来自数砖大佬的 130页 PPT 深入介绍 Apache Spark 3.2 & 3.3 新功能
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了来自数砖大佬的 130页 PPT 深入介绍 Apache Spark 3.2 & 3.3 新功能相关的知识,希望对你有一定的参考价值。
本文 PPT 材料来自 DATA + AI SUMMIT 2022 6月29日标题为《Data Deep Dive into the New Features of Apache Spark 3.2 and 3.3》分享的全文 PPT,大约130页,分享者来自数砖的 Daniel Tenedorio、范文臣以及李潇等大佬。关于本文对应的视频将在后期上传,敬请关注过往记忆大数据微信公众号。
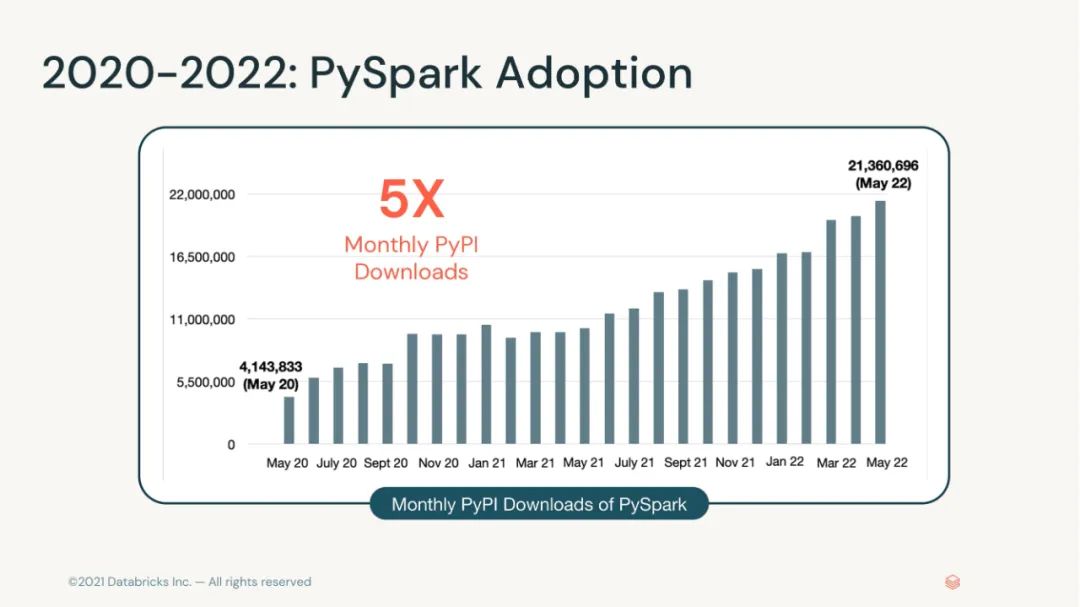
