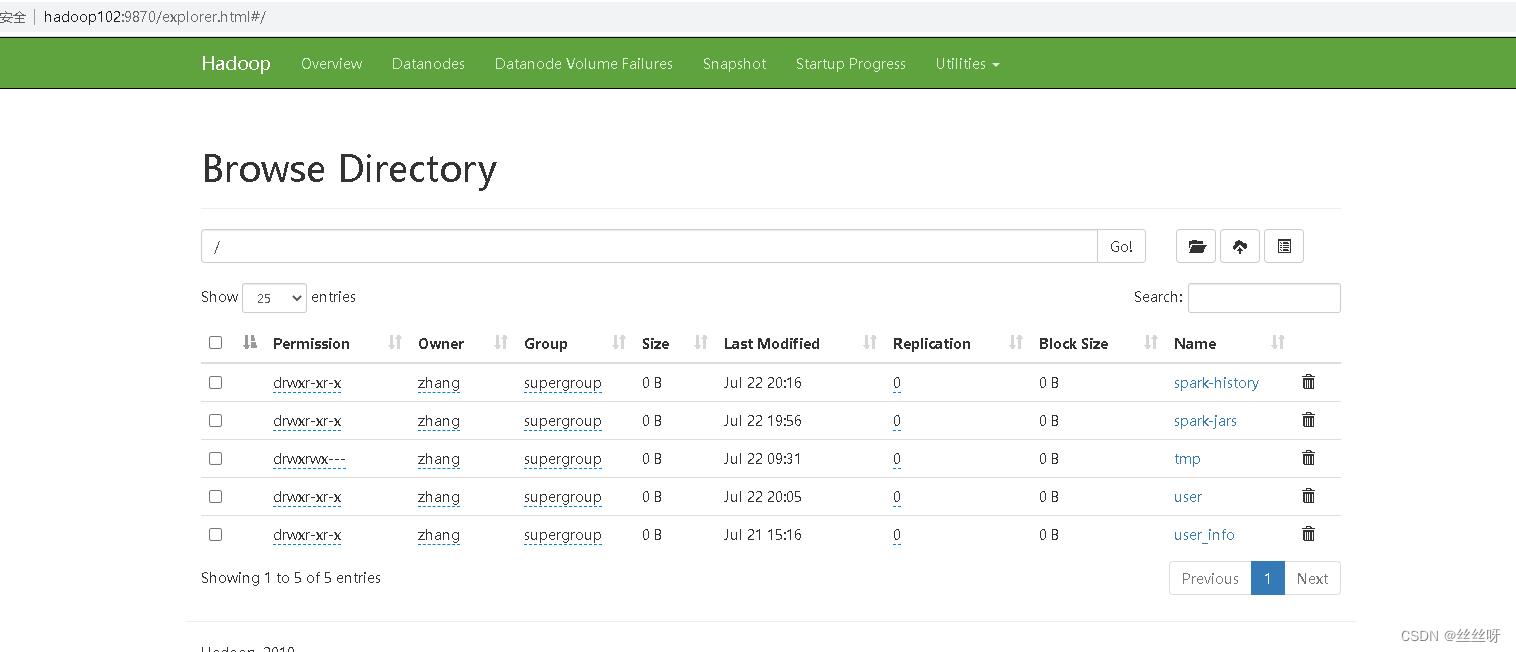
[zhang@hadoop102 applog]$ lg.sh


证明用户行为日志数据已经准备好了。
2.2 业务数据
业务数据一般存在历史数据,此处需准备2020-06-10至2020-06-14的数据。具体操作如下。
1)修改hadoop102节点上的/opt/module/db_log/application.properties文件,将mock.date、mock.clear,mock.clear.user三个参数调整为如图所示的值。
[zhang@hadoop102 applog]$ cd /opt/module/db_log/
[zhang@hadoop102 db_log]$ ll

