操作系统CPU调度策略---07
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统CPU调度策略---07相关的知识,希望对你有一定的参考价值。
操作系统CPU调度策略---07
多进程图像与CPU调度
当进程1执行陷入阻塞时,需要进行进程调度,此时有进程2和进程3都处于就绪态,问: 应该选择哪个进程进行切换?
进程2刚read完,进入就绪状态,而进程3是因为时间片到期,而进入就绪态的
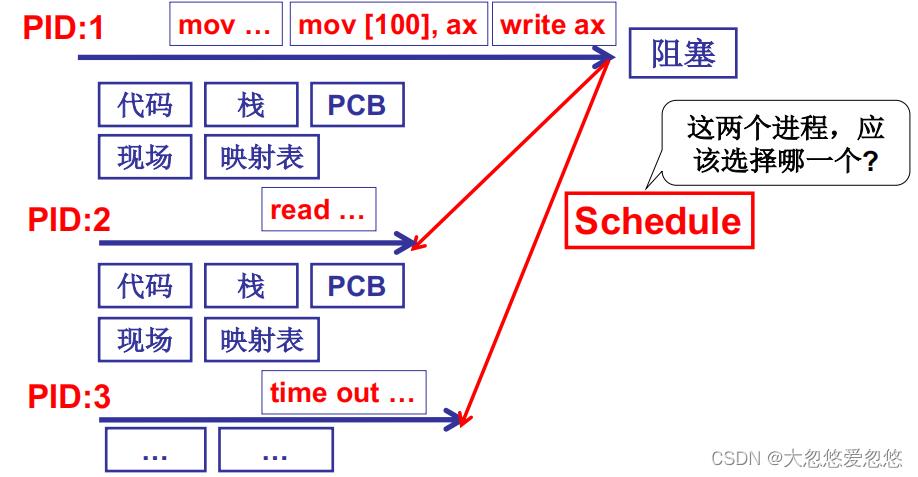
CPU调度(进程调度)的直观想法

面对诸多场景,如何设计调度算法?

如何做到合理? 需要折中,需要综合…
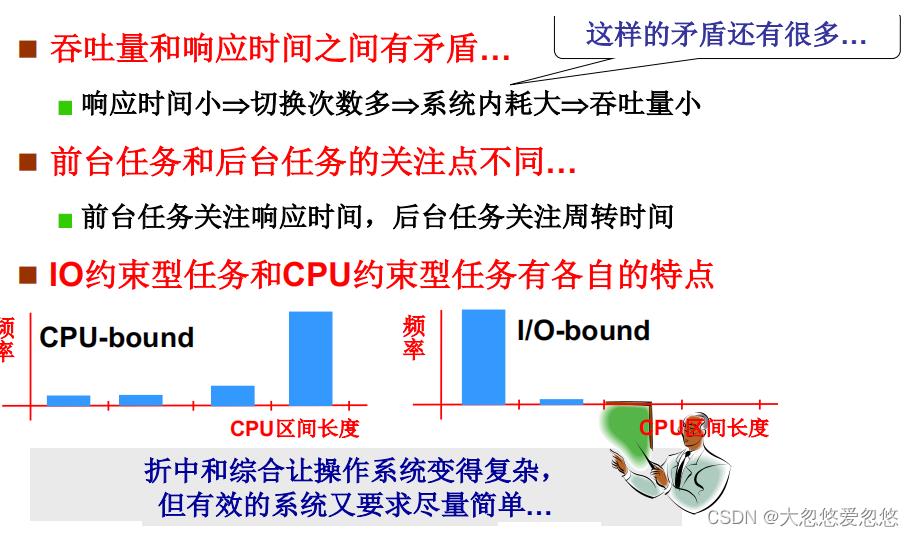
- 先具体来说明一下响应时间和吞吐量之间的矛盾关系
例如: 我们打开一个word文档,往文档里面输入文字,那么我们每输入一个文字,就需要进行一次磁盘IO,那么就必然要进入内核态,陷入阻塞,从而引起线程切换。
因此,如果想让用户使用word时,有很好的体验,就必须让响应时间减少,即切换频率要增加,最好是IO处理完毕后,线程进入就绪态后,刚好切换到该线程执行。
但是,切换频率增加,必然会导致系统内耗增大,毕竟无论是TSS切换,还是内核栈切换,都需要消耗一定的时间,如果切换的非常频繁,用在切换上面的时间就会变多,但是这些时间又没有花在程序运行上,因此被称为系统内耗时间。
系统内耗增大后,系统整体的吞吐量就会减少,即无法在一定时间内,完成更多有效的工作。
- 前后台任务异同