Apache Spark 已经成为在单节点或集群上执行数据工程、数据科学和机器学习的最广泛使用的计算引擎。Spark 的月 maven下载数量迅速增长到2000万次。本 PPT 将讨论 Spark 3.2 和 3.3 中的高级特性和改进。并深入介绍以下功能:
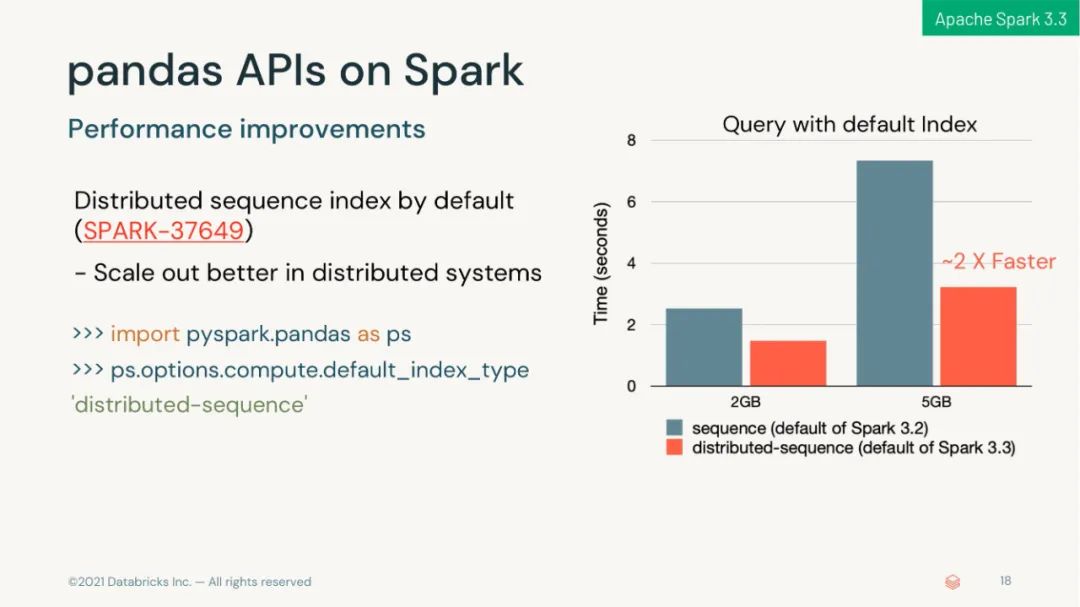
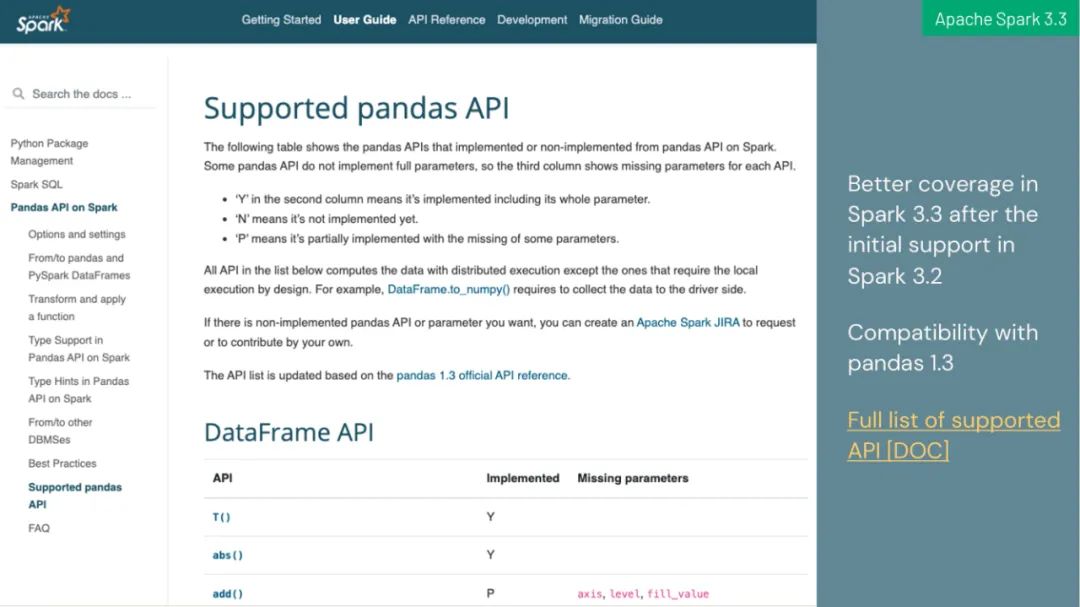
