DRL前沿之:End to End Learning for Self-Driving Cars
Posted songrotek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DRL前沿之:End to End Learning for Self-Driving Cars相关的知识,希望对你有一定的参考价值。
前言
如果大家关注上个月Nvidia GTC,那么大家应该会注意到Nvidia 老大黄仁勋介绍了他们自家的无人驾驶汽车,这个汽车的无人驾驶技术和以往的方法不一样,完全采用神经网络。这个系统取名为DAVE。
NVIDIA GTC Self-Driving Car
上面的视频需翻墙观看。
很庆幸的是,就在上周,Nvidia发表了他们的文章来介绍这个工作:
http://arxiv.org/abs/1604.07316
虽然这个工作暂时和Reinforcement Learning没有关系,但是相信他们会加上增强学习是这个无人车具备自主学习提升的能力。
Abstract
这个工作的思路可以说超级的简单,就是使用人类的驾驶数据来训练一个端到端的卷积神经网络CNN。输入是车载摄像头,输出直接是汽车的控制数据。想来这个事情在以前恐怕是难以想象的,要知道当前最先进的自动驾驶系统依然是采用标志识别,道路识别,行人车辆识别,路径规划。。。各种步骤来实现的。而现在这些通通不用,就给汽车一个图像,让汽车根据图像做判断。想想这是一个非常神奇的事情,虽然根据CNN的能力我们可以理解这是可以做到的。
那么这件事大概当前也就Nvidia可以做,因为他们有最先进的硬件Nvidia DevBox,Nvidia DRIVE PX。
那么通过训练,他们在一定程度上取得了成功。结果很重要。训练出来之后,这意味着在未来,随着性能的提升,训练的进一步强化,以及使用增强学习,未来的无人车将具备完全自己思考的能力。
DAVE-2 系统结构
这个系统叫做DAVE-2,DAVE其实是(DARPA Autonomous Vehicle的缩写,无人车比赛最早就是DARPA搞出来的)。整个硬件系统如下:
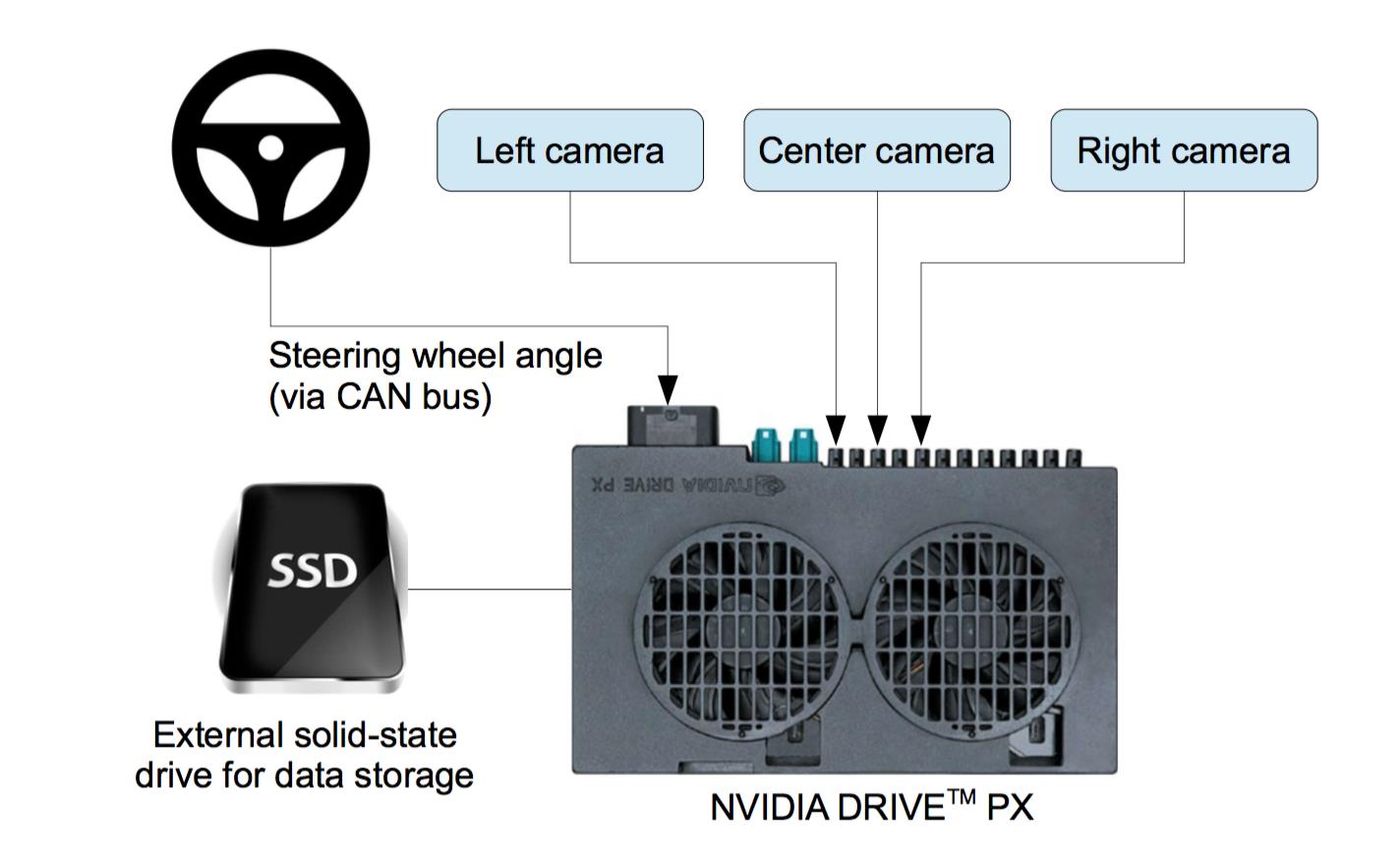
用三个摄像头,通过NVIDIA DRIVE PX做输入输出。
软件系统如下:

那么这里有个trick,就是我们人类只输入的是正确的样本,那么怎么让计算机面对错误的环境来做调整呢?很简单的trick,在车上面再安装两个摄像头,不过这两个摄像头的位置不在正中间,那么这两个摄像头看到的样本就是错误的。其他的偏移中间及旋转则可以根据3d变化来模拟出来。那么对应的偏移及旋转的控制量也可以计算出来。这样就有了一一对应的样本了。
那么这里我们也应该看到,输出是很简单的,就是汽车驾驶的轮子的角度。并没有速度控制。这一定程度上大大简化了训练的要求。
而对于训练,那就是简单的CNN-regression训练。
训练好之后,要forward就使用中间的摄像头
训练数据
72小时的人类数据。由于上面的多个摄像头的数据,及科研进行3d变换得到的模拟数据,总的样本将极其之大。
关于具体的网络结构还有训练细节大家还是看原文比较好。基本上没有大的trick。
小结
这个工作idea其实很简单,关键是实现,完全是一个非常复杂的系统工程,需要一个大的团队配合才能搞出来,和AlphaGo类似。这才是真正的智能车啊。明年将举行的Roborace想必将极大推进这方面的进展。
以上是关于DRL前沿之:End to End Learning for Self-Driving Cars的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读|图神经网络+Actor-Critic求解静态JSP(End-to-End DRL)《基于深度强化学习的调度规则学习》(附带源码)
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control