前台任务关注响应时间,例如: word文档,我们输入一个字后,必须要尽快的在文档上显示出这个字来,因此,这就需要响应时间要快,即前台任务切换要快。
后台任务关注周转时间,例如: 编译器在进行编译时,编译的过程需要大量的CPU计算,而不需要IO读取和写入,因此,最好是减少切换次数,这样编译器所在进程就可以一直拥有CPU资源,从而加快编译速度。
- IO约束型任务和CPU约束型任务
对于IO约束型任务而言,例如: word这类前台程序,他们在运行过程中需要大量输入和输出,即运行过程中的大部分时间都花在了IO上面,因此得名IO约束型任务。IO约束型任务通常是前台任务,因为前台任务需要和用户进行交互,而交互过程主要靠的就是IO输入和输出。
对于CPU约束型任务而言,例如: gcc编译器,他们在编译程序的过程中,大部分时间都是利用CPU进行各种计算,而很少会去进行IO操作。CPU约束型任务通常对应后台任务,因为后台任务通常大部分时间都是只使用CPU,而不会使用IO操作。
大家思考: 如果同时存在IO约束型的任务和CPU约束型的任务,我们应该让那个任务先执行,从而才能获得系统的最高效率呢?
- 应该让IO约束型任务先执行,因为IO约束型任务通常执行一小段时间,就会因为IO阻塞,而被迫让出CPU使用权,此时会进行线程切换,切换到CPU约束型任务继续执行,等到CPU约束型任务时间片到期后,又会再次切换会IO约束型任务继续执行。
- 这样可以实现IO约束型和CPU约束型任务,二者并行的局面
各种CPU调度算法
折中和综合让操作系统变得复杂, 但有效的系统又要求尽量简单…