在 Apache Spark 上引入 pandas API 以统一不同数据规模的 API;
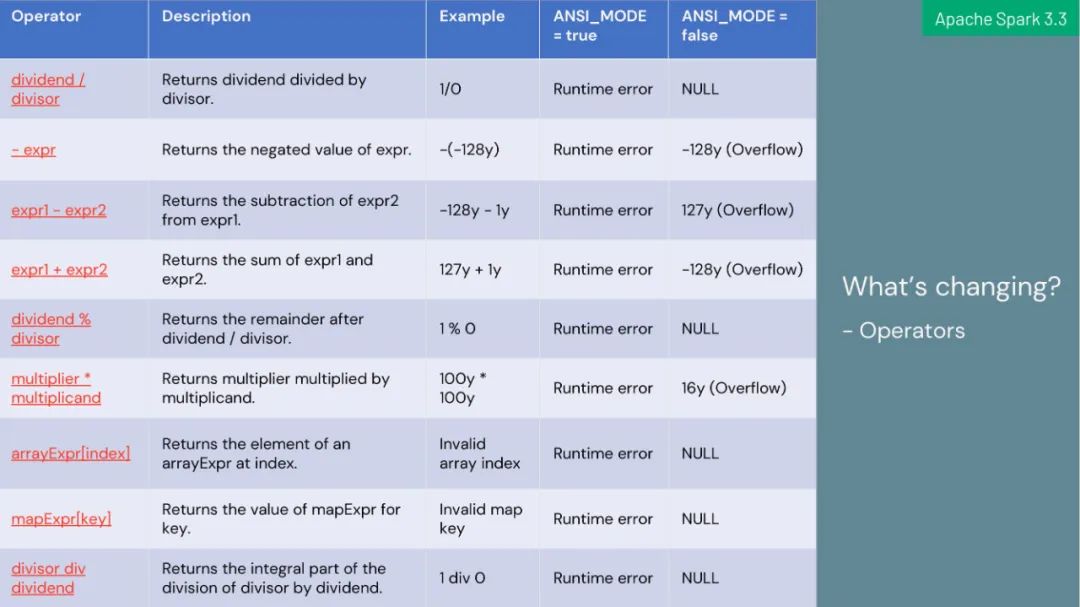
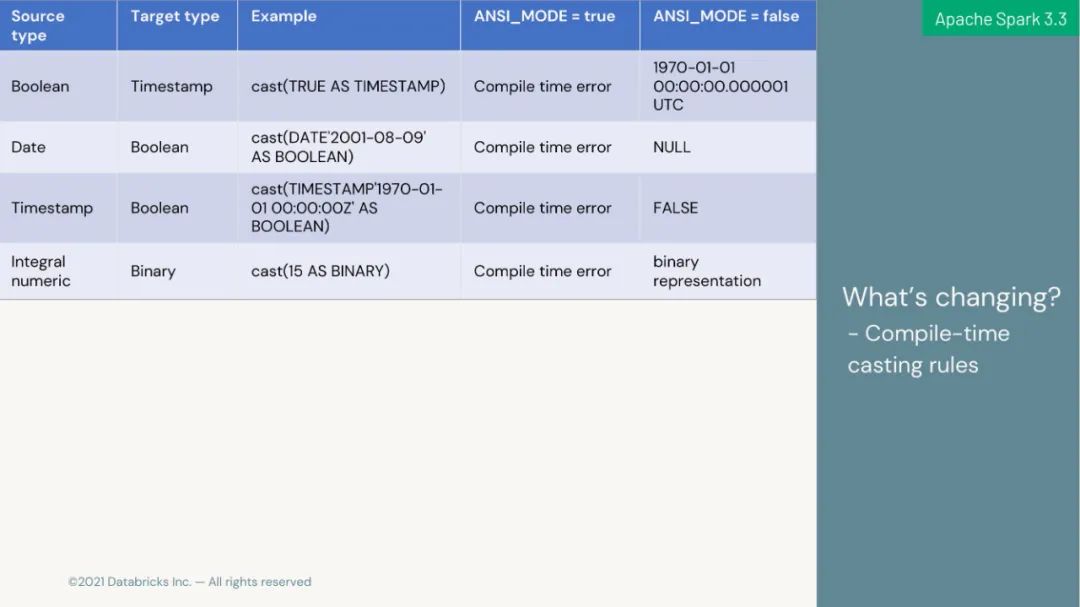
完成 ANSI SQL 兼容模式,简化 SQL 工作负载的迁移;
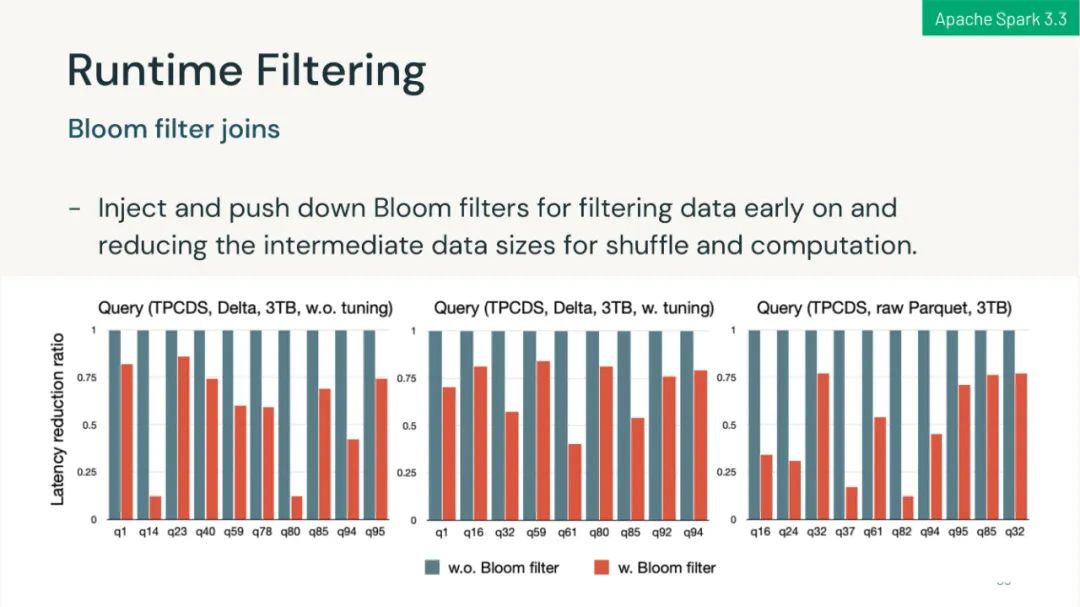