[zhang@hadoop102 db_log]$ vim application.properties

[zhang@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar

再打开配置文件,修改6月11号
[zhang@hadoop102 db_log]$ vim application.properties

写入11号的文件 [zhang@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar

修改6月12日
修改6月13日

 修改6月14日
修改6月14日


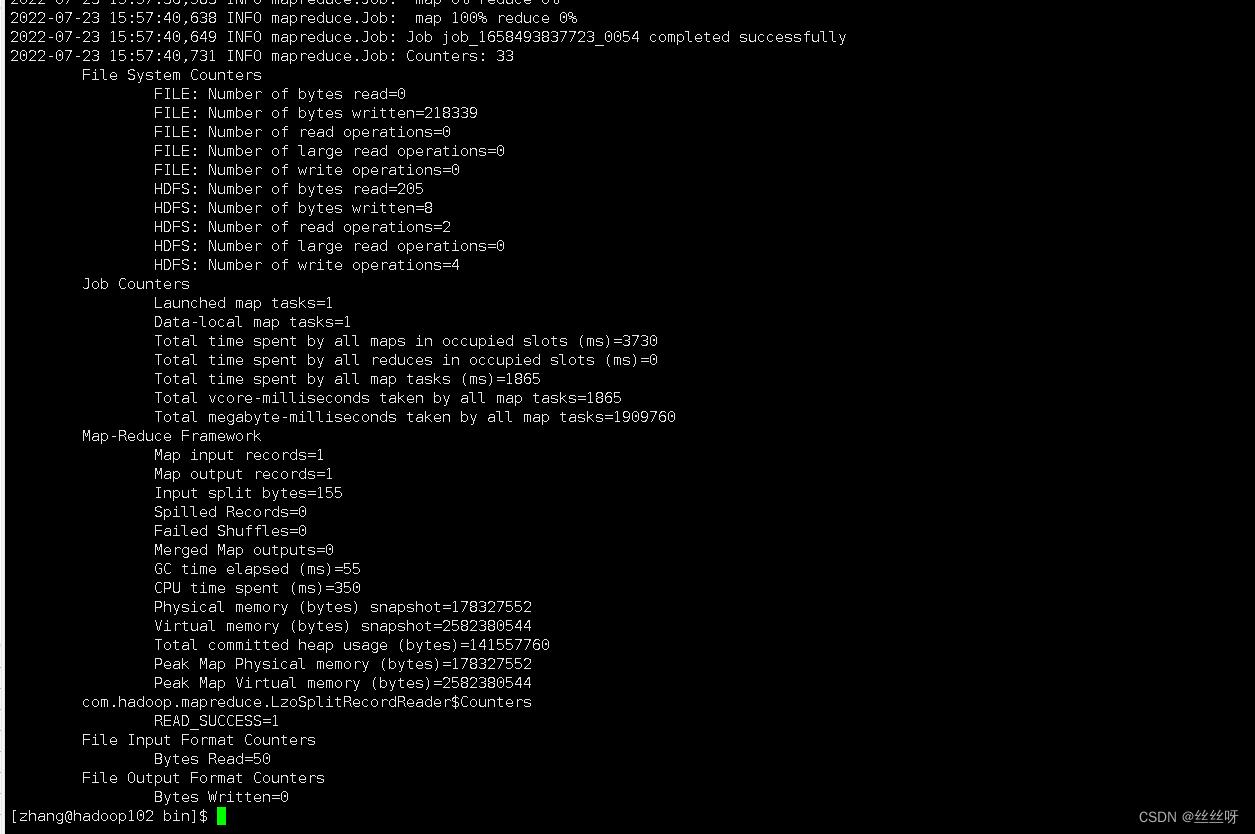
[zhang@hadoop102 ~]$ cd bin/

[zhang@hadoop102 bin]$ ./mysql_to_hdfs_init.sh all 2020-06-14
以上是关于数仓4.0笔记——数仓环境搭建—— DataGrip准备和数据准备的主要内容,如果未能解决你的问题,请参考以下文章