因此,对于CPU调度算法而言,一定要尽可能的简单,执行尽可能的快,但是又尽可能的折中和综合,看似矛盾,实则的确矛盾,但是能不能做到呢?
First Come, First Served (FCFS)
最简单的策略就是先进先出,但是这种策略显然不适合当前场景。
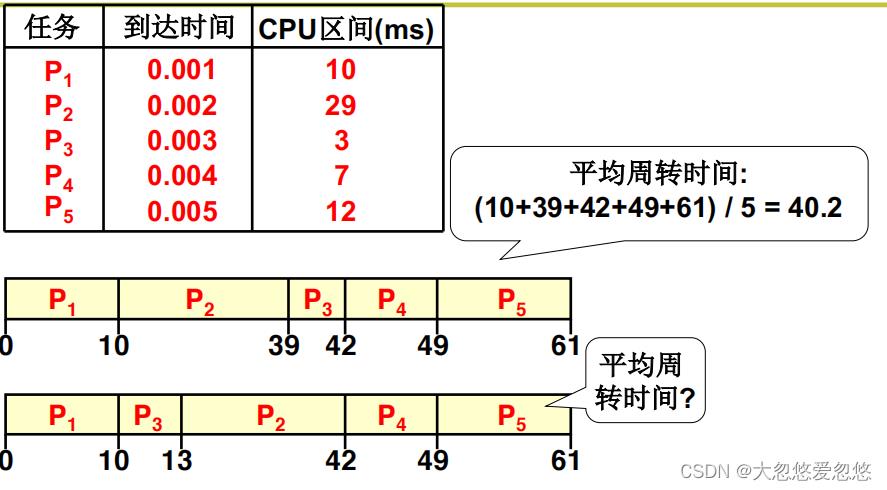
我们可以计算一下CPU的平均周转时间,即将每个任务从第一个任务开始执行计算时间,然后到当前任务执行结束为止,相减,即可得到当前任务的周转时间。
将每个任务的周转时间相加/任务数=平均周转时间
通过证明可以发现,将小任务提前执行,可以减少系统整体的平均周转时间
如何缩短周转时间? SJF: 短作业优先
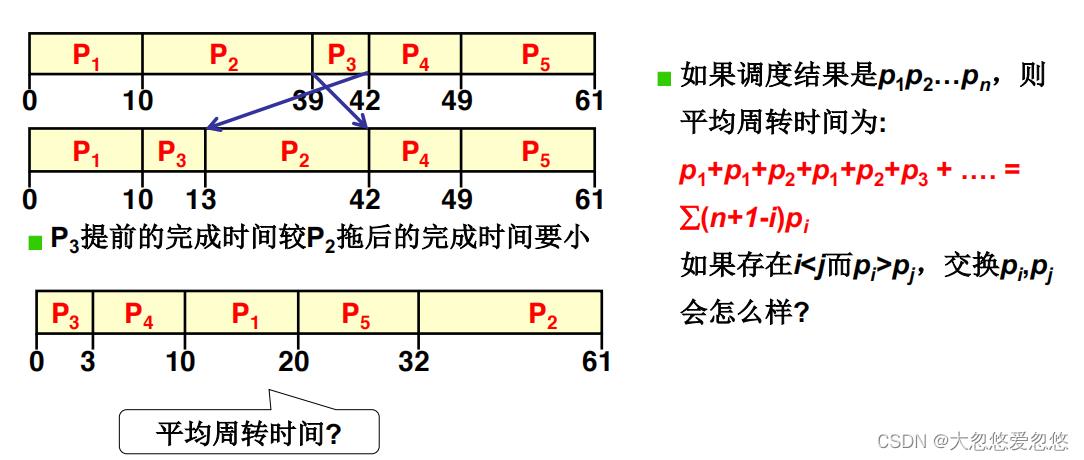
如何证明将短作业优先执行可以减少系统整体周转时间呢?
下面给出证明:
- 任务p1的周转时间=p1
- 任务p2的周转时间=p1+p2
- 任务p3的周转时间=p1+p2+p3
- …
- 任务pn的周转时间=p1+p2+p3+…+pn
- 因此系统平均周转时间为=( p1+(p1+p2)+(p1+p2+p3)+…+(p1+p2+p3…+pn) ) /n=( np1+(n-1)p2+(n-2)p3+…pn ) /n
因此可以看出,当越是排在前面的任务耗时越短,那么系统的平均周转时间才会越小
响应时间该怎么办?
响应时间取决于切换速度,并且为了区分前后台任务的优先级,不同的任务,需要切换的时间应该不一样
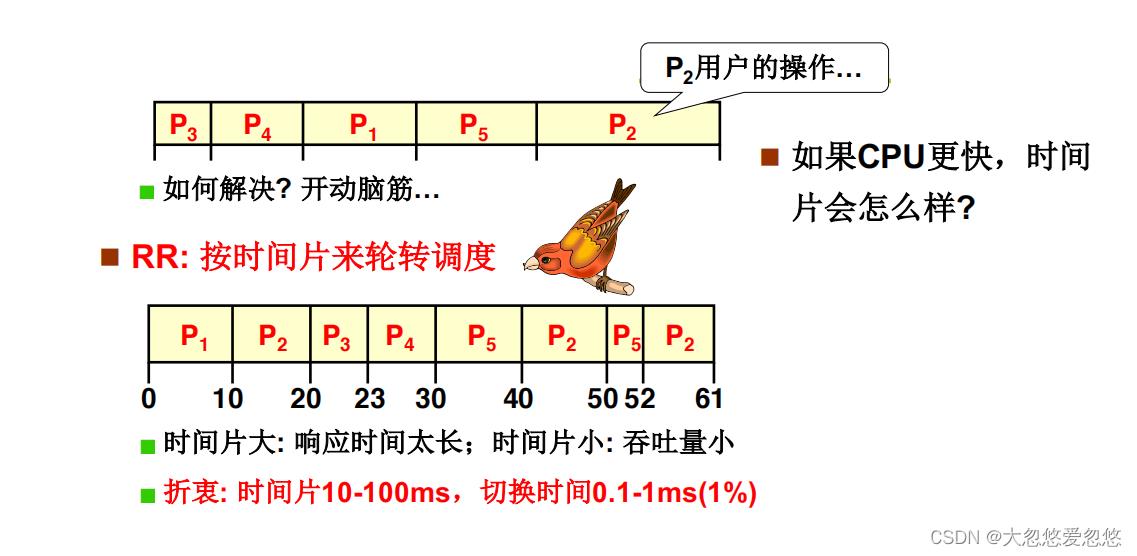
响应时间和周转时间同时存在,怎么办?