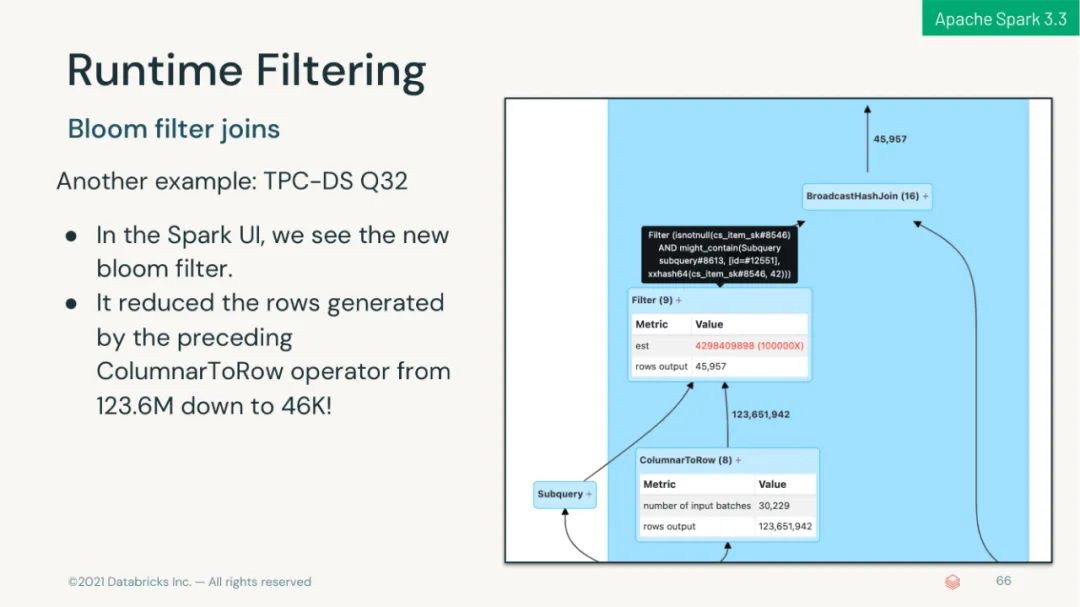
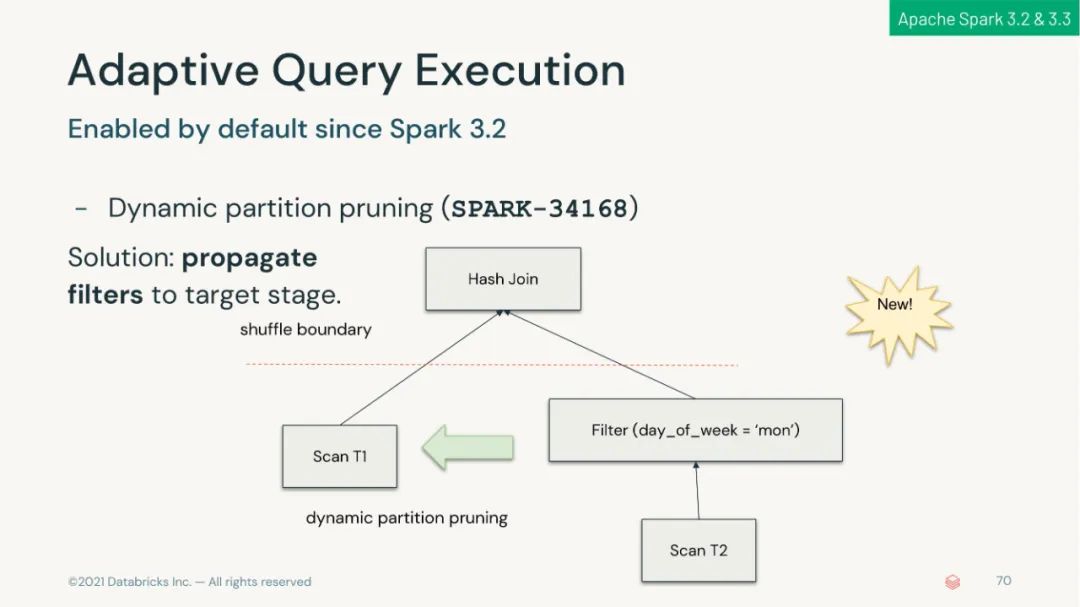
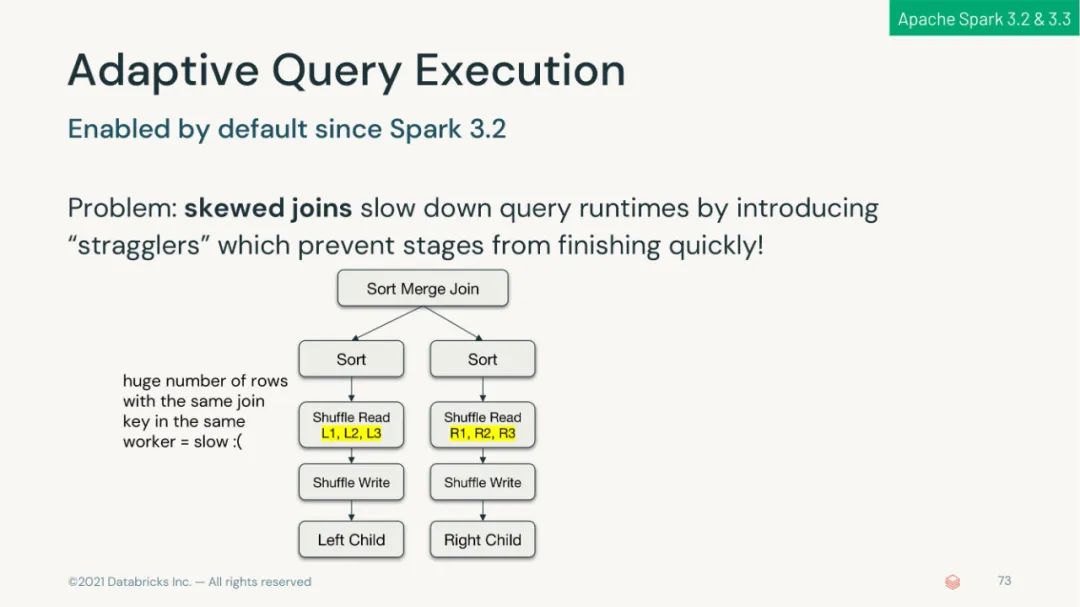
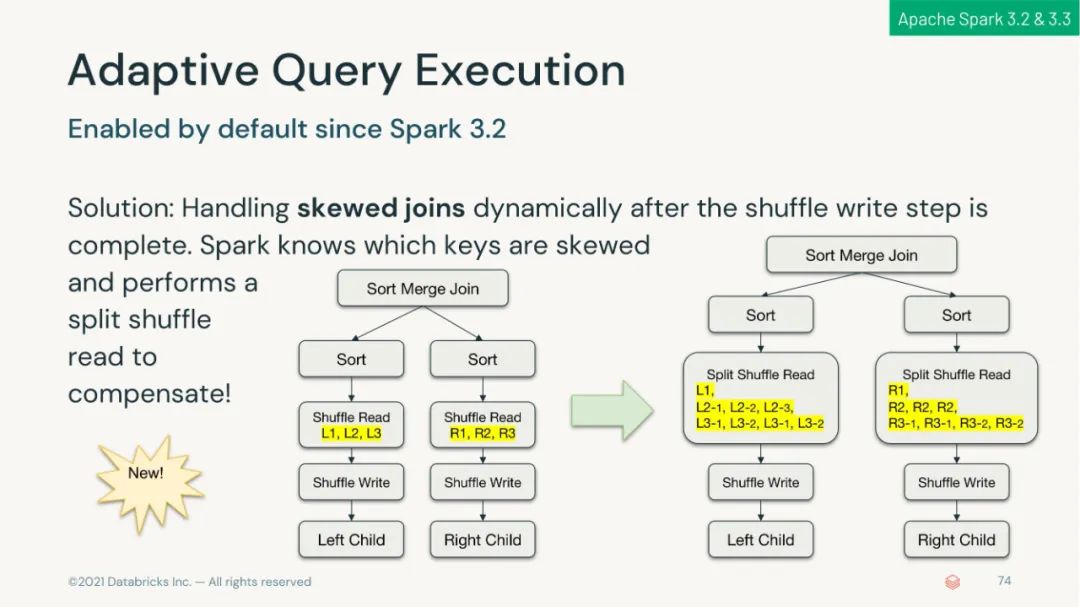
可以在生产环境下使用自适应查询执行以在运行时加速 Spark SQL;
