11.cpu调度策略与schedule调度函数
Posted PacosonSWJTU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了11.cpu调度策略与schedule调度函数相关的知识,希望对你有一定的参考价值。
【README】
1.本文内容总结自 B站 《操作系统-哈工大李治军老师》,内容非常棒,墙裂推荐;
2.cpu调度: 指的是 cpu从就绪队列中选择一个进程来执行;选择哪一个进程是调度算法的执行结果;
3. 相关定义:
- 响应时间:从用户操作发生到程序响应的等待时间;
- 吞吐量:cpu在单位时间内完成的任务量;
- 周转时间: 从进程提交到进程完成的时间间隔;
4.4种调度算法列表(非常重要*):
- 先来先服务 FCFS;
- 短作业优先 SJF;
- 时间片轮转调度 RR-RoundRobin算法;
- 优先级调度;
【1】cpu调度策略
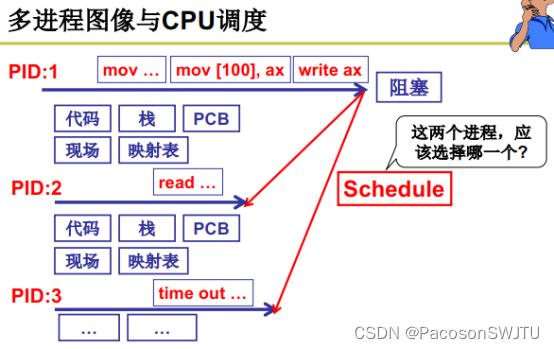
【1.1】多进程图像与cpu调度
1)问题: 进程pid1执行阻塞,应该切换到 pid2 还是pid3执行,这就需要调度算法来决定了;
【1.2】调度策略
1)调度策略:FIFO,优先级 ;
2)调度算法应该满足进程正常运行条件:
- 尽快结束任务: 周转时间(从任务进入到任务结束)短;
- 用户操作尽快响应: 响应时间(从操作发生到响应)短;
- 系统内耗时间少:吞吐量(cpu单位时间完成的任务量);
3)总原则:系统专注于任务执行, 又能合理调配任务;
4)如何做到合理? 需要折中,综合考虑

吞吐量与响应时间之间的矛盾;
- 响应时间小 =》 切换次数多 =》 系统内耗大 =》 吞吐量小 ;即响应时间短与吞吐量大两者不可兼得;
- 响应时间,指的是 用户敲键盘到键盘响应的时间;
【例】敲键盘
- 用户在程序1中敲键盘那个时刻,cpu刚好切换到其他程序2执行,程序2执行若干时间片又切回程序1,这时程序1才响应键盘中断,从切出来到切回来这段时间叫做响应时间(或指的是从操作发生到程序响应的用户等待时间);
- 要想响应时间小,即程序的cpu时间片减少(下图程序2的执行时间要少),那切换次数就要多;
- 切换次数越多, 切换成本越高(如栈切换,tss切换),即系统内耗大,进而导致吞吐量小;
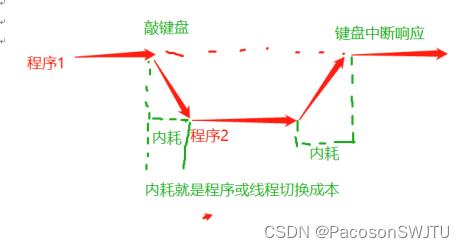
图 敲键盘的响应时间
5)任务类型
- 5.1)IO密集型任务: 程序需要执行计算与IO工作;
- 5.2)CPU密集型任务:仅执行计算工作;
【1.3】cpu调度算法*
4种调度算法列表(非常重要*):
- 先来先服务 FCFS;
- 短作业优先 SJF;
- 时间片轮转调度 RR-RoundRobin算法;
- 优先级调度;
【1.3.1】调度算法1:先来先服务-FCFS
first come, first served
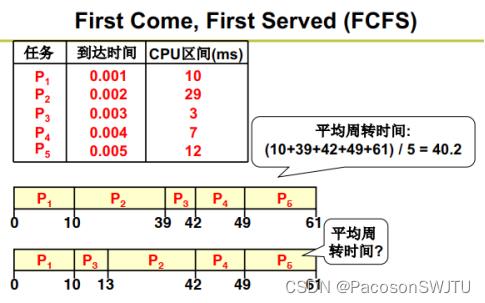
图解:
- 调度策略1: P1, P2, P3, P4, P5;平均周转时间为 (10+39+42+49+61) / 5 = 40.2
- 调度策略2: P1, P3, P2, P4, P5;平均周转时间为 (10+13+42+49+61)/5= 35
策略1与策略2的区别在于:
- 策略2把短作业 P3 放在了P2的前面,可以理解为 短作业优先;
先来先服务的调度算法比较基础;
【1.3.2】调度算法2-短作业优先SJF
1.短作业优先,SJF,short job first ,减少周转时间(最小化平均周转时间);