- 前台任务看重响应时间,因此将所有前台任务放入前台任务队列,并且该队列采用的调度算法以时间片调度为主
- 后台任务看重周转时间,因此将所有后台任务放入后台任务队列,并且该队列采用的调度算法以短作业优先为主
- 然后,前台任务队列的执行优先级要高于后台任务队列
如果一直有前台任务…
上面给出的场景,可能会导致后台任务队列中某个进程饥饿,长期捞不到CPU资源。

为了解决后台进程饥饿的问题,采用了后台任务优先级动态升高的策略,但是一旦某个后台任务捞到了CPU资源,但是该后台任务会持续执行,那么此时前台任务就会迟迟得不到响应。
因此前后台任务都应该采用时间片机制,并且后台任务还需要体现出短作业优先的策略。
该怎么设计,才能保证前台任务响应快,后台任务短作业优先,周转快呢?
还有很多问题…
- 我们怎么知道哪些是前台任务,哪些是后台任务,fork时告诉我们吗?
设计的调度算法要具备学习能力
- gcc就一点不需要交互吗? Ctrl+C按键怎么工作? word就不会执行一段批处理吗? Ctrl+F按键?
- SJF中的短作业优先如何体现? 如何判断作业的 长度? 这是未来的信息…
一个实际的schedule函数
Linux 0.11的调度函数schedule()
kernel/sched.c schedule() 的目的是找到下一个任务 next,切换到下一个任务,完整源码如下:
/*
* 'schedule()' is the scheduler function. This is GOOD CODE! There
* probably won't be any reason to change this, as it should work well
* in all circumstances (ie gives IO-bound processes good response etc).
* The one thing you might take a look at is the signal-handler code here.
*
* NOTE!! Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
/*
* 'schedule()'是调度函数。这是个很好的代码!没有任何理由对它进行修改,因为它可以在所有的
* 环境下工作(比如能够对IO-边界处理很好的响应等)。只有一件事值得留意,那就是这里的信号
* 处理代码。
* 注意!!任务0 是个闲置('idle')任务,只有当没有其它任务可以运行时才调用它。它不能被杀
* 死,也不能睡眠。任务0 中的状态信息'state'是从来不用的。
*/
void schedule(void)
int i,next,c;
struct task_struct ** p; // 任务结构指针的指针。
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
if ((*p)->alarm && (*p)->alarm < jiffies)
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
/* this is the scheduler proper: */