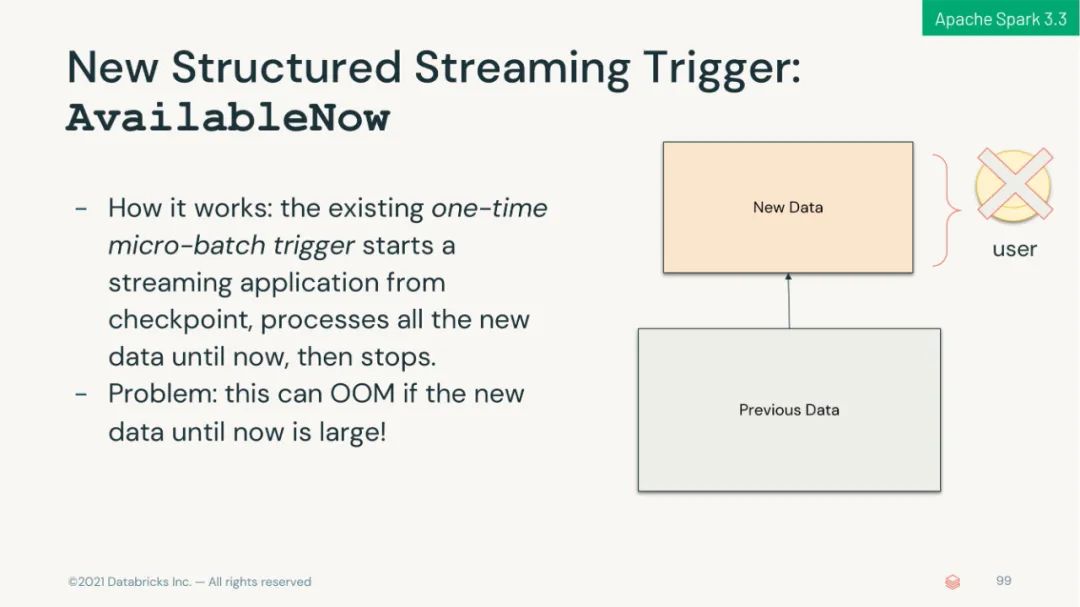
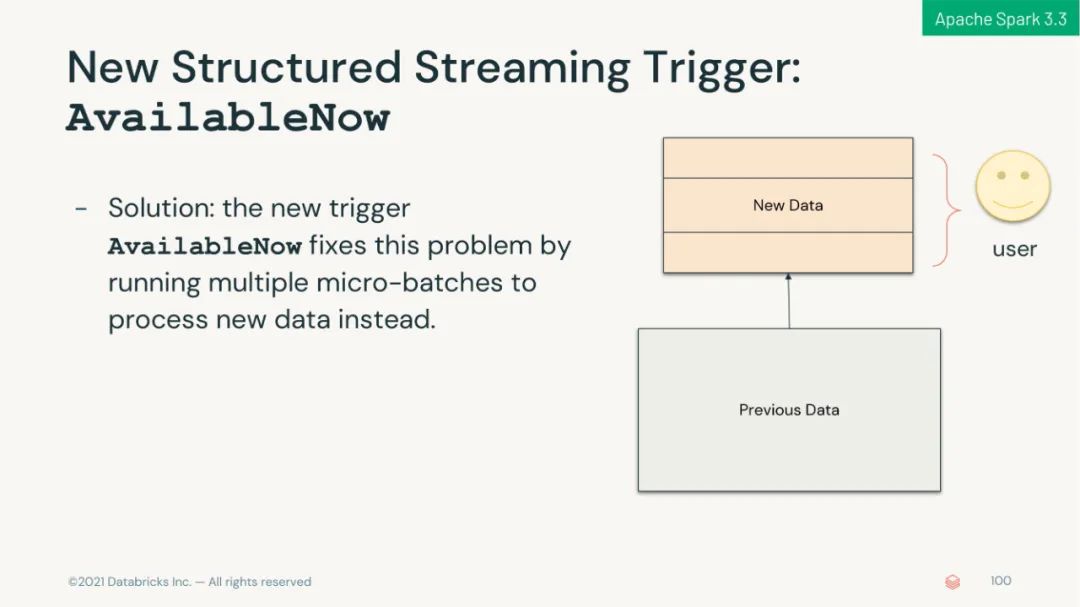
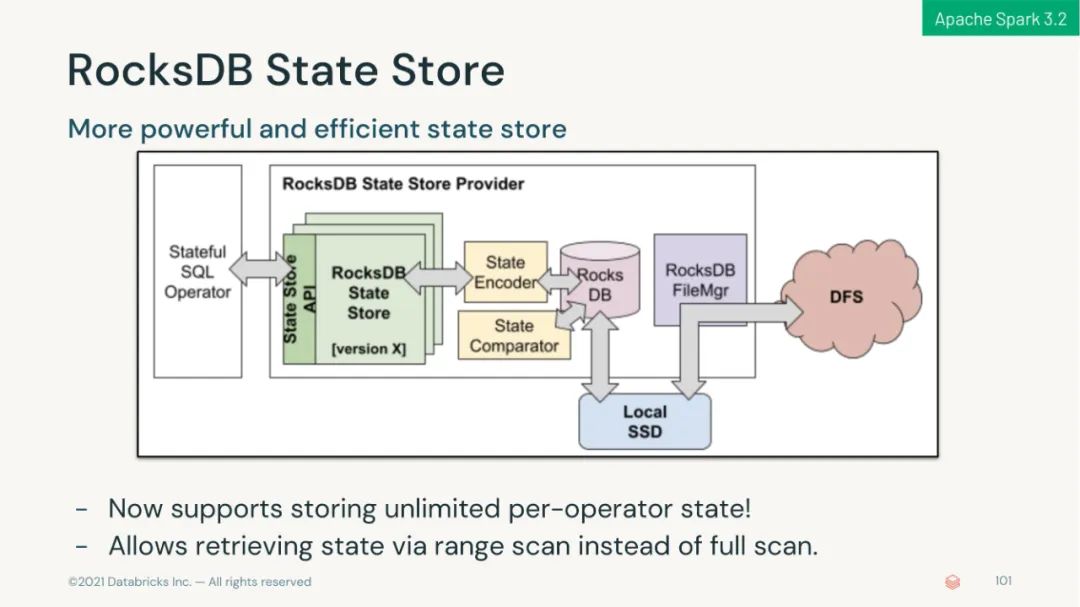
引入 RocksDB 状态存储,使状态处理更具可扩展性。
关于本文的 PPT 材料请添加 fangzhen0219 