P1+(p1+p2) + (p1+p2+p3) + … = ∑(n+1-i)Pi = n*p1 + (n-1)p2 + ……
为了使结果越小,又n最大,所以p1应该取最小,p2次之,......;
2)短作业优先的问题:
- 短作业优先调度算法,把耗时短的作业提前,耗时长的作业放后面,会导致耗时长的作业的响应时间过长,用户体验不好;
【1.3.3】调度算法3-时间片轮转调度(RR)
1)时间片轮转调度:按照时间片轮转调度(Round-Robin轮转调度算法);

【1.3.4】 调度算法4-优先级调度
1)响应时间和周转时间同时需要考虑,怎么办 ?
- 如 word关心响应时间, gcc编译器关心周转时间,两类任务同时存在,应该怎么办?
2)任务类型
- 前台任务: IO密集型任务,如word;
- 后台任务: 计算密集型任务,如gcc编译器;
3)把前台任务链接到队列1,后台任务链接到队列2;
4)优先级调度细节:
- 前台任务队列(队列1)采用短作业优先策略,优先级高;
- 后台任务采用轮转调度,优先级低;

5)优先级调度算法的问题
- 如果前台任务一直存在的话,后台任务可能一直都没有机会被cpu执行,后台任务饥饿;
- 如果后台任务优先级被动态升高,则会影响前台任务的执行,前台任务响应时间又会增加;
- 此外,操作系统如何知道 哪些是前台任务(io密集型任务),哪些是后台任务(计算密集型任务)?

6)解决方法
- 以轮转调度为核心,短作业优先级高于长作业;
【2】一个实际的 schedule函数 (调度算法)
【2.1】linux0.11的调度函数 schedule()

1)schedule()函数源码
// 操作系统进程调度函数源码
void schedule()
while(1)
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while(--i)
// TASK_RUNNING 就是 就绪
if (*p->state == TASK_RUNNING && (*p)->counter > c)
c = (*p) -> counter, next = i;
// 若c不等于0,则找到了最大的counter,结束循环,跑去 switch_to 执行
// 基于 counter实现了优先级调度,且counter作为时间片,进行了轮转调度
if (c) break;
// counter等于0 ,执行到这里,表示所有就绪态进程的时间片都用完了
// 遍历所有进程
for ( p = &LAST_TASK; p > &FIRST_TASK; --p )
// 就绪态进程的 时间片恢复到初值(优先级);
// 阻塞态进程的 时间片设置为 时间片一半,加上初值(优先级),这个值在增加;
(*p)->counter = ( (*p)->counter >> 1 ) + (*p)->priority;
// 切换到next进程
switch_to(next);
2)counter的作用
作用1:时间片;
- 每次时钟中断发生时,counter都会自减1(时钟中断时,当前进程的counter时间片减去1,然后再切换出去;因为当前counter减1,所以它不是最大的,所以下一次轮转调度不会选择上一个同样的进程);
- 当 counter 不等于0,则调度到其他进程;典型的时间片轮转算法;
- 当 counter 等于0,则表明所有就绪进程时间片用完(注意是就绪态进程,不是所有进程的时间片都用完),需要重新初始化时间片(包括初始化就绪进程时间片,增大阻塞进程时间片);

作用2: 优先级;
- 参见上文中 schedule()函数源码中的以下代码:
(*p)->counter = ( (*p)->counter >> 1 ) + (*p)->priority;
counter代表的优先级可以动态调整;
阻塞的进程在就绪后,优先级高于非阻塞进程,因为
// 阻塞进程的counter值在增加
(*p)->counter = ( (*p)->counter >> 1 ) + (*p)->priority;
所以io密集型进程的优先级会高于计算密集型进程的优先级;其中io密集型是前台进程的特征;
【2.2】counter作用小结

1) Counter保证了响应时间的界,因为按照下面重置counter时间片的算法,其最大值为2p;
// 阻塞进程的counter值在增加
// 下面的算法是一个递增函数,即阻塞时间越长,counter被重置次数越多;
(*p)->counter = ( (*p)->counter >> 1 ) + (*p)->priority; 2)经过io后,counter会变大;io时间越长,counter时间片越大,照顾了io进程,或前台进程;
3)后台进程一直按照 counter轮转,近似 SJF 短作业优先调度算法;
4)每个进程只用维护一个 counter变量,简单,高效;
5)cpu调度:
- 一个简单的算法折中了大多数任务需求,这就是实际工作的 schedule函数;
以上是关于11.cpu调度策略与schedule调度函数的主要内容,如果未能解决你的问题,请参考以下文章