while (1)
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i)
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
switch_to(next);
schedule() 函数中,第一个for循环处理了很多信号的响应,我们暂时不管,先看最核心的代码,即第二个while循环。
void schedule (void)
int i, next, c;
struct task_struct **p; // 任务结构指针的指针。
……
while (1)
c = -1;
next = 0;
i = NR_TASKS;//从后往前遍历
p = &task[NR_TASKS];//将p设为task数组的最后一个地址
// 这段代码也是从任务数组的最后一个任务开始循环处理,比较每个就绪
// 状态任务的counter(任务运行时间的递减滴答计数)值,哪一个值大,运行时间还不长,next 就
// 指向哪个的任务号。
while (--i)
if (!*--p)
continue;
//Linux 0.11中,TASK_RUNNING是就绪态,counter是时间片
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
//判断是就绪态,并且 counter>-1,就给c和next赋值,遍历找到最大的counter
c = (*p)->counter, next = i;
// 如果比较得出有counter 值大于0 的结果,则退出while(1)的循环,执行任务切换。
// counter 最大的任务,优先级最高
if (c)
break;
// 否则c=0,说明就绪态的时间片都用完了,根据每个任务的优先权值,更新每一个任务的counter 值。
// counter 值的计算方式为counter = counter /2 + priority
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
//执行过的任务 比初始任务 优先级高
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
switch_to (next); // 切换到任务号为next 的任务,并运行。
- 从任务数组的最后一个任务开始循环处理,跳过非就绪的任务,并在就绪任务中选择counter 值最大的任务,即剩余时间片最多的任务,若有 counter 值不为0的结果或系统没有一个可运行任务(此时next为0)存在,则选择next对应进程进行切换。
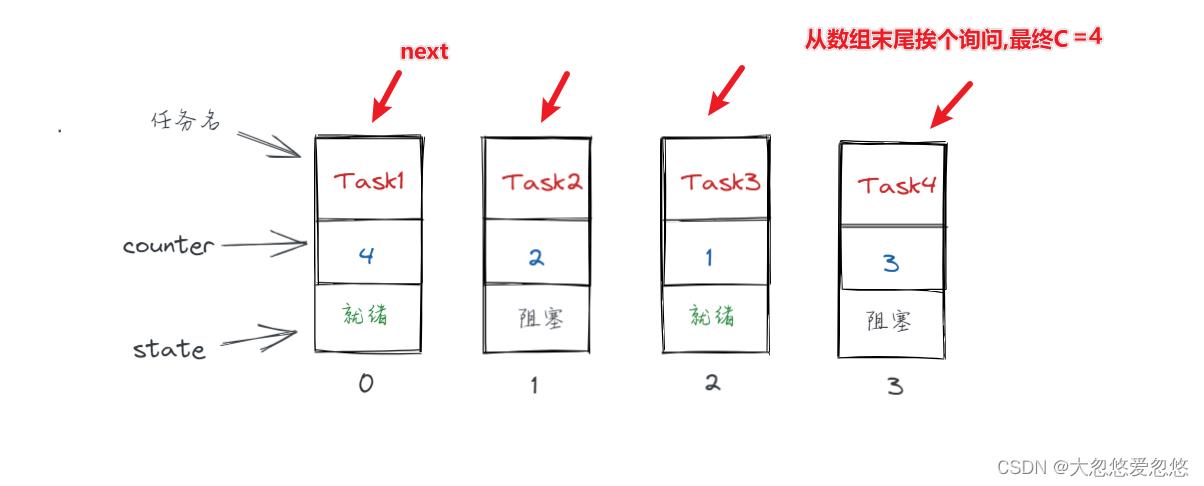
- 若就绪任务中 counter 值全为0,则根据每个任务的优先权值更新每一个任务(全部任务,包含阻塞的)的 counter 值,然后再次遍历,选出一个counter最大的任务。
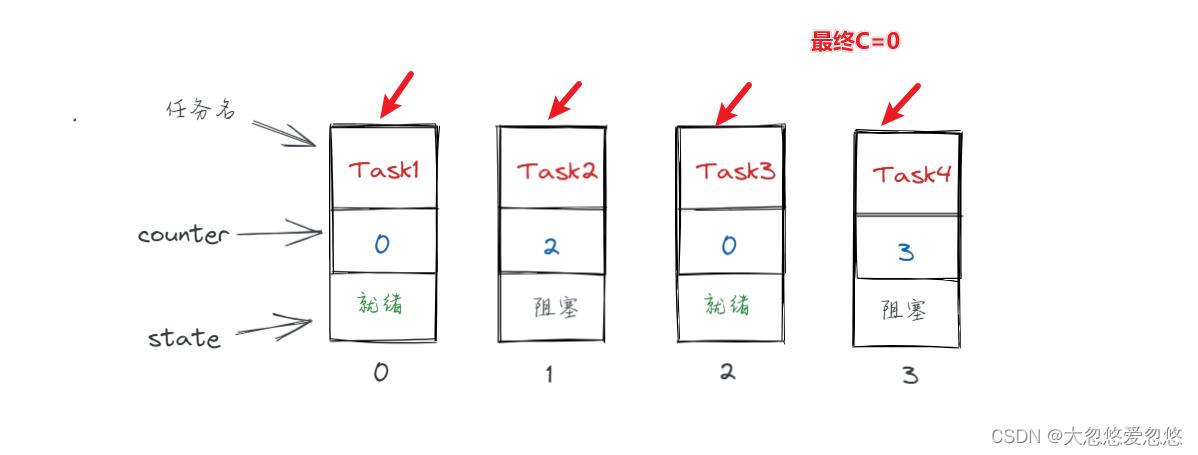
更新counter,然后再次轮询:
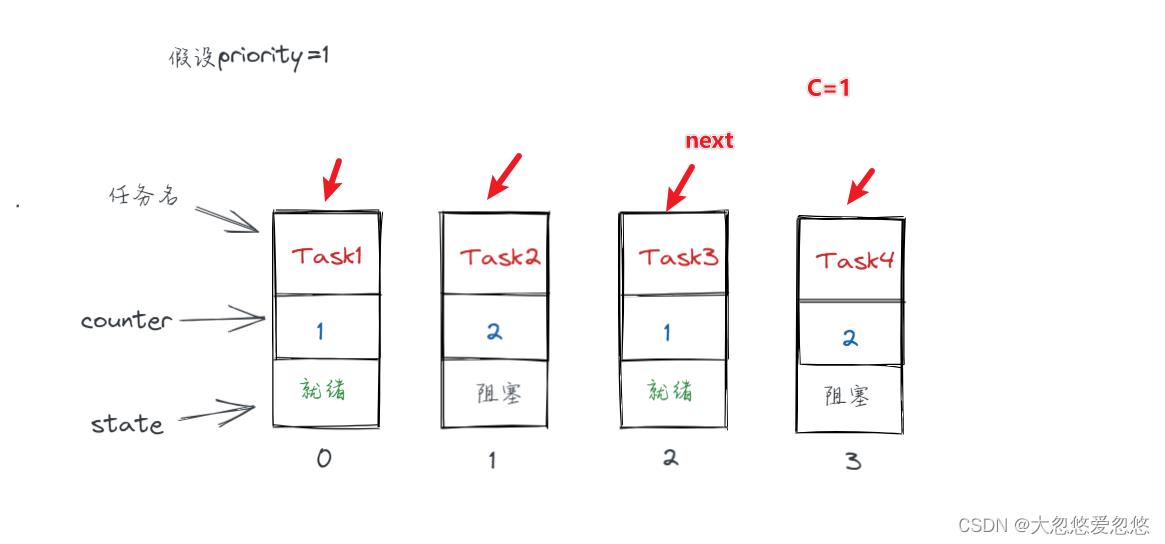