微信获取。





































































































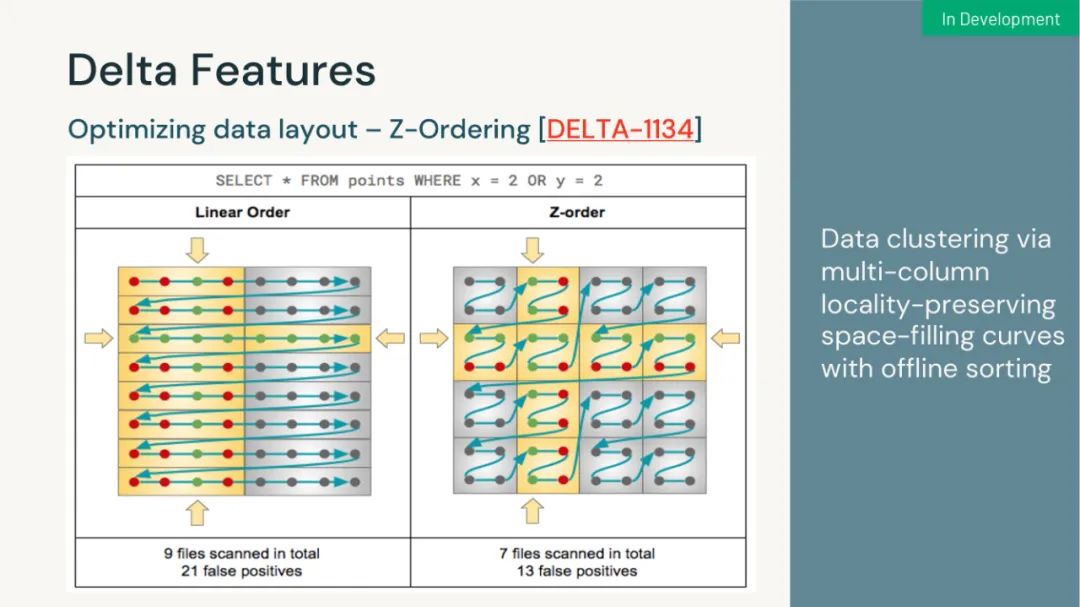

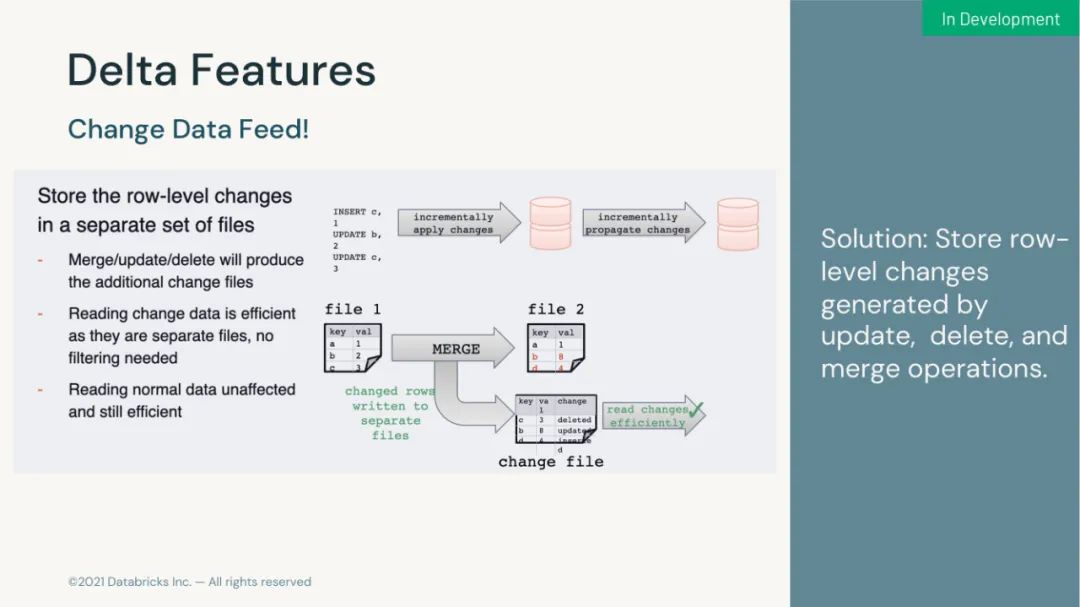
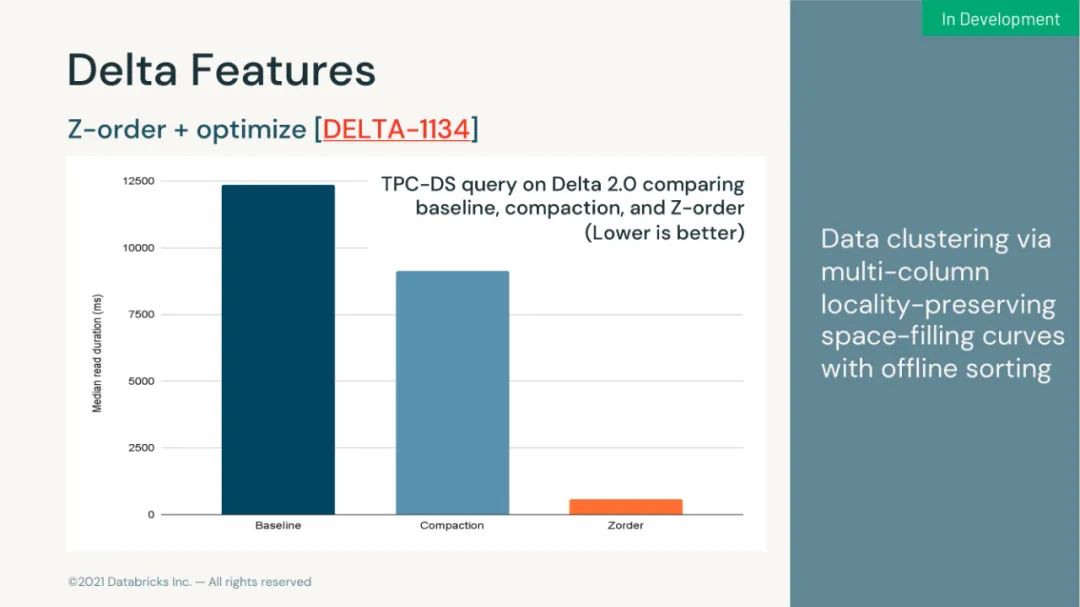