假如再更新counter之前,Task2从阻塞态恢复到了运行态,会怎样呢?

阻塞的进程再就绪后,其优先级会高于非阻塞进程。阻塞是因为发生了I/O,而I/O则是前台进程的特征,所以该调度策略照顾了前台进程。
counter的作用: 时间片
要了解时间片,我们先来普及一下时间片轮转
- 在Bios引导进入系统后,会执行系统的main函数(init/main.c):
void main(void) /* This really IS void, no error here. */
/* The startup routine assumes (well, ...) this */
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
...
sched_init();
...
move_to_user_mode();
if (!fork()) /* we count on this going ok */
init();
for(;;) pause();
- 其中进行了很多的初始化操作,包括 sched_init,这便是内核调度程序的初始化子程序(kernel/sched.c),其定义如下:
void sched_init(void)
...
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
...
sched_init 初始化了8253定时器(微机原理与接口技术学过的),8253每10ms发出一个中断请求信号。然后设置了一个中断服务程序 timer_interrupt,即每10ms中断一次,执行一次 timer_interrupt 。
timer_interrupt 在kernel/system_call.s中定义,为一段汇编程序:
.align 2
timer_interrupt:
push %ds # save ds,es and put kernel data space
push %es # into them. %fs is used by _system_call
push %fs
pushl %edx # we save %eax,%ecx,%edx as gcc doesn't
pushl %ecx # save those across function calls. %ebx
pushl %ebx # is saved as we use that in ret_sys_call
pushl %eax
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
movl $0x17,%eax
mov %ax,%fs
incl jiffies
movb $0x20,%al # EOI to interrupt controller #1
outb %al,$0x20
movl CS(%esp),%eax
andl $3,%eax # %eax is CPL (0 or 3, 0=supervisor)
pushl %eax
call do_timer # 'do_timer(long CPL)' does everything from
addl $4,%esp # task switching to accounting ...