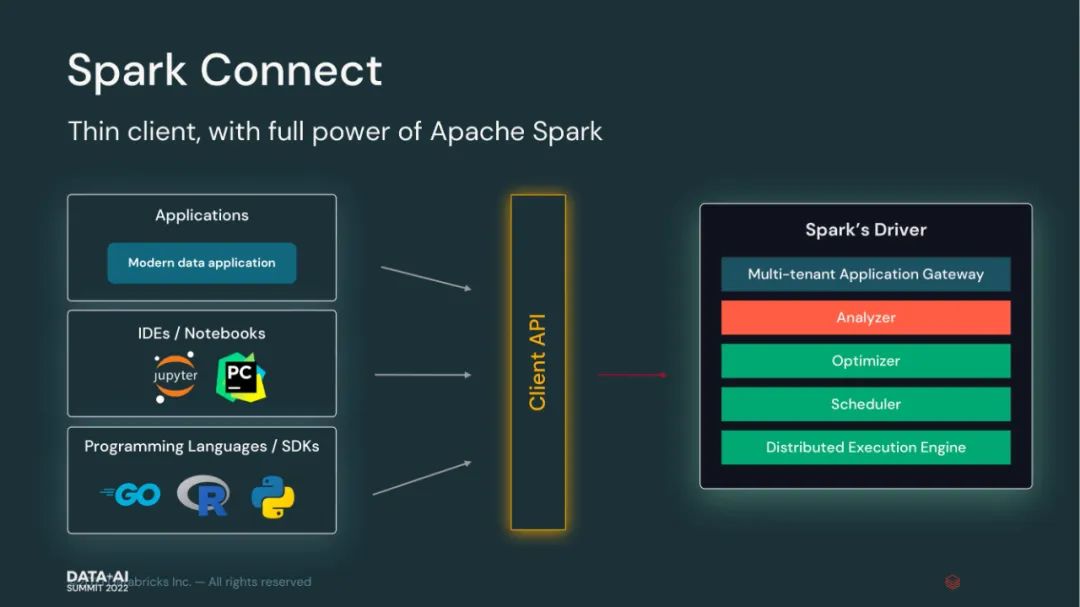



以上是关于来自数砖大佬的 130页 PPT 深入介绍 Apache Spark 3.2 & 3.3 新功能的主要内容,如果未能解决你的问题,请参考以下文章
NLPCC2020-微软自然语言处理机器推理,124页ppt
阿里P7大牛,深入剖析JVM底层设计原理+高级特性pdf,附46页ppt