jmp ret_from_sys_call
可以发现,其核心为一句 call do_timer,即调用 do_timer 函数。
do_timer 函数在kernel/sched.c中定义,
void do_timer(long cpl)
...
if ((--current->counter)>0) return;
current->counter=0;
// 内核中不调度
if (!cpl) return;
schedule();
其调用了一个 schedule(), 这个 schedule() 函数选出下一个要执行的进程,并且切换到它
通过上面的分析可以发现,counter 扮演了时间片的角色,每一次8253产生中断会调用中断服务程序,使当前进程 counter 减1,减到0则调用调度函数 schedule(),这是一个十分明显的round robin(时间片轮转)策略。
counter的另一个作用: 优先级
while(--i)
if((*p->state == TASK_RUNNING&&(*p)->counter>c)
c=(*p)->counter, next=i;
找counter最大的任务调度,counter表示了优先级
for(p=&LAST_TASK;p>&FIRST_TASK;--p)
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
counter代表的优先级可以动态调整
阻塞的进程再就绪以后优先级高于非阻塞进程,为什么?
- 当就绪进程的counter都为0时,会进行一波counter的更新,将所有就绪和阻塞的进程都counter值都进行更新,即counter=counter/2+priority
- 因此,对于阻塞进程而言,它的counter会因为每一次的更新,而变大,而就绪进程的counter则会置为初值
进程为什么会阻塞?
- I/O,正是前台进程的特征
counter作用的整理
- counter会无限增大吗? ----> 不会,因为counter保证了响应时间的界
设 c(0) = p
c(t) = c(t - 1) / 2 + p
…
c(∞)=p + p/2 + p/4 + …… <= 2p
最长的时间片是2p
- 经过IO以后,counter就会变大;IO时间越长,counter越大,照顾了IO进程,变相的照顾了前台进程
- 后台进程一直按照counter轮转,近似了SJF(短作业优先)调度,因为短作业耗时短,因此剩余时间片应该较多,所以每次轮询选出的概率较大,例如: word文档每敲入一个字,触发一次中断,然后进入IO阻塞,因此对于word进程而言,其属于短作业范畴,大部分时间都处于阻塞状态,真正使用CPU的时间较少,因此counter–的概率相对较低
10ms触发一次时钟中断,触发后,会去将当前进程的counter–,如果counter为0,就进行调度切换
- 每个进程只用维护一个counter变量,简单、高效
- CPU调度: 一个简单的算法折中了 大多数任务的需求,这就是实际工 作的schedule函数
我这里最后再抛出一个疑问: 存不存在一直有就绪态进程的counter值不为0的局面,这样的话,counter被集体更新的机会就没有了?
- 答: 不会
原因如下:
进程进入进入就绪态有两种方式,一种是从阻塞态转换到就绪态,一种是进程刚创建,然后设置为就绪态。
并且counter值减去1的情况,只可能发生在时钟中断情况下,随着时钟中断不断发生,会产生第一个就绪进程的counter值为0的局面,然后时钟中断中,会调用schedule函数。
当某个进程的时间片用完后,并不会进入阻塞状态,但是也不会再被调用了,而是等待着下一次counter被集体更新
而schedule函数会去找出剩余就绪进程中,counter非0的最大值,继续执行,然后随着时钟中断不断发生,慢慢的所有就绪进程的counter都变为了0,此时进行集体的counter更新。
因此,不会存在一直都有就绪态进程的couter不为0,导致集体更新一直没产生。
以上是关于操作系统CPU调度策略---07的主要内容,如果未能解决你的问题,请参考以下文章
Linux(内核剖析):07---进程调度总体概述(多任务系统策略时间片)
Linux 内核进程优先级与调度策略 ① ( SCHED_FIFO 调度策略 | SCHED_RR 调度策略 | 进程优先级 )
Linux 内核进程优先级与调度策略 ① ( SCHED_FIFO 调度策略 | SCHED_RR 调度策略 | 进程优先级 )